- The paper introduces FOCA, a multimodal framework that uses hyperbolic cross-attention to model hierarchical dependencies in malware classification.
- FOCA transforms raw binaries into audio and visual modalities and applies Möbius operations for curvature-aware feature fusion.
- Experimental results on CICMalDroid2020 and Mal-Net demonstrate state-of-the-art performance, with accuracy up to 99.10% and macro-F1 of 98.85%.
FOCA: Multimodal Malware Classification via Hyperbolic Cross-Attention
Introduction
FOCA ("FusiOn with Hyperbolic Cross-Attention") constitutes a significant advancement in multimodal malware classification, introducing a principled framework that leverages both audio and visual modalities extracted from raw binary files. Prior works largely confined modality fusion to Euclidean space, thereby neglecting the intrinsic hierarchical and non-Euclidean nature of relationships between separately extracted representations. By adopting hyperbolic geometry for cross-modal fusion, FOCA models these latent hierarchical dependencies with explicit curvature-aware constraints, which is critical for malware analysis where fine-grained and structural information coexist.
The central claim of the paper is that aligning and fusing representations in hyperbolic space—notably via a tailored Hyperbolic Cross-Attention (HCA) mechanism and M\"obius operations—yields superior performance to traditional Euclidean and concatenation-based methods. Extensive experiments on CICMalDroid2020 and Mal-Net datasets demonstrate consistent outperformance over all established unimodal and multimodal baselines, establishing state-of-the-art results (2601.17638).
Methodology
Raw binaries (APK-dex files) are transformed into two distinct modalities:
- Audio: Raw bytes are interpreted as waveform amplitude values and encoded as .wav files, amenable to direct processing by SOTA self-supervised audio models.
- Visual: The byte stream is mapped onto a 2D image, with bytes assigned as intensity in RGB channels, preserving structure (header, data segment, others) spatially.
This pairing enables exploitation of byte-level and structural information in a complementary, hierarchical manner.
- Audio: Represented by embeddings from Wav2vec2, WavLM, and HuBERT. All encoders are frozen; output features are averaged from the last hidden layer.
- Visual: Represented by embeddings from ResNet-50, VGG-19, and ViT, with features extracted post-global pooling.
FOCA Architecture
FOCA consists of three core hyperbolic operations:
- Projection to Hyperbolic Space: Modality-specific Euclidean embeddings are mapped to the Poincaré ball Bd via the exponential map at the origin.
- Hyperbolic Cross-Attention (HCA): Queries, keys, and values are computed independently for each modality. Cross-attention weights leverage the hyperbolic distance metric, enabling curvature-aware alignment:
αija→v=∑j′exp(−dH(Qi(a),Kj′(v)))exp(−dH(Qi(a),Kj(v)))
Output aggregation employs Möbius addition and hyperbolic scalar multiplication, integrating attended values under the manifold's nonlinearity.
- Hyperbolic Fusion and Back-Projection: The mutually attended outputs are fused in hyperbolic space and mapped back to Euclidean space for downstream classification with MLPs. This curvature-aware fusion captures multi-scale and hierarchical dependencies that are essential for robust malware family discrimination.
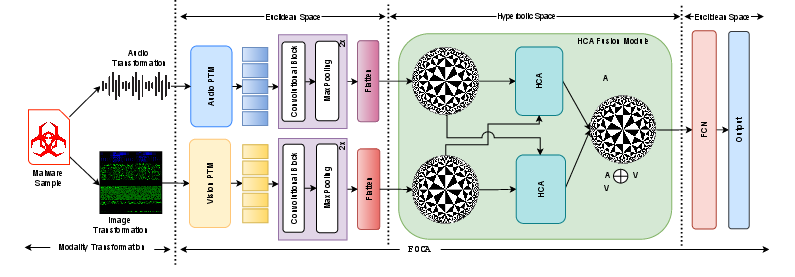
Figure 1: Overview of the FOCA framework, with binary-to-audio/image transformation, modality-specific encoders, hyperbolic projection, cross-attention, and Möbius-based fusion.
Experimental Results
Datasets and Protocol
- CICMalDroid2020: 17,341 APKs, 5 classes (benign + 4 malware).
- Mal-Net: Balanced subset of 8,000 APKs (10 classes) from a large malware image database, mapped to binaries using Androzoo.
Model training adopts 5-fold cross-validation, Adam optimizer, categorical cross-entropy loss, with rigorous regularization via dropout and early stopping.
Comparative Analysis
- Audio outperforms visual representations on both datasets. Among PTMs, the optimal encoder (Wav2vec2 or HuBERT) is data-dependent.
- ViT yields the strongest unimodal visual results.
Multimodal Fusion Methods
Baseline fusions include:
- Concatenation (+): Direct feature concatenation.
- Euclidean Cross-Attention (⊗): Attention between Euclidean representations.
FOCA (⊞) demonstrates strict dominance:
- On Mal-Net, HuBERT ⊞ ViT achieves 82.84% accuracy and 81.72% macro-F1, outperforming all baselines (e.g., HuBERT ⊗ ViT, 76.78% / 74.77%).
- On CICMalDroid2020, HuBERT ⊞ ViT attains 99.10% accuracy and 98.85% macro-F1, representing significant gains.
Visualization and Embedding Analysis
- t-SNE projections of penultimate layer features reveal that FOCA-derived embeddings form more compact and separable clusters than their Euclidean counterparts, indicating improved class discriminability.
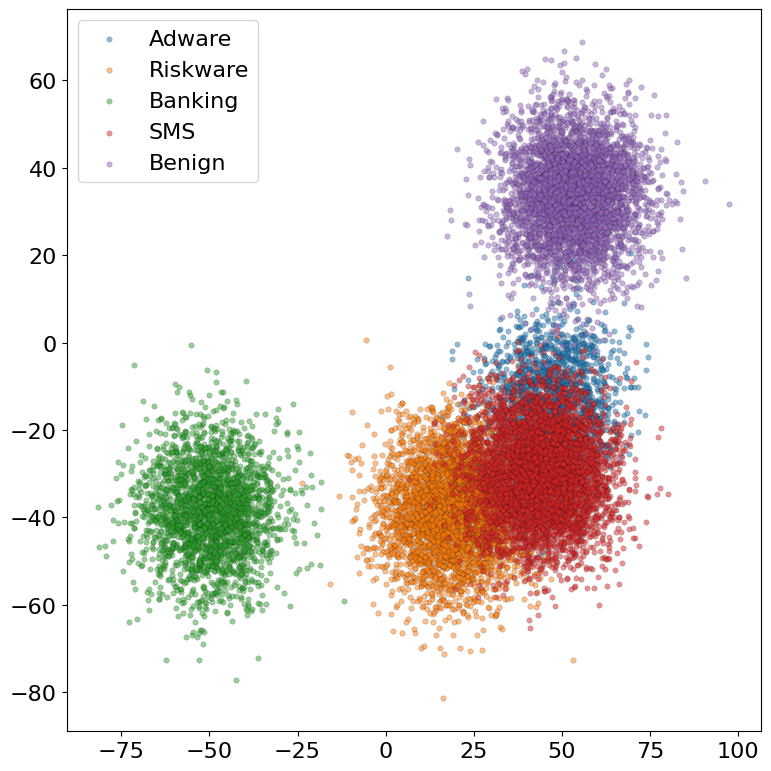
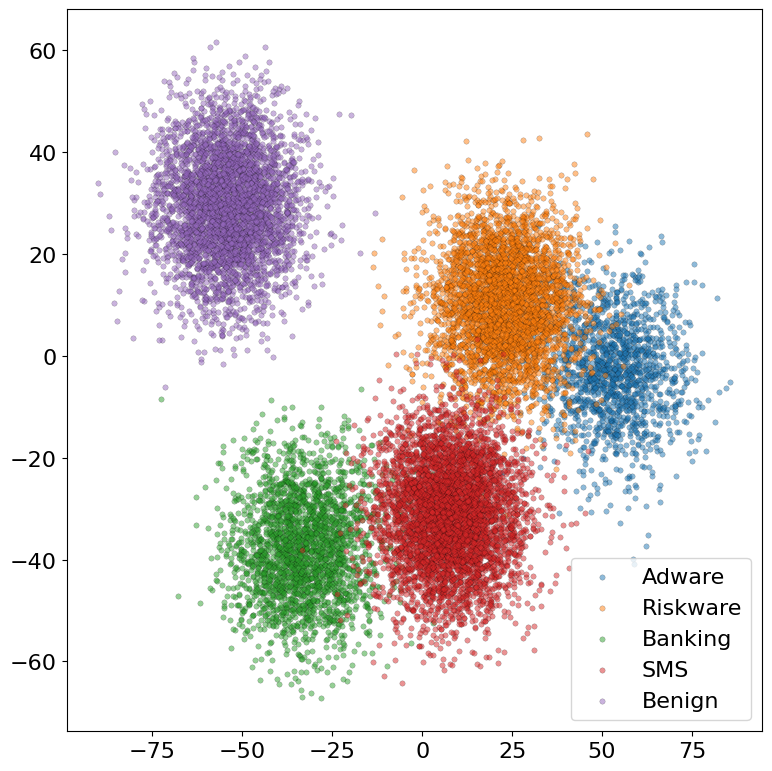
Figure 2: t-SNE comparisons of latent embeddings (a) Euclidean cross-attention, (b) FOCA, on CICMalDroid2020.
Comparison to Prior SOTA
FOCA demonstrates strong improvements over:
- Deep vision-only (e.g., "PVitNet" [yang2024pvitnet], 53.71% on Mal-Net).
- Prior multimodal and concatenation methods.
- Other advanced frameworks (e.g., "MalVIS," "HYDRA," and various ensemble or GNN-based SOTA approaches).
Notably, FOCA's advantage is consistent across audio-visual PTM pairings, confirming the robustness of the hyperbolic fusion principle.
Implications and Future Directions
FOCA's commitment to geometry-aware multimodal modeling marks a paradigm shift from widespread Euclidean fusion. The approach addresses the long-standing limitation of hierarchical dependency modeling in malware classification, leveraging the properties of hyperbolic space for multimodal alignment. Practically, this suggests that future malware defense systems—especially those operating at scale or in adversarial settings—can benefit from hierarchical curvature modeling.
Potential future directions include:
- Extending to additional or heterogeneous modalities (e.g., control flow graphs, tabular metadata).
- Exploring trainable hyperbolic geometry (learned curvature).
- Integrating transformer-based PTMs end-to-end within the hyperbolic manifold.
- Robustness studies under adversarial perturbations or distribution shifts in malware samples.
Given the open-source release, the architecture can facilitate benchmarking of non-Euclidean multimodal techniques across broader cyber security tasks.
Conclusion
FOCA proposes a comprehensive multimodal classification pipeline that achieves superior malware detection by explicitly modeling and fusing audio-visual modalities in hyperbolic space using HCA. Empirical results substantiate the efficacy of curvature-aware alignment, with clear separation in embedding space and performance surmounting all competitive methods. The FOCA framework thus advances both the theoretical underpinnings and practical capabilities of geometry-aware deep multimodal malware classification (2601.17638).