iFSQ: Improving FSQ for Image Generation with 1 Line of Code
Abstract: The field of image generation is currently bifurcated into autoregressive (AR) models operating on discrete tokens and diffusion models utilizing continuous latents. This divide, rooted in the distinction between VQ-VAEs and VAEs, hinders unified modeling and fair benchmarking. Finite Scalar Quantization (FSQ) offers a theoretical bridge, yet vanilla FSQ suffers from a critical flaw: its equal-interval quantization can cause activation collapse. This mismatch forces a trade-off between reconstruction fidelity and information efficiency. In this work, we resolve this dilemma by simply replacing the activation function in original FSQ with a distribution-matching mapping to enforce a uniform prior. Termed iFSQ, this simple strategy requires just one line of code yet mathematically guarantees both optimal bin utilization and reconstruction precision. Leveraging iFSQ as a controlled benchmark, we uncover two key insights: (1) The optimal equilibrium between discrete and continuous representations lies at approximately 4 bits per dimension. (2) Under identical reconstruction constraints, AR models exhibit rapid initial convergence, whereas diffusion models achieve a superior performance ceiling, suggesting that strict sequential ordering may limit the upper bounds of generation quality. Finally, we extend our analysis by adapting Representation Alignment (REPA) to AR models, yielding LlamaGen-REPA. Codes is available at https://github.com/Tencent-Hunyuan/iFSQ

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a simple way to improve how computers turn images into compact codes that models can learn from and generate with. The method is called iFSQ. It fixes a problem in a popular technique (FSQ) so that both types of image generators—those that work step by step with discrete “tokens” (autoregressive models) and those that gradually refine a noisy image with continuous features (diffusion models)—can use the same kind of input. This makes comparisons fair and reveals clearer insights about which approach works better and why.
Key Questions
Here are the main questions the paper asks and answers:
- Can we fix FSQ with a tiny change so it uses all its code “slots” evenly without hurting image quality?
- With a unified tokenizer (iFSQ), where is the best balance between using discrete tokens and continuous features?
- If both model types use the same tokenizer, which one learns faster and which one reaches better final quality?
- Can we speed up autoregressive models by aligning their internal features with a strong vision model (REPA), and how deep in the network should we align?
How the Method Works (in Simple Terms)
First, some everyday explanations for the technical parts:
- Tokenizer: Think of a tokenizer as a translator that turns an image into a compact set of numbers (codes) that a model can understand. Some models need “discrete” codes (like fixed labels), others use “continuous” features (smooth values).
- Quantization: Imagine you have a long ruler and you round every measurement to the nearest mark. Quantization does that to each feature—rounding to a fixed set of levels so it fits into neat bins.
- FSQ (Finite Scalar Quantization): A simple way to quantize each feature dimension by rounding to equally spaced levels. No big “codebook” to look up—just rounding on a grid.
- Activation function: A little math function that squashes values into a limited range (here, between -1 and 1). Original FSQ uses tanh for this.
The problem with vanilla FSQ:
- Real model features usually follow a “bell curve” (many values near the middle, fewer at the edges).
- FSQ uses equal spacing between levels. Because the data pile up in the center, the middle bins get crowded and the side bins are almost empty—like a theater where everyone sits in the middle and the edge seats are wasted. This “activation collapse” wastes information and can lower variety in generated images.
The one-line fix (iFSQ):
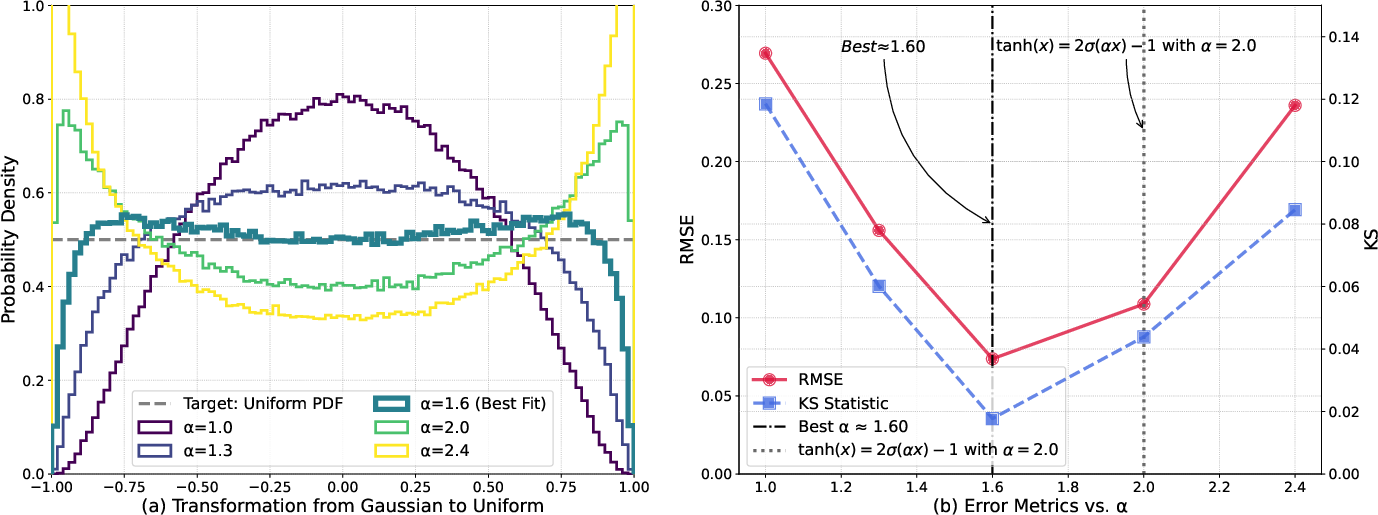
- Replace tanh with a slightly different squashing function that spreads values evenly across the -1 to 1 range: .
- In code, that’s simply:
1
z = 2 * sigmoid(1.6 * z) - 1
- Why this helps: If the outputs are spread evenly (uniformly), every bin gets used about equally. You keep the nice, even spacing (good for accuracy) and also get even usage (good for information).
Two ways the unified tokenizer helps:
- Continuous for diffusion: You round to the grid, then map back to smooth values for denoising. It’s like compressing and then lightly expanding again.
- Discrete for autoregression: You combine the rounded levels into a single integer index, so the model can predict tokens step by step—no codebook lookup needed.
What They Found
Below is a short, plain-language summary of the results and why they matter:
- iFSQ fixes the “crowding in the middle” problem:
- It uses all bins evenly (no collapse) while keeping precise reconstruction. This means sharper, cleaner image rebuilding from compressed features.
- It beats the original FSQ in metrics like PSNR/SSIM (precision) and FID (generation quality).
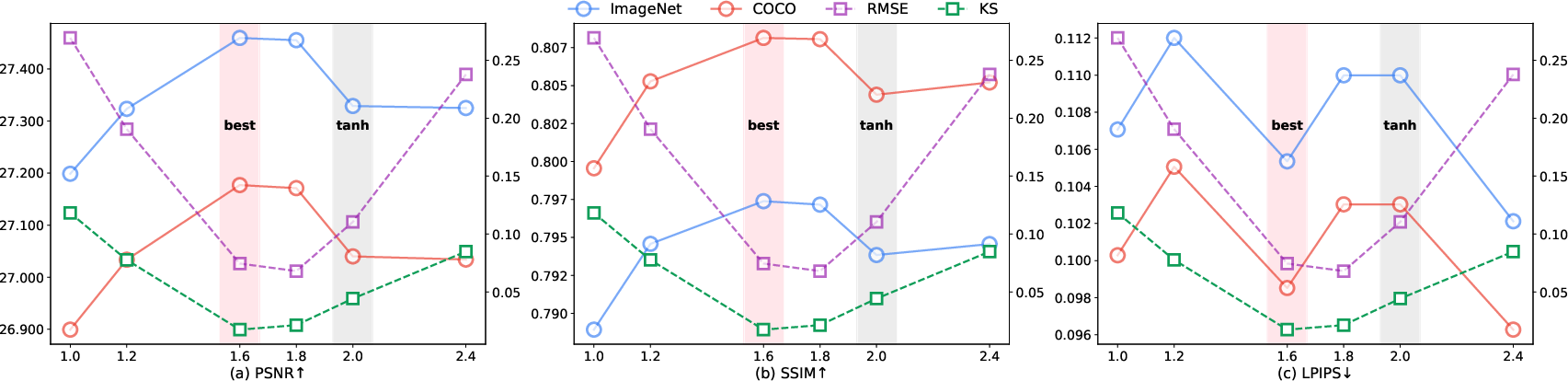
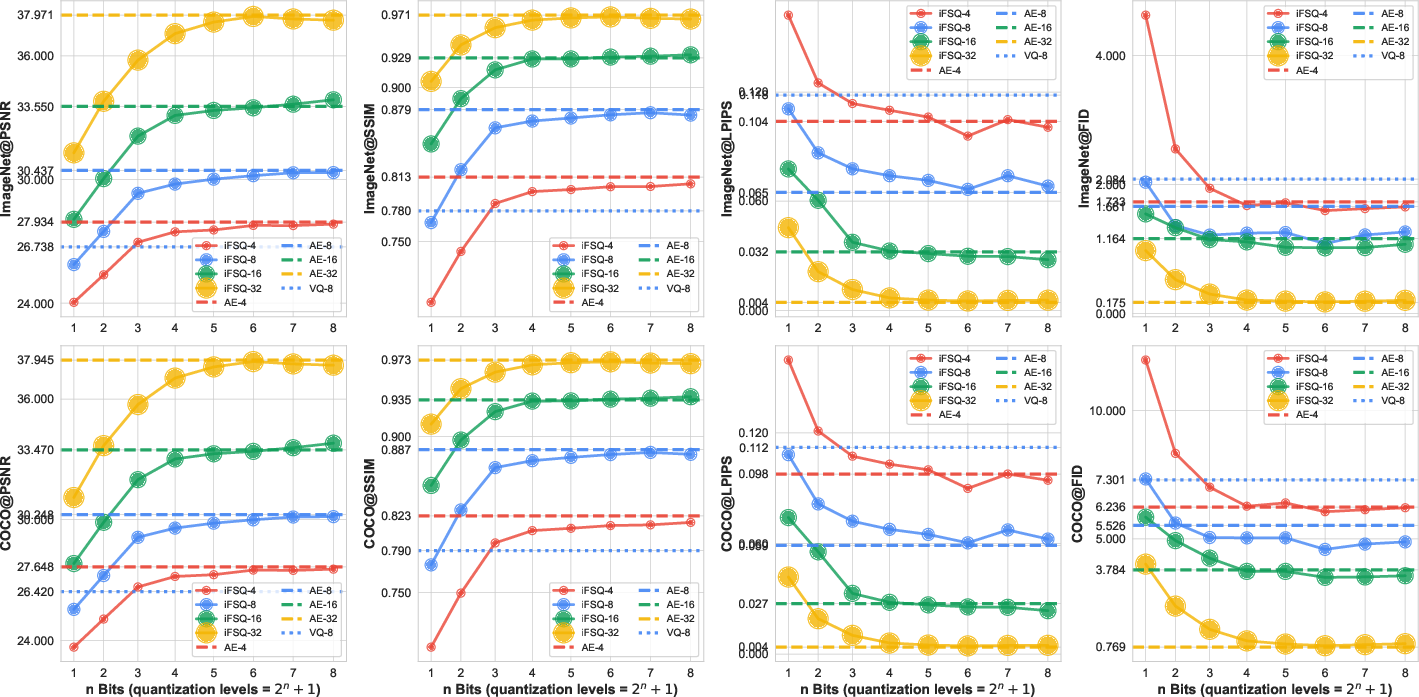
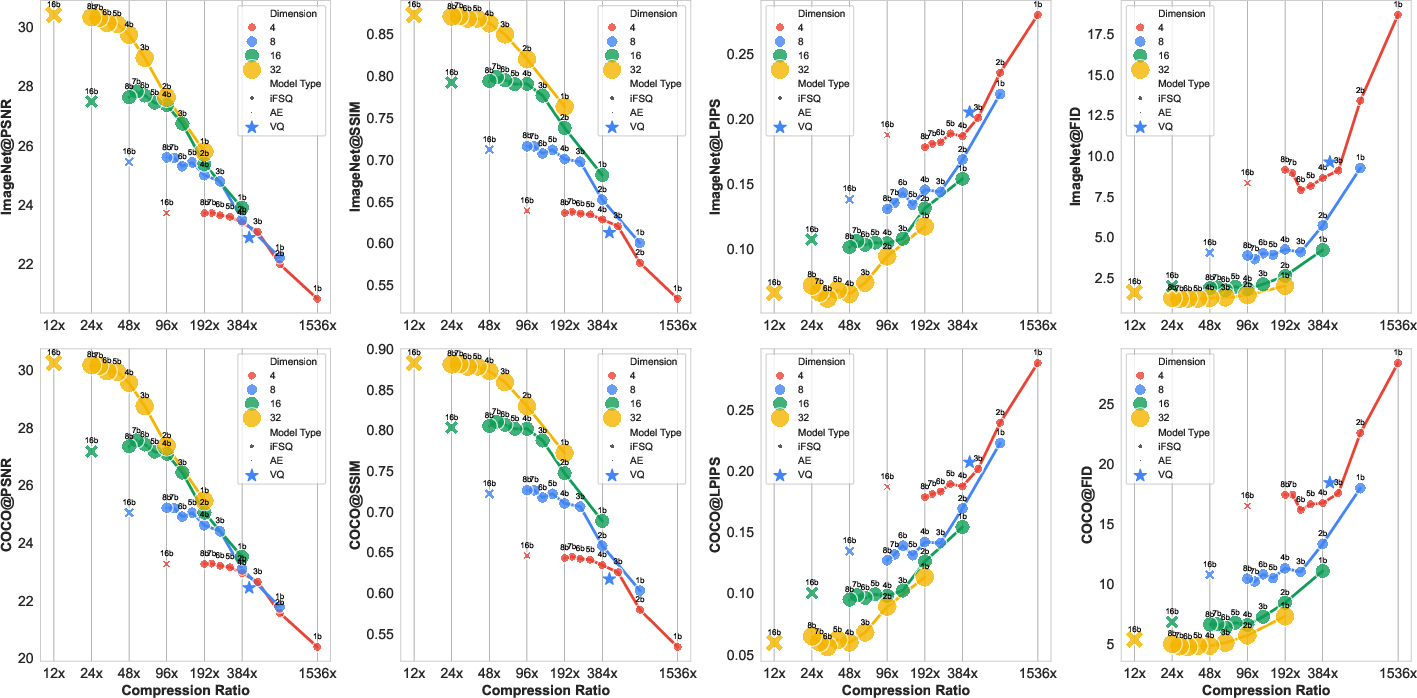
- There’s a “sweet spot” at about 4 bits per dimension:
- Bits are like tiny on/off switches. 4 bits ≈ 16 levels. The authors found that around 4 bits per feature dimension is the best balance between compactness and precision.
- Fewer than 4 bits hurts quality; more than 4 bits often doesn’t help much.
- Fair comparison between model types:
- Early training: Autoregressive (AR) models learn fast at the start.
- Later on: Diffusion models catch up and surpass AR in final quality.
- This suggests that AR’s strict step-by-step nature may cap its best possible quality, whereas diffusion’s holistic refinements can push higher.
- iFSQ is practical and efficient:
- It can give diffusion models high quality with stronger compression than standard autoencoders (AE).
- It can help AR models (like LlamaGen) perform better than using a typical VQ tokenizer under similar conditions.
- REPA for AR (called LlamaGen-REPA):
- REPA aligns the model’s internal features with a strong pre-trained vision model (DINOv2), nudging the network to learn high-level semantics earlier.
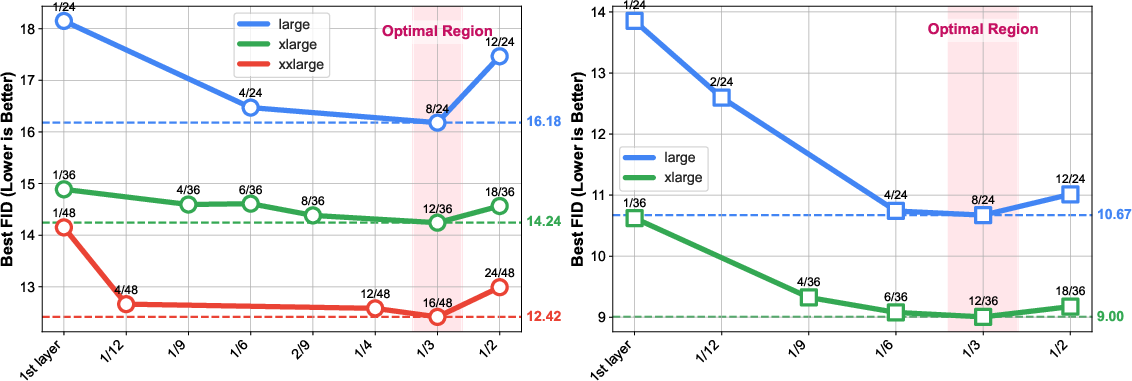
- Best results happen when aligning about one-third deep into the network (e.g., layer 8 out of 24).
- AR models benefit from stronger alignment weight (coefficient around 2.0), more than diffusion models typically need.
Why It Matters
- A unified bridge between discrete and continuous worlds:
- iFSQ lets both AR and diffusion models share the same input representation. This removes a major source of unfair comparison and shows their true strengths.
- Simple, plug-and-play upgrade:
- The fix is just one line of code and adds no extra cost. It’s easy to adopt in existing systems for images, and likely helpful for audio or video too.
- Design guidance for real systems:
- Use around 4 bits per dimension for a strong balance of quality and efficiency.
- Expect AR to be quick learners early, but choose diffusion when peak image quality is the priority.
- If you use REPA for AR, align at about 1/3 of the network depth and use a stronger alignment coefficient.
In short, iFSQ makes image tokenization smarter and fairer, helping researchers and engineers build better generators and compare them honestly—using a tiny change with a big impact.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete directions that the paper leaves open for future research:
- Distributional assumption and robustness
- The mapping choice (2·σ(1.6x)−1) is optimized under a standard normal assumption; no evidence it remains optimal when latents deviate from Gaussian (heavy-tailed, skewed, multimodal) or shift during training.
- No per-channel, per-layer, or per-dataset analysis of latent distributions; it is unclear whether a single global α suffices across layers, resolutions, datasets, or training stages.
- The method lacks pre-normalization (e.g., mean/variance whitening) guarantees; if z is not standardized, the uniformization target can be systematically biased.
- Theoretical guarantees vs. empirical evidence
- The paper claims to “mathematically guarantee” optimal bin utilization and reconstruction precision, but provides no formal rate–distortion analysis or proofs of optimality beyond empirical KS/RMSE under a Gaussian prior.
- No derivation that α=1.6 is globally optimal for minimizing distortion under fixed-rate scalar quantization; the choice is supported by a sweep on synthetic Gaussians, not a general theorem.
- Adaptivity and learnability of the mapping
- α is fixed and globally shared; there is no exploration of learning α (or a parametric monotone map) per-dimension, per-layer, or over training time to track distribution drift.
- No investigation of learned distribution matching (e.g., normalizing flows, learned CDF/quantile transforms, μ-law/A-law companding) that could more precisely equalize bin probabilities than a single-parameter sigmoid.
- Quantization design space not fully explored
- The work focuses on equal-interval scalar quantization; non-uniform (Lloyd–Max), vector/product quantization, residual quantization, or hybrid scalar–vector schemes are not compared.
- Deterministic rounding with a straight-through estimator (STE) is used; alternatives (stochastic rounding, soft-to-hard annealing, Gumbel-softmax relaxations) and their bias/variance trade-offs are not studied.
- Tokenizer expressivity and inter-dimensional dependencies
- FSQ/iFSQ assumes independent per-dimension quantization; cross-channel correlations are ignored, potentially leaving compression/reconstruction gains on the table relative to vector quantizers.
- No analysis of how iFSQ interacts with perceptual/adversarial reconstruction objectives (e.g., LPIPS, GAN losses), or whether it co-optimizes semantic fidelity under such losses.
- AR indexing and statistical properties
- Flattening indices to a single base-L scalar yields an implicit codebook of size Ld; the token frequency distribution, long-tail effects, and resulting AR perplexity are not characterized.
- No study of whether alternative token encodings (e.g., mixed-radix/grouped indices, factorized emissions) improve AR learnability or mitigate rare-token prediction issues.
- “4 bits per dimension” sweet spot: scope and generality
- The 4-bit optimum is shown on ImageNet/COCO under specific models and compression settings; it is unclear if this holds across datasets (e.g., high-frequency textures), higher resolutions (≥1024), or different spatial compression factors.
- No sensitivity study of the sweet spot with respect to model size, tokenizer depth/width, latent dimensionality, or training budgets.
- Benchmarking AR vs diffusion: fairness and coverage
- Compute fairness is only partially controlled (iterations, FLOPs); the impact of diffusion sampling steps, AR decoding length, and inference-time compute/latency is not normalized.
- Results are limited to ImageNet-scale class-conditional or unconditional generation; no evaluation on text-to-image, long-horizon compositionality, or data-scarce regimes, which could change the crossover conclusion.
- Metrics focus on FID/gFID; precision–recall trade-offs, CLIP-based alignment, human preference studies, and robustness metrics are missing.
- Rate–distortion and actual bitrate
- “Bits per dimension” and compression ratio are proxies; there is no measurement of realized bitrate under an entropy model (e.g., bits-per-pixel with arithmetic coding), nor rate–distortion curves across tokenizers.
- Bin utilization is discussed, but not linked to achievable entropy (token perplexity) and actual coding efficiency in practice.
- Robustness and generalization
- No evaluation under distribution shift (corruptions/OOD), domain-specific imagery (medical, satellite), or data augmentations to test stability of the uniformization and reconstruction.
- Generalization to other modalities (audio, video) is claimed plausible but untested; the effect of temporal correlations on iFSQ’s scalar design remains an open question.
- Optimization and training dynamics
- The impact of the sigmoid mapping on gradient saturation near tails and its interaction with STE noise is not analyzed; potential training instabilities or slower convergence at extreme activations remain unknown.
- No exploration of curriculum strategies (e.g., annealing α, progressive bits K) that might further stabilize training or improve the accuracy–rate trade-off.
- REPA for AR: scope and side effects
- REPA is validated with DINOv2-B only; the effect of different teachers (self-supervised vs supervised), teacher scales, or multi-teacher ensembles remains unexplored.
- The “1/3 depth” alignment rule is empirical; a mechanistic or theoretical explanation for why the optimal alignment depth scales with network depth is missing.
- Potential trade-offs of strong alignment (e.g., over-regularization, reduced diversity, mode collapse in AR generation) are not quantified beyond FID, nor are effects on token-level perplexity.
- Practical deployment considerations
- Memory/compute implications of very large implicit codebooks for AR (Ld) are not discussed; strategies for efficient caching, sampling, or factorized decoding are open.
- The claim of “no inference latency” holds for replacing tanh with sigmoid, but the end-to-end costs (tokenizer + generator) under various K, d, and compression settings are not profiled.
These gaps suggest concrete follow-ups: learnable or flow-based uniformization, non-uniform/vector quantization comparisons, entropy-coded bitrate evaluation, broader and fairer AR–diffusion benchmarking (including inference-time costs), theoretical rate–distortion analysis of the mapping, per-channel adaptive α, robustness studies, and principled explanations for the observed “4-bit sweet spot” and the “1/3 depth” REPA rule.
Practical Applications
Immediate Applications
Below are concrete ways practitioners can use the paper’s findings and methods today, along with sectors, candidate tools/workflows, and feasibility notes.
- Drop-in upgrade for FSQ-based tokenizers to improve fidelity and bin utilization
- Sectors: software/AI infrastructure, vision ML, media
- What to do: replace tanh with y = 2·sigmoid(1.6x) − 1 in existing FSQ tokenizers; retrain/fine-tune the tokenizer and decoder
- Tools/workflows: PyTorch code change (1 line), open-source repo (iFSQ), regenerate latents, evaluate with PSNR/SSIM/LPIPS/FID
- Assumptions/dependencies: latent activations approximately Gaussian; retraining the tokenizer/decoder is typically required; benefits depend on data/domain
- Unified benchmarking of AR vs. diffusion models using the same tokenizer
- Sectors: academia, industry R&D, benchmarking consortia
- What to do: adopt iFSQ as a shared tokenizer to compare AR (e.g., LlamaGen) and diffusion (e.g., DiT) fairly
- Tools/workflows: plug iFSQ into both pipelines; report FID/gFID under identical recon constraints; use provided basis-index mapping for AR
- Assumptions/dependencies: both model families train on the same iFSQ latents; downstream metrics and datasets (e.g., ImageNet/COCO) kept constant
- Bit-budget selection policies for production pipelines (≈4 bits/dimension “sweet spot”)
- Sectors: cloud AI services, mobile apps, content platforms
- What to do: default to ~4 bits/dim when balancing quality vs. compression/compute; use higher bits only if specific quality targets justify it
- Tools/workflows: ablation presets in training configs; QA pipelines for A/B testing quality vs. latency; compression-ratio reporting
- Assumptions/dependencies: optimality around 4 bits observed on ImageNet/COCO and specific architectures; may require revalidation on new domains/tasks
- Faster early-iteration prototyping with AR; higher-ceiling final renders with diffusion
- Sectors: creative tools, game/film pipelines, design studios
- What to do: use AR for rapid drafts and diffusion for final outputs within the same iFSQ tokenizer workflow
- Tools/workflows: dual-head generation (AR for quick previews → diffusion refinement); shared tokenizer reduces integration friction
- Assumptions/dependencies: training both heads with a shared tokenizer; compute availability for diffusion in final stages
- Improve AR training via representation alignment (LlamaGen-REPA)
- Sectors: foundation model builders, vision research labs
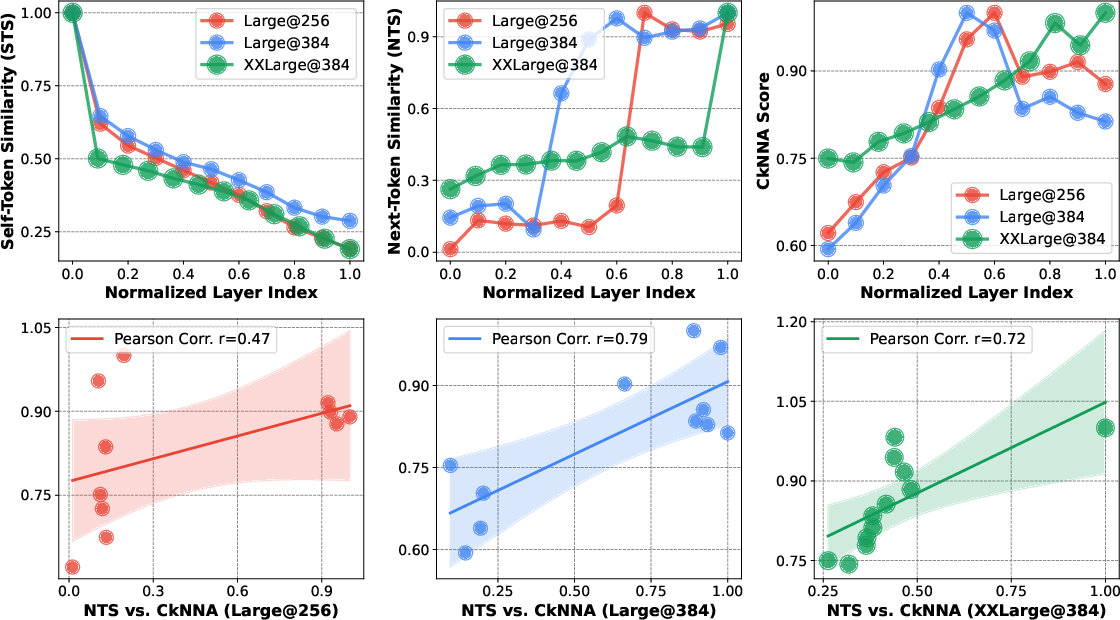
- What to do: align intermediate layers (~1/3 depth) to a strong vision backbone (e.g., DINOv2), with stronger coefficient (λ≈2.0)
- Tools/workflows: add REPA loss at ~one-third network depth; monitor CKNNA/NTS/STS; tune λ and alignment layer
- Assumptions/dependencies: requires suitable teacher model (e.g., DINOv2), extra training cost; optimum depth scales with total layers
- Leaner asset pipelines via learned latent compression
- Sectors: media/CAD/CAM, advertising, internal ML datasets
- What to do: store/transmit iFSQ latents at higher compression (e.g., CR≈96) with quality close to AEs; decode on-demand
- Tools/workflows: integrate iFSQ encoder/decoder; storage tiering; bandwidth-aware streaming of latents
- Assumptions/dependencies: end-to-end acceptance of lossy learned compression; domain-specific quality gating; security/privacy reviews
- Edge–cloud split for on-device generation
- Sectors: mobile, AR/VR, robotics
- What to do: run tokenizer on-device, transmit compact iFSQ latents to cloud for heavy generation, or vice versa
- Tools/workflows: encode–transmit–generate–decode pipeline; use base-L indices for AR when needed
- Assumptions/dependencies: connectivity constraints; encoder/decoder footprint compatible with device NPUs; privacy constraints on latent transmission
- Dataset storage and training throughput improvements
- Sectors: MLOps, data engineering
- What to do: pre-encode datasets into iFSQ latents to reduce I/O and accelerate training
- Tools/workflows: dataset preprocessing jobs; dataloaders reading latents; reproducible mapping back to images for evaluation
- Assumptions/dependencies: retraining tokenizers and decoders; careful versioning to prevent latent/data drift; acceptable lossiness for downstream tasks
- Better monitoring and debugging of quantization health
- Sectors: ML quality engineering, model monitoring
- What to do: track bin utilization, KS, and RMSE metrics during training to detect activation collapse or mismatch
- Tools/workflows: training dashboards; alerts on utilization drop; periodic reconstruction audits
- Assumptions/dependencies: metrics calibrated to the domain; thresholds set from internal baselines
Long-Term Applications
The following applications require additional research, scaling, engineering, or standardization.
- Standardized tokenizer benchmarks for regulatory and industry evaluations
- Sectors: policy, standards bodies, auditing labs
- Vision: use iFSQ-like unified tokenizers to decouple tokenizer effects from generator comparisons in certification or public benchmarks
- Tools/products: MLPerf-like suites for generative models; disclosure templates (tokenizer bits, CR, reconstruction metrics)
- Assumptions/dependencies: community consensus; dataset coverage beyond ImageNet/COCO; governance of synthetic media quality claims
- Multi-paradigm generative systems with a single tokenizer
- Sectors: creative suites, foundation model platforms
- Vision: one iFSQ tokenizer powering both AR (drafting) and diffusion (refinement) heads in a single product
- Tools/products: dual-head inference APIs; scheduler that routes prompts to AR/diffusion based on latency/quality needs
- Assumptions/dependencies: robust training and handover strategies; UX to manage draft→refine transitions; cost controls
- Cross-modal unified tokenization (images, audio, video)
- Sectors: streaming, XR, multimodal AI
- Vision: extend iFSQ-style distribution-matching quantization to audio/video/tokenizers for a universal latent codec across modalities
- Tools/products: unified latent containers; cross-modal editors and multi-stage generators
- Assumptions/dependencies: modality-specific latent distributions may not be Gaussian; α may need retuning; temporal consistency constraints
- Hardware/NPU support for scalar quantization and index arithmetic
- Sectors: semiconductors, device OEMs
- Vision: specialized ops for y = 2·sigmoid(αx) − 1, fast rounding, and base-L index transforms to speed training/inference
- Tools/products: fused kernels on NPUs/ASICs; on-device tokenizers that run at camera rates
- Assumptions/dependencies: sufficient industry adoption to justify silicon; standardized operator definitions across frameworks
- Latent-first cameras and editors
- Sectors: consumer devices, pro creative tools
- Vision: capture/store photos as compact iFSQ latents, support fast on-device edits in latent space, decode only for export
- Tools/products: latent-native photo/video apps; “token edits” for stylistic changes
- Assumptions/dependencies: user/market acceptance of learned lossy codecs; robust, artifact-free decoding; long-term archival reliability
- World models and simulators with bit-controlled perception in robotics
- Sectors: robotics, autonomous systems
- Vision: use ~4 bits/dim iFSQ latents for efficient perception feeds to world models, trading fidelity for speed in planning loops
- Tools/products: policies that adapt bit budgets based on task phase (exploration vs. fine manipulation)
- Assumptions/dependencies: safety-critical validation; domain transfer (industrial, outdoor); integration with control stacks
- Privacy-preserving sharing via controlled bit-rates
- Sectors: healthcare, enterprise collaboration
- Vision: share reduced-bit latents to limit identifiable detail while enabling downstream tasks (e.g., annotation, triage)
- Tools/products: policy-governed export levels; audit trails of latent transformations
- Assumptions/dependencies: rigorous tests that reduced-bit latents sufficiently anonymize; regulatory approvals; risk of reconstruction attacks
- Energy-efficient pipelines and sustainability reporting
- Sectors: cloud providers, sustainability offices
- Vision: report and reduce compute/storage via smaller latents and optimized training strategies (AR early, diffusion late)
- Tools/products: dashboards tying bit budgets to energy/CO2 metrics; procurement policies favoring efficient tokenizers
- Assumptions/dependencies: standardized measurement protocols; workload variability; alignment with organizational ESG targets
- Adaptive bit allocation and learned distribution matching
- Sectors: advanced ML research, AutoML
- Vision: per-channel or per-patch dynamic bit assignment around the 4-bit baseline; learn α or activation forms per-domain
- Tools/products: AutoML loops optimizing bits/α for tasks; controllers that adapt to data shifts
- Assumptions/dependencies: stability of training with dynamic quantization; monitoring to prevent collapse; additional complexity justified by gains
- Safety tooling for high-fidelity generation
- Sectors: trust & safety, policy
- Vision: pair higher-quality diffusion (enabled by iFSQ) with watermarking, provenance tracking, and content moderation
- Tools/products: standardized watermark injection at decode; provenance metadata bound to iFSQ latents
- Assumptions/dependencies: interoperable watermark standards; adversarial robustness; policy alignment across platforms
These applications leverage the paper’s core innovations: a one-line activation change that distribution-matches Gaussian latents to a near-uniform prior for FSQ (iFSQ), the empirical 4-bits-per-dimension operating point, the unified tokenizer benchmark enabling fair AR vs. diffusion comparisons, and practical guidance for representation alignment (REPA) in AR models (e.g., align at ~1/3 depth, higher λ).
Glossary
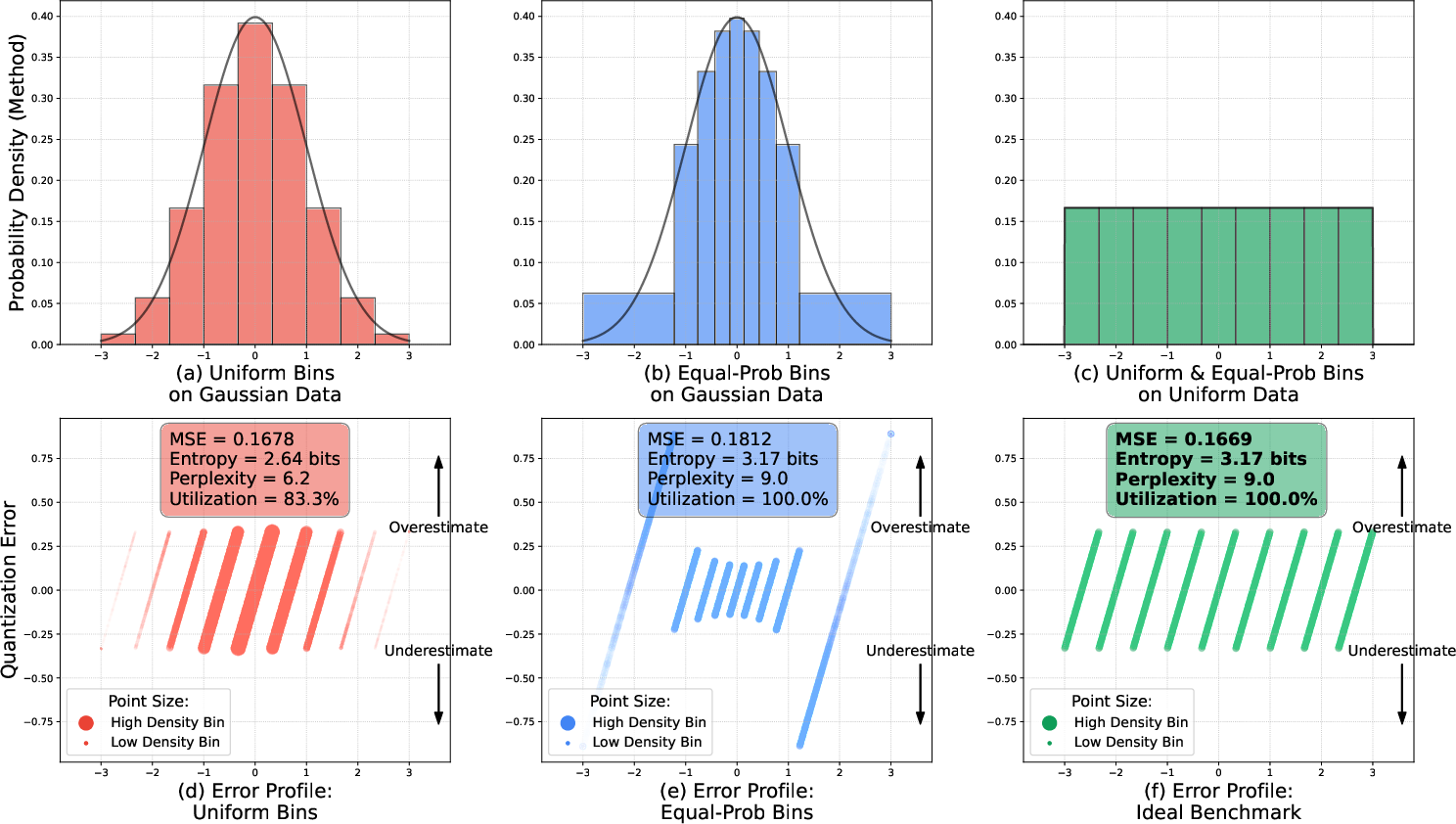
- Activation collapse: Underutilization of quantization bins where activations crowd into a few bins, reducing effective codebook capacity. "This ``activation collapse'' (Utilization: 83.3%) limits the effective size, hindering to learn diverse patterns."
- Adversarial losses (GAN): Training losses derived from Generative Adversarial Networks to encourage realistic reconstructions. "incorporate adversarial losses (GAN)"
- Autoregressive (AR) models: Generative models that predict the next token in a sequence given previous tokens. "Autoregressive (AR) models that predict discrete image tokens"
- AWQ: Activation-aware Weight Quantization, a weight-only quantization method for efficient LLM inference. "Weight-only quantization methods like GPTQ \cite{frantar2022gptq} and AWQ \cite{lin2024awq} are prevalent for accelerating inference."
- Base- expansion: A bijective mapping from multi-dimensional indices to a single scalar index using positional base expansion. "via a bijective base- expansion:"
- Bits per dimension: The number of bits used to represent each latent dimension, controlling discretization granularity. "approximately 4 bits per dimension."
- Classifier-Free Guidance (CFG): A guidance technique in diffusion sampling that does not require class labels during inference. "without CFG."
- CKNNA: A semantic alignment metric used in REPA to compare features with DINOv2 representations. "we utilize CKNNA score to quantify this semantic correspondence"
- Codebook collapse: Degeneration in VQ-based models where many codebook entries are unused. "suffers from codebook collapse"
- Compression ratio (CR): The factor by which data is reduced in size by the tokenizer. "CR denotes the compression ratio."
- Cumulative Distribution Function (CDF): The probability that a random variable takes a value less than or equal to a given value. "Cumulative Distribution Functions (CDFs):"
- Diffusion models: Generative models that iteratively denoise latent variables to produce samples. "diffusion models that denoise continuous latent representations"
- DiT: Diffusion Transformer, a transformer-based diffusion model architecture. "DiT \cite{peebles2023scalable}"
- DINOv2: A family of self-supervised vision models providing strong semantic features for alignment. "pre-trained DINOv2 features"
- Equal-interval quantization: Quantization where bins have equal width across the value range. "Panel (a) shows equal-interval quantization of a standard normal distribution."
- Equal-probability quantization: Quantization where each bin has equal probability mass under the data distribution. "Panel (b) shows equal-probability quantization of a standard normal distribution."
- Entropy regularization: A regularizer encouraging high-entropy (diverse) code usage to avoid collapse. "mitigates collapse via entropy regularization"
- Finite Scalar Quantization (FSQ): A scalar quantization scheme using fixed grids and rounding, enabling both discrete tokens and continuous latents. "Finite Scalar Quantization (FSQ) offers a theoretical bridge"
- FLOPs: Floating point operations, a measure of computational cost. "exhibit approximately 161.04G and 169.65G FLOPs"
- Fréchet Inception Distance (FID): A standard metric for evaluating generative image quality via distribution matching in feature space. "Training Efficiency Comparison: DiT vs LlamaGen (FID vs Compute)."
- Gaussian prior: A normal distribution assumed for latent variables in VAEs/diffusion. "impose a gaussian prior on the latent space"
- GPTQ: A post-training quantization method for transformers focused on weight quantization accuracy. "Weight-only quantization methods like GPTQ \cite{frantar2022gptq} and AWQ \cite{lin2024awq} are prevalent for accelerating inference."
- gFID: FID computed for generated images under a specific evaluation protocol used in the paper. "yields a better gFID (12.76) than AE (13.78)"
- Information entropy: A measure of information content; higher entropy implies more uniform and efficient code usage. "maximizes information entropy (3.17 bits)"
- Kolmogorov–Smirnov (KS) statistic: A nonparametric measure of divergence between two distributions based on their CDFs. "Kolmogorov-Smirnov (KS) \cite{an1933sulla} statistic"
- Latent Diffusion Models: Diffusion models operating in a learned latent space rather than pixel space. "For Latent Diffusion Models (Continuous):"
- Learned Perceptual Image Patch Similarity (LPIPS): A perceptual distance metric correlating with human judgments of image similarity. "perceptual losses (LPIPS) \cite{zhang2018unreasonable}"
- LlamaGen-REPA: The adaptation of REPA to the LlamaGen autoregressive image model to align internal representations. "yielding LlamaGen-REPA."
- Next-Token Similarity (NTS): A metric measuring how features shift toward predicting the next token as depth increases. "Next-Token Similarity (NTS)."
- Peak Signal-to-Noise Ratio (PSNR): A distortion metric quantifying reconstruction fidelity; higher is better. "PSNR and SSIM increase while KS and RMSE decrease."
- Quantization-Aware Training (QAT): Training that simulates quantization effects to improve post-quantization performance. "Other approaches, such as QAT \cite{liu2024llm}, extend this to activation values."
- Rate–Distortion Optimization (RDO): The trade-off framework balancing compression rate (bits) and reconstruction error (distortion). "Rate-Distortion Optimization (RDO) \cite{sullivan2002rate}"
- Representation Alignment (REPA): A training strategy aligning intermediate features with a target representation (e.g., DINOv2). "Representation Alignment (REPA)"
- Root Mean Square Error (RMSE): A standard measure of average squared reconstruction error, square-rooted. "Root Mean Square Error (RMSE) \cite{gauss1877theoria}"
- Self-Token Similarity (STS): A metric quantifying how much a layer’s features retain the input token encoding. "Self-Token Similarity (STS) measures the retention of input encoding"
- Spatial compression: Downsampling factor applied to spatial dimensions to reduce token count/latents. "with 256× spatial compression"
- Straight-Through Estimator (STE): A gradient approximation technique allowing backpropagation through non-differentiable quantization. "relies on the straight-through estimator for gradient approximation."
- Structural Similarity Index (SSIM): A perceptual metric assessing image reconstruction quality; higher is better. "PSNR and SSIM increase while KS and RMSE decrease."
- Teacher forcing: Training scheme for AR models where the ground-truth previous token is fed during training. "teacher-forcing training scheme in autoregressive models."
- Tokenizer: A module producing discrete tokens or continuous latents for generative models. "a unified tokenizer to benchmark AR against diffusion models."
- Uniform prior: A target distribution over bounded activations to ensure equal bin utilization in quantization. "transform latent distributions into a Uniform prior"
- Variational Autoencoder (VAE): A generative model that learns a probabilistic latent space with an encoder-decoder structure. "Variational Autoencoders (VAE)"
- Vector Quantized-VAE (VQ-VAE): A discrete latent model using a learnable codebook and nearest-neighbor quantization. "Vector Quantized-VAEs (VQ-VAE)"
Collections
Sign up for free to add this paper to one or more collections.