- The paper demonstrates that rubric-constrained LLMs achieve near-human performance with mean absolute errors within typical human disagreement ranges.
- It compares zero-shot LLM scoring with statistical NLP regression, revealing each approach's strengths in evaluating different assessment rubrics.
- The study emphasizes human oversight and bias mitigation, highlighting vulnerabilities like prompt injection that require robust safeguards.
Machine-Assisted Grading of Nationwide School-Leaving Essays: LLMs and Statistical NLP in the Estonian Context
Introduction and Motivations
The study systematically evaluates the feasibility and performance of LLMs and statistical NLP methods for automated scoring of nationwide essay examinations in Estonian. The work is positioned within a context where Estonia, leveraging its advanced digital infrastructure, is transitioning to computer-based national examinations and considering the integration of AI-driven assessment methods. Issues of grading reliability, validity, fairness, and compliance with EU regulations (particularly the AI Act’s stipulations on high-risk applications in education) frame the necessity for robust, interpretable, and human-in-the-loop machine-assisted pipelines.
Datasets and Rubrics
The empirical foundation comprises the full 2024 trial exam cohorts: 781 essays from 9th grade students and 764 from 12th grade, each double-scored by trained assessors using rubrics operationalizing the national curriculum across multiple rubric categories (content/structure, vocabulary/syntax, orthography/formatting, et al.), with both holistic and analytic subscore profiles. The datasets are realistic in terms of score distributions, essay lengths, and inter-rater deviation, capturing typical grading challenges encountered in high-stakes assessment.
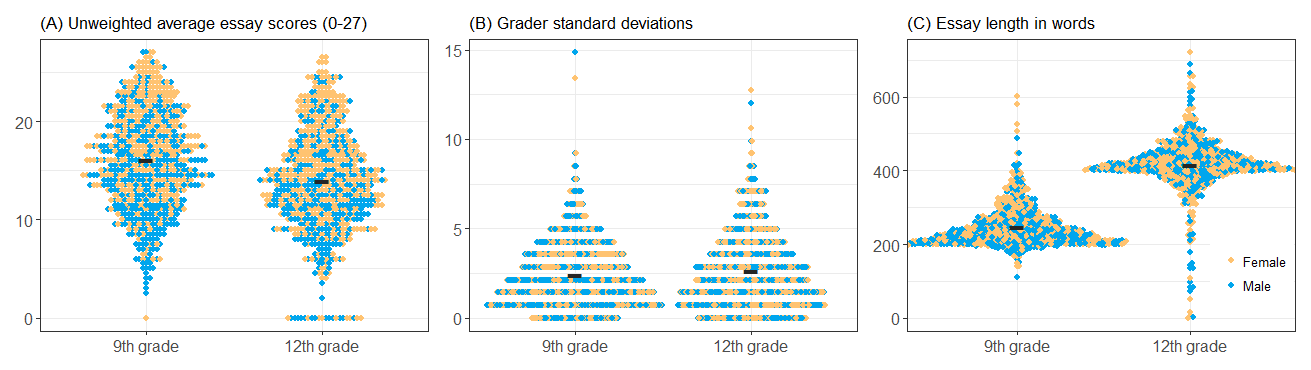
Figure 1: Summary of score distribution, grader discrepancy, and essay lengths for both grade cohorts; each essay is one dot, colored by student sex.
Methods: LLM Zero-Shot Scoring and Statistical NLP Regression
A zero-shot in-context learning paradigm was employed for LLM evaluation: for each rubric aspect, the model was prompted with the corresponding official instructions and rubric definitions, constraining outputs to a rubric-aligned format. Five top-tier LLMs were used (GPT-4o, GPT-4.1, o4-mini, Gemini-2.0-Flash, Gemini-1.5-Pro), all supporting Estonian; each model scored each essay separately for each subcategory, mimicking authentic human grading practices.
In parallel, feature-based supervised learning pipelines were constructed for the language accuracy aspects, incorporating over 100 linguistic features (error counts, lexical/syntactic complexity, surface readability, etc.) extracted with dedicated GEC tools and linguistically informed feature engineering. Regression models (Linear/Ridge, SVR, Random Forest) were tuned per subscore using 10-fold cross-validation.
Across all models and approaches, the mean absolute error (MAE) on subscore categories typically falls within the empirically observed human disagreement range (often <1 on the 0–3 scale). Model errors are often explainable by human rater subjectivity, especially in components such as vocabulary and argumentation. The most notable finding is that LLMs, when rubric-constrained, exhibit near-human performance for most aspects, with their prediction distributions closely tracking those of human graders and rarely falling outside plausible human ranges.
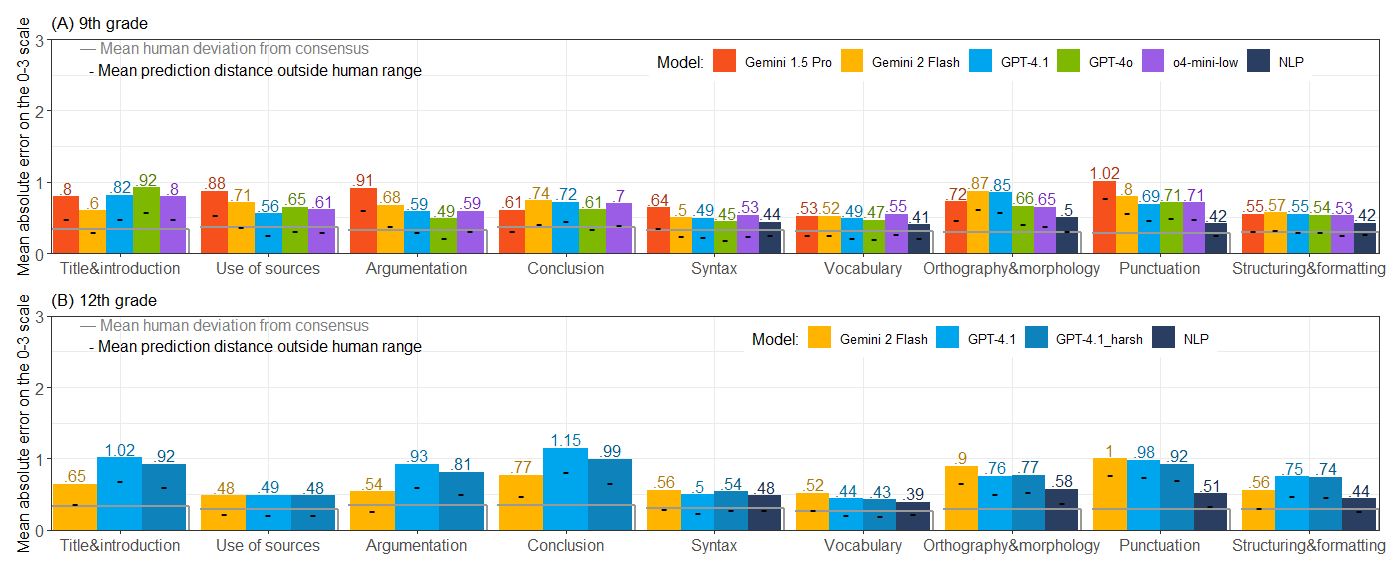
Figure 2: Mean absolute error (MAE) per rubric category and model, benchmarked against inter-grader deviation (gray lines).
Statistical NLP regressors slightly outperform zero-shot LLMs for highly orthographic or morphosyntactic aspects (e.g., punctuation, spelling), consistent with the deterministic and high precision of dedicated error correction systems. However, for content and argumentation, LLMs demonstrate a robust capacity for nuanced evaluation—an essential requirement for open-ended written assessments.
Bias analysis reveals that certain models exhibit a persistent leniency or harshness (i.e., systematic polarity bias), but the magnitude is bounded (e.g., Gemini 1.5 Pro: -3.66/27; GPT-4.1: +4.68/27), underscoring the importance of calibration and human moderation in deployment.
Prompt Injection Vulnerability and Mitigation
A controlled experiment demonstrates that LLM-based grading is susceptible to prompt injection attacks—malicious or accidental instructions embedded in student essays can override or bias the scoring prompt. The attacked models awarded inflated scores for all injection cases, underscoring a clear operational risk for unsupervised LLM deployment.
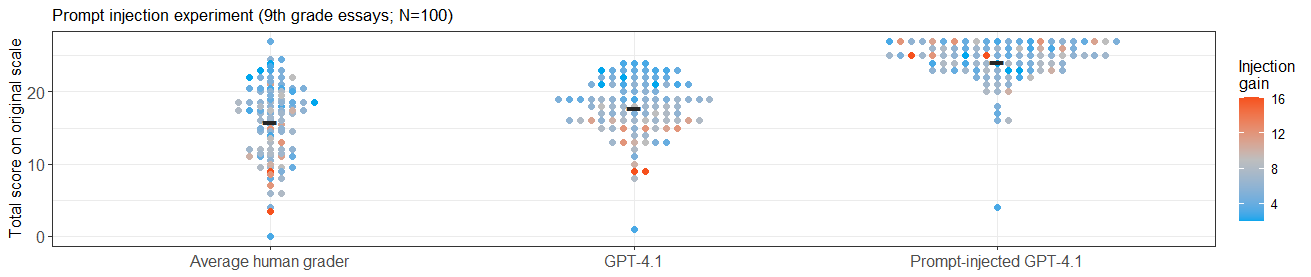
Figure 3: Prompt injection leads to consistent positive shifts in assigned scores across all tested essays.
Mitigation strategies—such as input sanitization, prompt hardening, or ensemble-based anomaly detection—are essential, especially in high-stakes contexts.
LLMs as Writers and the Evolving Assessment Landscape
LLM-generated essays, prompted to meet rubric specifications, consistently receive top possible scores from both human and LLM graders, often exceeding those of actual student submissions. This empirical result highlights a disconnect: current assessment rubrics are highly product-oriented and structurally explicit, which makes them vulnerable to optimization by generative models, but does not capture process-related aspects of writing or deeper cognitive constructs.
Practical Implications and Framework for Deployment
The findings establish that LLM-assisted scoring is technically viable at national scale, even for lower-resource languages such as Estonian, provided stringent rubric anchoring and systematic human oversight. Given regulatory constraints (EU AI Act: mandatory human-in-the-loop, transparency, and data governance), the recommended operational framework is a modular scoring pipeline wherein:
This modular and auditable strategy enables continuous model evaluation and adaptation to policy shifts, safeguarding both psychometric integrity and institutional trust.
Limitations and Directions for Future Work
The study is not a comprehensive LLM benchmark; real-world deployment will require continual updating as new architectures emerge and as prompt-based interfaces evolve. Furthermore, rubric and assessment designs must become increasingly operationalizable yet pedagogically meaningful, minimizing ambiguous descriptors. There is a growing need to explore longitudinal effects on learning, examining not only scoring robustness but also pedagogical implications when LLMs provide formative feedback or act as writing coaches.
Expansion to oral, multimodal, or process-focused assessment, as well as further investigation of user (student/teacher) perceptions regarding AI-generated grades and feedback, presents compelling avenues for future research.
Conclusion
The research provides decisive evidence that, when embedded within rigorously designed human-in-the-loop workflows, LLMs and statistical NLP methods can support high-stakes essay scoring in national exams with reliability and validity comparable to human raters. The modular architecture outlined is broadly generalizable, offering a template for responsible, scalable, and transparent integration of AI into educational assessment systems—especially for small-language contexts and under stringent regulatory regimes. Continued attention to rubric clarity, bias auditing, adversarial robustness, and stakeholder acceptance remains essential as educational assessment evolves in the era of generative AI.