PocketGS: On-Device Training of 3D Gaussian Splatting for High Perceptual Modeling
Abstract: Efficient and high-fidelity 3D scene modeling is a long-standing pursuit in computer graphics. While recent 3D Gaussian Splatting (3DGS) methods achieve impressive real-time modeling performance, they rely on resource-unconstrained training assumptions that fail on mobile devices, which are limited by minute-scale training budgets and hardware-available peak-memory. We present PocketGS, a mobile scene modeling paradigm that enables on-device 3DGS training under these tightly coupled constraints while preserving high perceptual fidelity. Our method resolves the fundamental contradictions of standard 3DGS through three co-designed operators: G builds geometry-faithful point-cloud priors; I injects local surface statistics to seed anisotropic Gaussians, thereby reducing early conditioning gaps; and T unrolls alpha compositing with cached intermediates and index-mapped gradient scattering for stable mobile backpropagation. Collectively, these operators satisfy the competing requirements of training efficiency, memory compactness, and modeling fidelity. Extensive experiments demonstrate that PocketGS is able to outperform the powerful mainstream workstation 3DGS baseline to deliver high-quality reconstructions, enabling a fully on-device, practical capture-to-rendering workflow.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making high‑quality 3D models on a smartphone, starting from a short video you take. The technique it uses is called “3D Gaussian Splatting” (think of painting a scene with thousands of soft, colored blobs). Usually, training these models needs a powerful computer with lots of memory. The authors created PocketGS, a system that trains these 3D models directly on a phone in just a few minutes, while keeping the results sharp and realistic.
What questions were the researchers trying to answer?
In simple terms, they asked:
- How can we get reliable 3D information from a quick phone capture without heavy, slow processing?
- How can we start the model in a smart way so it learns fast (because phones don’t have time or memory to waste)?
- How can we redesign the “learning” steps to run well on phone GPUs (the graphics chips in phones), which handle things differently than big desktop GPUs?
How does PocketGS work?
To understand the approach, imagine you’re trying to build a 3D diorama from a stack of phone photos. PocketGS uses three coordinated steps to make this fast and accurate on a phone.
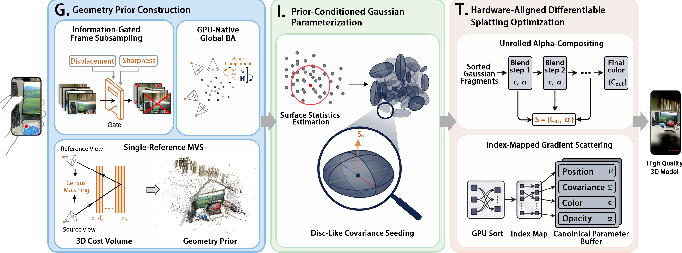
1) Geometry Prior Construction (they call it G)
Goal: Build a clean, helpful 3D “scaffold” from your photos before training the final model.
Everyday explanation:
- Pick the best frames: The system only keeps photos that add new, sharp information. It skips blurry or almost identical frames, so it doesn’t waste time.
- Line up the cameras: It refines where each photo was taken from (the phone’s position and angle) so that all images line up neatly in 3D. This is like straightening and aligning pieces before gluing a model.
- Estimate depth: Using multiple photos, it figures out how far surfaces are, creating a dense point cloud (lots of little dots in 3D space). This gives a solid starting structure.
Why this helps: Phones have limited time and memory, so building a compact, reliable 3D scaffold up front avoids blowing up the model later with too many blobs.
2) Prior‑Conditioned Gaussian Parameterization (they call it I)
Goal: Start the “blobs” in the right shapes and directions, using what the scaffold tells us.
Everyday explanation:
- Instead of starting with identical ball‑shaped blobs everywhere (slow and clumsy), PocketGS creates thin, disc‑like blobs that lie along surfaces (like placing flat stickers on walls and tables).
- It looks at nearby points to estimate the surface’s direction (the normal) and sets blob sizes based on how crowded the points are, so blobs naturally fit the scene’s shape.
Why this helps: Good starting shapes mean the model learns faster and doesn’t waste its limited training time fixing obvious mistakes.
3) Hardware‑Aligned Splatting Optimization (they call it T)
Goal: Redesign the training and rendering steps so they match how phone GPUs work.
Everyday explanation:
- Layering colors (alpha compositing): Rendering mixes many blob layers front‑to‑back. PocketGS makes this process explicit and keeps tiny “notes” about each step, so during learning it can figure out exactly how to adjust each blob.
- Efficient sorting without shuffling: It sorts which blobs should be drawn first by depth, but uses index lists so it doesn’t physically move data around in memory (important on a phone).
- Train entirely on the GPU: It performs all parameter updates on the phone’s GPU, avoiding slow back‑and‑forth with the CPU.
Why this helps: It keeps memory use under control and lets the phone learn smoothly without overheating or slowing down.
What did they find, and why is it important?
Main results:
- Fast on‑device training: PocketGS can train end‑to‑end in about 4 minutes on an iPhone 15 (around 500 iterations), keeping peak memory under 3 GB.
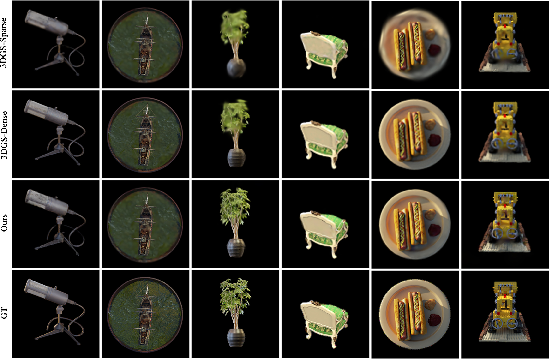
- High visual quality: It often matches or beats powerful workstation (desktop) systems in how realistic the images look. In many tests, PocketGS produced sharper textures and fine details (like leaves, bicycle spokes) and lower LPIPS scores (a metric that means “looks more like the real thing”).
- Better efficiency: On real‑world phone captures (their MobileScan dataset) and common benchmarks (LLFF and NeRF‑Synthetic), PocketGS delivered a strong mix of speed and quality. In geometry‑clean scenes, it was nearly as accurate as very heavy desktop methods while being much faster end‑to‑end.
Why it matters:
- You don’t need a big computer: People can capture and train 3D scenes on a phone quickly and privately.
- Practical 3D content creation: This makes it more feasible to create AR/VR scenes, digital twins, and robot training environments on the go.
What’s the bigger impact?
PocketGS shows that with smart design, phones can handle tasks once reserved for high‑end desktops. This opens the door to:
- Instant “capture‑to‑3D” apps for mixed reality and gaming.
- Faster, more accessible 3D scanning for shopping, education, and cultural heritage.
- On‑device AI techniques that respect battery, memory, and heat limits.
Going forward, similar ideas could make other advanced 3D and vision models train directly on mobile devices, enabling creative and practical tools that anyone can use anywhere.
Knowledge Gaps
Unresolved Knowledge Gaps and Open Questions
The paper proposes a compelling on-device 3DGS training paradigm, but several aspects remain underexplored or uncertain. The following concrete gaps and questions can guide future research:
- Device generalization and portability:
- How does PocketGS perform across diverse mobile GPUs and OSes (e.g., Adreno/Mali on Android, older iPhone generations), given differences in tile sizes, memory bandwidth, and shader capabilities?
- What are the impacts of thermal throttling, energy consumption, and battery drain under typical usage over longer sessions and across devices with smaller RAM (e.g., ≤2 GB)?
- Photometric and radiometric robustness:
- The training objective is unspecified; what loss functions (L1/L2, SSIM, perceptual LPIPS, exposure-robust variants) best support rapid convergence within the 500-iteration budget?
- How robust is the pipeline to exposure/white-balance variation, rolling shutter, and nonlinear camera response (e.g., sRGB gamma)? Is radiometric calibration or exposure compensation necessary on-device?
- Pose and intrinsics calibration:
- The approach assumes ARKit intrinsics/poses and fixes scale via a baseline constraint; how does performance degrade with inaccurate VIO, unknown intrinsics, lens distortion, or rolling-shutter artifacts?
- Can the system self-calibrate intrinsics/distortion and metric scale (e.g., via IMU or learned scale priors) entirely on-device?
- MVS design trade-offs:
- Single-reference cost-volume MVS reduces memory, but how does it affect occlusion handling, thin structures, and large-baseline scenes compared to multi-reference or multi-view aggregation?
- The depth search range is set via 5–95% quantiles; how sensitive is reconstruction to this heuristic in scenes with large depth extents or sparse BA points? Would adaptive multi-scale or hierarchical depth sampling improve robustness?
- Initialization hyperparameters and robustness:
- The prior-conditioned seeding uses fixed
K=16neighbors and a normal-scale ratior_normal=0.3; what is the sensitivity of convergence and quality to these choices, and can they be auto-tuned from local statistics (e.g., curvature, noise levels)? - How robust is PCA-based normal estimation to outliers, sparse neighborhoods, or varying point densities, and would robust estimators (e.g., RANSAC normals, trimmed PCA) yield better results?
- The prior-conditioned seeding uses fixed
- Handling poor priors and failure modes:
- The method relies heavily on MVS; what fallback strategies (e.g., lightweight densification, geometry regularization, or learned priors) can recover when MVS fails in textureless, reflective, or translucent regions?
- Can the pipeline detect and mitigate BA/MVS failure cases on-device (e.g., confidence-based gating, automatic re-capture prompts, or corrective re-localization)?
- Differentiable splatting correctness and stability:
- The unrolled compositing caches only
{C_in, α}; what is the quantitative gradient error versus a full differentiable renderer, and under what conditions does this approximation break (e.g., deep stacks of fragments, high opacity variance)? - Can formal analysis or empirical validation (against workstation-grade differentiable splatting in FP32) bound gradient bias/variance and quantify stability under FP16/mixed precision?
- The unrolled compositing caches only
- View-dependent appearance:
- The parameterization appears to use per-fragment color
cwithout explicit spherical harmonics or learned reflectance; how does performance degrade on glossy/specular surfaces, and can low-cost SH or neural appearance models be incorporated within mobile constraints?
- The parameterization appears to use per-fragment color
- Densification and adaptive capacity:
- While avoiding heavy densification improves efficiency, are there lightweight, on-device compatible densification/pruning strategies that improve coverage when priors are incomplete?
- How can the Gaussian count be adaptively controlled during training to balance memory, speed, and fidelity in a device-aware manner?
- Training budget and scalability:
- What are the quality/time trade-off curves beyond 500 iterations, across resolutions and scene sizes? Can early-stopping or curriculum schedules improve efficiency under strict budgets?
- How does performance scale with image resolution and number of input frames, and what are optimal capture protocols under varying scene complexity?
- Frame gating design:
- The displacement threshold (0.05 m), window size (8 frames/250 ms), and sharpness heuristic are fixed; how sensitive are results to these hyperparameters across small/large scenes, and can gating be adaptive (e.g., scale-aware, texture-aware)?
- Does gating ever over-prune viewpoints needed for view extrapolation or occlusion resolution? How can coverage guarantees be enforced?
- BA formulation details:
- BA assumes a projection model but does not discuss distortion parameters; how much do unmodeled distortion or rolling-shutter effects impact optimization, and can BA be augmented to handle them on-device?
- What is the effect of different robust losses (Huber vs. Tukey), re-triangulation strategies, and outlier filters on the quality/stability under mobile constraints?
- Geometry evaluation metrics:
- The paper reports photometric metrics (PSNR/SSIM/LPIPS) but not geometric accuracy (e.g., depth error, mesh/point cloud fidelity, normal consistency); how does geometry quality correlate with perceptual gains, and can geometry metrics illuminate failure modes?
- Baseline coverage and fairness:
- Comparisons focus on COLMAP-based SfM/MVS with workstation training; how does PocketGS compare to recent fast-training 3DGS/NeRF variants (e.g., hash-grid, Zip-NeRF, RTGS-SLAM) under matched mobile budgets?
- End-to-end time includes workstation reconstruction for baselines but mobile-native reconstruction for PocketGS; a more controlled study under identical device constraints would isolate algorithmic efficiency gains.
- Real-time deployment metrics:
- Beyond screenshots, what are end-to-end on-device FPS, latency, and memory footprints during rendering at different resolutions/scene sizes, and how do these metrics evolve with thermal throttling?
- What is the energy/thermal profile of the capture-to-train-to-render workflow, and can scheduling (e.g., tile-size tuning, kernel fusion) reduce energy cost?
- Scene diversity and edge cases:
- How does the system handle outdoor large-scale scenes, extreme lighting, textureless areas, repeated patterns, glass/transparency, or motion (dynamic objects), which commonly break classical MVS/BA?
- Can PocketGS be extended to dynamic 3DGS (time-varying geometry/appearance) with mobile-friendly optimization and gating?
- Data and code availability:
- The MobileScan dataset is described but not clearly released; standardized, publicly available mobile captures with poses and raw images would enable reproducibility and broader benchmarking.
- Open-source release of the mobile implementation (Metal kernels, app workflow) would allow community validation across hardware and foster further mobile-native 3DGS research.
- Safety and robustness in the app:
- How does the mobile app handle memory pressure from background processes, low-storage conditions, or GPU preemption, and can the pipeline degrade gracefully (e.g., dynamic downscaling, checkpointing) under such constraints?
These gaps suggest concrete avenues for experimentation, algorithmic refinement, and broader validation to solidify PocketGS as a robust, generalizable solution for on-device 3D scene modeling.
Practical Applications
Immediate Applications
Below is a concise set of actionable use cases that can be deployed now, leveraging PocketGS’s demonstrated on-device capture-to-training workflow (∼4 minutes on an iPhone 15, peak memory <3 GB) and its co-designed operators for geometry priors, conditioned initialization, and hardware-aligned differentiable rendering.
- Mobile capture-to-render for e-commerce and marketing (Sector: software, media, retail)
- What: Scan products (shoes, bags, furniture) with a smartphone and produce photorealistic, AR-ready assets directly on device.
- Tools/workflows: PocketGS mobile app or SDK; export to USDZ/GLTF; plug-ins to Unity/Unreal; content management systems ingest Gaussian assets.
- Assumptions/dependencies: Static scenes, sufficient parallax in 50–100 gated frames, modern mobile GPUs (e.g., iPhone 15-class); acceptable photometric conditions; basic scale anchoring for size realism.
- Rapid field capture of digital twins for AEC (Sector: construction, AEC/BIM, energy)
- What: On-site, privacy-preserving scans of rooms, partial façades, equipment for progress tracking or clash checks.
- Tools/workflows: PocketGS SDK integrated in site-capture apps; export assets to BIM viewers; overlay in AR for deviation checks.
- Assumptions/dependencies: Metric consistency requires scale anchoring (fiducial or measured baseline), static or slow-changing environments, adequate lighting.
- Real-estate listing tours (Sector: real estate, media)
- What: Agents produce indoor tours with realistic occlusion and parallax from a phone without cloud reconstruction.
- Tools/workflows: Capture app using information-gated frames; one-click export to listing platforms with embedded WebGL/3DGS viewer.
- Assumptions/dependencies: Stable capture, indoor lighting; tour assembly workflow for multi-room stitching.
- Insurance claims documentation (Sector: finance/insurtech)
- What: High-fidelity on-device 3D capture of damage scenes for faster adjuster review and fraud detection.
- Tools/workflows: PocketGS integrated into adjuster apps; local processing to meet privacy/regulatory requirements; standardized export for back-office review.
- Assumptions/dependencies: Scene static; rough scale validation; adherence to data-retention policies; device thermal budget in field conditions.
- Cultural heritage and museum object digitization (Sector: culture/heritage, education)
- What: Curators and educators digitize artifacts affordably with phone-based, high-perceptual models.
- Tools/workflows: Curatorial capture guides using displacement/sharpness gating; export to educational AR apps or web viewers.
- Assumptions/dependencies: Permission and lighting control; static objects; archival storage and metadata standards.
- Robotics “quick world” modeling for sim and data generation (Sector: robotics, simulation)
- What: Rapid scan of workspaces to produce environments for robot simulation, synthetic data, and perception testing.
- Tools/workflows: Capture with PocketGS; import Gaussian scenes into sim engines; generate synthetic viewpoints to augment training.
- Assumptions/dependencies: Scenes mostly static; known baseline for scale; downstream sim compatibility with Gaussian assets.
- Indie game and VFX asset creation (Sector: gaming, media)
- What: Creators capture props and set pieces as 3DGS assets that render fast and look photorealistic.
- Tools/workflows: Unity/Unreal import; look-dev pipelines with Gaussian materials; fast iteration using on-device updates.
- Assumptions/dependencies: Static props; platform plug-ins for Gaussian rendering; pipeline alignment with rasterization-friendly splats.
- Education and research labs (Sector: education, academia)
- What: Teaching modules for mobile graphics, BA/MVS, and differentiable rendering under real resource constraints.
- Tools/workflows: PocketGS app/SDK; lab exercises replicating on-device BA and MVS; dataset creation in class.
- Assumptions/dependencies: iOS devices (Metal); Android requires Vulkan port; instructor guides for capture hygiene.
- Privacy-preserving AR personalization (Sector: software, privacy/compliance)
- What: Users locally train room models for accurate occlusion and placement in AR apps—no images leave the device.
- Tools/workflows: On-device PocketGS pipeline integrated with ARKit/ARCore; local asset caching; opt-in export.
- Assumptions/dependencies: Stable capture, platform integration; policy alignment (GDPR/CCPA) is simplified by on-device-only processing.
- Location scouting and previsualization (Sector: media/film)
- What: Directors and DPs quickly scan locations; art and camera teams iterate on blocking and lighting plans with photoreal environments.
- Tools/workflows: Phone-based scans; immediate visualization in previz tools that accept Gaussian scenes.
- Assumptions/dependencies: Static sets; lighting variability managed in capture; asset handoff to previz teams.
Long-Term Applications
The following opportunities require further research, scaling, cross-platform porting, or algorithmic advances (e.g., dynamic scenes, relighting, multi-user fusion). They build on PocketGS’s mobile-native foundation but extend capabilities and reach.
- Real-time, continuous on-device training for dynamic scenes (Sector: AR/VR, robotics)
- What: Update Gaussian scenes as objects or lighting move; enable live telepresence or AR occlusion under motion.
- Tools/workflows: Streaming capture with incremental optimization; robust dynamic modeling; thermal-aware schedulers.
- Assumptions/dependencies: New dynamic 3DGS formulations; stable gradients under frequent updates; energy-aware runtime.
- Collaborative multi-user capture and merge (Sector: software, education, AEC)
- What: Several devices jointly capture large spaces; merge into a unified Gaussian scene.
- Tools/workflows: Networked keyframe exchange; distributed BA/MVS; conflict resolution and scale unification.
- Assumptions/dependencies: Synchronization protocols; secure peer-to-peer; robust pose alignment; bandwidth limitations.
- Relightable and editable Gaussian assets on device (Sector: media, e-commerce)
- What: Change lighting and materials post-capture for product visualization and creative editing.
- Tools/workflows: On-device estimation of BRDFs/relightable Gaussians; artist tooling; mobile path/plausible relighting.
- Assumptions/dependencies: New reflectance models and training; compute budgets; validation of appearance consistency.
- Healthcare-grade scanning (Sector: healthcare, policy/compliance)
- What: Patient-specific models (orthotics, prosthetics, wound care) with secure, on-device processing.
- Tools/workflows: LiDAR-assisted capture; scale-calibrated pipelines; HIPAA/GDPR-compliant storage; clinical validation.
- Assumptions/dependencies: Higher metric accuracy and regulatory approval; robust lighting and motion handling; clinician workflows.
- On-robot on-device mapping and planning (Sector: robotics, logistics)
- What: Robots build photoreal digital twins on-board for planning and manipulation with rich appearance cues.
- Tools/workflows: Embedded GPU ports (Jetson-class); SLAM-integrated 3DGS; online BA/MVS; appearance-aware planners.
- Assumptions/dependencies: Portability to diverse GPUs; real-time constraints; dynamic obstacle modeling.
- Drone-based large-scale outdoor capture (Sector: infrastructure, energy, agriculture)
- What: Edge compute on drones for photoreal reconstructions of assets (turbines, bridges, crops) with minimal cloud dependence.
- Tools/workflows: Flight planning with gated frames; onboard BA/MVS; intermittent upload; GIS/BIM integration.
- Assumptions/dependencies: Battery/compute limits; vibration blur; autonomy regulations; cross-device synchronization.
- Standardization of 3DGS asset formats and pipelines (Sector: software, policy)
- What: Interoperable file formats (analogous to USDZ/glTF) for Gaussian scenes to ease toolchain integration.
- Tools/workflows: Open specs; converters (Gaussian↔mesh/NeRF); engine plug-ins.
- Assumptions/dependencies: Community consensus; performance-appearance trade-off standardization; IP/licensing.
- Privacy-first AR cloud with local training and federated sharing (Sector: smart cities, policy)
- What: City-scale maps built from device-local training and minimal, privacy-preserving summaries.
- Tools/workflows: Federated learning for scene descriptors; differential privacy; local-to-cloud compression.
- Assumptions/dependencies: Policy frameworks; secure federated protocols; edge/cloud coordination.
- Energy-aware mobile graphics and training schedulers (Sector: energy, software)
- What: Adaptive pipelines that meet thermal/energy budgets (e.g., pausing, downscaling, tile-aware caching).
- Tools/workflows: OS-level APIs; energy profiling; autotuned caches (forward replay, counter buffers).
- Assumptions/dependencies: OS integration; device telemetry access; user controls for energy/quality trade-offs.
- Consumer pipeline to fabrication (Sector: consumer, manufacturing)
- What: Convert Gaussian assets to printable meshes for hobbyists and rapid prototyping.
- Tools/workflows: Gaussian-to-mesh conversion; watertightness repair; scale calibration; slicer integration.
- Assumptions/dependencies: Robust meshing from splats; tolerance control; device-side preprocessing.
- Automated appraisal and valuation (Sector: finance/proptech)
- What: Photoreal, on-device scans feed condition assessment and valuation models.
- Tools/workflows: Scoring models consume Gaussian scenes; analytics dashboards; audit trails.
- Assumptions/dependencies: Metric accuracy and lighting normalization; standards for evidence admissibility; fairness audits.
- In-device content authenticity and provenance (Sector: policy, media)
- What: Provenance metadata for scanned assets, ensuring trusted capture-to-render lineage.
- Tools/workflows: Secure signing at capture/training; metadata standards; verifiable logs.
- Assumptions/dependencies: Hardware-backed keys; standardization; policy adoption by platforms.
Notes on Assumptions and Dependencies Across Applications
- Hardware: Current implementation targets iOS/Metal; Android/Vulkan support requires porting. Performance assumes tile-based mobile GPUs and ∼3 GB available memory.
- Capture constraints: Static or quasi-static scenes; adequate parallax; gating removes blurred/redundant frames; good lighting conditions improve outcomes.
- Scale/metric accuracy: PocketGS fixes gauge via baseline constraints; applications needing strict metric accuracy should anchor scale and validate.
- Thermal/energy: Minute-scale training budgets (<5 min) rely on thermal headroom; extended sessions require energy-aware scheduling.
- Interoperability: Downstream consumption of Gaussian scenes needs engine plug-ins or converters; standardized formats will ease adoption.
- Privacy/compliance: On-device processing reduces regulatory burden; exporting to cloud or sharing must follow local policies and consent.
Glossary
- 3D Gaussian Splatting (3DGS): An explicit scene representation that models surfaces with 3D Gaussian primitives for fast rasterization and differentiable rendering. "3D Gaussian Splatting (3DGS) \cite{Kerbl2023} is a promising paradigm for high-quality scene modeling, advancing mixed reality \cite{gao2024relightable, liang2024gs}, digital twins \cite{Huang2024_2DGS, Yu2024GOF}, and robotic simulation \cite{escontrela2025gaussgym, zhang2025dynamic}."
- Adam optimizer: An adaptive gradient-based optimization algorithm that maintains first and second moment estimates to stabilize and accelerate training. "ensuring that Adam optimizer states remain aligned with their respective parameters without CPU intervention or redundant memory copies."
- Alpha-compositing: A blending technique that accumulates color by combining incoming color and current fragment color using opacity (alpha). "PocketGS unrolls alpha-compositing into an explicit differentiable pipeline with cached intermediates."
- Anisotropic Gaussians: Gaussian ellipsoids whose spread varies by direction, used to better align primitives with local surface geometry. "Prior-Conditioned Parameterization seeds anisotropic Gaussians by estimating local surface statistics"
- Bundle Adjustment (BA): A joint optimization of camera poses and 3D point positions that minimizes reprojection error to refine geometry and camera parameters. "Treating BA (Bundle Adjustment) and MVS (Multi-View Stereo) as core prior-construction primitives"
- Census Transform: A robust, illumination-invariant local image descriptor based on binary comparisons within a neighborhood. "The matching cost is computed using the Census Transform \cite{fife2012improved} for robustness to illumination changes."
- Cost volume: A 3D tensor of matching costs over discretized depth hypotheses used in multi-view stereo to infer depth. "The MVS module constructs a 3D cost volume by sampling depth hypotheses via census matching to produce a dense geometric scaffold."
- Front-to-back compositing: A depth-ordered blending scheme that composites nearer fragments before farther ones for correct transparency accumulation. "Standard front-to-back compositing follows:"
- Gauge fixing: Constraining degrees of freedom (e.g., global pose and scale) to resolve ambiguities in monocular reconstruction. "Scale-Aware Gauge Fixing."
- Gaussian densification: Increasing the number or density of Gaussian primitives during training to compensate for poor initialization or sparse geometry. "Existing methods compensate by densifying Gaussians, but this raises computation and memory overhead,"
- Hardware-aligned splatting: A rendering and optimization design tailored to mobile GPU architectures to reduce memory traffic and ensure correct gradients. "Hardware-Aligned Splatting implements a mobile-native differentiable renderer"
- Huber loss: A robust loss function that is quadratic near zero and linear for large residuals, reducing sensitivity to outliers. "and is the robust Huber loss."
- Index-mapped gradient scattering: A backpropagation technique that maps gradients from the depth-sorted rendering order back to the canonical parameter layout without physically reordering memory. "index-mapped gradient scattering to ensure stable backpropagation"
- LPIPS: A learned perceptual metric that measures visual similarity between images based on deep network features. "LPIPS: 0.108"
- Multi-View Stereo (MVS): A method that estimates dense depth and reconstructs geometry from multiple overlapping images. "Single-Reference Cost-Volume MVS"
- NeRF (Neural Radiance Fields): An implicit neural representation of scenes that models volumetric density and color as a function of 3D coordinates and viewing direction. "By replacing implicit neural representations \cite{Mildenhall2020} with rasterization-friendly 3D Gaussians"
- Plane sweep: A stereo technique that evaluates matching costs by sweeping hypothetical depth planes through the scene. "Depth is inferred via plane sweep \cite{yang2020mobile3drecon} with Semi-Global Matching aggregation."
- PSNR: Peak Signal-to-Noise Ratio; a fidelity metric measuring reconstruction quality relative to ground truth, higher is better. "Higher is better for PSNR/SSIM, and lower is better for LPIPS/Time."
- Schur complement: A matrix reduction technique that eliminates variables to yield a smaller system, commonly used to solve BA efficiently. "We exploit the sparse block structure via a full GPU Schur complement."
- SE(3): The Lie group of 3D rigid motions (rotation and translation) representing camera poses. " is the pose of camera "
- Semi-Global Matching (SGM): A cost aggregation algorithm for stereo that optimizes disparity with penalties along multiple paths to balance accuracy and efficiency. "with Semi-Global Matching aggregation."
- Structure-from-Motion (SfM): A pipeline that estimates camera intrinsics/extrinsics and reconstructs sparse 3D points from image sequences. "offline SfM \cite{Triggs1999, Schoenberger2016} for pose and sparse geometry,"
- Tile-Based Deferred Rendering (TBDR): A mobile GPU architecture that processes the frame in tiles, deferring shading and reducing bandwidth by caching intermediates in tile memory. "Our differentiable renderer is tailored for Tile-Based Deferred Rendering (TBDR) GPUs."
- Visual-Inertial Odometry (VIO): Motion estimation that fuses visual features with inertial measurements to track device pose. "typically via visual-inertial odometry for pose estimation"
Collections
Sign up for free to add this paper to one or more collections.