A Pragmatic VLA Foundation Model
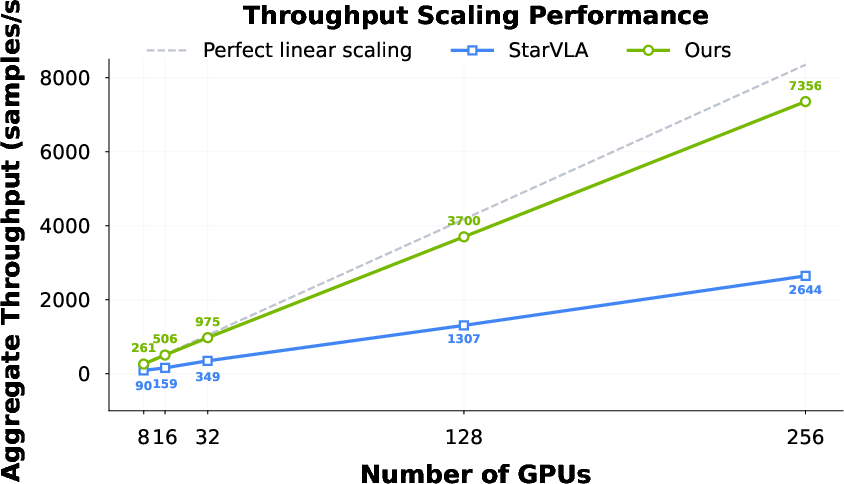
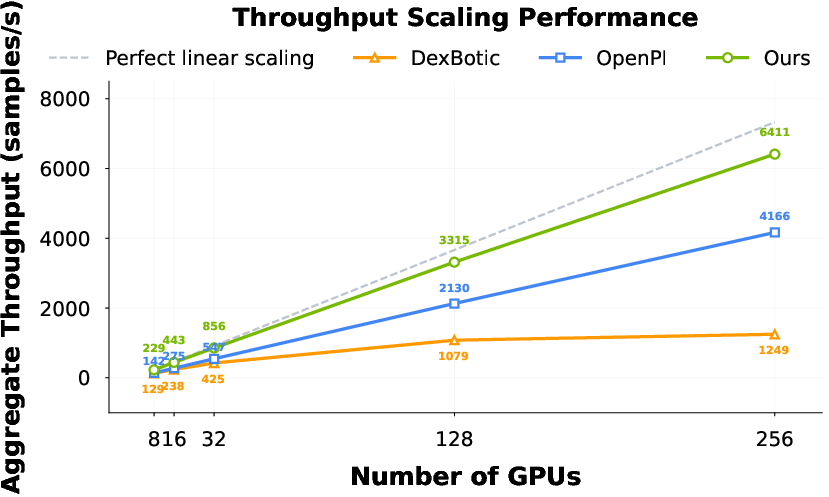
Abstract: Offering great potential in robotic manipulation, a capable Vision-Language-Action (VLA) foundation model is expected to faithfully generalize across tasks and platforms while ensuring cost efficiency (e.g., data and GPU hours required for adaptation). To this end, we develop LingBot-VLA with around 20,000 hours of real-world data from 9 popular dual-arm robot configurations. Through a systematic assessment on 3 robotic platforms, each completing 100 tasks with 130 post-training episodes per task, our model achieves clear superiority over competitors, showcasing its strong performance and broad generalizability. We have also built an efficient codebase, which delivers a throughput of 261 samples per second per GPU with an 8-GPU training setup, representing a 1.5~2.8$\times$ (depending on the relied VLM base model) speedup over existing VLA-oriented codebases. The above features ensure that our model is well-suited for real-world deployment. To advance the field of robot learning, we provide open access to the code, base model, and benchmark data, with a focus on enabling more challenging tasks and promoting sound evaluation standards.
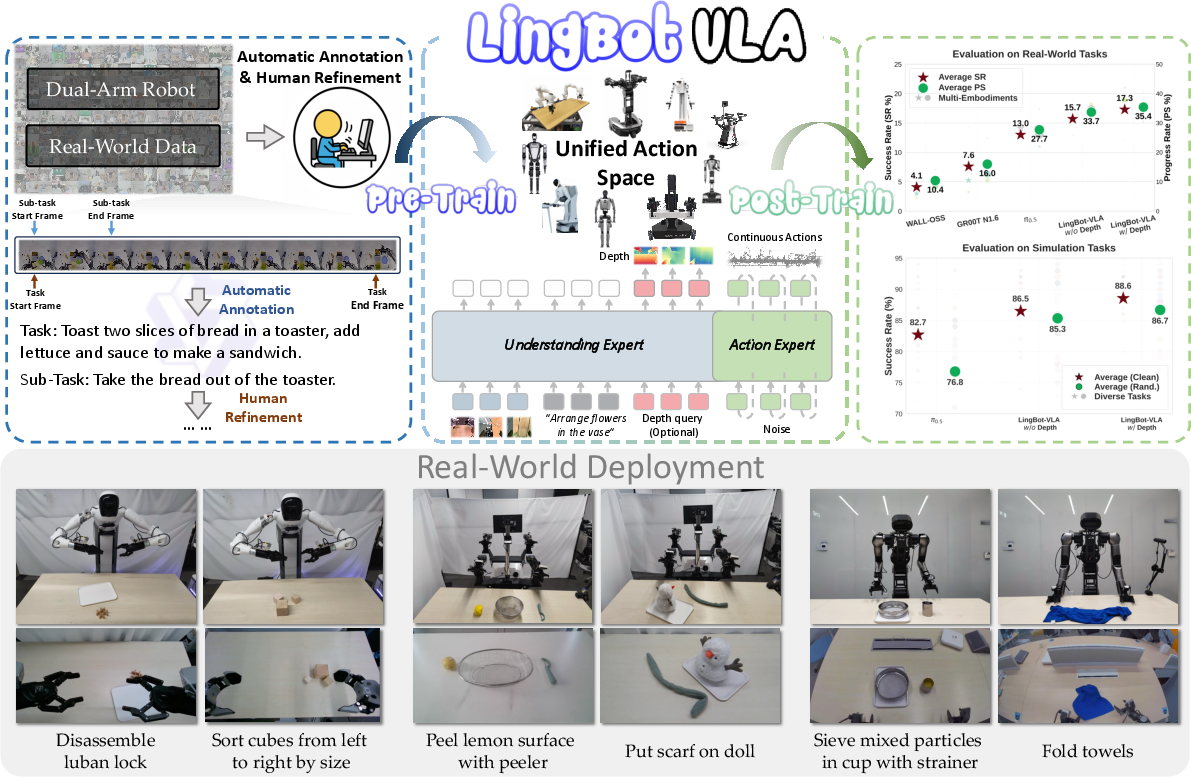


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about building a “foundation model” for robots that can see, understand language, and take actions. Think of it like a general-purpose robot brain that learns from lots of real-world examples so it can quickly adapt to many tasks and different robot bodies. The authors trained their Vision-Language-Action (VLA) model on about 20,000 hours of real robot data and built a fast training system. They then tested the model in a careful, fair way across different robots and many tasks to see how well it generalizes.
They also share their code, model, and evaluation data to help other researchers and engineers build better robots. In their open-source materials, this model is referred to as LingBot‑VLA.
Key Objectives (Questions They Wanted to Answer)
- Does training a robot model on a huge amount of real-world data really make it better across many tasks?
- How well can a single model handle many types of robots (not just one)?
- Can we build a training system that is fast and cost‑efficient so more people can try large‑scale robot learning?
- How much do 3D “depth” cues (like how far objects are) help with tricky manipulation tasks?
- What are fair, reliable ways to measure robot success in the real world?
Methods and Approach
The Data (What the model learned from)
- The team collected around 20,000 hours of robot manipulation from 9 popular dual‑arm robot setups (two arms, like a person).
- People controlled the robots (teleoperation) to perform many tasks (like picking up, stacking, sorting), and the robots recorded video from multiple cameras and the actions taken.
- They broke long videos into short clips that match “atomic actions” (small, clear steps), then used a large vision‑LLM to write precise instructions for tasks and sub‑tasks. This helps the robot link what it sees with what it should do.
The Model (How it thinks)
- The brain has two parts working together:
- A vision‑LLM (VLM) that understands images and text instructions (like “put the red bowl on the blue bowl”).
- An “action expert” that outputs smooth robot motions over time.
- They connect these parts using a Mixture‑of‑Transformers (MoT) design. You can imagine two teams in a classroom (vision‑language team and action team) that share attention and talk layer by layer, so the action team is constantly guided by what the vision‑language team understands.
- For generating actions, they use a technique called Flow Matching. In simple terms: start from a noisy, random guess of the robot’s movement, then learn a smooth path toward the correct movement. It’s like turning static into a clear song by learning how to “flow” from noise to the right notes.
Better 3D Awareness (Depth)
- The model learns 3D spatial cues—like how far or tall objects are—by aligning its visual features with a depth model (LingBot‑Depth). This “distillation” means the model gets extra geometry sense, which is important when placing or gripping objects accurately.
Training Efficiency (Making it fast and affordable)
- They optimized distributed training using a method called FSDP to split model parts across GPUs and save memory.
- They sped up attention (how the model focuses on important parts of the input) using specialized operators (FlexAttention).
- They used compiler‑level tricks to fuse operations, reducing overhead.
- Result: high throughput (up to 261 samples per second per GPU on 8 GPUs) and near‑linear scaling as you add more GPUs.
Evaluation (Proving it works)
- Real‑world benchmark: GM‑100 includes 100 diverse tasks. They tested across 3 different robot platforms and ran many trials per task under controlled, fair conditions (same robots, same tasks, randomized object positions).
- Metrics:
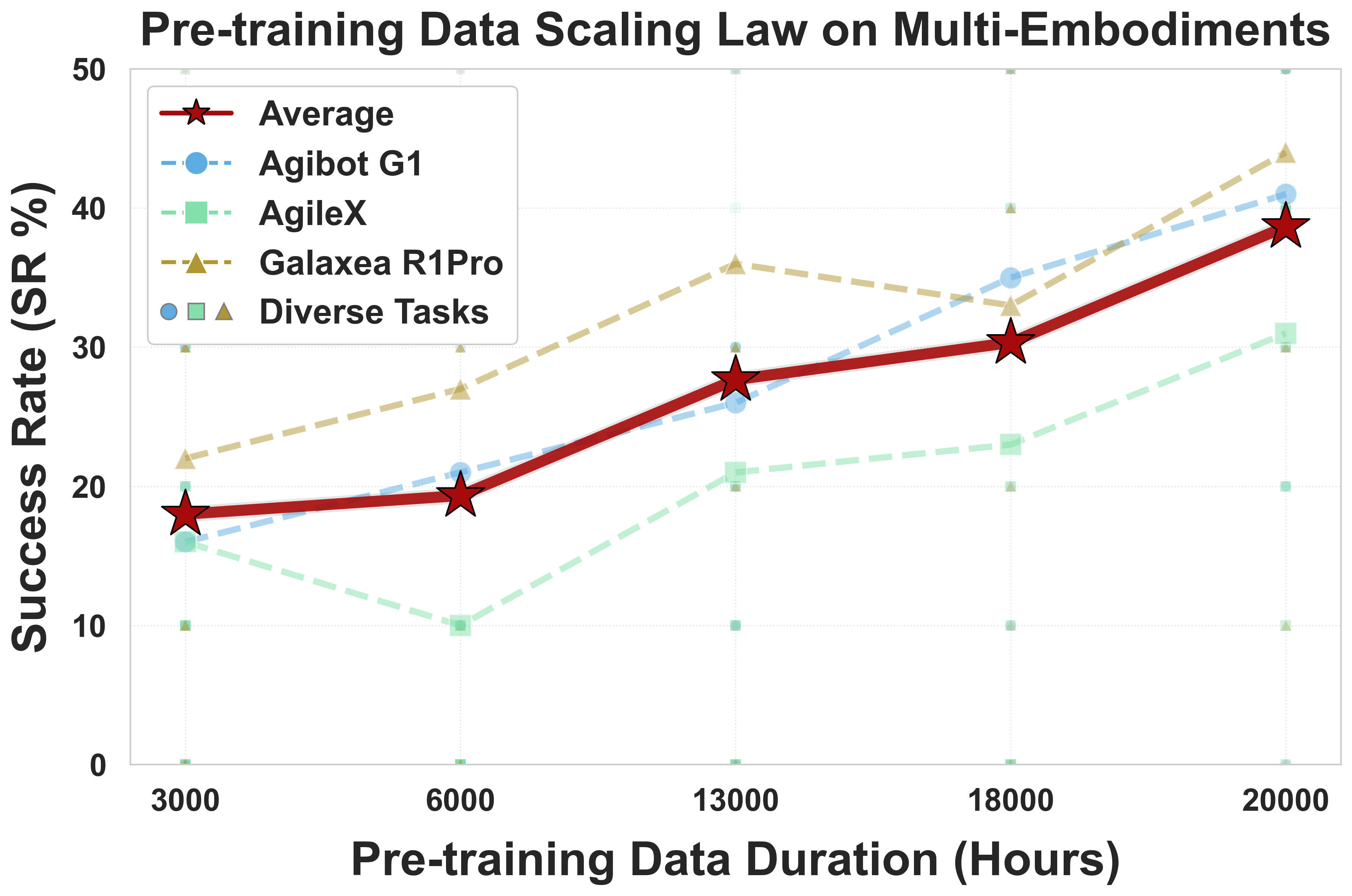
- Success Rate (SR): How often the task is fully completed within 3 minutes.
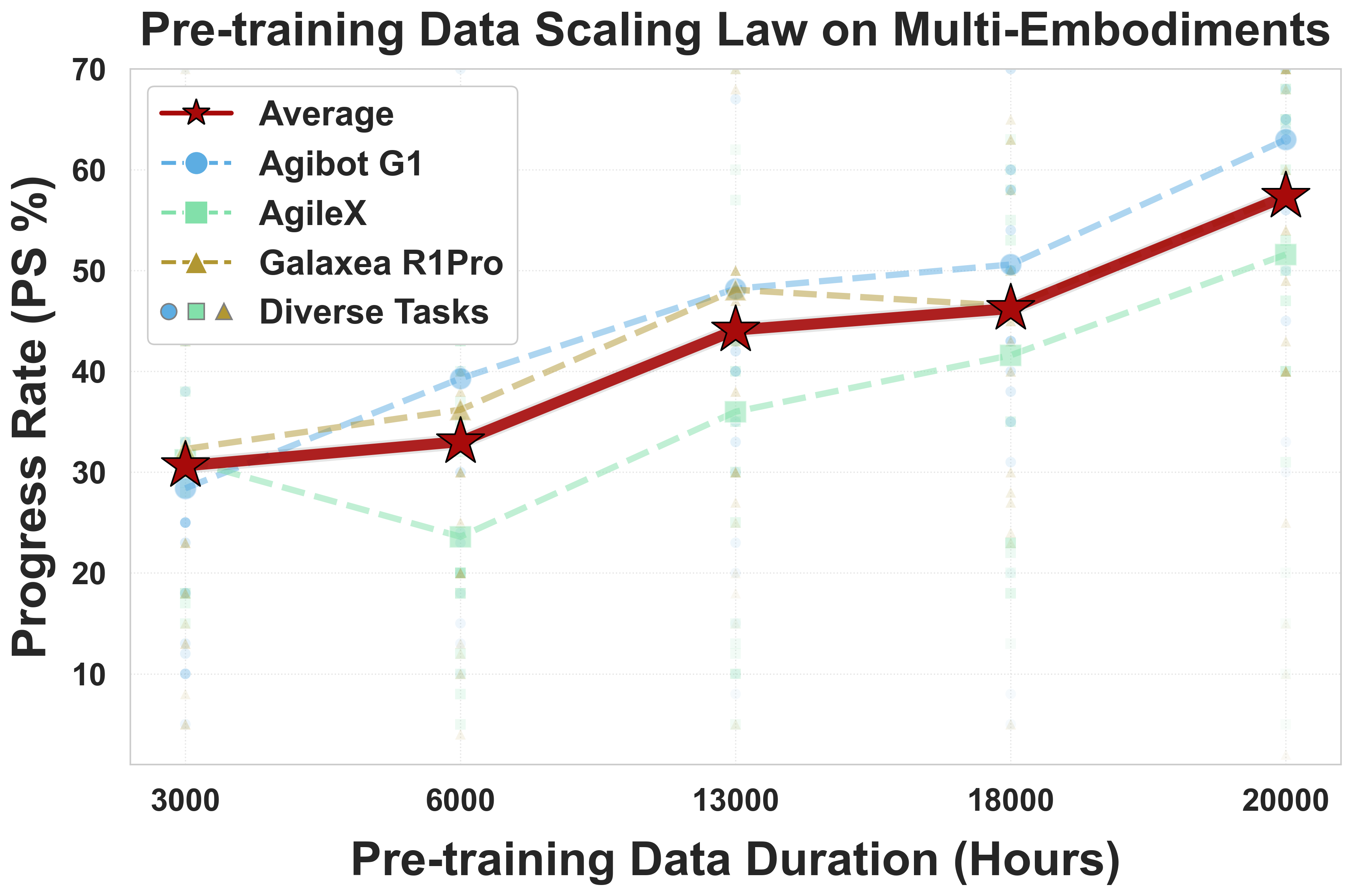
- Progress Score (PS): How many steps of a multi‑step task were completed (e.g., finishing 4 out of 6 steps gives a score of 4/6).
- Simulation benchmark: RoboTwin 2.0 with 50 tasks, tested in clean and randomized scenes (clutter, lighting, table height changes, etc.).
Main Findings and Why They’re Important
Here are the key results:
- More real data helps a lot: When they increased pre‑training from 3,000 to 20,000 hours, performance kept improving and did not plateau. This is strong evidence that “scaling up” real-world robot data leads to better generalization.
- Stronger real‑world performance: Across 3 platforms and 100 tasks, their model outperformed other known VLA baselines (like π₀.₅, GR00T N1.6, and WALL‑OSS) in both success rate and progress score. This shows it can handle many tasks and robot bodies.
- Depth makes manipulation better: Adding depth information improved average success rate and progress score over strong baselines, especially in tasks requiring precise 3D understanding.
- Faster training: Their codebase achieved the best training speeds compared to other open frameworks, and scaled well with more GPUs. This matters because faster training lowers costs and helps teams iterate quickly.
- Better with fewer examples: In post‑training (task‑specific finetuning), the model reached or beat the baseline’s performance using fewer demonstrations per task, showing strong data efficiency.
Implications and Potential Impact
- Big, diverse, real‑world datasets are worth it: The study shows that collecting lots of real robot data pays off with better general‑purpose skills.
- Generalist robots come closer to reality: A single model can be applied to different robots and tasks without starting from scratch, which could speed up deployment in homes, labs, and factories.
- Better benchmarks help everyone: Their careful evaluation methods and open data/code set higher standards for fair robot testing, making it easier to compare models and make real progress.
- 3D understanding is critical: Depth cues noticeably improve manipulation. Future robot models should keep investing in good spatial perception.
- Faster, cheaper training makes research more accessible: With an efficient codebase, more teams can explore large‑scale training without huge compute budgets.
In short, this work shows that a practical, scalable VLA foundation model—trained on lots of real robot data and optimized for speed—can generalize well to many tasks and robots. It provides solid evidence that “more and better real data + efficient training + fair testing” is a powerful recipe for building capable robot brains.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Real-world zero-shot generalization: The model is post-trained with 130 demonstrations per GM-100 task; it does not evaluate zero-shot or few-shot performance on unseen tasks, environments, or embodiments without per-task fine-tuning.
- Cross-embodiment transfer without hardware-matched data: Evaluations are conducted on the same robot units used for data collection; robustness to previously unseen robots (different kinematics, controllers, grippers, camera placements, sensor suites) is untested.
- Unified action space design: The paper does not detail how actions are normalized across robots with differing DoF, joint limits, gripper types, and control interfaces; a principled, embodiment-agnostic action parameterization remains unspecified.
- Long-horizon control: Action chunks use a fixed horizon
T=50, but the control frequency, receding-horizon strategy, and scalability to long-horizon tasks (multi-minute manipulation sequences, interleaved subtasks) are not analyzed. - Failure taxonomy and root-cause analysis: Real-world average success rates (~17–21% SR) remain low; the paper lacks a detailed breakdown of failure modes (perception errors, grasp failures, planning mistakes, controller issues) and targeted remedies.
- Depth distillation robustness: The depth-query alignment is evaluated only under nominal conditions; performance under depth failure modes (transparent/reflective objects, sensor noise, occlusions, miscalibration) is not assessed.
- Spatial method comparisons: The proposed depth distillation is not compared to alternative spatial VLA approaches (e.g., Spatial Forcing, explicit 3D scene representations, point clouds, voxel grids) via controlled ablations.
- Instruction annotation quality: Task/subtask language is generated by Qwen3-VL; the paper lacks measures of annotation accuracy, consistency, and bias, as well as the impact of noisy labels on downstream performance.
- Language grounding robustness: The model is not tested with naturalistic, varied, or ambiguous user instructions, paraphrases, multi-step natural language planning, or in interactive correction/feedback scenarios.
- Dataset diversity vs. volume disentanglement: Scaling experiments increase total hours, but the independent effects of action diversity, embodiment diversity, and environment diversity are not isolated or quantified.
- Data leakage controls: It is unclear whether pre-training data contain tasks overlapping with GM-100; explicit checks to prevent leakage and to quantify true generalization are not reported.
- Cross-site reproducibility: Benchmarks are executed on fixed platforms with standardized objects; performance across different labs, hardware tolerances, calibration differences, lighting, and background variability is not analyzed.
- Simulation-to-real gap: The model’s high simulation performance (Robotwin 2.0) vs. modest real-world SR is not investigated; the paper lacks a systematic sim-to-real gap analysis and mitigation strategies.
- Alternative action heads and objectives: Flow Matching is adopted without comparison to diffusion, autoregressive, latent dynamics, or hybrid RL-imitation objectives; trade-offs in stability, sample efficiency, and latency are untested.
- Architectural ablations: The Mixture-of-Transformers (shared self-attention) design, blockwise causal attention, and coupling strength between VLM and action expert are not ablated to justify architectural choices.
- Proprioceptive/haptic sensing: The model does not use force/torque, tactile, or compliance signals; the impact of adding haptics for contact-rich manipulation is unexplored.
- Controller and low-level stack details: The interplay between policy outputs and low-level controllers (impedance, velocity/position control, gains, safety constraints) is not described or evaluated across embodiments.
- Safety and reliability in deployment: Beyond simple termination criteria, the paper does not analyze safety incidents, near misses, long-run reliability, or integrate formal safety monitors and recovery behaviors.
- Data-efficient post-training scope: Data efficiency is shown for 8 tasks on one platform; broader coverage across all 100 tasks and multiple embodiments, and few-shot/active learning regimes, are not explored.
- Camera configuration dependence: The approach assumes three-view RGB(-D); robustness to fewer cameras, different viewpoints, or dynamic camera motion (e.g., mobile platforms) is not tested.
- Mobile and single-arm manipulation: The dataset and evaluations focus on fixed dual-arm tabletop setups; performance on single-arm, mobile, or mobile-manipulation scenarios is acknowledged as future work but remains untested.
- Deformable, contact-rich, and precision tasks: Capabilities on deformable objects, insertions, assemblies, tool use, and high-precision operations are not separately benchmarked or analyzed.
- Compute and cost transparency: Training throughput is reported, but end-to-end metrics (GPU hours, energy, wall-clock for 20,000-hour pre-training and post-training) and cost-to-performance curves are missing.
- Inference latency and real-time constraints: The effect of model size and architecture on closed-loop control latency, jitter, and stability across robots is not characterized.
- Benchmark fairness and optimization: Baselines are fine-tuned under a uniform pipeline; whether each baseline was trained with its native, best-performing settings and optimizations (to avoid under-tuning) is unclear.
- Dataset release and replicability: It is not explicit whether the full 20,000-hour pre-training dataset is publicly released; without it, independent replication of scaling results is limited.
- Interpretability and diagnostics: The paper does not provide attention maps, failure visualizations, or diagnostic tools to understand how language and vision cues influence action decisions.
Glossary
- Action expert: A specialized module that predicts and generates robot actions within the model architecture. "an initialized action generation module called `action expert'."
- Atomic actions: Minimal, indivisible action units used to segment and annotate robot behaviors in videos. "according to predefined atomic actions."
- Bidirectional attention: An attention pattern where tokens within a block can attend to each other in both directions. "all tokens within the same block employ bidirectional attention"
- Blockwise causal attention: Attention that enforces causal dependencies across predefined blocks while allowing full attention within each block. "we implement blockwise causal attention"
- Causal mask: An attention mask that prevents tokens from attending to future tokens, ensuring causality. "A causal mask is applied among these blocks,"
- Conditional Flow Matching: A generative modeling technique that learns a conditional vector field to map noise to data conditioned on observations. "through conditional flow matching."
- Cross-attention: An attention mechanism that aligns or fuses representations across different sequences or modalities. "applies cross-attention for dimensional alignment."
- Degrees of Freedom (DoF): The number of independent parameters that define a robot arm’s configuration or movement. "two 7-DoF arms"
- Diffusion-based action head: An action-generation component that uses diffusion models to produce robot control trajectories. "coupled with diffusion-based action head."
- Distillation loss: The objective used to align student representations with teacher (e.g., depth) signals during distillation. "distillation loss :"
- Distributed Data Parallel (DDP): A distributed training paradigm that replicates models across GPUs and synchronizes gradients. "OpenPI utilizes DDP"
- Egocentric: A first-person, agent-centered visual perspective used in robot perception. "to capture an egocentric, human-eye perspective."
- Embodiment: The physical configuration of a robot, including morphology and sensors, used to describe platforms. "three robotic embodiments"
- FlexAttention: An attention optimization technique/library used to accelerate sparse attention computation. "we leverage FlexAttention to optimize computation."
- Flow Matching: A continuous-time generative modeling framework that learns vector fields to transform noise into data. "We employ Flow Matching~\cite{lipman2022flow} for continuous action modeling,"
- Fully Sharded Data Parallel (FSDP): A memory-efficient distributed training method that shards model states across devices. "Fully Sharded Data Parallel (FSDP)"
- Hybrid Sharded Data Parallel (HSDP): A strategy that shards selected model components to balance memory usage and communication overhead. "Hybrid Sharded Data Parallel (HSDP)"
- Isomorphic arms: Robot arms with identical kinematics used to simplify control and data collection. "Robot control is achieved using isomorphic arms during the data collection process."
- Mixture-of-Transformers (MoT): An architecture that processes different modalities through separate transformer pathways with shared attention. "Mixture-of-Transformers (MoT) architecture"
- Multimodal conditioning: Conditioning action generation on fused inputs from multiple modalities such as vision, language, and state. "to establish multimodal conditioning for subsequent action generation."
- Parallel-jaw grippers: End-effectors with two parallel fingers used for grasping in manipulation tasks. "equipped with parallel-jaw grippers."
- Progress Score (PS): A metric quantifying partial task completion via subtask checkpoints. "Progress Score (PS):"
- Proprioceptive sequences: Time-series of internal robot states (e.g., joint positions/velocities) used for action prediction. "the robot's proprioceptive sequences"
- rosbag: A ROS data logging format used to record sensor streams, states, and predictions for reproducible evaluation. "recorded in rosbag format"
- Scaling behavior: How model performance trends change as data size or diversity increases. "Understanding the scaling behavior of VLA models is crucial"
- Scaling efficiency: The degree to which throughput or performance increases proportionally with more computational resources. "exhibits excellent scaling efficiency"
- Self-attention mechanism: The transformer operation that computes attention within a sequence to produce contextualized representations. "shared self-attention mechanism for layer-wise unified sequence modeling."
- Sparse attention: An attention computation pattern where only a subset of token pairs are attended, reducing cost. "is fundamentally a sparse attention process."
- Success Rate (SR): The proportion of trials that fully complete all task steps within time limits. "Success Rate (SR):"
- Teleoperation: Human-operated control of robots, often via VR or remote interfaces, used to collect demonstrations. "expert demonstrations via teleoperation"
- Throughput: The number of training samples processed per second per GPU, indicating efficiency. "achieves a throughput of $261$ samples per second per GPU"
- torch.bfloat16: A 16-bit floating-point format used to reduce memory and communication while maintaining numerical stability. "utilizing torch.bfloat16 for storage and communication."
- torch.compile: A PyTorch compilation feature that fuses operators to reduce kernel overhead and improve speed. "operator fusion (via torch.compile)"
- Vision distillation: A training technique to transfer spatial/geometric knowledge (e.g., depth) into a vision-LLM. "we adopt a vision distillation approach"
- Vision-Language-Action (VLA): A class of foundation models that map visual and language inputs to robotic actions. "Vision-Language-Action (VLA) foundation models"
- Vision-LLM (VLM): Models that jointly process vision and language; used as semantic backbones for VLA. "pre-trained VLM (i.e., Qwen2.5-VL~\cite{bai2025qwen2})"
- ZeRO (Zero Redundancy Optimizer): A distributed optimization technique that shards optimizer states to reduce memory redundancy. "Zero Redundancy Optimizer (ZeRO)"
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s released model (Lingbot-VLA), training codebase, datasets, and evaluation protocols, assuming access to dual‑arm robots with parallel grippers and multi‑camera setups.
- Healthcare (hospital backroom), Manufacturing, Logistics — dual-arm kitting and tray preparation
- What: Automate kitting, assembling instrument trays, packing sterile kits, and assembling small components that require two-handed coordination on tabletops.
- How: Post-train Lingbot‑VLA on 80–130 teleoperated demonstrations per task; use the depth‑enhanced variant for improved spatial precision. Integrate the GM‑100 evaluation protocol (SR/PS) as a pre-deployment gate.
- Tools/Workflow: Teleoperation data capture → Qwen3‑VL instruction annotation → post-training with the released high‑throughput codebase (FSDP2/FlexAttention) → on‑robot validation with SR/PS metrics.
- Assumptions/Dependencies: Controlled environment, standardized objects and layouts, safety guardrails, human overseer during ramp-up, regulatory procedures for sterile workflows.
- Retail backroom and e‑commerce fulfillment — sorting, reboxing, shelf‑ready packaging
- What: Sort returned items, rebox products, prepare shelf‑ready kits with dual‑arm manipulation guided by natural language task specs.
- How: Fine‑tune on site‑specific SKUs and packaging variations; enforce the standardized task protocol and termination criteria to ensure safe deployment.
- Tools/Workflow: “Record‑and‑deploy” pipeline (teleoperation → post‑train) with multi‑view cameras; task catalogs built from GM‑100 analogs.
- Assumptions/Dependencies: Object variability constrained; robust perception lighting; human‑in‑the‑loop for edge cases and partial progress recovery.
- Laboratory automation (non‑sterile prep) — sample rack organization and tube handling
- What: Organize racks, sort labeled tubes, cap/decap low‑torque containers, and set up tabletop experiments.
- How: Use depth‑distilled spatial queries for precise positioning; adopt partial progress scoring to monitor substeps (e.g., pick → place → verify).
- Tools/Workflow: Multi‑view, language‑conditioned manipulation; SR/PS logging to identify failure modes; targeted post‑training to specific lab SKUs.
- Assumptions/Dependencies: Tasks within gripper capabilities; safe handling protocols for fragile items; slip detection via external sensors recommended.
- Education and academic research — standardized embodied AI benchmarking and scaling laws
- What: Adopt GM‑100 tasks and RoboTwin 2.0 simulations to teach and study embodied AI, data scaling, and cross‑embodiment transfer.
- How: Use the open model, datasets, and training code to replicate scaling studies (3k–20k hours) and ablations (depth distillation, MoT, Flow Matching).
- Tools/Workflow: Course labs built around SR/PS evaluation; reproducible experiments with released checkpoints; PyTorch‑based code with FSDP2 and operator fusion.
- Assumptions/Dependencies: Access to compute clusters or cloud GPUs; two‑arm robots for real‑world labs; institutional safety frameworks.
- Software/MLOps — cost‑efficient large‑scale VLA training and iteration
- What: Integrate the provided codebase to reduce training time and GPU costs for internal VLA projects.
- How: Use FSDP2 sharding and FlexAttention under PyTorch 2.x; benchmark throughput (≈261 samples/s/GPU on 8 GPUs) and scale to 16–256 GPUs while tracking near‑linear scaling.
- Tools/Workflow: Shared “shard groups” for action experts; mixed precision; torch.compile operator fusion; standardized logging of throughput.
- Assumptions/Dependencies: Compatible PyTorch/CUDA stack; fast storage/network to avoid I/O bottlenecks; robust job orchestration.
- Simulation‑first training and sim‑to‑real transfer — multi‑task policy bootstrapping
- What: Pretrain in RoboTwin 2.0 randomized scenes to build robust multi‑task policies before limited real‑world post‑training.
- How: Start from released checkpoints; train on 2,500–25,000 sim demos; transfer the depth‑aware variant to real robots with environment‑matched camera placements.
- Tools/Workflow: Domain randomization (lighting, clutter, table heights); SR/PS progression tracking; small real‑world finetuning sets (≈80 demos/task).
- Assumptions/Dependencies: Calibration between sim cameras and real setup; differences in friction/contact may require additional demos.
- Robotics vendor ecosystems — platform‑specific task libraries
- What: Ship pre‑trained, platform‑adapted task bundles (e.g., “stack bowls,” “pack box,” “assemble tray”) for AgileX, Agibot G1, Galaxea R1Pro.
- How: Fine‑tune Lingbot‑VLA per embodiment; publish verified SR/PS and rosbag recordings for transparency; include natural language task schemas.
- Tools/Workflow: Vendor CI pipelines with GM‑100 protocols; rosbag–based auditing; checkpoint curation per hardware revision.
- Assumptions/Dependencies: Ongoing maintenance with new firmware; standardized camera rigs; licensing for Qwen2.5‑VL and LingBot‑Depth components.
- Policy and safety — pre‑deployment conformance testing using SR/PS standards
- What: Use GM‑100 SR/PS metrics, termination criteria, and multi‑platform testing to create internal safety gates and procurement benchmarks.
- How: Mandate 15 trials per task‑robot pair; randomized object poses; publish per‑task partial progress to identify failure modes; enforce collision aborts.
- Tools/Workflow: SR/PS dashboards; controlled evaluation setups; independent recording (third‑person views, robot states) for audits.
- Assumptions/Dependencies: Organizational adoption of standard protocols; safety officer oversight; staged release with human supervision.
- Daily life (semi‑structured settings) — cafeteria/table setting and tidying assistants under supervision
- What: Deploy dual‑arm robots in cafeterias or office pantries to set tables, stack dishes, tidy counters with human oversight.
- How: Post‑train on site‑specific tableware; run depth‑aware policies; rely on partial‑progress recovery for subtask failures; natural‑language instructions for variations.
- Tools/Workflow: Teleoperation fallback; SR/PS gating per shift; task playlists defined in language.
- Assumptions/Dependencies: Non‑fragile items; clearances enforced; human supervisor to intervene on edge cases.
- Robotics R&D — spatial perception module reuse
- What: Drop‑in depth‑distilled spatial queries for existing VLM‑based controllers to improve 3D awareness without full retraining.
- How: Align VLM learnable queries to LingBot‑Depth tokens via the released distillation loss; integrate into current policies.
- Tools/Workflow: Cross‑attention projection layers; per‑task evaluation to quantify gains.
- Assumptions/Dependencies: Availability of depth sensors or accurate depth estimates; compatible tokenization.
Long‑Term Applications
These applications require further research, higher reliability, broader datasets (e.g., single‑arm/mobile robots), specialized end‑effectors or sensors, and formal safety/regulatory approvals.
- Home bimanual assistants — general household tidying, laundry folding, dish handling
- Vision: Robust domestic robots that follow spoken instructions for multi‑step chores.
- Needed advances: Deformable object manipulation, tactile/haptic sensing, improved SR/PS across broader task distributions, long‑horizon planning and recovery.
- Dependencies: Mobile base integration, richer datasets beyond GM‑100, formal safety frameworks for operation near people.
- Hospital frontline support — sterile pack assembly and instrument handling with certification
- Vision: Certified dual‑arm robots assembling surgical packs and arranging instrument trays in sterile environments.
- Needed advances: Sterilization compliance, force/torque control for delicate instruments, near‑human reliability under SR/PS, traceable audit trails.
- Dependencies: Regulatory approvals (FDA/CE), validated failure‑handling protocols, operator training.
- Elder care and assisted living — meal prep and medication sorting
- Vision: Voice‑guided assistance for meal preparation, pill sorting, and organizing personal items.
- Needed advances: Human‑aware motion planning, fail‑safe stopping, perception under clutter and occlusion, adaptive grasping of diverse objects.
- Dependencies: Policy frameworks for in‑home safety, caregiver co‑supervision, economic feasibility.
- Mobile manipulation in dynamic environments — factory cells and service robots
- Vision: Robots moving between stations, reconfiguring workcells, handling diverse tasks with minimal re‑training.
- Needed advances: Integration of mobile platforms, multi‑sensor fusion (LiDAR, depth, tactile), larger multi‑embodiment datasets including single‑arm/mobile scenarios.
- Dependencies: Robust navigation and re‑localization; standardized interfaces across vendors.
- Agriculture and food processing — bimanual packing, trimming, and gentle handling
- Vision: Stationary or mobile robots packing produce, trimming plants, handling delicate food items.
- Needed advances: Soft grippers, force control, perception under natural variability (lighting, shape, texture), contamination prevention.
- Dependencies: Sector‑specific standards (food safety), domain‑specific datasets.
- Construction and prefabrication — assembly of components and fixtures
- Vision: Dual‑arm robots assembling medium‑complexity fixtures or prefabricated elements at benches.
- Needed advances: Handling heavier parts, compliance and alignment strategies, precise spatial reasoning beyond current depth distillation.
- Dependencies: Specialized end‑effectors, safety in industrial settings, standardized part libraries.
- Hazardous laboratory/energy sectors — chemical handling and nuclear decommissioning tasks
- Vision: Robots performing precise, risk‑intensive operations under language guidance with high reliability.
- Needed advances: Radiation/chemical‑safe hardware, advanced sensing (spectroscopy, force), extreme SR/PS targets and formal verification.
- Dependencies: Specialized hardware, rigorous certification, extensive task‑specific datasets.
- Cross‑vendor “robot app store” — shareable task bundles and rapid on‑prem fine‑tuning
- Vision: Marketplace of validated task packages with SR/PS scores, portable across embodiments.
- Needed advances: Standardized robot I/O schemas, sensor configurations, calibration tools, licensing and IP agreements.
- Dependencies: Industry consortium for standards, automated conformance testing.
- Zero‑shot/generalist industrial policies — language‑guided adaptation to new lines
- Vision: Policies that can perform unseen assembly or packing tasks from natural language and a handful of demonstrations.
- Needed advances: Larger and more diverse pretraining (beyond 20k hrs), improved spatial grounding, robust failure recovery, knowledge distillation across sectors.
- Dependencies: Data-sharing agreements, privacy/compliance for factory data, continued codebase optimization.
- Formal benchmarking for regulation and procurement — sector‑wide SR/PS certification
- Vision: National/industry standards using GM‑100‑like protocols for certifying service/manipulation robots.
- Needed advances: Task suites expanded to sector‑specific scenarios, third‑party audit pipelines, longitudinal reliability tracking.
- Dependencies: Policymaker adoption, independent test facilities, standardized reporting formats.
- Edge deployment and energy efficiency — compressed VLA for low‑cost robots
- Vision: Run capable policies on affordable hardware with limited compute and power budgets.
- Needed advances: Model compression/quantization for VLM+action experts, efficient multi‑camera pipelines on edge accelerators, adaptive inference.
- Dependencies: Hardware co‑design, robust performance under compression, toolchain maturity.
- Fleet learning and continual improvement — multi‑site data aggregation and updates
- Vision: Centralized training from distributed robot fleets, with safe over‑the‑air policy updates and automatic SR/PS monitoring.
- Needed advances: Privacy‑preserving data aggregation, drift detection, online post‑training, robust rollback mechanisms.
- Dependencies: MLOps for embodied systems, governance for data and updates, operator training.
Notes on feasibility and current limitations
- Average real‑world SR across 100 diverse tasks is ≈17% (with higher PS), indicating the need for task‑specific post‑training, structured environments, and human supervision for near‑term deployments.
- The model shows strong data efficiency (80 demos/task outperforming a baseline trained on 130) and favorable scaling up to 20,000 hours, suggesting continued gains with larger, more diverse datasets.
- Depth‑distilled spatial awareness improves robustness, but complex deformable objects, high‑precision force tasks, and mobile manipulation still require further research and hardware upgrades.
- The training codebase significantly reduces iteration costs, enabling faster R&D cycles and broader academic/industrial experimentation under standardized evaluation protocols.
Collections
Sign up for free to add this paper to one or more collections.