- The paper introduces StreamLoD-GS, a novel method combining hierarchical LoD-based 3D Gaussian splatting with motion segmentation and quantized residual refinement for efficient SFVV.
- It achieves significant improvements in PSNR, rendering speed (>500 FPS), and a 66% storage reduction using as few as 3 training views.
- This framework paves the way for scalable, real-time free-viewpoint video streaming in bandwidth-constrained environments.
Hierarchical LoD-Structured Gaussian Splatting for Streaming Free-Viewpoint Video Reconstruction
Introduction and Motivation
Streaming Free-Viewpoint Video (SFVV) targets the photorealistic and interactive visualization of dynamic scenes from arbitrary perspectives, demanding rapid and storage-efficient reconstructions even under highly sparse multi-view inputs. Conventional approaches either suffer from prohibitive optimization costs or require dense synchronized camera arrays, limiting applicability in bandwidth-constrained practical scenarios. Recent advances in 3D Gaussian Splatting (3DGS) have substantially improved real-time rendering and model expressiveness, but suffer from overfitting and geometric redundancy under sparse-view constraints, inflating storage and bandwidth footprints.
The paper introduces StreamLoD-GS, a hierarchical Level-of-Detail (LoD) structured 3D Gaussian splatting framework, explicitly designed for streaming video applications. The method addresses SFVV's critical challenges—rapid optimization, high fidelity with few input views, and minimal storage—by integrating LoD-based hierarchical Gaussian pruning, efficient motion segmentation, and quantized residual refinement.
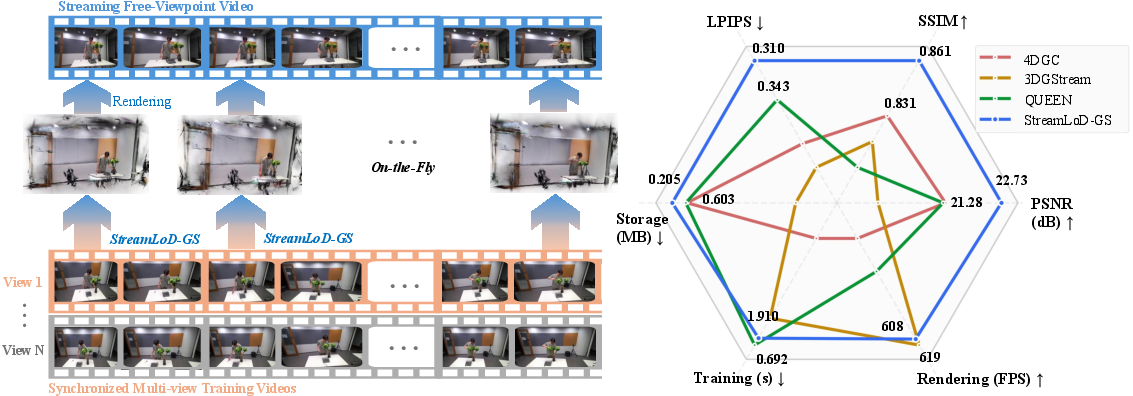
Figure 1: StreamLoD-GS provides efficient, on-the-fly reconstruction for SFVV and demonstrates superior quality compared to contemporary approaches using only 5 training views.
StreamLoD-GS Architecture
The proposed framework consists of three essential components:
- LoD-Structured 3DGS with Anchor and Octree Primitives: Utilizing layer-wise placement of anchors and organization into an octree, the system establishes a multi-resolution hierarchy, with dynamically selected anchors optimizing both rendering and gradient flow. A hierarchical Gaussian dropout mechanism controls redundancy and stabilizes optimization, especially salient under sparse viewpoints.
- GMM-Based Motion Partitioning: Leveraging temporal coherence, a Gaussian Mixture Model segments anchors into dynamic and static regions using frame-to-canonical image gradients. This enables selective refinement, strictly updating only dynamic regions, and freezing static (background) content for computational efficiency.
- Quantized Residual Refinement: Dynamic anchor updates are compressed via quantization of learned residuals (attributes and offsets, excluding center coordinates), using Straight-Through Estimation for differentiable quantization. This design dramatically reduces the memory footprint for streamed updates.
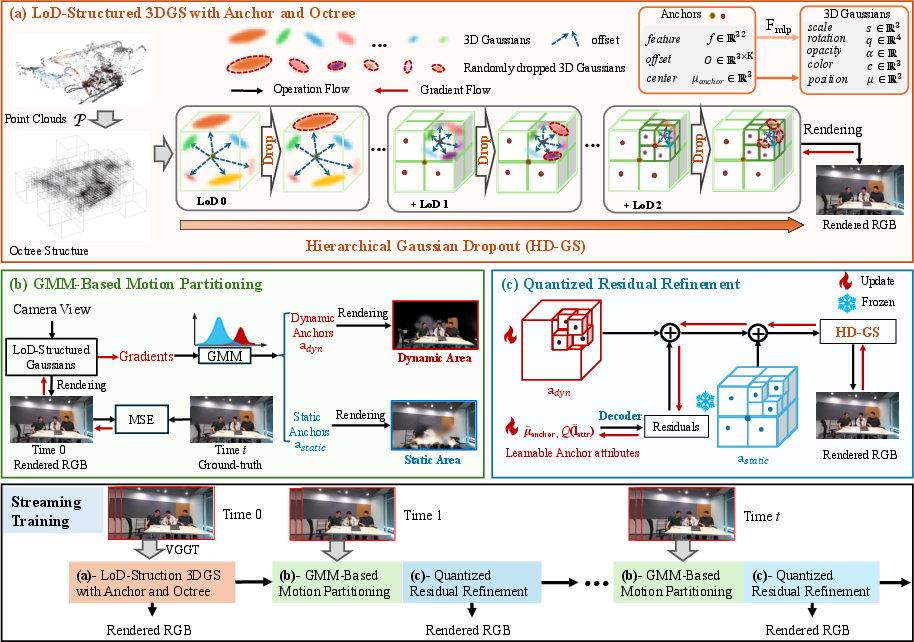
Figure 2: The StreamLoD-GS pipeline: LoD-structured anchor initialization, GMM-based motion partitioning, and quantized residual refinement for temporally coherent rendering.
Experimental Evaluation
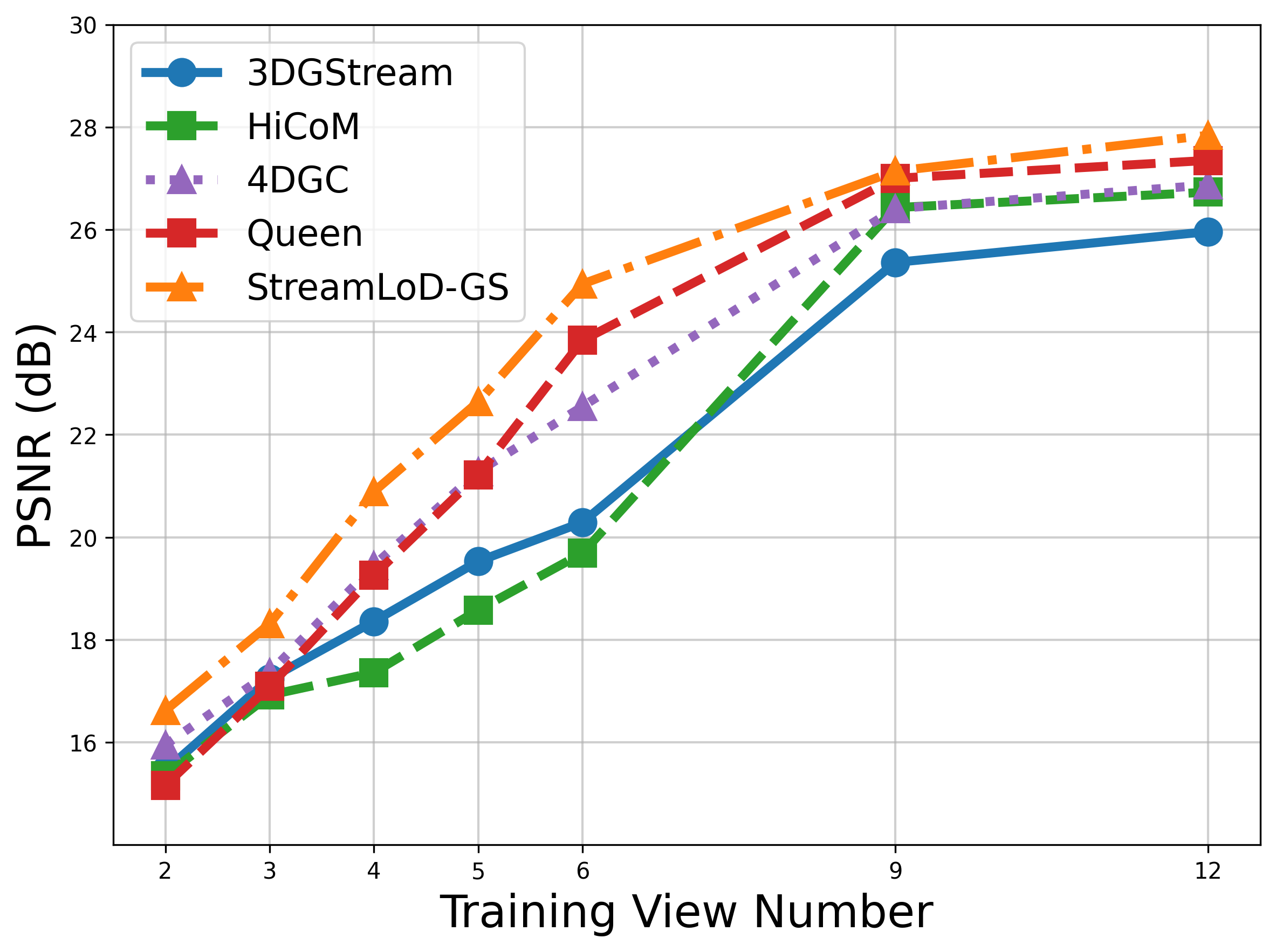
Comprehensive experiments are conducted on two benchmark datasets: Neural 3D Video (N3DV) and Meet Room. The evaluation rigorously compares StreamLoD-GS against StreamRF, 3DGStream, HiCoM, 4DGC, and QUEEN under both sparse and dense-view training regimes.
StreamLoD-GS exhibits marked improvements in both visual quality and storage efficiency. With only 3 training views:
- Achieves PSNR gains exceeding 1–2 dB over the best prior baselines.
- Storage requirements are compacted to 0.205 MB on Meet Room, amounting to 66% reduction relative to advanced quantization baselines.
- Render throughput consistently exceeds 500 FPS.
- Visual artifacts are minimized and scene details are preserved, overcoming floaters and boundary erosion evident in competing methods.

Figure 3: Qualitative reconstruction comparisons in N3DV showing StreamLoD-GS recovers sharper structures with minimal artifacts.

Figure 4: Quantitative frame-wise PSNR analysis on N3DV (Coffee Martini) highlighting superior temporal consistency with StreamLoD-GS.

Figure 5: Frame-wise performance across the Meet Room dataset illustrating StreamLoD-GS's resilience to artifacts and fidelity loss under sparse-view conditions.
Dense-View Scalability
With 12 training views, StreamLoD-GS maintains a significant margin in PSNR and achieves the fastest rendering and lowest storage cost relative to all baselines, confirming robust scalability without compromising efficiency.
Module Ablations and Analysis
Ablation experiments validate the necessity and synergy of architectural components:
Limitations and Future Directions
The GMM-based motion partitioning, although effective, confronts challenges in visually uniform, highly specular regions—where view-dependent photometric noise yields false-positive dynamic segmentation. Future enhancements should integrate color-consistency constraints and geometric priors to discriminate genuine motion from appearance artifacts, targeting improved segmentation robustness under complex environmental conditions.

Figure 7: Dynamic anchor segmentation results on Meet Room showing instances of misclassification in highly reflective objects and uniform surfaces.
Implications and Prospects
StreamLoD-GS positions itself as a practical solution for real-time, memory-efficient SFVV, delivering state-of-the-art synthesis under single-digit training views and minimal computational budgets. Theoretically, its integration of LoD hierarchical pruning and quantized update schemes establishes a template for future research in adaptive representation modeling and bandwidth-constrained video streaming. Practically, these developments enable scalable deployment of interactive 3D video in mobile and bandwidth-limited settings.
Anticipated future directions include the fusion of physically correct reflectance models for improved temporal appearance consistency, and extension to more generalized dynamic scene paradigms (non-rigid, unstructured motion), as well as on-device adaptation and federated learning schemes for distributed SFVV construction.
Conclusion
StreamLoD-GS introduces a hierarchical LoD-structured 3DGS design, GMM-driven dynamic/static segmentation, and quantized residual refinement, together achieving superior efficiency, fidelity, and compression for streaming free-viewpoint video applications. The method demonstrates robust generalization across sparse and dense-view scenarios, setting a new benchmark for practical SFVV systems with explicit architectural innovations that directly address scalability and real-time interactivity.
(2601.18475)