- The paper introduces GR3EN, a pipeline integrating video-to-video diffusion and 3D distillation for controllable, high-fidelity relighting of full room-scale environments.
- It employs precise light source conditioning with per-pixel specifications to enable individual control over indoor and outdoor illumination.
- Experimental results, including improved PSNR, SSIM, and LPIPS metrics along with user studies, demonstrate significant gains over prior relighting methods.
Generative Relighting for 3D Environments: Technical Analysis of GR3EN
Introduction and Motivation
Relighting captured 3D scenes under user-defined illumination is essential for graphics, visual effects, and immersive experiences. Classical inverse rendering techniques have struggled to generalize to complex scenes due to intrinsic ill-posedness, often requiring strong simplifications or abundant data. While 2D generative models and recent diffusion-based relighting frameworks have shown promise for videos and isolated objects, none have achieved controllable, fine-grained relighting of full room-scale 3D reconstructions. "GR3EN: Generative Relighting for 3D Environments" (2601.16272) introduces a pipeline that employs video-to-video diffusion modeling and 3D distillation, directly addressing these challenges.
Pipeline Architecture and Innovations
The GR3EN framework consists of three primary stages:
- 3D Scene Reconstruction: Multiview posed images are used to synthesize a 3D scene, typically utilizing Zip-NeRF or 3D Gaussian Splatting. The system is agnostic to the reconstruction method, as it only requires rendered camera-path videos for subsequent steps.
- Video-to-Video Relighting via Diffusion: The core relighting engine is a fine-tuned Wan 2.2 TI2V-5B diffusion model. Given a rendered input video and a per-pixel target lighting specification (intensity, color, and exterior lighting), the model generates a video under new illumination. Conditioning is performed via temporal concatenation and rotary positional encodings rather than channel-wise concatenation, providing full self-attention across frames and modalities.
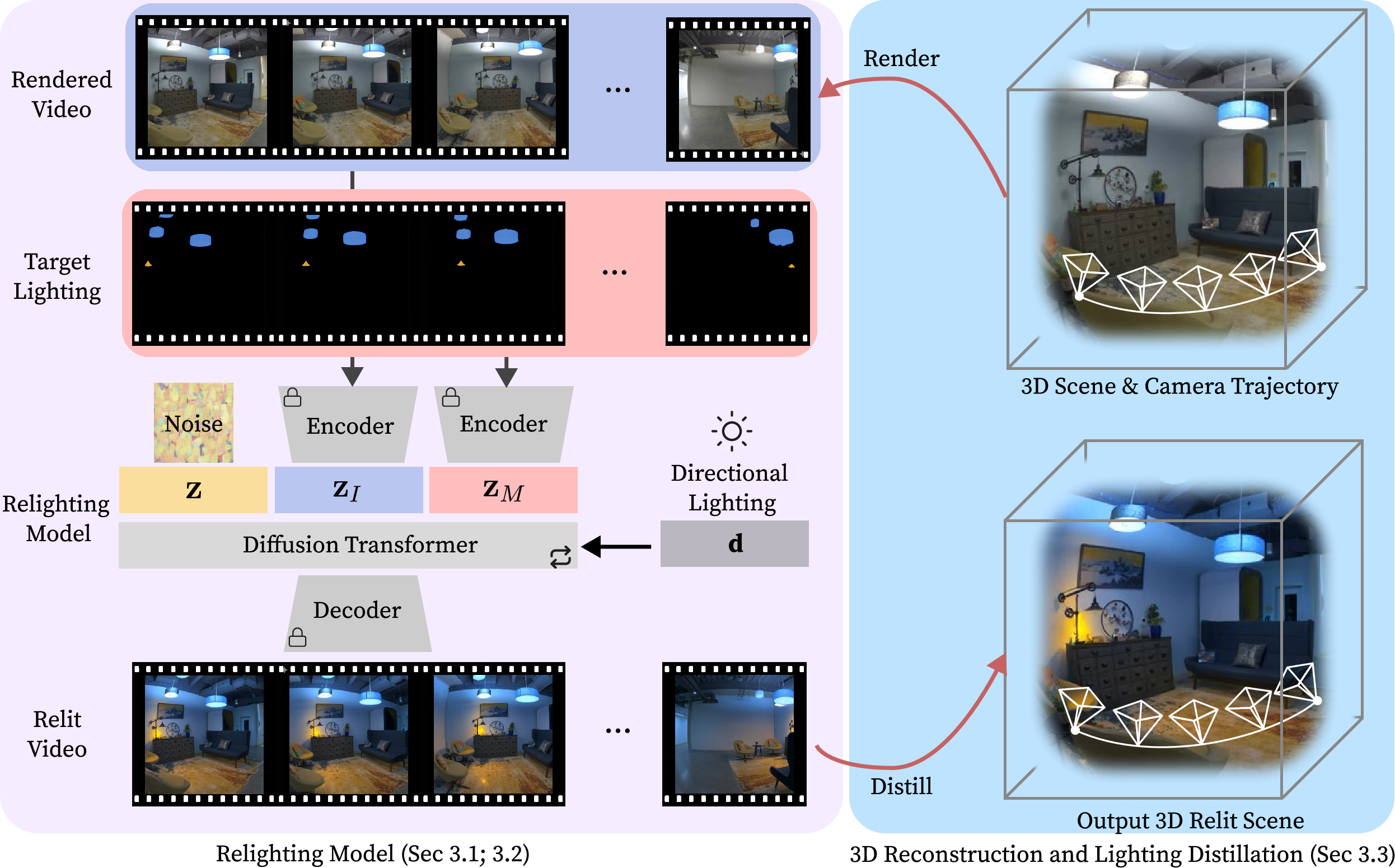
Figure 1: The relighting pipeline combines 3D scene video rendering, diffusion-based relighting with conditioning video, and distillation of the transformed appearance back to 3D.
- Distillation to 3D: The relit video is used to fine-tune the 3D scene model, resulting in a 3D representation consistent with the new lighting, suitable for novel-view synthesis. Distillation typically involves optimizing Zip-NeRF parameters to minimize discrepancies between rendered and desired relit videos.
Conditioning Strategies and Training Paradigm
Light Source Conditioning
GR3EN's conditioning approach enables explicit control of arbitrary indoor (directly visible) and outdoor (externally observed or unobserved, e.g., sunlight) light sources. Scene light masks are generated by annotating source positions and specifying on/off states, per-source color, and exterior light scalar.

Figure 2: Visualization of the one-light-at-a-time data pipeline for generating lighting basis images, enabling arbitrary target lighting by linear combination.
Diffusion Training Objective
Training employs a latent video representation, input/lighting concatenation as described, and a flow-based noise scheduler with biased sampling to high-noise timesteps (τ=0.4, ρ=0.85). This ensures the model learns global illumination consistency across the scene before refining high-frequency details.
Dataset Construction
The synthetic data set leverages Infinigen for large-scale photorealistic indoor environments. Each scene is rendered under 30 lighting configurations using an OLAT strategy, producing over 108,000 unique videos. Sampling prioritizes diverse illumination, emission temperatures, and color patterns to enforce generalization without overfitting.
Experimental Results
GR3EN demonstrates robust generalization from solely synthetic training data to real-world scenes (Eyeful Tower dataset). Results show physically-plausible relighting even with previously unseen fixture types, accurate shadowing, reflection removal, and exterior/interior light toggling.

Figure 3: Real-world relighting comparisons: GR3EN matches lighting edits with realistic global illumination, outperforming prior methods.
Further, insertion of novel, out-of-distribution light sources (e.g., a neon wall) yields plausible illumination distributions and shadows.

Figure 4: The method accommodates arbitrary new light source insertion into reconstructed 3D scenes—even without such instances in the training corpus.
GR3EN's relit scenes retain high fidelity when synthesized from novel viewpoints, in contrast to 2D relighting methods (LightLab), which fail to propagate consistent effects across views.

Figure 5: Relit novel views: Geometry-aware relighting preserves cross-view consistency—2D methods fail especially when target light is not in direct view.
Fine-Grained and Controllable Lighting
GR3EN allows toggling individual lights, partial activation, color modulation, and precise emission specification. Such control is unattainable with prior scene-based or framewise relighting strategies.


















Figure 6: Fine, per-light control—users adjust both local and global scene luminance interactively for flexible edits.
Intensity variation experiments confirm local appearance adjustments in target-lit regions with negligible artifacting in ambient-lit zones.
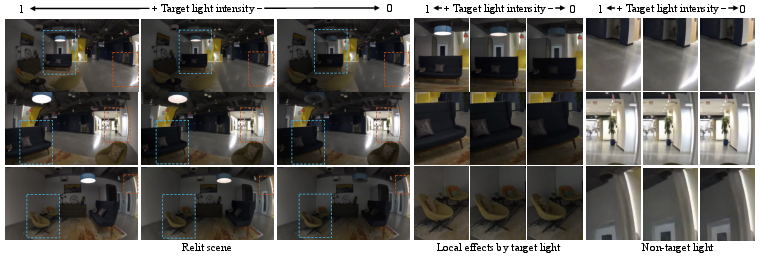
Figure 7: Local output varies appropriately with target light intensity; ambient regions remain stable under identical conditions.
Quantitative and Qualitative Metrics
Across held-out synthetic scenes, GR3EN consistently outperforms DiffusionRenderer, LightLab, and Light-A-Video in PSNR, SSIM, and LPIPS. GR3EN achieves 24.77 PSNR, 0.741 SSIM, 0.130 LPIPS, exceeding the best prior by substantial margins. Ablation studies show conditioning strategy and noise sampling critically impact fidelity.
A user study with video pairwise comparisons shows GR3EN preferred in 79% of cases overall, with an 88% win rate for lighting similarity, demonstrating both realism and consensus at scale.
Additional Applications
- Video-Only Relighting: The video-to-video component can relight conventional content absent 3D information, generating plausible shadowing and reflections.
- Unseen Source Types: Out-of-distribution light shapes, emission colors, and fixture arrangements can be controlled with minimal artifacts.
- Temporal Consistency: GR3EN avoids flickering seen in per-frame editors (LightLab), supporting applications demanding perceptual stability.
Limitations and Future Directions
GR3EN is constrained by the representational diversity of training assets; extremely rare or non-emissive source types lead to minor inconsistencies. Scene coverage in the input video is also a prerequisite for high-fidelity output; occluded regions or incomplete masks can manifest as physical inconsistencies. Expansion of synthetic assets, improved coverage strategies, and deeper integration with multi-sensor scene capture could mitigate these effects.
Potential future developments involve:
- Scaling training to heterogeneous outdoor-indoor scenes
- Incorporating joint material estimation for physically-accurate relighting
- Adapting the pipeline for real-time relighting in AR/VR pipelines
Conclusion
GR3EN demonstrates that generative diffusion models, appropriately conditioned and distilled into 3D representations, enable controllable, high-fidelity relighting of complex, room-scale environments. The system supports fine-grained, per-light control, robust cross-domain generalization, and significant improvements over previous graphics and vision-based relighting pipelines. In summary, GR3EN advances the paradigm of 3D scene editing, opening practical avenues for scene manipulation in fast-prototyping, digital content creation, and mixed-reality applications.