- The paper proposes a modular ASR pipeline integrating Wav2Vec2 segmentation, AST filtering, and Whisper transcription to enhance performance in challenging audio settings.
- It employs curriculum learning, aggressive Audio Spectrogram Transformer filtering, and Bayesian fine-tuning to reduce hallucination artifacts and improve transcription accuracy.
- Performance benchmarks indicate lower WER and higher BERT-F1 scores, while built-in uncertainty modeling effectively localizes errors for targeted human review.
Pisets: Architecture, Evaluation, and Uncertainty Modeling in Robust Speech Recognition
Three-Component Modular Architecture
Pisets introduces an integrated three-stage approach to automatic speech recognition (ASR), specifically targeting the challenges of transcription in long, noisy, heterogeneous audio sources typical of lectures and interviews. The pipeline comprises:
- Wav2Vec2 Segmenter: Replacing standard VAD heuristics, Wav2Vec2 is employed for segment boundary detection, leveraging its contextual representation capabilities and curriculum learning on diverse Russian corpora. The segmentation process is optimized to handle complex acoustic scenes, ensuring high recall without excessive fragmentation.
- Audio Spectrogram Transformer (AST) Filtering: Post-segmentation, AST—trained on AudioSet ontology—is deployed to aggressively filter false positive segments, substantially reducing non-speech artifacts and improving downstream recognition reliability under adverse conditions.
- Whisper-Based Final Transcription: The Whisper model performs the primary transcription task on segments that have passed both previous stages. Fine-tuning strategies using Bayesian Invariant Risk Minimization (BIRM) and curated Russian corpora (Librispeech, Taiga, Podlodka) further enhance the model's robustness to domain and acoustic shifts.
The cascade substantially mitigates Whisper's intrinsic hallucination artifacts and improves both accuracy and computational efficiency.
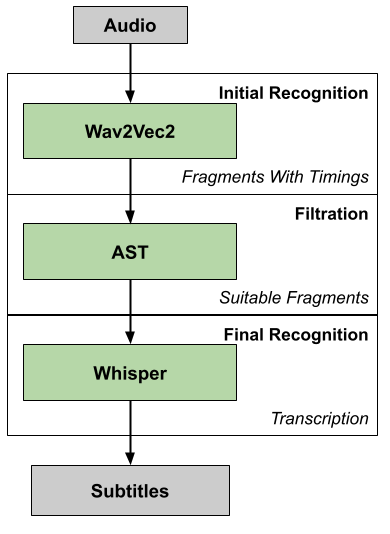
Figure 1: Proposed three-component speech recognition architecture integrating Wav2Vec2, AST, and Whisper for robust transcription.
Comparative Evaluation Against WhisperX
Pisets systematically benchmarks its pipeline against WhisperX, emphasizing both lexical fidelity (WER) and semantic congruence (BERT-F1). Key quantitative results:
- Quiet Acoustic Environments: Pisets achieves WER = 0.1065 and BERT-F1 = 0.9652, outperforming WhisperX (WER = 0.1683; BERT-F1 = 0.9479).
- Noisy Scenarios: Pisets demonstrates superior robustness; Whisper-Podlodka-V3 surpasses Whisper-Large-V3 in noisy conditions, indicating enhanced noise generalization from multi-corpus fine-tuning.
- Pipeline Efficiency: Wav2Vec2 "smart" chunking yields reduced inference latency compared to uniform chunking, facilitating scalable batch processing even in resource-constrained settings.
These benchmarks validate Pisets' bold claim of consistently exceeding WhisperX and baseline Whisper architectures in practical transcription tasks for Russian-language scientific lectures.
Advanced Uncertainty Modeling and Error Localization
Pisets implements multi-faceted uncertainty estimation—crucial for downstream editing, post-correction, and integration with LLM-driven summarization. The methods evaluated include:
- Whisper Token Probabilities: Direct extraction of per-token probabilities enables effective scoring; marking 5% of words as "uncertain" captures 35% of all transcription errors.
- Model Disagreement: Alignment and difference detection between Wav2Vec2 and Whisper outputs, as well as intra-Whisper TTA (audio stretching), were investigated.
- Hybrid Ensembling: Combination strategies yield marginal improvements.
Quantitative analysis demonstrates that no model disagreement or ensembling approach reliably outperforms the direct use of Whisper scores. The practical implication is the ability to highlight high-error regions with minimal false positive rate, streamlining human review and correction.
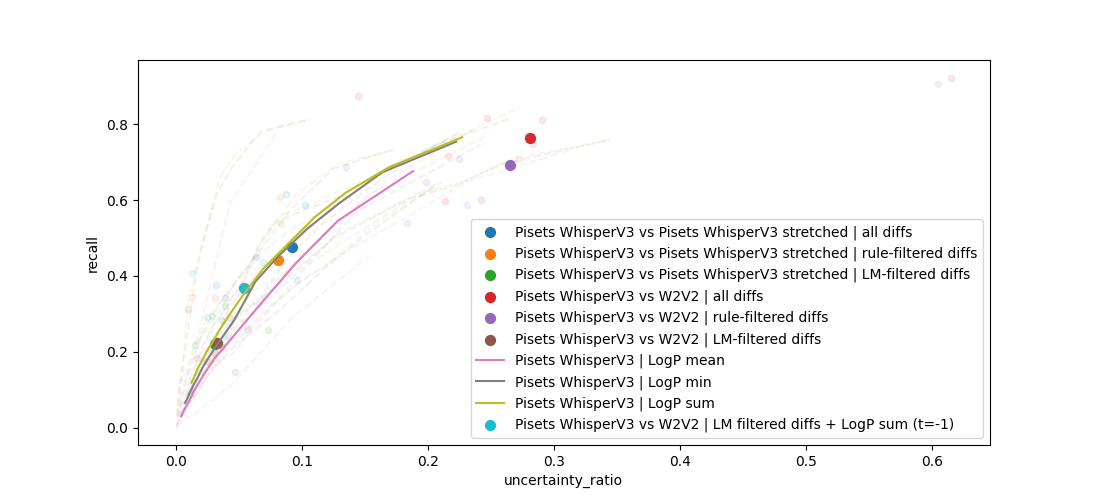
Figure 2: Error detection recall and uncertainty ratio of different estimation methods, with Whisper scores capturing 35% of total errors by highlighting just 5% of words.
Visualization of transcriptions with uncertainty overlay enables intuitive user interaction for rapid manual correction and selective human validation, optimizing both efficiency and accuracy in real-world deployment.

Figure 3: Example of highlighted dubious places in transcription based on model disagreement-derived uncertainty estimates.
Practical and Theoretical Implications
Pisets establishes a modular ASR architecture that demonstrates measurable gains in both performance and reliability for extended conversational and lecture transcription. The curriculum-driven segmentation and adaptive filtering modules provide resilience under nonstationary acoustic and linguistic conditions, a critical requirement for scientific and journalistic use-cases.
The explicit integration of word-level uncertainty paves the way for hybrid human-AI workflows, where rapid, semi-automated correction supplants exhaustive manual editing. Furthermore, error localization mechanisms are conducive to targeted LLM post-processing, potentially reducing the propagation of error-induced misrepresentations in downstream NLP tasks.
Theoretical implications include the validation of multi-stage modular pipelines over end-to-end approaches for long-form, domain-adaptive ASR, particularly in settings where hallucination minimization is paramount. The demonstrated efficacy of curriculum learning in ASR segmentation suggests further investigation into curriculum design for other modular subcomponents. Effective uncertainty quantification further supports the argument for confidence-aware AI deployments in critical domains.
Future Directions
Pisets is positioned for extension to multilingual and non-native speech scenarios. Current limitations regarding homophone and pragmatic context handling suggest the augmentation of the pipeline with multimodal LLMs (e.g., Qwen-Audio) to enable pragmatic disambiguation and context-sensitive recognition. Such developments would address current autoregressive model constraints and facilitate pragmatic-level integration, advancing the field toward holistic, context-aware speech transcription.
Conclusion
Pisets delivers a rigorously evaluated, modular ASR pipeline model offering demonstrable improvements in accuracy, robustness, and practical usability for long-form scientific and interview transcription. Its systematic uncertainty modeling and error localization capabilities represent a significant advance for confidence-aware, semi-automated transcription workflows. The framework lays the groundwork for future innovations in multi-domain, multilingual, and pragmatically-informed ASR systems.