- The paper introduces a dual-stage framework combining CARE for robust feature alignment and IQE for dynamic query refinement to enhance person search accuracy.
- It leverages multi-granularity encoding, complementary pair mining, and context-guided optimal transport to bridge cross-modal representation gaps and reduce noise.
- Empirical results on datasets like CUHK-PEDES and RSTPReid demonstrate significant Rank-1 improvements and effective cross-domain robustness.
CONQUER: Context-Aware Representation with Query Enhancement for Text-Based Person Search
Introduction
The paper "CONQUER: Context-Aware Representation with Query Enhancement for Text-Based Person Search" (2601.18625) addresses principal limitations in Text-Based Person Search (TBPS), a cross-modal retrieval task involving the localization of pedestrian images via free-form textual queries. The inherent noise in cross-modal embedding spaces and ambiguity in user descriptions remain key technical obstacles, particularly when queries are incomplete or non-specific. CONQUER proposes a two-stage framework integrating advanced representation learning (training) with dynamic query enhancement (inference), leveraging multi-level granular alignment and anchor-driven query refinement to robustly address these challenges.
Framework Overview
The CONQUER framework operates in two discrete stages: Context-Aware Representation Enhancement (CARE) during training and Interactive Query Enhancement (IQE) at inference.
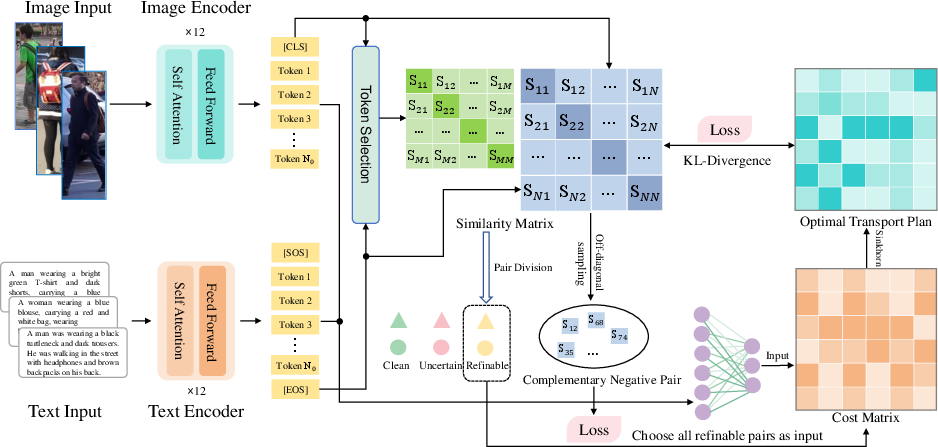
Figure 1: CARE module architecture, integrating multi-granularity encoding, complementary pair mining, and context-guided Optimal Transport for fine-grained cross-modal alignment.
Context-Aware Representation Enhancement (CARE)
CARE module addresses cross-modal representation gaps through three components:
- Multi-Granularity Encoding: Extracts both global and local features using modality-specific encoders. Local tokens provide fine-grained semantic cues, and confidence-based sampling discriminates between clean, uncertain, and refinable pairs for differential mining.
- Complementary Pair Mining: In the refinable set, off-diagonal negative sampling increases the diversity and challenge of negative samples, hardening the discrimination boundary.
- Context-Guided Optimal Matching: Formulates alignment as a regularized Optimal Transport (OT) problem, using a neural cost matrix. KL-divergence regularization ensures that fine-grained local matches conform to global semantic similarity, further enhancing robustness under noisy cross-modal correspondence.
This modular architecture enables enhanced cross-modal feature consistency and discriminability without requiring granular manual annotation.
Interactive Query Enhancement (IQE)
IQE module is invoked during inference, functioning entirely as a plug-and-play enhancement atop the trained backbone.
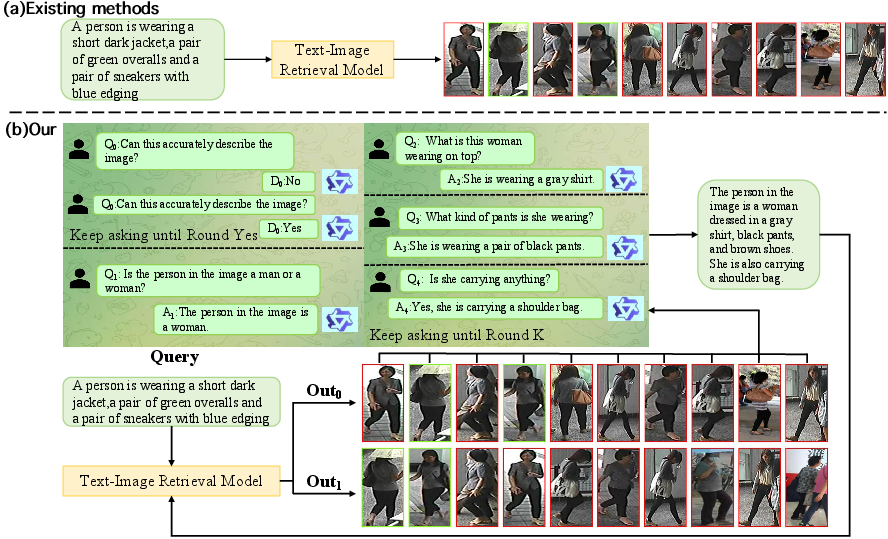
Figure 2: IQE module workflow, demonstrating anchor selection, attribute reasoning via MLLM Q&A, fusion, and ranking refinement for ambiguous queries.
- Anchor Identification: Retrieves top-K high-confidence images as anchors using a multimodal reasoning engine (Qwen2.5-VL-7B). Early-stop and fallback triggers optimize cost and reliability for ambiguous queries.
- Attribute-Driven Enrichment: For each anchor, a tailored Q&A protocol extracts salient attributes using the MLLM. Confidence-weighted aggregation and voting yield a compact set of enhancements to the original query.
- Query Fusion and Re-ranking: Final fused query features are scored and used for gallery re-ranking. A safeguard mechanism prevents deterioration when attribute enrichment is ineffective.
IQE dynamically adapts to incomplete or brief descriptions, ensuring reliable retrieval without model retraining.
Empirical Evaluation
Extensive experiments were performed on CUHK-PEDES, ICFG-PEDES, and RSTPReid datasets. CONQUER achieves superior retrieval metrics compared to all contemporary baselines.
- CUHK-PEDES: Rank-1: 77.13%, mAP: 68.75%
- ICFG-PEDES: Rank-1: 67.70%, mAP: 40.36%
- RSTPReid: Rank-1: 68.40%, mAP: 51.73%
These results indicate measurable improvements over prior approaches such as OCDL, RDE, and CFAM.
Furthermore, cross-domain transfers (e.g., CUHK-PEDES to RSTPReid) show that CONQUER maintains stability despite severe domain discrepancies, outperforming strong baselines like IRRA and SEN, often by margins exceeding 3–8% in Rank-1 accuracy.
Ablation and Robustness Studies
Ablation on RSTPReid highlights the additive and synergistic benefit of integrating both CARE and IQE: isolated modules only offer marginal gains, while their combination yields the best performance (Rank-1: 68.40%, mAP: 51.73%). This affirms that granular alignment must be complemented by adaptive query enrichment for optimal results.
Cross-domain robustness shows CONQUER generalizing across non-trivial source-target transfers. The attribute-driven enrichment particularly proves effective in mitigating performance drops when queries are underspecified or domain shifts are pronounced.
Implications and Future Directions
CONQUER demonstrates the critical need for both robust alignment during training and adaptive enrichment during inference in cross-modal retrieval. Its plug-and-play inference architecture is applicable for real-world TBPS deployments, including law enforcement and surveillance scenarios where queries are often incomplete.
Possible future directions include further reducing inference latency, enhancing attribute extraction reliability from anchor images, and extending the CARE-IQE paradigm to broader cross-modal retrieval tasks, e.g., retrieval from video corpora or multimodal event detection.
Conclusion
CONQUER advances TBPS by uniting fine-grained representation enhancement with dynamic, anchor-based query enrichment. Through extensive evaluation, the synergy between CARE and IQE mechanisms establishes state-of-the-art performance and robustness against domain and query-driven variability, substantiating its value for both academic investigation and practical deployment.