- The paper derives statistical bias and variance decompositions for actor and critic outputs using asymptotic expansions with respect to network width and scaling exponent beta.
- It presents deterministic and stochastic contributions that guide hyperparameter tuning, ensuring rapid convergence and reduced output variance.
- Empirical results confirm that tuning beta near one minimizes initialization effects, leading to stable and efficient policy convergence.
Scaling Effects and Uncertainty Quantification in Neural Actor-Critic Algorithms
Overview of Objectives and Contributions
The paper "Scaling Effects and Uncertainty Quantification in Neural Actor Critic Algorithms" (2601.17954) provides an analytical and empirical study of the asymptotic scaling regimes for neural actor-critic reinforcement learning algorithms, focusing on shallow networks with width N→∞. The primary contributions are:
- The derivation and rigorous characterization of the statistical bias and variance for actor and critic neural outputs across a continuum of scaling exponents β∈(21,1).
- Construction of asymptotic expansions for the network outputs, which detail both deterministic and stochastic contributions, thus enabling a fine-grained analysis of estimator uncertainty.
- Identification of concrete, scaling-law-based prescriptions for algorithmic hyperparameters (learning rates, exploration rates) that guarantee controlled statistical behavior.
- Empirical demonstration of the impact of the scaling parameter β on the speed of convergence (bias decay) and estimator robustness (variance reduction).
Theoretical Analysis: Asymptotic Expansions and Bias-Variance Decomposition
The paper employs stochastic process and measure-theoretic analysis to demonstrate that, under specific scaling constraints on network parameters and learning rates, the outputs of shallow actor and critic networks can be expanded as:
QtN≈Qt(0)+Nβ−1Qt(1)+⋯+N21−βQt(n) PtN≈Pt(0)+Nβ−1Pt(1)+⋯+N21−βPt(n)
with each Qt(j), Pt(j) satisfying deterministic or, for the highest-order term, stochastic evolution equations, and the scaling constant β controlling the order at which random fluctuations enter. Crucially, this reveals:
- Bias Reduction: The non-random terms decay proportionally with training time and network width, and bias corrections scale as Nmax{β−1,21−β} (minimized near β=3/4).
- Variance Reduction: The variance term scales as N21−β, strictly decreasing as β→1. Thus, choosing β near $1$ (mean-field regime) optimally suppresses random initialization effects.
Implications for algorithm design include the setting of learning rate and exploration schedules as explicit functions of N and β, validated by proofs and error bounds.
Large-Time Convergence and Control of Estimator Uncertainty
The convergence of the critic network to the true state-action value function and the actor to a stationary optimal policy is established under the prescribed scaling and ergodicity assumptions. The rate of convergence can be directly controlled via the exploration parameter schedule, tying hyperparameter choices to provably favorable statistical behavior. Moreover, the explicit bias-variance decomposition allows the practitioner to select β to minimize the variance of policy/reward estimators in practical deployments.
Empirical Validation
The authors present extensive numerical experiments utilizing a forest management MDP, varying β over [21,1] and network width N=10,000, with Monte Carlo repetition to estimate convergence metrics and output variance.
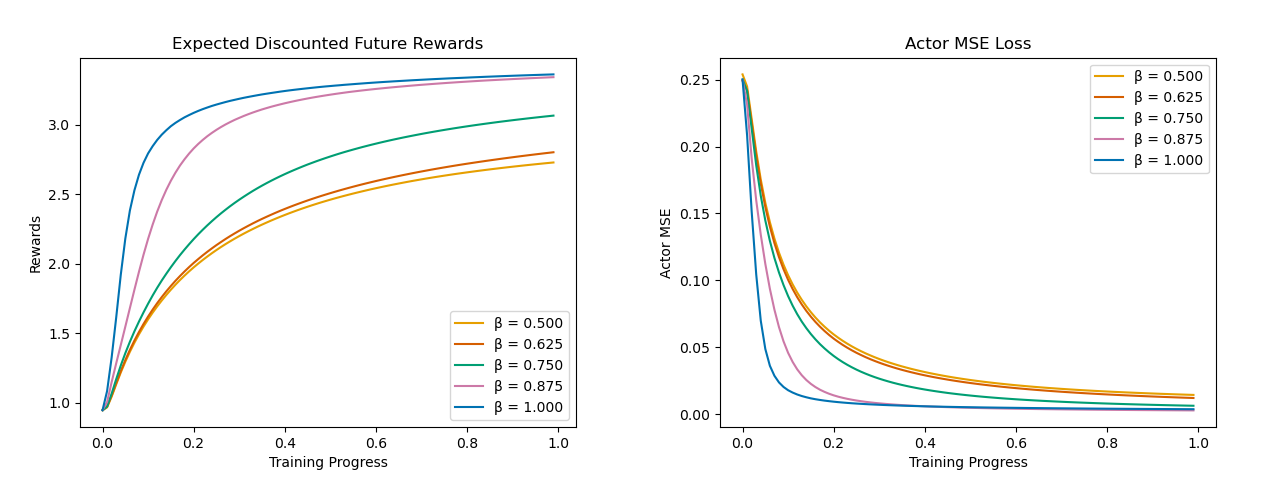
Figure 1: The Reward and Actor MSE Loss as a function of training time.
The first set of experiments demonstrates that convergence to optimal policy and maximum reward is fastest for β close to $1$, reinforcing the theoretical prediction for bias term decay. MSE loss curves and reward trajectories are consistent across repeated trials and demonstrate rapid decay with increasing β.
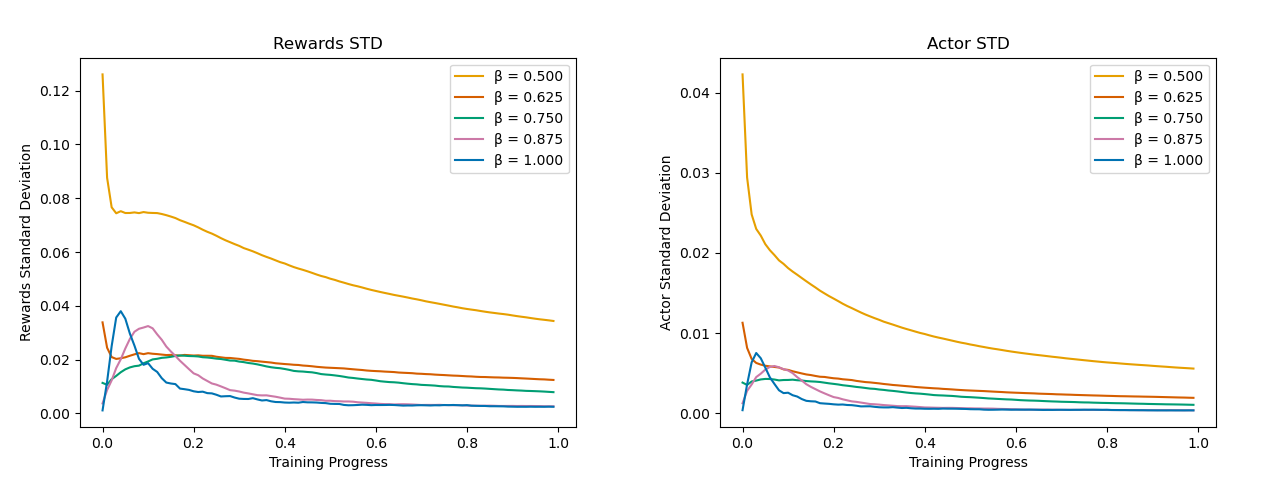
Figure 2: Standard deviation Monte Carlo estimates for the Actor, the Critic, and the Rewards as a function of training progress for different values of the scaling parameter β.
Variance analysis shows that output variance for actor, critic, and reward estimators decreases sharply as β moves toward $1$, in precise agreement with the asymptotic scaling N21−β. This supports the claim of enhanced statistical robustness available by tuning β, making the estimates less sensitive to initialization stochasticity and more stable in deployment.
Mathematical and Algorithmic Implications
From a mathematical perspective, the work generalizes shallow network scaling analyses from the regression domain to the RL setting, where Markov chain sampling in SGD training introduces additional technical complications. Notably, the non-homogeneity and slow time variation of the chains required the development of new martingale bounds and stationary distribution fluctuation characterizations.
Practically, the findings dictate that scaling the output of both networks with a large β—in the mean-field or feature-learning regime—combined with matched learning/exploration rates per the derived scaling laws, enables actor-critic systems to achieve both rapid convergence and minimal estimator uncertainty for large N. The prescriptions cover network initialization, learning rates ∼N2β−2, and exploration decay.
Future Directions
Potential avenues for further research include:
- Extension to multi-layer (deep) architectures, investigating the layer-wise sensitivity to the scaling parameter as documented in deep regression settings.
- Analysis of other optimization algorithms (e.g., Adam, RMSProp) within the scaling framework developed here.
- Investigation of more complex, non-stationary environments and richer RL domains.
Conclusion
This paper provides a rigorous, quantitative framework for understanding and controlling the scaling-induced bias and variance in neural actor-critic RL algorithms. By linking asymptotic behavior to algorithmic hyperparameters, it enables practitioners to optimally tune shallow neural network estimators for statistical efficiency and robustness, and sets the stage for future studies in large-scale, mean-field RL modeling and uncertainty quantification.