- The paper introduces a hybrid SALAD framework that fuses sparse and linear attention with adaptive gating to balance efficiency and generation quality.
- It achieves 90% sparsity and a 1.72× inference speedup while maintaining video generation quality comparable to dense models.
- Analyses reveal that shared QKV projections and learned gating are crucial to mitigating degradation observed with static or LoRA-tuned sparse approaches.
Introduction
Video diffusion transformers have set a new standard for high-fidelity video generation, but their utility is fundamentally constrained by the quadratic computational scaling of the full attention mechanism with respect to sequence length. This computational bottleneck is especially acute for high-resolution, long-duration video generation tasks. While sparse and linear attention mechanisms have been proposed, each exhibits inherent trade-offs. Sparse attention models offer improved efficiency but often at the cost of generation quality, especially at extremely high sparsity levels. Linear attention alleviates quadratic scaling but suffers from degraded expressive power for complex token dependencies. The SALAD framework—“High-Sparsity Attention paralleling with Linear Attention for Diffusion Transformer” (2601.16515)—proposes an architecture that tightly integrates these two paradigms via a parallel, shared-parameter hybrid module, regulated by a trainable, input-dependent scalar gate.
SALAD Architecture
SALAD operates by running sparse and linear attention branches in parallel, with the linear branch acting as a global context supplement to the high-sparsity sparse branch. Critically, these branches share the query, key, and value (QKV) projections, introducing only a minor increase in parameter count (+4.99%). The linear attention output is passed through a learned projection and into a scalar gating mechanism, which adaptively modulates its contribution on a per-sample and per-layer basis. This allows the model to finely balance local (sparse) and global (linear) dependencies even at high sparsity.
The design is applicable to both static (e.g., sliding-window) and dynamic (e.g., Top-K) sparse patterns, with linear attention employing a ReLU kernel and 3D RoPE for spatial-temporal modeling. The gating mechanism is implemented as a linear layer followed by a sigmoid activation and spatial/temporal averaging to yield a per-layer scalar.
Analysis of Sparse Attention and Hybrid Limitations
While static sparse masks (such as sliding window) exploit locality and are hardware-friendly, their receptive field grows sub-optimally with depth, leading to limited context aggregation and performance loss at high sparsity. Dynamic sparse strategies like Top-K optimize informativeness per sample but are computationally involved to train and deploy, especially at extreme sparsity levels (≥ 80%). Despite parameter-efficient fine-tuning approaches like LoRA, empirical results show that neither can reliably recover performance to that of dense models under severe sparsity, especially in scenarios with limited fine-tuning data (e.g., 2k videos) and low compute budgets. This is evidenced by persistent generative artifacts such as prompt-inconsistent duplications and temporal drift.
The hybridization with linear attention provides high-bandwidth, low-rank global context, but its uncontrolled influence can degrade training stability and output quality. The gating mechanism in SALAD is therefore essential: ablation studies demonstrate that both static and constant-scale fusion fail to exploit the synergy between local and global dependencies as effectively as the learned input-adaptive gating.
Empirical Results and Quality-Efficiency Trade-off
The framework achieves 90% sparsity and a 1.72× end-to-end inference speedup on video generation workloads while attaining aggregate VBench scores (sum of subject/background consistency, image/text consistency) close to a dense baseline.
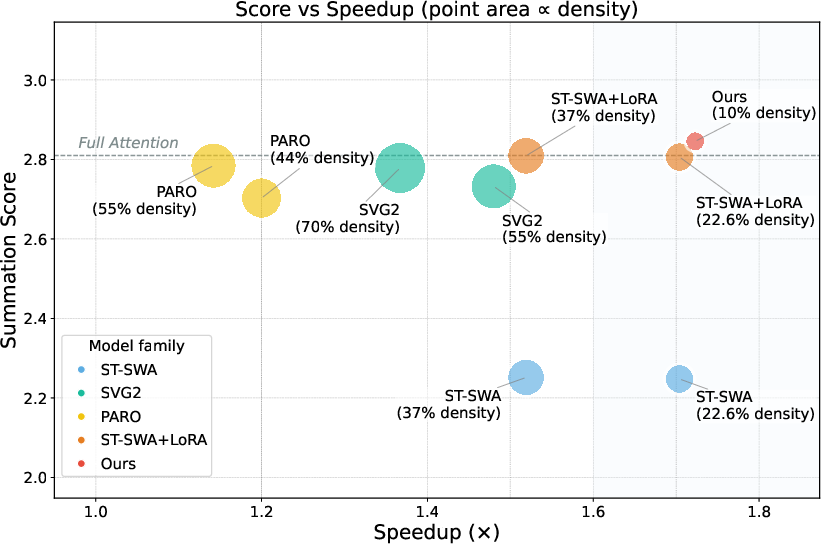
Figure 1: Comparison of SALAD and alternative sparse attention methods on the quality–efficiency trade-off curve. Point size inversely proportional to computational density. Summation scores (VBench) reflect overall video generation quality.
SALAD outperforms training-free sparse methods (e.g., SVG2, PARO) and LoRA-finetuned sparse attention baselines across all quality metrics in the high-sparsity regime. Notably, LoRA-tuned sparse models see irreversible declines in subject/background consistency and text adherence as sparsity increases beyond 80%, whereas SALAD maintains comparable or better consistency and fidelity. Furthermore, qualitative and quantitative results show elimination of instance duplication and improved global coherence relative to sparse/LoRA alone.

Figure 2: Illustrative samples—full attention reference, sparse attention (sliding window), and LoRA-tuned sparse attention. LoRA partially recovers detail but generation artifacts and inconsistencies remain at high sparsity.
Training efficiency is another key result: SALAD requires only 1,600 fine-tuning steps on 2k open-source video samples, an order of magnitude less compute than recent alternatives (e.g., SLA, VSA, VMoBA).
Ablation and Mechanistic Analysis
Systematic ablations reveal several key findings:
- Projection and Gate Integration: Adding projection and gating to the linear branch is essential to reconcile the value range and functional contributions of parallel attention outputs. Shared QKV/projection weights further improve parameter efficiency with little or no quality loss.
- Gate Dynamics: The gating value typically ranges between 0.1–0.4, reflecting optimal balance between sparse and linear components for most video sequences. Fixed (static) gate values or projection-only variants yield either underutilization or uncontrolled dominance of one branch, impairing performance.
- Branch Dropping: Selective dropping of linear branches (20% with highest gate magnitude) can further accelerate inference without harming quality, indicating practical leeway for deployment optimizations.
- LoRA Comparisons: Incrementally increasing LoRA rank does not improve—and intermittently reduces—fidelity for ultra-sparse attention, whereas SALAD's gated architecture consistently achieves higher subject/background/image quality for equivalent trainable parameter budgets.
Theoretical and Practical Implications
SALAD’s composition demonstrates that high-sparsity attention can be made viable for large-scale generation tasks, provided a lightweight, globally-informative supplement is appropriately regularized. The design generalizes across different sparse attention schemes, and is compatible with structured and dynamic patterns. The gating principle is conceptually extensible to other efficiency/quality trade-off frontiers, such as quantized or compressed transformers in both vision and language.
For practical video synthesis, SALAD enables orders-of-magnitude longer or higher-resolution generations on fixed hardware budgets, with empirical evidence suggesting the potential for further acceleration via adaptive branch reduction.
From a theoretical standpoint, the work highlights the necessity of per-sample, per-layer modulation in hybrid attention architectures: fixed attention fusion weights or simplistic heuristics are suboptimal for complex generative tasks. The integration of linear attention—properly gated—not only recovers global context but also alleviates error modes (e.g., entity duplication, temporal fragmentation) that are otherwise intractable under extreme sparsity.
Future Directions
Further advances may include dynamic, differentiable branch-dropped routing per layer, hardware-aligned sparse scheduling, and exploration of alternative global attention augmentations (e.g., Performer, kernelized attention, or data-driven global token pooling). The principles underlying SALAD’s architecture may generalize to compositional attention for multimodal diffusion, autoregressive sequence modeling, and ultra-long-context video or text synthesis. Additional investigation into optimal gate parameterization, learned branch routing, and explicit quality/efficiency tunability would aid adaptation for downstream industrial-scale deployments.
Conclusion
SALAD demonstrates an efficient, parameter-light solution to the core challenge of scaling diffusion-transformer-based video generation via sparse attention. By coupling ultra-sparse local attention with dynamically-gated, linear global attention, the model attains high sparsity, significant inference speedup, and maintains generation quality without requiring high compute or data expenditures for tuning. Empirical and mechanistic analyses support the efficacy and robustness of this design paradigm for scalable, controllable video synthesis.