Masked Depth Modeling for Spatial Perception
Abstract: Spatial visual perception is a fundamental requirement in physical-world applications like autonomous driving and robotic manipulation, driven by the need to interact with 3D environments. Capturing pixel-aligned metric depth using RGB-D cameras would be the most viable way, yet it usually faces obstacles posed by hardware limitations and challenging imaging conditions, especially in the presence of specular or texture-less surfaces. In this work, we argue that the inaccuracies from depth sensors can be viewed as "masked" signals that inherently reflect underlying geometric ambiguities. Building on this motivation, we present LingBot-Depth, a depth completion model which leverages visual context to refine depth maps through masked depth modeling and incorporates an automated data curation pipeline for scalable training. It is encouraging to see that our model outperforms top-tier RGB-D cameras in terms of both depth precision and pixel coverage. Experimental results on a range of downstream tasks further suggest that LingBot-Depth offers an aligned latent representation across RGB and depth modalities. We release the code, checkpoint, and 3M RGB-depth pairs (including 2M real data and 1M simulated data) to the community of spatial perception.









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about helping computers “see” the 3D world more accurately. The authors focus on depth — the distance from the camera to objects in a scene — which is crucial for things like self-driving cars and robots. They introduce a new way to fix and improve depth from RGB-D cameras (cameras that record both color and depth). Their key idea is to learn from the parts of depth images that are missing or wrong, rather than just throwing those parts away.
What goals did the researchers have?
The researchers wanted to make depth sensing:
- Accurate in real-world units (so you know actual distances, not just relative).
- Complete and dense (so every pixel has a depth value).
- Fast enough to use in real time.
They also wanted a single model that can:
- Fill in missing depth (“depth completion”) when a depth camera struggles.
- Predict depth from a single color image (“monocular depth”) when no depth is available.
Finally, they aimed to show that better depth helps in real tasks like tracking points in 3D videos and robotic grasping (picking up tricky objects).
How did they do it?
The big idea: Learn from missing depth
Depth cameras often fail on shiny, transparent, or plain surfaces (think glass, mirrors, polished metal, or blank white walls). When they fail, parts of the depth map become empty or noisy — like holes in a coloring book.
Instead of ignoring those holes, the authors treat them as “natural masks” and train a model to fill them in. The model looks at:
- The full RGB image (the color picture).
- The valid (non-missing) parts of the depth map.
It then learns to predict the missing depth values by connecting what it sees in color to how depth usually behaves.
The model in everyday terms
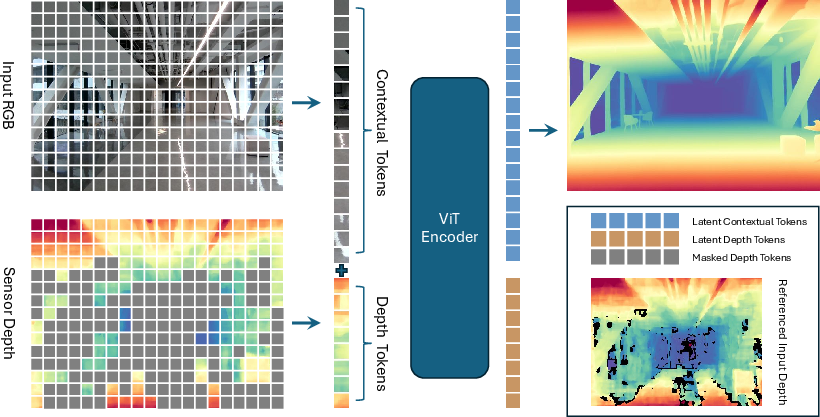
- Think of the scene as a grid of small patches (like tiles on a floor).
- Each RGB patch and each depth patch becomes a “token” (a small piece of information).
- A Transformer (a type of neural network that’s great at connecting related pieces) looks at all the RGB tokens and the valid depth tokens together.
- The model learns which color patterns (edges, textures, materials) match certain depth patterns (near/far, flat surfaces, boundaries).
- A specialized decoder (built with convolutional layers) uses those learned connections to reconstruct a complete, high-quality depth map.
Two modes:
- Depth completion: Only mask the bad depth tokens; use the remaining good depth plus RGB to fill the holes.
- Monocular depth: Mask all depth tokens; use only the RGB image to predict depth.
Building a huge dataset
Good depth training data is rare, especially when it includes realistic failures. The authors built two data pipelines:
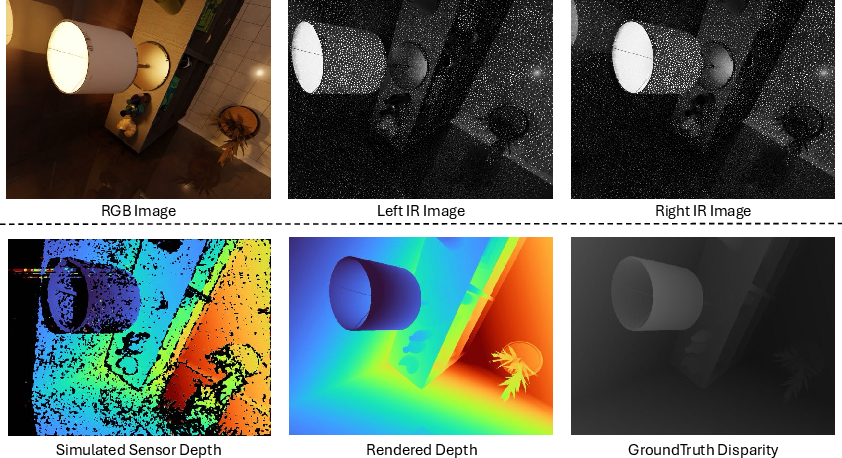
- Synthetic (simulated) data: They rendered scenes in Blender, produced stereo pairs (like having two eyes), and ran a stereo algorithm (SGM) to simulate sensor-like depth — including natural imperfections.
- Real-world data: They assembled a portable capture rig with multiple commercial RGB-D cameras (like Intel RealSense, ZED, Orbbec). They collected 2 million real captures across many indoor and some outdoor places. They used stereo pairs to create “pseudo” depth labels where perfect depth wasn’t available.
They combined this with seven public datasets to reach about 10 million RGB–depth pairs for training.
Training approach
- Backbone: A large Vision Transformer (ViT-L/14) pretrained on images.
- Input: Separate embeddings for RGB and depth, plus position info so the model knows where each patch is and which modality it came from.
- Masking: Mostly mask the depth tokens where the sensor failed, plus some random masking to make learning robust.
- Decoder: A convolutional “ConvStack” that reconstructs detailed, dense depth.
- Scale: Trained for 250k iterations with a huge batch size across many GPUs (about a week of training).
What did they find?
The model delivered strong results:
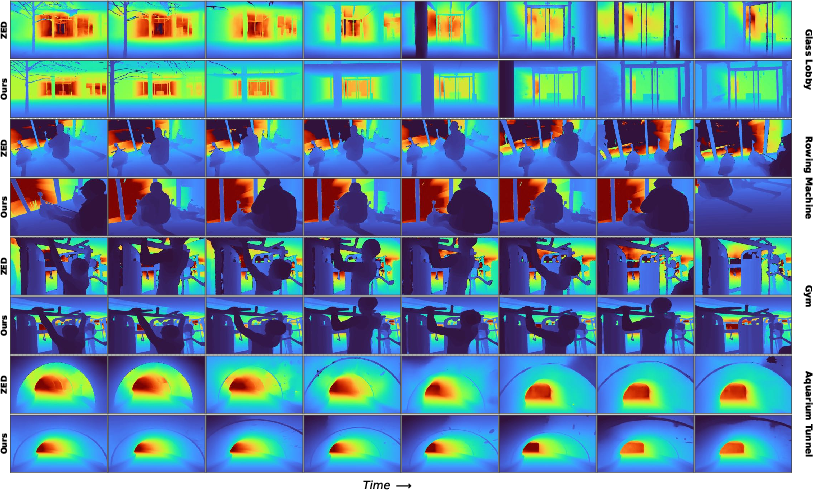
- Beats top RGB-D cameras in both accuracy and coverage:
- It fixes missing regions and reduces noise in tough scenes (glass, mirrors, low texture).
- It produces dense, pixel-aligned depth maps with real-world scale.
- Outperforms leading depth completion methods on standard benchmarks:
- Strong across different difficulty levels and masking types.
- Handles very sparse inputs (like points from Structure-from-Motion) better than other methods.
- Improves monocular depth:
- When used as a pretraining backbone, it helps a depth model (MoGe) outperform a popular image-pretrained baseline (DINOv2) on many datasets.
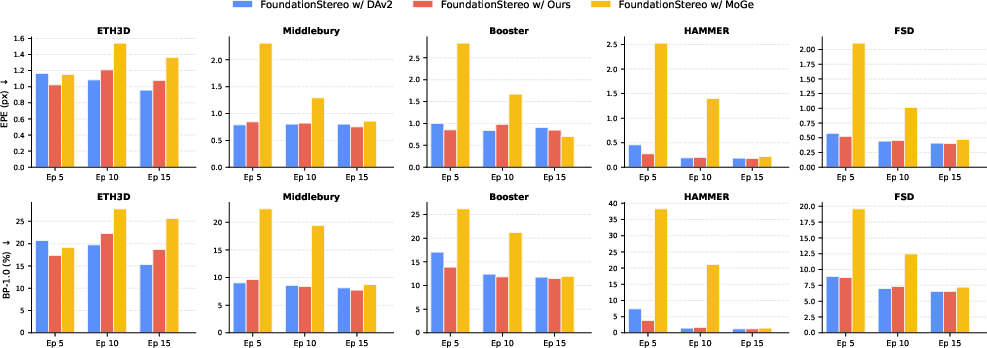
- Helps stereo matching training (FoundationStereo):
- Faster, more stable training and better final performance when using this model’s depth priors.
- Generalizes to video:
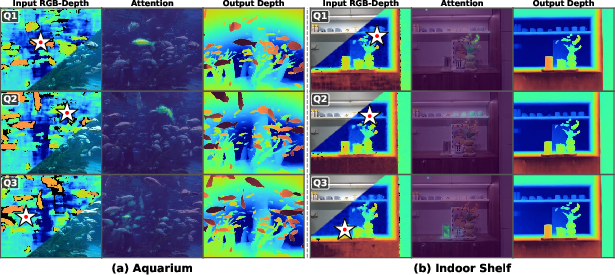
- Even without video training, it produces depth that is temporally consistent (stable over time), improving 3D tracking.
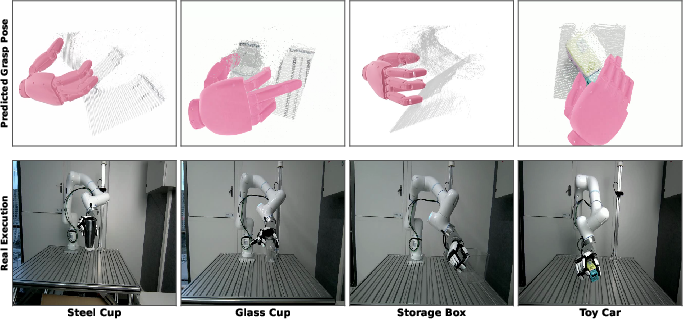
- Enables better robotics:
- A dexterous grasping policy using the model’s depth can grasp tricky objects like transparent glass and reflective bowls — cases that defeat standard sensors.
They also released code, model checkpoints, and 3 million curated RGB–depth pairs to help the community.
Why does it matter?
- Safer and smarter machines: Cars, drones, and robots rely on depth to avoid obstacles and interact with objects. More reliable depth means better planning and fewer mistakes.
- Works in the real world: By learning from natural sensor failures, the model handles the exact situations where traditional sensors go wrong.
- One model, many uses: It can fill in missing depth and predict depth from a single image, making it versatile for different setups.
- Boosts many applications: From stereo matching and video tracking to robotic manipulation, stronger depth makes downstream systems more effective and efficient.
- Scales with data: The automated data collection pipelines (synthetic + real) make it practical to train large, robust models for spatial perception.
In short, this research shows a practical way to turn the weaknesses of depth sensors into a learning signal, and it delivers a model that makes 3D perception more accurate, complete, and useful in the real world.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide follow-up research:
- Ground-truth fidelity in “hard” regions: Many training labels in real data are pseudo-depth from stereo matching and exclude invalid pixels; depth in reflective/transparent/textureless areas is effectively unsupervised. Quantify accuracy in these regions and develop labeling or self-supervision strategies that provide reliable targets (e.g., controlled multi-view LiDAR, polarization, coded illumination, or multi-bounce handling).
- Absolute scale for monocular mode: The paper claims metric monocular depth but primarily reports affine-/scale-invariant metrics for monocular evaluation. Provide metrics and experiments that demonstrate absolute scale accuracy across cameras and scenes without depth inputs, and analyze scale drift across domains.
- Camera intrinsics/extrinsics handling: The model does not explicitly ingest camera intrinsics/extrinsics, yet metric generalization requires them. Assess performance across wide FOV/focal-length changes, introduce intrinsic-aware conditioning, and report cross-camera generalization.
- Cross-sensor generalization: MDM leverages “natural masks” from specific RGB-D cameras (Orbbec, ZED). Evaluate generalization to different sensor types (e.g., ToF, structured light with different wavelengths, automotive stereo rigs) and quantify performance under different noise/mask distributions.
- Outdoor/long-range robustness: Evidence on large-range outdoor settings (sunlight, specular highlights, low SNR at distance) is limited. Benchmark against long-range ground truth (e.g., LiDAR) and report failure modes beyond DIODE-Outdoor.
- Temporal consistency quantification: Video results are qualitative; provide quantitative temporal metrics (e.g., warping consistency, flicker indices) under dynamic scenes, moving objects, and exposure changes, and study integration with simple temporal modules vs. zero-shot image-only.
- Uncertainty and confidence: No predictive uncertainty maps or confidence calibration are provided. Develop and evaluate calibrated uncertainty that correlates with depth error, enabling safe downstream use (e.g., in planning or SLAM).
- Failure detection and abstention: The model can hallucinate plausible depth where supervision is absent. Study mechanisms to detect OOD content and to “abstain” or retain sensor readings where they are more trustworthy.
- Masking strategy design: The paper posits that natural masks are “harder” than random but does not show ablations. Compare natural vs. random vs. learned/adaptive masks, analyze mask ratio sensitivity (60–90%), mixed-patch thresholding (0.75), and the impact of mask shape/scale on learning.
- Decoder design choices: Latent depth tokens are discarded in decoding; the decoder consumes only contextual tokens. Ablate using both contextual and unmasked depth tokens in the decoder, or cross-attention decoders, and measure boundary sharpness and error in sparse regimes.
- Loss formulation: Only L1 in linear depth is used. Test log-depth/inverse-depth, scale-aware composite losses, edge-aware terms, and gradient/normal losses, especially for large depth ranges and thin structures.
- Positional/modality embeddings: The modality embedding is a simple scalar (1/2). Explore richer modality encodings, learned cross-modal positional biases, and alternative tokenization (e.g., multi-scale/hierarchical tokens) for better fine-structure reconstruction.
- Pretraining data balance and bias: The real dataset composition (scene categories) and synthetic distributions (assets, baselines, focal lengths) may bias performance. Quantify domain coverage vs. target tasks, and release per-domain breakdowns of error to guide targeted data augmentation.
- Pseudo-label pipeline transparency: Details of the stereo network adaptation, training hyperparameters, and quality filtering beyond LR-check are sparse. Provide a thorough audit (EPE, BP-1.0, completeness) of pseudo-labels and their error propagation to MDM.
- Transparent/specular surfaces benchmarking: Claims of improved handling are shown qualitatively without ground truth. Construct controlled testbeds (e.g., glass/metal fixtures with benchmarked depths via multi-view laser scanning) for quantitative evaluation.
- Computation and deployment: No runtime, memory footprint, or energy benchmarks are reported. Provide latency and throughput on edge devices (e.g., Jetson/Orin), and study model compression (pruning, distillation, quantization) vs. accuracy trade-offs for real-time robotics.
- Integration with SLAM/VO: It is unclear how MDM depth affects pose estimation, loop closure, and map consistency. Evaluate in SLAM pipelines (ATE, RPE, map completeness) and measure benefits of MDM-driven densification vs. raw sensor depth.
- Robustness to adverse conditions: Assess performance under motion blur, rolling shutter, low light, HDR scenes, rain/fog/steam, and flickering artificial lighting; include controlled robustness suites and targeted augmentations beyond basic degradations.
- Dynamic scenes and deformable objects: Training is on static images; moving and deformable objects pose occlusion and non-rigidity challenges. Quantify performance on dynamic datasets and explore training with synthetic motion or temporal masking curricula.
- Calibration errors and synchronization: Real systems face RGB–depth misalignment, extrinsic drift, and timestamp skew. Evaluate sensitivity to these errors and propose training-time robustness (e.g., randomized misalignment) or test-time rectification.
- Cross-task transfer beyond depth: The ConvStack supports multi-task heads but only depth is demonstrated. Investigate joint learning of normals, occlusion boundaries, reflectance, or segmentation and measure whether depth improves or is improved by them.
- FoundationStereo integration fairness: Comparisons disable iterative self-curation used by the original method and show only short training schedules. Provide matched training protocols and ablations isolating the contribution of MDM priors vs. schedule/data differences.
- Evaluation breadth and metrics: Add planarity, edge accuracy (e.g., iBims geometric metrics), thin-structure recall, and surface normal error to complement RMSE/REL; report per-material breakdown (glass, metal, fabric, wood) to validate claimed appearance–geometry reasoning.
- Naming and dataset release clarity: The paper references unnamed splits (synthetic/real) and promises release of 3M pairs while training uses ~10M samples. Clarify what will be released (data, assets, stereo code), licensing, and reproducibility steps for the full pretraining.
- Safety and downstream impact: For robotic manipulation and navigation, characterize how depth errors translate to task failure rates, grasp safety margins, and collision risks; include quantitative ablations on policy sensitivity to depth noise/latency.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that can be implemented now using the paper’s released code, checkpoints, and datasets, or by integrating the model into existing workflows.
- Robotics (industrial and service)
- Use case: Depth completion on commodity RGB-D cameras to enable reliable grasping and manipulation of transparent, reflective, and low-texture objects (e.g., glassware, metal bowls, plastic packaging) in warehouses, kitchens, labs.
- Tools/products/workflows: MDM Depth Completion ROS node or edge module; integration into grasping stacks and motion planners; training a dexterous grasping policy using MDM latent features.
- Assumptions/dependencies: Accurate RGB–depth calibration and pixel alignment; real-time inference feasibility on available compute (GPU/NPU); safety fallback for edge cases; domain adaptation for specific environments.
- AR/VR and 3D scanning (software, consumer electronics, construction/real estate)
- Use case: Temporally consistent video depth completion to improve occlusion handling, scene reconstruction, and room scanning in challenging environments (glass walls, mirrors, shiny floors).
- Tools/products/workflows: Unity/Unreal SDK plugin for depth refinement; room-scanning app enhancement; interior design and real-estate virtual tours with denser, more accurate depth.
- Assumptions/dependencies: Device supports either RGB-D capture or calibrated monocular input; compute budget on device or low-latency cloud; monocular-only mode sacrifices metric scale unless external cues are added.
- Stereo training acceleration (academia, software)
- Use case: Use MDM-pretrained encoder as a stronger monocular depth prior in FoundationStereo to speed convergence and improve final accuracy.
- Tools/products/workflows: Drop-in prior for stereo networks; reduced training time and cost for new stereo datasets; reproducible training scripts based on the paper’s methodology.
- Assumptions/dependencies: Access to training data (e.g., FSD or internal datasets); compute resources; compatibility with existing training pipelines.
- Online 3D point tracking (AR/VR, robotics, security/retail analytics)
- Use case: Replace the standard VGGT frontend with the MDM encoder in SpatialTrackerV2 to improve motion understanding and tracking robustness in reflective/texture-less settings.
- Tools/products/workflows: MDM-Tracker plugin; enhanced 3D tracking for object interaction, analytics, and AR overlays.
- Assumptions/dependencies: Stable frame rate and synchronization; GPU or optimized inference for real-time tracking; accurate camera intrinsics/extrinsics.
- Manufacturing and quality inspection (industrial automation)
- Use case: Depth completion for specular and low-texture parts to improve dimensional measurements and defect detection where ToF/structured light struggle.
- Tools/products/workflows: On-premise machine vision module that refines sensor depth; integration with QA pipelines; automated pass/fail checks on reflective components.
- Assumptions/dependencies: Controlled lighting/calibration; inference speed aligned with line throughput; periodic validation against ground truth metrology.
- Warehouse logistics and bin picking (robotics)
- Use case: Improve grasp success rates for transparent/reflective packaged items; robust depth for cluttered bins with mixed materials.
- Tools/products/workflows: MDM-refined depth as input to bin-picking pipelines; retraining grasp policies with MDM latent features.
- Assumptions/dependencies: Domain adaptation to warehouse scenes; camera placement and occlusion management; integration with existing control stacks.
- Construction and facility scanning (AEC/BIM)
- Use case: Generate denser, cleaner point clouds from consumer RGB-D devices for as-built documentation, facility audits, and renovation planning.
- Tools/products/workflows: Depth-completion module in mobile scanning workflows; post-processing tool for point clouds that corrects sensor failures on glass/mirror surfaces.
- Assumptions/dependencies: Accurate sensor calibration; alignment with BIM tools; file format compatibility.
- Education and academic research
- Use case: Teaching and research on spatial perception, masked modeling, and RGB-D fusion using the released 3M RGB-depth pairs and code.
- Tools/products/workflows: Course labs; reproducing the synthetic and real-world data curation pipelines; benchmarking masked depth modeling versus MAE-style methods.
- Assumptions/dependencies: Availability of cameras or simulated assets; Blender and SGM setup; GPU access for training/fine-tuning.
- Lab automation in healthcare and biotech
- Use case: Reliable manipulation of glass labware (petri dishes, beakers) and shiny instruments in automated workflows.
- Tools/products/workflows: MDM depth module for lab robots; safety checks integrated with perception stack; policy training leveraging MDM latent features.
- Assumptions/dependencies: Regulatory and safety constraints; environmental consistency; periodic validation with ground-truth measures.
- Developer APIs and SaaS (software)
- Use case: Hosted service or edge SDK for depth completion, monocular metric depth (where feasible), and temporal stabilization.
- Tools/products/workflows: REST/gRPC API; mobile and embedded SDKs; batch refinement for recorded datasets.
- Assumptions/dependencies: Data privacy and on-prem requirements; latency/bandwidth budgets; device GPU/accelerator support.
Long-Term Applications
Below are opportunities that require further research, scaling, hardware integration, regulatory alignment, or broader ecosystem support.
- Sensor-firmware integration and “self-healing” RGB-D cameras (hardware, consumer electronics)
- Use case: Embed MDM-like models directly in camera firmware so sensors output refined, dense, metric-aligned depth under adverse imaging conditions.
- Tools/products/workflows: On-device model compression and acceleration (NPU/DSP), firmware co-design; standardized calibration routines.
- Assumptions/dependencies: Hardware accelerators; power/battery constraints; robust field updates; OEM partnerships.
- Generalist spatial perception foundation for robotics (robotics, autonomy)
- Use case: Unified RGB–depth latent representations powering multi-task robots (grasping, navigation, inspection) across diverse materials and environments.
- Tools/products/workflows: Multi-task training with temporal supervision; policy learning pipelines that consume shared spatial latents; sim-to-real bridges.
- Assumptions/dependencies: Larger-scale, temporally annotated data; integration with planning and control; safety-certification pathways.
- SLAM and mapping systems with robust priors (AR cloud, robotics)
- Use case: SLAM pipelines that remain stable around glass/mirrors and low-texture scenes using MDM priors for depth completion and monocular depth fallback.
- Tools/products/workflows: Tight coupling with visual-inertial SLAM; loop-closure resilient to sensor failures; map refinement services.
- Assumptions/dependencies: Real-time fusion; careful handling of dynamic scenes; cross-device calibration standards.
- Standards and policy for RGB-D evaluation (public sector, procurement, testing labs)
- Use case: Benchmarks and certification protocols emphasizing “depth completeness” and robustness to adverse materials, not just accuracy in ideal conditions.
- Tools/products/workflows: Open test suites; procurement specs for facilities and public deployments; compliance reports and auditing tools.
- Assumptions/dependencies: Stakeholder consensus; reproducible test hardware; long-term dataset stewardship.
- Medical AR and patient monitoring (healthcare)
- Use case: Reliable spatial understanding in reflective hospital environments for navigation, fall detection, and guided procedures.
- Tools/products/workflows: Certified AR applications with robust occlusion handling; monitoring systems using depth-enhanced analytics.
- Assumptions/dependencies: Regulatory approval; privacy protections; validated failure modes and redundancies.
- Consumer AR glasses and smart home devices (consumer electronics)
- Use case: Persistent AR experiences with accurate occlusions and 3D understanding across mirrors/windows; improved home robots’ perception.
- Tools/products/workflows: On-device depth refinement; energy-efficient inference; developer frameworks for AR occlusion and segmentation.
- Assumptions/dependencies: Battery and heat budgets; miniaturized accelerators; platform ecosystem adoption.
- Drone and industrial inspection (energy, utilities, transportation)
- Use case: Robust depth on shiny pipelines, solar panels, polished machinery, wind turbine blades; improved defect localization.
- Tools/products/workflows: Fusion of stereo/IR with MDM priors; temporal consistency in aerial video depth; standardized inspection reports.
- Assumptions/dependencies: Outdoor generalization (lighting/weather); high-speed inference; safety in flight operations.
- Insurance and finance: property appraisal and claims (finance/insurance, real estate)
- Use case: More reliable 3D capture of interiors with mirrors and glass for valuation, claims assessment, and fraud detection.
- Tools/products/workflows: Scanning apps with built-in depth refinement; automated damage quantification; audit trails and metadata standards.
- Assumptions/dependencies: Acceptance by regulators and adjusters; privacy and security controls; cross-platform consistency.
- Education: hands-on spatial perception kits (education)
- Use case: Affordable kits and curricula that teach masked modeling, RGB-D fusion, and real-world data curation at scale.
- Tools/products/workflows: Classroom-friendly rigs (3D-printed mounts), synthetic data pipelines, assignment packs.
- Assumptions/dependencies: Cost and maintenance; institutional support; teacher training.
- Edge AI silicon tuned for masked depth modeling (semiconductors)
- Use case: Custom accelerators and compilers optimized for ViT-style masked modeling and ConvStack decoding for dense geometry.
- Tools/products/workflows: Model–hardware co-design; sparsity-aware execution; standardized benchmarks for depth workloads.
- Assumptions/dependencies: Ecosystem investment; stable workloads; long-term hardware/software maintenance.
Cross-cutting assumptions and dependencies
- Metric scale and pixel alignment depend on accurate camera calibration and synchronized RGB–depth streams; monocular-only modes may suffer from scale ambiguity.
- Real-time deployment of ViT-L + ConvStack may require model distillation, pruning, quantization, or hardware accelerators.
- Domain generalization is strong in reported tests but may still require fine-tuning for unique environments (e.g., extreme outdoor glare).
- Integration with existing systems (SLAM, stereo pipelines, robotics controllers) involves engineering overhead and careful failure-mode handling.
- Data governance considerations (privacy, security) are essential when using cloud services or recording indoor spaces.
- Licensing and IP terms for released assets and code must be respected; proprietary datasets may be needed for targeted sectors.
Glossary
- Active stereo: A depth sensing approach using two cameras and projecting structured patterns to aid correspondence. "including active stereo (Intel RealSense, Orbbec Gemini) and passive stereo (ZED) systems."
- AdamW: An optimizer that decouples weight decay from gradient-based updates for better regularization. "The optimizer is AdamW~\cite{loshchilov2017decoupled} with momentum parameters , , and a weight decay of 0.05."
- BF16: Brain floating-point 16-bit format used to speed up training with minimal precision loss. "mixed-precision training using BF16 is enabled throughout to improve computational efficiency and reduce memory consumption."
- Bilinear upsampling: A resampling method that interpolates pixel values using a weighted average of neighbors. "The final depth prediction is bilinearly upsampled to match the original input resolution."
- BP-1.0: A stereo metric measuring the percentage of pixels with disparity error greater than 1.0 pixel. "report the EPE (end-point-error ) and BP-1.0 that computes the percentage of pixels where the disparity error is larger than 1.0 pixel."
- CLS token: A special token in Transformers used to aggregate global information across inputs. "In addition to the RGB-D tokens, a [cls] token is retained to capture global context across modalities."
- ConvStack decoder: A convolutional decoder architecture tailored for dense geometric reconstruction. "we employ a ConvStack decoder adopted from MoGe \cite{moge,moge2}, which is better suited for dense geometric prediction."
- Coplanarity: A geometric prior where points lie on the same plane. "fundamental geometric priors such as near--far relationships, coplanarity, and spatial continuity."
- DINOv2: A large-scale self-supervised vision transformer pretraining method. "we initialize the encoder with the official DINOv2 pretrained checkpoint."
- Depth completion: The task of filling in missing or invalid depth values to produce dense depth maps. "it achieves competitive performance in both depth completion and metric monocular depth estimation."
- Dexterous grasping: Robotic manipulation focusing on precise, versatile grasps using rich sensory input. "including 3D point tracking and dexterous grasping."
- Differential learning rate: Training strategy using different learning rates for different model parts (e.g., pretrained vs randomly initialized). "we employ a differential learning rate strategy: parameters in the encoder backbone are optimized with a base learning rate of , while all remaining parameters, including those in the decoder, are trained with a higher learning rate of ."
- Disparity: The pixel offset between stereo images, inversely related to depth. "disparity error is larger than 1.0 pixel."
- End-point error (EPE): A stereo metric measuring the average absolute error in disparity. "report the EPE (end-point-error ) and BP-1.0"
- FoundationStereo: A foundation model for stereo matching trained on diverse datasets. "We also use our MDM-pretrained model as a strong monocular depth prior in FoundationStereo~\cite{FoundationStereo}."
- Gradient clipping: Limiting the norm of gradients during training to improve stability. "Gradient clipping with a maximum norm of 1.0 is applied to stabilize optimization"
- IR (infrared): Spectrum used by active depth sensors for stereo or structured-light measurements. "compute the stereo disparity of the left-right IR pairs"
- Joint embedding: A shared representation learned across multiple modalities (e.g., RGB and depth). "learn a joint embedding of RGB tokens and unmasked depth tokens"
- LiDAR: Depth sensing using laser pulses to measure distances via time-of-flight. "active sensor-based depth measurement (e.g., LiDAR, ToF, Structured Light)."
- L1 loss: A regression loss using absolute differences between predictions and targets. "The predicted depth map is supervised using an L1 loss applied directly to the ground-truth depth map."
- Masking ratio: The proportion of tokens or pixels masked during training to encourage reconstruction. "The overall masking ratio is in the range of 60\%-90\% for depth maps."
- Masked Autoencoder (MAE): A self-supervised method reconstructing masked inputs, commonly for images. "In vanilla MAE, pixel-wise RGB reconstruction is performed using a shallow Transformer decoder."
- Masked Depth Modeling (MDM): A pretraining approach using naturally missing sensor depth as masks to learn depth representations. "we introduce {\bf M}asked {\bf D}epth {\bf M}odeling (MDM) to achieve dense, pixel-aligned scene geometry."
- Mixed-precision training: Training with reduced numeric precision to speed computation and save memory. "mixed-precision training using BF16 is enabled throughout to improve computational efficiency and reduce memory consumption."
- Modality embedding: A positional encoding component indicating the source modality (RGB vs depth). "Specifically, the modality embedding is set to 1 for RGB tokens and 2 for depth tokens."
- Monocular depth estimation: Predicting scene depth from a single RGB image without explicit depth input. "data-driven monocular depth estimation"
- Nearest-neighbor interpolation: An upsampling technique that copies the closest pixel value without smoothing. "then upsampled using nearest-neighbor interpolation to match the target resolution."
- Passive stereo: Depth sensing with two cameras relying solely on natural scene texture, without projection. "including active stereo (Intel RealSense, Orbbec Gemini) and passive stereo (ZED) systems."
- Patch embedding: Projecting image patches into token embeddings for transformer input. "We apply separate patch embedding layers to the two input modalities: the 3-channel RGB image and the single-channel depth map."
- Pixel-aligned geometry: Depth values that are aligned per pixel with the RGB image for accurate correspondence. "pixel-aligned dense geometry"
- Pseudo-depth supervision: Using approximate depth labels from a secondary process (e.g., stereo) to supervise training. "The stereo pairs enable pseudo-depth supervision through a custom stereo matching network"
- Self-Attention: Transformer mechanism computing attention weights among tokens to model relationships. "forcing the Self-Attention layers to exploit RGB context alone to infer geometry."
- Semi-global matching (SGM): A stereo algorithm aggregating matching costs along multiple paths to compute disparity. "semi-global matching (SGM) algorithm"
- Shot noise: Random fluctuations in sensor measurements due to discrete photon events. "motion blur, and shot noise"
- SLAM (Simultaneous Localization and Mapping): Techniques to estimate camera pose and build maps from sensor data. "Using SfM/SLAM techniques to recover camera poses and sparse scene geometry"
- Specular reflections: Mirror-like surface reflections that cause failures in stereo/active depth sensing. "such as low-texture surfaces, specular reflections, and complex lighting conditions."
- Speckle patterns: Dot or interference patterns projected or rendered to aid stereo or structured-light matching. "grayscale stereo image pairs with speckle patterns in Blender."
- Step decay scheduler: A learning rate schedule that reduces the rate by fixed factors at set intervals. "After warm-up, a step decay scheduler reduces both learning rates by a factor of 0.5 every 25{,}000 iterations."
- Structured Light: Depth sensing by projecting known patterns and measuring their deformation on surfaces. "active sensor-based depth measurement (e.g., LiDAR, ToF, Structured Light)."
- Transposed convolutions: Convolutional layers that increase spatial resolution (upsampling) in decoders. "transposed convolutions (kernel size 2, stride 2)"
- UV positional encodings: Encodings of 2D image coordinates (U,V) injected to preserve spatial layout. "UV positional encodingsâderived from a circular mapping of image coordinatesâare injected to preserve spatial layout and aspect ratio."
- ViT-Large: A large Vision Transformer configuration (e.g., 24 layers, patch size 14). "using ViT-Large as the encoder backbone."
- Vision Transformer (ViT): A transformer architecture adapted for images by tokenizing patches. "We adopt a standard Vision Transformer (ViT) architecture \cite{vit}, using ViT-Large as the encoder backbone."
- Zero-shot generalization: Performing well on a task or domain without task-specific fine-tuning. "remarkable zero-shot generalization to video depth estimation, producing temporally consistent geometry without explicit temporal supervision."
- ZED: A commercial passive stereo camera used for depth sensing and benchmarking. "including active stereo (Intel RealSense, Orbbec Gemini) and passive stereo (ZED) systems."
Collections
Sign up for free to add this paper to one or more collections.