- The paper introduces a non-spectral procedure using neighborhood smoothing and K-means clustering for perfect clustering in sparse, directed SBMs.
- It establishes new uniform row-wise concentration bounds to handle heterogeneous in- and out-degrees under vanishing edge probabilities.
- Simulations confirm the method's high clustering accuracy and robustness even as the number of communities grows and edge density decreases.
Perfect Clustering for Sparse Directed Stochastic Block Models: An Expert Review
Introduction and Context
This work addresses a critical gap in the theoretical understanding of community detection via exact recovery in sparse, directed stochastic block models (SBMs), especially when the number of communities Kn diverges with the network size. While sharp results exist for undirected SBMs [abbe2015exact] [lyzinski2014perfect], such guarantees for the directed, sparse case have remained elusive. Spectral algorithms typically lose stability in regimes where networks are both asymmetric and low-degree [chen2019spectral] [wang2020spectral]. Previous non-spectral approaches were focused primarily on matrix estimation and did not provide cluster recovery results in directed settings [zhang2017estimating]. This paper fills a significant gap by providing a robust, non-spectral procedure that achieves exact recovery under mild conditions in this setting.
The paper considers a binary, directed graph G on n nodes, with edges generated according to a generalization of the Stochastic Block Model: each node is assigned to one of Kn communities with probabilities ρ; the probability of a directed edge from i (community j) to k (community l) is γnBjl, where γn controls sparsity. This setup naturally leads to heterogeneity in in- and out-degrees, as well as asymmetry in connectivity, reflecting real-world networks such as citation graphs or the web [leicht2008community].
The recovery goal is strict: exact identification of all community labels (up to permutation) with probability tending to one. Crucially, the paper allows for both vanishing edge probabilities (γn→0) and a growing number of communities (Kn→∞).
Proposed Methodology
Two principal stages underpin the proposed procedure:
1. Probability Matrix Estimation via Neighborhood Smoothing:
A nonparametric estimator is constructed by locally averaging edge occurrences over node neighborhoods determined by a quantile-based dissimilarity measure. For a node i, its neighborhood Ni contains the nodes most similar in their connectivity patterns, as determined by a robust metric. The estimated edge probability from i to j is P~ij=∣Ni∣−1i′∈Ni∑Ai′j, where Ai′j is the adjacency indicator.
2. K-means Clustering of Smoothed Rows:
Once the smoothed probability matrix is obtained, K-means is applied to its rows, directly clustering nodes according to their estimated patterns of outgoing connections. This step entirely avoids eigen- or singular value decompositions, which are known to become numerically unstable in very sparse or asymmetric graphs.
Theoretical Guarantees
The heart of the paper lies in the derivation of new uniform row-wise concentration bounds for the estimator P~, encapsulated in a (2,∞)-norm result:
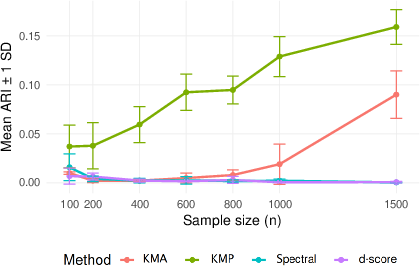
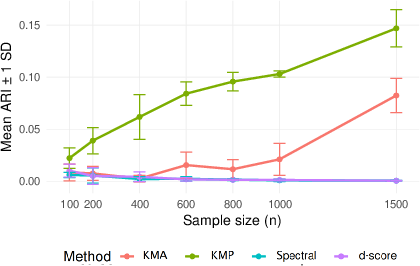
Figure 1: Undirected setting schematic illustrating distinctive block structure and neighborhood relationships in the SBM.
These bounds critically handle the separately varying in- and out-degree distributions. The separation between distinct rows of the expected probability matrix (as induced by distinct communities) is lower-bounded in terms of the sparsity γn, the minimal community proportion ρmin, and the minimal separation dB∗. The analysis leverages new geometric and probabilistic arguments extending concentration phenomena in ways not needed in the undirected case.
Under mild conditions—that neither γn nor ρmin decay too quickly and that Kn grows sub-exponentially—the main theorems guarantee:
- The (2,∞) and Frobenius norms of the estimation error are small with high probability (see Corollary 1 and 2).
- If the minimum inter-community separation is above a quantifiable threshold, K-means on the smoothed matrix achieves perfect clustering.
Simulation Results and Empirical Validation
The authors provide extensive simulations under diverse regimes, including highly directed, sparse networks, non-symmetric block structures, and increasing numbers of communities. These empirics decisively show that:
- The non-spectral method (KMP) achieves high clustering accuracy as measured by Adjusted Rand Index (ARI), even in regimes where spectral and score-based methods (d-score) fail.
- The empirical ARI converges to 1 with increasing n, even when Kn grows and γn vanishes.
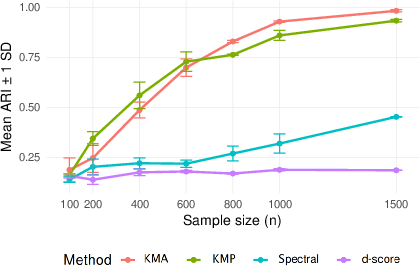
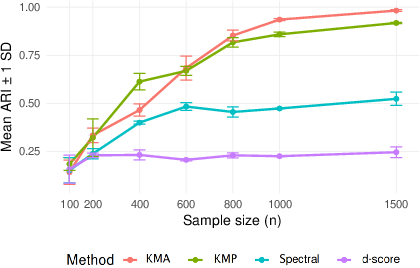
Figure 2: Clustering accuracy for banded SBM, demonstrating the robustness of KMP to locally homogeneous block structure, both undirected and directed.
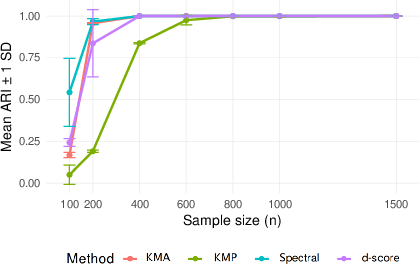
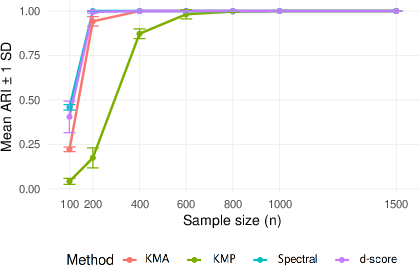
Figure 3: Performance in diagonal-dominant SBM highlights convergence of ARI and matches classical benchmarks for undirected and directed cases.
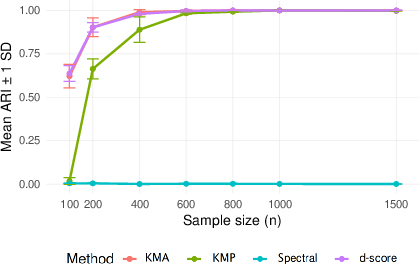
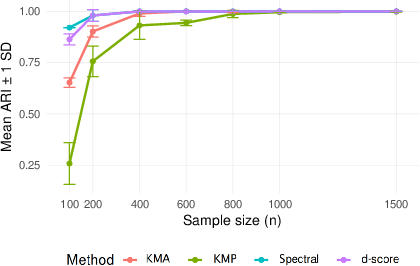
Figure 4: Recovery accuracy in sparse two-block SBM (γn=(logn/n)1/4), showing strong performance precisely at the sparsity boundary.
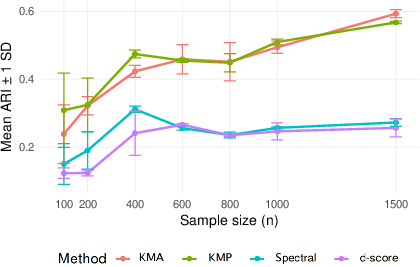
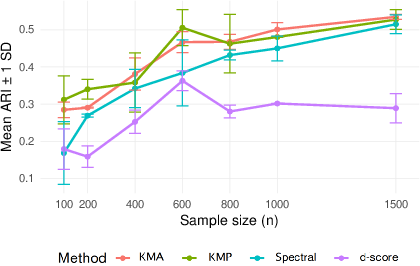
Figure 5: Empirical ARI for growing Kn=⌊logn⌋, indicating scalability and exact recovery in high community-count regimes.
These results both corroborate the theory and demonstrate practical reliability where standard methods deteriorate.
Practical and Theoretical Implications
The non-spectral, smoothing-based approach enables tractable exact recovery in directed, sparse networks—a setting common in citation graphs, online social networks, and other realistic data domains. The method remains robust as Kn diverges and as edge probabilities become vanishingly rare. Notably, this framework invites scaling to large graphs since computational bottlenecks associated with singular value decomposition are avoided.
Theoretically, this work shifts the boundary of what is possible in directed SBMs, providing a template for exact recovery with minimal assumptions, and opening avenues to analysis in regimes previously dismissed as intractable due to instability of spectral techniques.
Future Directions
The authors articulate several promising extensions:
- Generalization to overlapping or mixed-membership SBMs, which are important for real-world network modularity.
- Dynamics: Adapting the smoothing and clustering procedures to time-evolving directed graphs.
- Incorporation of node covariates, edge weights, and degree correction, while retaining non-spectral estimation.
These advances could enable robust community detection in highly complex network data and facilitate principled analysis at scale.
Conclusion
This paper establishes the first provable, non-spectral method achieving exact recovery of communities in sparse, directed SBMs with diverging numbers of clusters. Its contribution is both theoretical—via new concentration bounds and separation criteria—and practical, providing an estimator and clustering pipeline that outperforms existing spectral methods precisely where those methods are known to fail. The work thus substantially expands understanding and capability for network inference in complex directed settings.
References
- (2601.16427): "Perfect Clustering for Sparse Directed Stochastic Block Models"
- [zhang2017estimating]: "Estimating network edge probabilities by neighborhood smoothing"
- [chen2019spectral]: "Spectral clustering of directed networks: consistent community detection under the stochastic block model"
- [wang2020spectral]: "Spectral Algorithms for Community Detection in Directed Networks"
- [lyzinski2014perfect]: "Perfect clustering for SBM graphs via adjacency spectral embedding"
- [leicht2008community]: "Community structure in directed networks"
- [abbe2015exact]: "Exact recovery in the stochastic block model"
Full bibliographical details provided in main text.