- The paper demonstrates that RLVR-based explicit reasoning increases robustness and consistency in ToM tasks through chain-of-thought techniques.
- The methodology uses adapted psychological tests and curated benchmarks to evaluate social-cognitive abilities in large language models.
- Empirical results reveal that reasoning models outperform non-reasoning counterparts, highlighting the need for improved scene modeling and multimodal integration.
Reasoning-Induced Robustness in Theory of Mind Tasks for LLMs
Introduction
The paper "Reasoning Promotes Robustness in Theory of Mind Tasks" (2601.16853) addresses the problem of reliably eliciting social-cognitive abilities—specifically Theory of Mind (ToM)—from LLMs. Recent advances, including the development of reasoning-focused LLMs through reinforcement learning with verifiable rewards (RLVR), raise new questions about the origin and nature of success in ToM benchmarks. This work systematically evaluates both base and reasoning-oriented LLMs, employing adapted machine psychological experiments and curated benchmarks, and quantifies the impact of explicit reasoning (i.e., chain-of-thought, CoT) on model robustness and consistency.
Historically, autoregressive LLMs trained via next-token prediction exhibited parameter-dependent scaling in general language tasks but were limited in systematic reasoning, particularly for tasks requiring recursive social cognition and logical decomposition. Chain-of-thought (CoT) prompting (Figure 1) offered an avenue for improved reasoning by guiding models to produce intermediate step-wise rationales. However, increasing size alone did not yield reliable performance in logical or mathematical domains [weiChainofThoughtPromptingElicits2023].
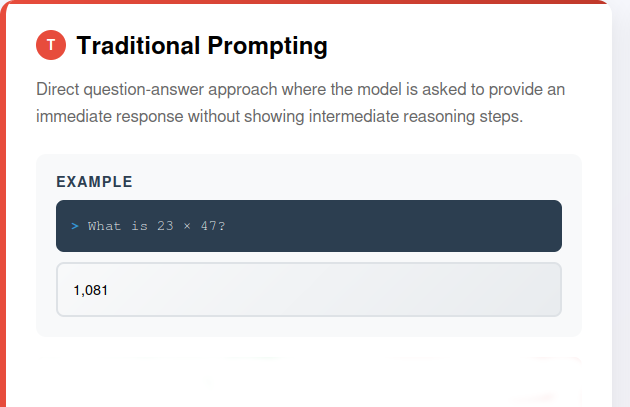


Figure 1: Chain-of-thought prompting: (a) Traditional prompting (no CoT), (b) Few-shot CoT prompting (elicits reasoning at the cost of examples), (c) Zero-shot CoT prompting (elicits reasoning with minimal priming).
The more recent introduction of RLVR training altered optimization targets to reinforce inference chains that are verifiable by reward functions, yielding models such as OpenAI's GPT-5, Anthropic's Claude, and DeepSeek R1. These models prioritize stepwise output and improved "reasoning traces" (i.e., the chains of reasoning revealed in responses), leading to speculation about whether these models have attained fundamentally novel ToM capacities or merely enhanced stability in reasoning under prompt variation [xuLargeReasoningModels2025, plaat_reasoning_2025].
Theory of Mind, defined as the ability to represent and reason about the mental states, beliefs, intentions, and desires of self and others, has been the locus of both developmental psychology and AI evaluation since its formalization [premackDoesChimpanzeeHave1978]. False belief tasks, recursive intentionality, and context-modified scenarios represent canonical tests for ToM capacity. Recent LLMs achieved child- and near-adult-level performance in these tasks [streetLLMsAchieveAdult2024], but their success remained fragile under prompt modifications or adversarial settings [ullmanLargeLanguageModels2023].
Materials and Experimental Design
Model Properties
The study evaluates models with explicit differences in their reasoning properties (i.e., whether reasoning can be toggled on/off, whether reasoning steps are visible, and whether temperature is configurable for reproducibility). In comparative experiments, the ability to disable or elicit explicit thinking tokens is critical for attributing performance gains to reasoning itself versus architectural or data-related confounds.
Psychological and Benchmarking Protocols
Four classes of psychological tests adapted from machine cognition literature are used:
- First- and second-order Sally-Anne tests (false belief and recursive belief attribution)
- Strange Stories (evaluation of intention, sarcasm, double-bluff, and non-literal reasoning)
- Imposing Memory (tests for tracking perceptions and intentionality beyond mere fact recall)
- Modified ToM tasks (variants designed to probe fragility, as identified in prior work [ullmanLargeLanguageModels2023])
Scoring is normalized: $0$ (incorrect), $1$ (partial/uncertain), $2$ (correct with reasoning). Benchmark results are sourced from established ToM datasets such as FANToM, BigToM, ParaphrasedToMi, and MMToM-QA [kimHypothesisDrivenTheoryofMindReasoning2025].
Prompting Methodology
Experiments include both zero-shot and explicit CoT-prompts with reasoning toggled where possible (Figure 2). For models supporting contextual chaining, previous reasoning outputs are supplied as additional context, matching realistic usage paradigms.
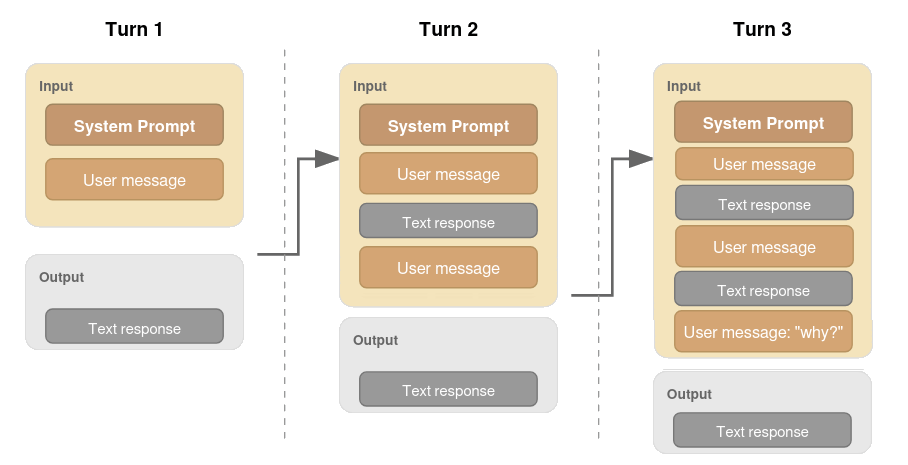
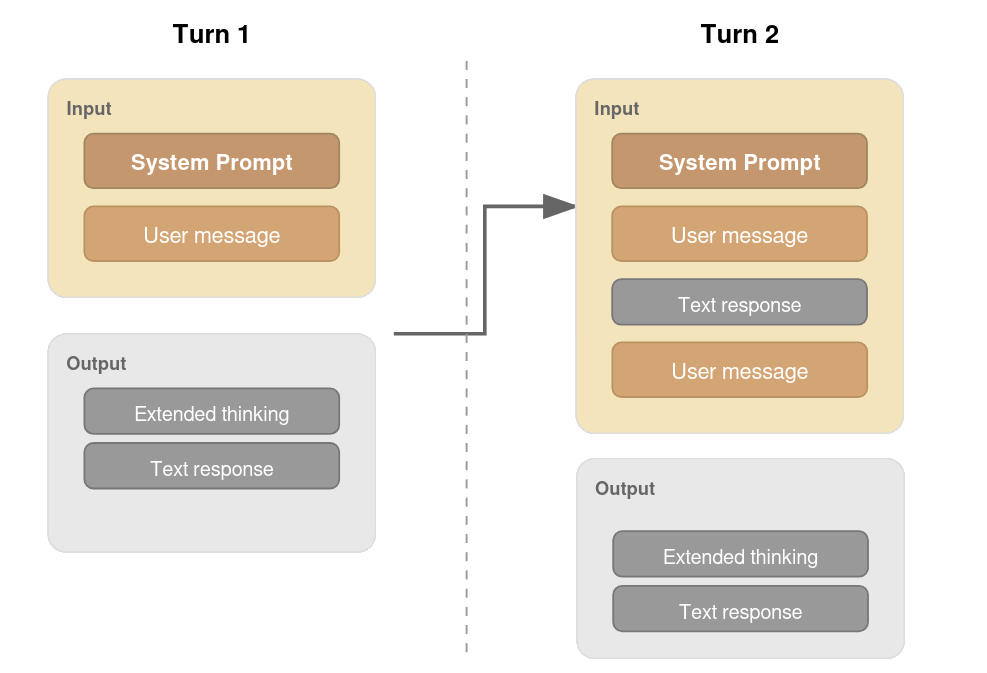
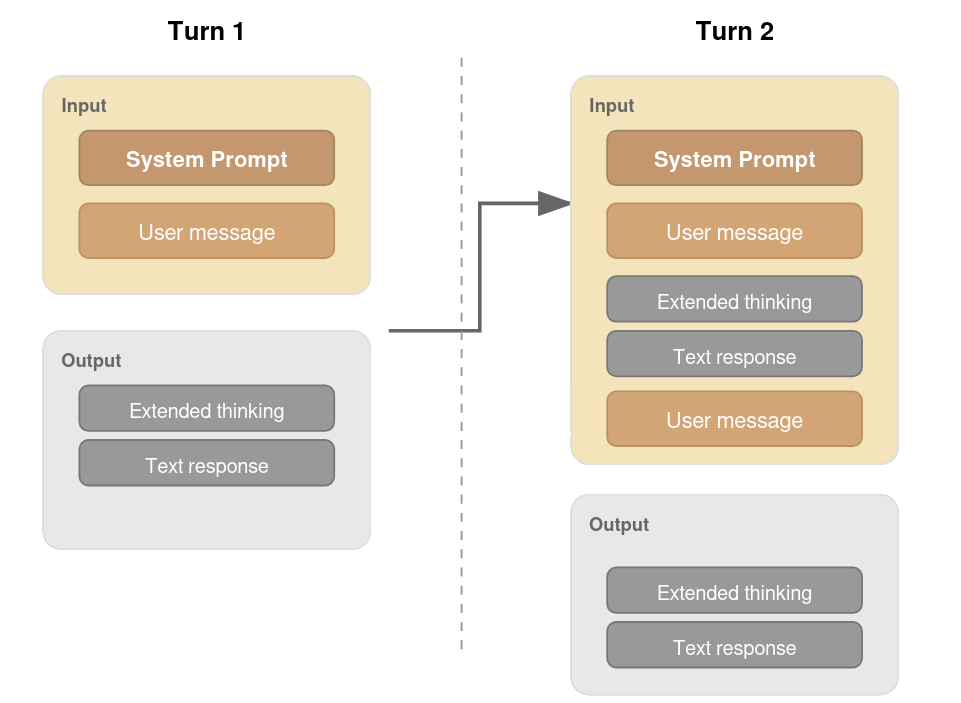
Figure 2: Prompting flows for Sally-Anne: (a) No reasoning model, (b) Reasoning model, (c) Claude's interface with explicit context carrying.
Empirical Findings
Psychological Tests
Sally-Anne (SA1, SA2): Reasoning models, with or without explicit thinking, achieve perfect normalized scores (1.00) across the first and second order tasks. Non-reasoning models display isolated errors due to merging of character knowledge—consistent with lack of robustness rather than fundamental inability.
Strange Stories: Across lie, pretend, joke, whitelie, and misunderstanding categories, models universally achieve perfect scores. Slight reduction is observed in sarcasm and double-bluff, where incomplete mental modeling or absence of scene visualization impedes optimal inference. Notably, toggling explicit reasoning in Claude yields no difference—story complexity appears insufficient to create divergent solution paths.
Imposing Memory: Reasoning models outperform their non-thinking counterparts, particularly in higher-order intentionality queries. Most errors pertain to failures in discriminating between factual recall and mental-state inference, supporting the claim that reasoning increases inference consistency.
Prompt Modifications: In stress-test scenarios, RLVR-trained models are significantly more robust to adversarial or trivial prompt changes. Two variants (requiring visual/relational inference) remain challenging for all evaluated models, possibly due to the lack of grounded scene representation or semantic heuristics.
Benchmark Analysis
Benchmark results corroborate experimental findings: RLVR reasoning models consistently surpass base and non-reasoning models on ToM datasets. Performance gains are most pronounced in benchmarks measuring robustness across multi-question scenarios (e.g., FANToM). Distilled reasoning models show degradation in true-belief tasks, indicating possible trade-offs in generalization.
Mechanisms and Analysis
The evidence supports a bifurcated interpretation: RLVR models do not fundamentally extend the coverage of reasoning patterns available to the base model [yueDoesReinforcementLearning2025]; rather, they improve the stability and reproducibility of solution paths under variable or adversarial prompting. Enhanced inference-time scaling via RLVR yields more consistent access to latent capabilities rather than large-scale architectural innovations.
The analysis of reasoning traces reveals emergent meta-cognitive strategies such as perspective-taking and context filtering—sometimes matching human-designed strategies for ToM elicitation [wilf_think_2023]. However, models sometimes rely on meta-pattern matching (e.g., identifying "this is a classic false belief test"), raising questions about the separation of genuine ToM inference from heuristic recognition.
Limitations
- The study does not fully quantify the magnitude of robustness improvements across a wide range of models and base configurations. Pass@k analyses and direct comparisons to non-RLVR scaling approaches are needed.
- Distillation effects, memory hallucinations, and non-veridical reasoning traces confound interpretation [chenReasoningModelsDont2025].
- Benchmarks often lack coverage for grounded scene understanding and multimodal integration, which are critical for certain classes of ToM failures.
Implications and Future Directions
The findings have clear implications for theory and application. RLVR training offers a practical avenue for increasing robustness and reliability of ToM inference in user-facing LLMs. For social agents, safety-critical deployments, and educational interfaces, stable social reasoning is preferable to brittle heuristic matching.
Theoretically, the results suggest that future improvements in ToM performance may depend more on advances in scene modeling, agent representation, and multimodal fusion than on further scaling or reward shaping alone. Novel architectures capable of integrating temporal and spatial information (e.g., TimeToM [houTimeToMTemporalSpace2024]) may be required to overcome current limitations in visual-relational reasoning.
Conclusion
Across psychological experiments and benchmarks, reasoning-oriented LLMs produce more robust and consistent outputs in Theory of Mind tasks compared to base models and non-reasoning peers. The primary advancement induced by RLVR training is an increase in inference robustness and consistency, rather than the emergence of fundamentally new reasoning capabilities. This interpretation reframes prior skepticism regarding LLM failures under prompt modification—they reflect the brittleness of prompt-to-solution routing rather than an absence of latent ToM capacity. Future research should focus on direct quantification of robustness under adversarial settings, exploration of multimodal ToM reasoning, and more granular dissection of reasoning trace fidelity.