Statistical Decisions and Partial Identification: With Application to Boundary Discontinuity Design
Published 25 Jan 2026 in econ.EM | (2601.17648v1)
Abstract: We are delighted to respond to the excellent surveys by Cattaneo et al. (2026) and Hirano (2026). Our discussion will attempt two things: first, we show how statistical decision theory can be applied to situations with partial identification; second, we connect the surveys' themes by applying these insights to an imagined policy experiment in one of Cattaneo et al.'s (2025) applications. To do so, we lay out a stylized scenario of statistical decision making under partial identification and, drawing on our own and others' earlier work, provide a complete solution for that scenario. We then apply these results to a hypothetical reduction (modelled on actual policies) in eligibility for educational subsidies. We will see that something of interest can be said, but also that bringing the theory to the application involves some leaps of faith and leaves some questions open. This leads to the final section, where we discuss what we see as the main open challenges in statistical decision theory under partial identification.
The paper presents a formal framework where minimax regret decision rules are explicitly derived for scenarios with partially identified treatment effects.
It shows that small identification uncertainties allow ignoring model uncertainty, while larger uncertainties necessitate randomized decision rules with closed-form solutions.
The study outlines algorithmic approaches including discretization and convex optimization to efficiently compute optimal policies in boundary discontinuity designs.
Statistical Decision Theory under Partial Identification
Decision Rules in Partially Identified Environments
The paper "Statistical Decisions and Partial Identification: With Application to Boundary Discontinuity Design" (2601.17648) provides a rigorous treatment of statistical decision problems in contexts where the quantity of direct interest is only partially identified. The canonical setup considers a decision maker (DM) confronting treatment assignment based on empirical evidence subject to both estimation uncertainty (parametric noise) and identification uncertainty (potential model misspecification). Specifically, while the average treatment effect μ∗ is of principal interest, only bounds of the form μ∗∈[μ−k,μ+k] are typically known, where μ is a point estimator and k parameterizes identification uncertainty.
To select optimal actions under such uncertainty, the authors adopt the minimax regret (MMR) criterion, focusing on decision rules that minimize worst-case expected regret relative to an oracle that knows μ∗ exactly. The technical nucleus of the paper is the explicit characterization of MMR-optimal decision rules in the stylized setting where the DM observes a single noisy estimate μ^∼N(μ,σ2) and must choose between a status quo policy and a treatment for the target population.
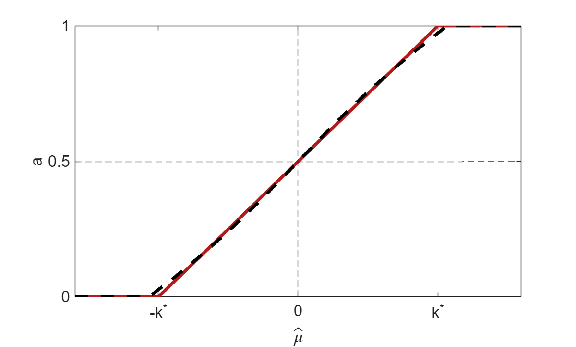
Key theoretical results establish that if the identification uncertainty k is small relative to the estimation standard deviation σ (specifically, k≤σπ/2), the decision rule that simply assigns treatment when μ^>0 is MMR optimal—model uncertainty is effectively ignored by the optimizer. When k is larger, the MMR-optimal rule must randomize within a critical region around zero, with an explicit form for the randomized policy that is linear in the observed signal within an interval determined by a smoothness equation involving k∗<k (see Theorem 1). The necessity of randomization over model uncertainty intervals is a distinctive and theoretically justified feature of the MMR paradigm in partially identified models.
Figure 1: Left panel visualizes a policy intervention shifting an eligibility threshold in double running variable discontinuity design; right panel overlays the exact and approximated MMR rules as a function of the signal.
Application: Boundary Discontinuity Design and Policy Evaluation
The authors apply their theory to boundary discontinuity designs arising in policy contexts such as financial aid programs. They instantiate their stylized model within the setting studied by Cattaneo, Titiunik, and Yu [CTY25a], where treatment assignment depends on two covariates (student ability and family wealth). The DM contemplates increasing the threshold for one covariate, operationalized as a probability a∈[0,1] of executing the shift. The relevant welfare statistic for the policy experiment is shown to depend on the (partially identified) average treatment effect over a policy-relevant subpopulation, constructed via integration over the covariate distribution.
Because the discontinuity design does not identify the treatment effect everywhere on the margin, the approach invokes a Lipschitz constraint on the treatment effect function τ(⋅) to operationalize identification uncertainty. Crucially, imposing the constraint only in one direction (e.g., ability holding wealth fixed) causes the uncertainty bounds for the policy-relevant mean to resemble the structure of the stylized model solved previously. This insight enables direct transfer of the closed-form MMR rules from the theoretical section to a concrete empirical policy choice problem.
Numerical experiments using empirical data and plausible choices for the smoothness parameter C reveal that, for most plausible parameterizations, the optimal policy counsels against threshold increases—the minimax regret rule is typically non-randomizing (zero probability of increasing the threshold) unless identification uncertainty is very large or estimation error is very small. For moderate to large uncertainty, fractional randomization arises and is quantitatively characterized.
Algorithmic and Asymptotic Developments
The design and computation of minimax decision rules in settings with partial identification is inherently challenging, particularly as the parameter and action spaces grow. Recent advances leverage the equivalence of minimax statistical decision problems to zero-sum games against Nature. The paper reviews two principal algorithmic approaches:
Discretization and fictitious play: Guggenberger and Huang [guggenberger2025numerical] discretize both the parameter and decision spaces, enabling the statistical game to be solved via variants of fictitious play. This offers practical solutions but its scalability with dimensionality depends on the density and structure of discretization.
Convex optimization and multiplicative weights: Aradillas Fernández et al. [fernandez2024epsilon] restrict discretization to the strategy space and leverage advanced convex optimization techniques, yielding guaranteed bounds and rates for approximate MMR solutions. The need for efficient oracles for Nature's optimization remains a practical bottleneck in this paradigm.
Theory also anticipates the desirability of rigorous large-sample approximations in partially identified models, though embedding full asymptotic local experiments (as done in point-identified settings by Hirano and Porter) is substantially more delicate. Recent work [xu25asymptotic, christensen2022optimal, kido2023locally] advances frameworks for profiling out the partially identified parameter and analyzing risk or regret under global or local asymptotics, though consensus on asymptotic optimality in these regimes is still emerging.
Implications and Outlook
This research clarifies and solves foundational statistical decision problems under partial identification, furnishing explicit, practical rules for policy decision-making (notably in RD designs with model uncertainty). Theoretically, the analysis shows that small identification uncertainties can and should be ignored by MMR-optimal policies, while larger uncertainties demand randomized rule design, and that only partial use of model structure may be sufficient for robust optimality.
Practically, the framework provides actionable guidance for policy makers faced with ambiguous evidence—especially in high-dimensional or complex designs—backed by concrete numerical and analytic tools. The duality between decision making and game-theoretic Nash equilibrium, and the connections to modern convex optimization, offer promising avenues for automating scalable minimax solutions.
Future research should further integrate robust algorithmic methods for Nash equilibrium computation, refine partial identification bounds using richer structural or smoothness conditions, and systematically analyze large-sample asymptotic properties of minimax regret rules in broader settings (including non-normal experiments and multi-action spaces). Addressing computational difficulties in high-dimensional models and extending the framework to dynamic or adaptive settings remain critical for expanding the reach of decision theory in policy analysis and machine learning.
Conclusion
This paper delivers a formal framework for statistical decision making under partial identification, providing both explicit characterizations of minimax regret rules and empirical illustrations in realistic policy evaluation settings. The identification of when model uncertainty can be ignored, and the principled necessity for randomized decision rules otherwise, enriches the theory and practice of causal inference and policy choice. The interplay between analytical solutions and modern algorithmic techniques positions this research as a foundational reference for further development of robust statistical decision systems under ambiguity.