Trustworthy Evaluation of Robotic Manipulation: A New Benchmark and AutoEval Methods
Abstract: Driven by the rapid evolution of Vision-Action and Vision-Language-Action models, imitation learning has significantly advanced robotic manipulation capabilities. However, evaluation methodologies have lagged behind, hindering the establishment of Trustworthy Evaluation for these behaviors. Current paradigms rely on binary success rates, failing to address the critical dimensions of trust: Source Authenticity (i.e., distinguishing genuine policy behaviors from human teleoperation) and Execution Quality (e.g., smoothness and safety). To bridge these gaps, we propose a solution that combines the Eval-Actions benchmark and the AutoEval architecture. First, we construct the Eval-Actions benchmark to support trustworthiness analysis. Distinct from existing datasets restricted to successful human demonstrations, Eval-Actions integrates VA and VLA policy execution trajectories alongside human teleoperation data, explicitly including failure scenarios. This dataset is structured around three core supervision signals: Expert Grading (EG), Rank-Guided preferences (RG), and Chain-of-Thought (CoT). Building on this, we propose the AutoEval architecture: AutoEval leverages Spatio-Temporal Aggregation for semantic assessment, augmented by an auxiliary Kinematic Calibration Signal to refine motion smoothness; AutoEval Plus (AutoEval-P) incorporates the Group Relative Policy Optimization (GRPO) paradigm to enhance logical reasoning capabilities. Experiments show AutoEval achieves Spearman's Rank Correlation Coefficients (SRCC) of 0.81 and 0.84 under the EG and RG protocols, respectively. Crucially, the framework possesses robust source discrimination capabilities, distinguishing between policy-generated and teleoperated videos with 99.6% accuracy, thereby establishing a rigorous standard for trustworthy robotic evaluation. Our project and code are available at https://term-bench.github.io/.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Trustworthy Evaluation of Robotic Manipulation: Explained for a 14-year-old
What is this paper about?
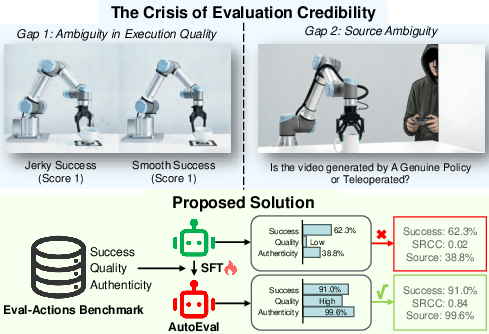
This paper focuses on how we judge robot actions—especially robots that learn by watching people (imitation learning) and by using vision and language (VA and VLA models). Today, robots are often scored with a simple “success or fail.” The authors argue this isn’t enough. A robot might “succeed” but move in a shaky, unsafe, or inefficient way, or the “success” might secretly come from a human controlling it. The paper introduces a new dataset and evaluation methods to make robot scoring more trustworthy, fair, and detailed.
What questions did the researchers ask?
The researchers wanted to answer two big questions:
- How well did the robot actually perform the task, beyond just “did it finish”? (Think: smoothness, safety, and speed.)
- Did the robot do the task by itself, or was a hidden human teleoperating (controlling) it?
How did they study it?
The team built two main things: a benchmark dataset and an evaluation system.
- Eval-Actions (the dataset)
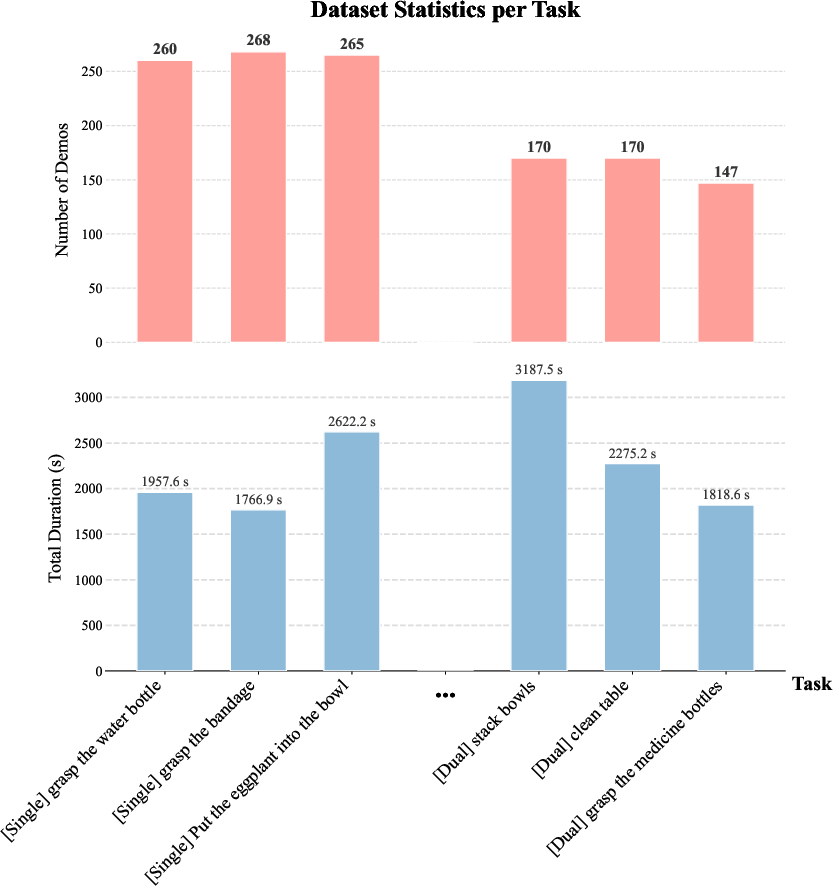
- What it contains: Thousands of videos and data from robots doing more than 150 tasks (like stacking bowls or folding towels), plus human-controlled examples.
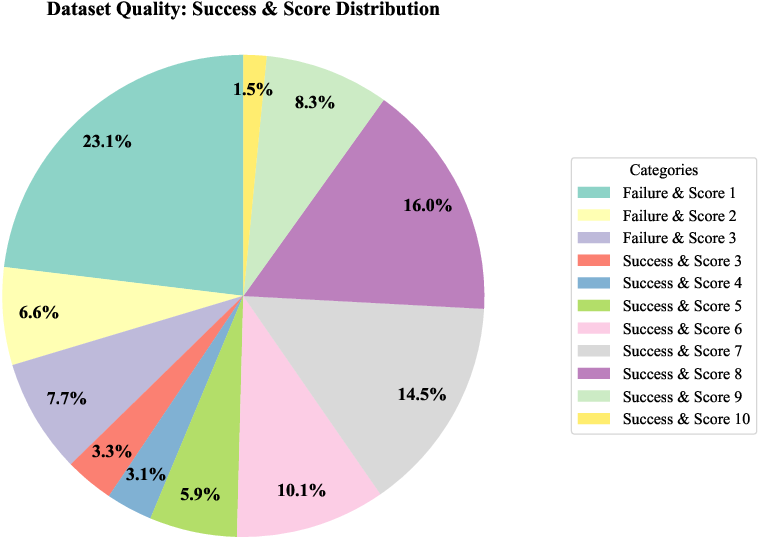
- Why it’s special: It doesn’t only include successes—it also includes failures. It has detailed labels that help judge the quality of each action, not just win/lose.
- How it scores quality: Like a report card with four parts:
- Success: Did the task get done?
- Smoothness: Were the movements steady, not shaky?
- Safety: Did the robot avoid collisions or risky motions?
- Efficiency: How quickly and cleanly did it finish?
- Three kinds of labels:
- Expert Grading (EG): Human experts rate performance (like “Excellent,” “Good,” “Poor”).
- Rank-Guided (RG): Experts rank which videos look better; a smart algorithm turns these rankings into scores that match human judgment.
- Chain-of-Thought (CoT): Experts write simple reasons explaining the score (like “the robot dropped the towel, so the score is lower”).
- AutoEval (the evaluation system)
- Goal: Automatically watch a robot video and judge:
- The action quality score
- Whether it succeeded
- Whether the video came from a fully autonomous robot or from human teleoperation
- Two versions:
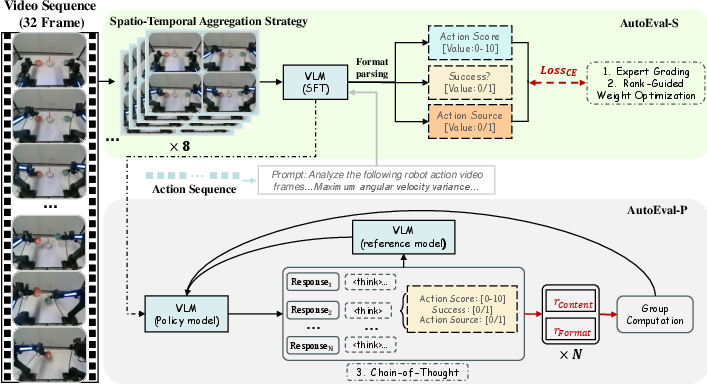
- AutoEval-S (Small): Great for scoring and success detection. It uses:
- Spatio-Temporal Aggregation: Imagine turning a short flipbook of frames into a smart collage so you can see both key moments and smooth motion without using too much computer memory.
- Kinematic Calibration Signal: Like a fitness tracker for the robot’s joints, it adds stats (speed, acceleration) to spot shakiness or smoothness more precisely.
- AutoEval-P (Plus): Built for deeper reasoning and explanations (CoT). It uses GRPO (Group Relative Policy Optimization), a reinforcement learning method. Think of it like practicing multiple explanations, rewarding the most accurate, well-formatted ones that match the facts, and gently penalizing bad guesses or messy answers.
- A helpful algorithm detail (made simple): Rank-Guided Weight Optimization
- The system tries many weight combinations (like mixing ingredients) to make automatically computed scores line up with how human experts ranked the videos. It uses a Genetic Algorithm—basically “evolution” for numbers—to find the best combo that matches human judgment.
What did they find and why is it important?
- Better matching with expert judgments:
- AutoEval’s predicted quality scores strongly match expert rankings (high correlation), especially:
- 0.81 with Expert Grading (EG)
- 0.84 with Rank-Guided (RG)
- This means the system is good at telling which robot runs look better, not just whether they finished.
- Strong source authenticity detection:
- It can tell if a video is from a real autonomous robot or human teleoperation with up to 99.6% accuracy.
- This is crucial for honesty in robot research—no more sneaky “human-in-the-loop” successes pretending to be robot autonomy.
- Reliable success detection:
- Around 90–91% accuracy for recognizing whether the task actually succeeded.
- Beats general-purpose AI models:
- Standard vision-LLMs (without fine-tuning) barely matched human scoring. AutoEval, trained on Eval-Actions, did much better.
- Catches subtle problems:
- AutoEval spots issues like duplicate, jittery movements and unsafe behaviors that simple “success/fail” misses.
- The reasoning-focused AutoEval-P reduces “hallucinations” (made-up explanations) by grounding its score in what’s visually true (e.g., noticing when the towel was actually dropped).
What’s the impact?
This work helps move robotics beyond basic “did it work” scoring to “how well did it work, and was it truly autonomous?” That matters because:
- It makes robot evaluations fairer and more trustworthy across labs and companies.
- It supports safer real-world robots by rewarding smooth, safe, efficient behavior—not just lucky successes.
- It helps prevent cheating or confusion about whether a robot really did something on its own.
- It provides a high-quality benchmark with failures and fine-grained labels, which can improve future training and testing.
- In the long run, it can guide better robot design and regulation, because we can measure what really matters for people’s safety and confidence.
Overall, the paper sets a new standard for judging robot actions: detailed, transparent, and hard to fake.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Inter-rater reliability is not reported for Expert Grading (e.g., Cohen’s κ, Krippendorff’s α), leaving uncertainty about annotation consistency and an upper-bound “human ceiling” for SRCC to contextualize the reported 0.81–0.84.
- The Rank-Guided (RG) weight optimization lacks transparency on global vs. per-task weighting, sensitivity analysis, and robustness to overfitting, making it unclear whether the composite score generalizes across task families and embodiments.
- Chain-of-Thought (CoT) evaluation focuses on numeric accuracy but does not assess explanation quality (faithfulness, factuality, counterfactual consistency) or human trust in the rationales; standardized CoT-specific metrics are missing.
- Authenticity classification (teleoperation vs. policy) may exploit dataset-specific artifacts (e.g., camera viewpoints, UI overlays, timing/replay patterns), but adversarial robustness to obfuscation or mimicry (e.g., teleop that mimics policy jitter, or smoothed policies) is not tested.
- Cross-embodiment generalization appears limited (source accuracy drops to 90%; score SRCC to 0.71–0.75 on Franka), with no broad evaluation across diverse hardware (gripper types, actuation, compliance) or heterogeneous control stacks.
- The safety dimension is defined via “hazardous interactions/collisions” but lacks instrumented sensing (force/torque, tactile) or calibrated thresholds; near-miss detection, contact quality, and human-proximal safety are not rigorously measured.
- Efficiency normalization (“baseline operator performance within spatial zones”) is under-specified (zone definition, operator selection, per-task/per-robot calibration), making reproducibility and fairness across initial conditions unclear.
- Kinematic smoothness is assessed in joint space (variance of velocity/acceleration) without normalizing for joint ranges, gear ratios, or controller rates; end-effector trajectory smoothness, jerk, and energy metrics are not incorporated.
- Dataset diversity and ecological validity are insufficiently characterized (object taxonomy, clutter, lighting, occlusions, long-horizon sequences, deformable/fragile objects, dynamic environments); it is unclear how representative the 150+ tasks are of real-world deployment.
- Failure coverage (2.8k episodes) lacks a taxonomy (e.g., perception errors, grasp failures, path planning lapses, force misregulation), severity labeling, or recovery behaviors, limiting diagnostic value and downstream training uses.
- No analysis of multi-view contributions (wrist/head/third-person): ablations for single-view vs. multi-view, view fusion strategies, and view-specific bias or failure modes are missing.
- The spatio-temporal aggregation strategy is not accompanied by thorough ablations (frame density k, token budget, aliasing artifacts), failure analyses, or guidelines for selecting parameters under memory and latency constraints.
- Real-time feasibility is not evaluated (inference latency, VRAM footprint at deployment, on-robot compute requirements), which is critical for using AutoEval online for monitoring or gating policy execution.
- Uncertainty quantification and calibration are absent (e.g., predictive intervals for scores, reliability diagrams for success/source classifiers), limiting trust and operational decision-making in safety-critical contexts.
- Statistical significance, confidence intervals, and variability across runs/seeds are not reported for SRCC/AUC/F1, leaving the robustness of improvements unclear.
- Generalization across tasks and environments is not systematically tested (OOD objects, background shifts, lighting changes, camera placement variation, sim-to-real transfer), nor are domain adaptation strategies evaluated.
- Source labels (teleoperation vs. policy) lack a formal verification protocol (e.g., audit trails, input device logs, session metadata), and do not consider gray zones (scripted primitives, semi-autonomous assistance), risking label noise.
- Integration of AutoEval into policy training is unexplored (e.g., as a reward or constraint for improving smoothness/safety), and online learning loops that use evaluator feedback to reduce unsafe behaviors are not demonstrated.
- The evaluator’s susceptibility to adversarial inputs (video tampering, motion retiming, synthetic noise, camera spoofing) is not assessed, leaving open the risk of evaluation spoofing.
- The dataset omits richer modalities (force/torque, tactile, audio beyond RGB-D and joint kinematics) that would strengthen safety and authenticity judgments; the effect of adding these modalities remains an open avenue.
- Weighting of smoothness, safety, efficiency is task- and application-dependent, but mechanisms for user-tunable or context-aware weighting (and their impact on correlations) are not provided.
- Success classification uses a fixed 0.5 threshold; threshold calibration under class imbalance, cost-sensitive settings, or deployment-specific priors is not explored.
- The paper does not benchmark against human evaluators as a baseline for authenticity verification and success detection, nor does it report how close AutoEval is to human performance under identical conditions.
- Data licensing, annotation release completeness (EG/RG/CoT), and privacy considerations for human operators are not detailed, which may limit community adoption and reproducibility.
- The list of included policies, their autonomy levels, and distribution across tasks are under-specified, impeding assessment of how well authenticity and quality evaluations generalize to new or stronger policy families.
- Long-horizon and mobile manipulation tasks, multi-contact dexterity, and human-robot collaboration scenarios are not featured or separately analyzed, constraining claims about “trustworthy evaluation” in broader embodied settings.
Glossary
- Action Chunking with Transformers (ACT): A transformer-based method that segments and models action sequences for robotic control. "Techniques such as Action Chunking with Transformers (ACT) \cite{aloha} and Diffusion Policies \cite{dp1} have demonstrated exceptional capabilities in modeling complex, multi-modal action distributions, enabling high-precision manipulation."
- Action Quality Assessment (AQA): A domain that measures how well an action is executed rather than simply recognizing it. "Action Quality Assessment (AQA) quantifies how well an action is executed, distinct from the classification task of action recognition."
- Advantage (RL): A reinforcement learning signal that measures how much better an action is compared to an average baseline, used to guide policy updates. "First, we compute the total reward for each output utilizing Eq. \ref{eq:total_reward} and derive the advantage value ."
- Authenticity Verification: The process of ensuring that observed robotic performance is genuinely autonomous rather than teleoperated. "Crucially, it provides an authoritative Authenticity Verification, distinguishing policy-generated actions from teleoperation with 99.6\% accuracy."
- AutoEval Plus (AutoEval-P): A variant of the evaluation architecture optimized for Chain-of-Thought reasoning using GRPO. "AutoEval Plus (AutoEval-P) incorporates the Group Relative Policy Optimization (GRPO) paradigm to enhance logical reasoning capabilities."
- AutoEval Small (AutoEval-S): A lightweight evaluation model that uses spatio-temporal aggregation and a kinematic calibration signal for fine-grained assessment. "AutoEval Small (AutoEval-S) leverages Spatio-Temporal Aggregation for semantic assessment, augmented by an auxiliary Kinematic Calibration Signal to refine motion smoothness;"
- Chain-of-Thought (CoT): An annotation and reasoning paradigm where models or experts provide step-by-step justifications for their evaluations. "Chain-of-Thought (CoT)."
- Cross-Entropy Loss: A standard loss function for training classification or structured text generation models. "It generates structured text predictions; following format decomposition, the model is optimized via Supervised Fine-Tuning (SFT) using Cross-Entropy Loss."
- Degrees of Freedom (DoF): The number of independent joint or actuator variables that define a robot’s configuration. "precise kinematic records (7/14-DoF Joint Trajectories)"
- Diffusion Policies: Generative control methods that sample actions via diffusion processes to model complex action distributions. "Techniques such as Action Chunking with Transformers (ACT) \cite{aloha} and Diffusion Policies \cite{dp1} have demonstrated exceptional capabilities in modeling complex, multi-modal action distributions"
- Distribution Alignment: A post-processing step to match the scale and distribution of algorithmic scores to human scores. "To ensure consistency, we perform a final Distribution Alignment via Z-score normalization."
- End-effector: The tool or gripper at the end of a robot arm that interacts with the environment. "every trajectory includes the full 7-DoF joint angles and end-effector states"
- End-to-end learning: Training policies that map raw sensory inputs directly to actions without handcrafted modules. "The paradigm of robotic control has evolved from specialized primitives \cite{grasp1, tro2, tro_GRASP} to end-to-end learning."
- Expert Grading (EG): Human expert ratings used as ground truth for fine-grained action quality. "Expert Grading (EG)."
- Fine-Grained Action Quality: A detailed evaluation metric that assesses smoothness, safety, efficiency, and success of task execution. "To address this limitation, we introduce âFine-Grained Action Quality\" as a core evaluation criterion."
- Gaussian kernel-based soft regression: A reward shaping method that provides smooth, continuous feedback for score prediction in RL. "To mitigate the sparsity of binary rewards in regression tasks, we formulate a Gaussian kernel-based soft regression mechanism."
- Genetic Algorithm (GA): An evolutionary optimization technique used to tune weights for kinematic scoring to match expert rankings. "We then formulate a composite scoreâaggregating smoothness, success indicators, collision penalties, and human scoresâand optimize the weights using Genetic Algorithm (GA) to minimize the discrepancy between the scores and expert rankings."
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that optimizes policies via group-wise advantages and KL regularization without a value network. "Addressing the complexity of CoT generation, we adopt the Group Relative Policy Optimization (GRPO) paradigm \cite{GPRO, guo2025deepseek}, integrating Reinforcement Learning (RL) to fortify the VLM's physical reasoning capabilities."
- Kinematic Calibration Signal: An auxiliary input containing motion statistics to help the model assess smoothness despite video artifacts. "It compensates for video compression artifacts by providing explicit motion statistics, ensuring precise smoothness quantification without dominating the semantic evaluation."
- Kinematic metrics: Quantitative measures of motion such as velocities and accelerations used to assess smoothness and stability. "Smoothness is quantified via kinematic metrics, including joint angular velocity and acceleration variance."
- Kullback-Leibler (KL) divergence: A regularization term that penalizes deviation from a reference policy during RL fine-tuning. "To prevent the model from deviating excessively from its initial linguistic capabilities (catastrophic forgetting), we incorporate a Kullback-Leibler (KL) divergence penalty"
- LoRA: Low-Rank Adaptation, a parameter-efficient fine-tuning technique for large models. "Each model is fine-tuned with LoRA \cite{hu2022lora} for only 20 epochs"
- Multimodal model: A model that processes multiple input modalities, such as video frames and kinematic text prompts. "Consequently, the multimodal model , parameterized by , processes both the visual keyframes and the physics-aware prompt"
- Open X-Embodiment (OXE): A large-scale aggregated dataset for cross-embodiment robotic learning. "the Open X-Embodiment (OXE) dataset \cite{openx} aggregated over one million trajectories from laboratories worldwide"
- Point clouds: 3D data representations of spatial points used to enhance manipulation policies’ spatial understanding. "methods like DP3 \cite{dp3} and MP1 \cite{sheng2025mp1} have extended these capabilities by incorporating 3D point clouds, significantly enhancing spatial generalization."
- Proximal Policy Optimization (PPO): A widely used RL algorithm; referenced as a baseline relative to GRPO. "GRPO offers a distinct advantage over standard PPO by eliminating the need for a separate value network"
- Rank-Guided (RG): An evaluation protocol where human rankings guide weight optimization and score calibration. "Rank-Guided preferences (RG)"
- Reinforcement Learning (RL): A training paradigm where policies are optimized via rewards, used to strengthen CoT reasoning in AutoEval-P. "integrating Reinforcement Learning (RL) to fortify the VLM's physical reasoning capabilities."
- RGB-D: Combined color (RGB) and depth sensing used as multimodal input in robotic datasets. "This includes raw sensory data (RGB, Depth), precise kinematic records (7/14-DoF Joint Trajectories)"
- Source Authenticity: The veracity of whether a trajectory is produced by an autonomous policy or by human teleoperation. "Source Authenticity (i.e., distinguishing genuine policy behaviors from human teleoperation)"
- Source discrimination: A mechanism to classify whether a trajectory originates from a policy or teleoperation. "we ... introduce a specialized source discrimination mechanism within the AutoEval architecture."
- Spearman’s Rank Correlation Coefficient (SRCC): A statistic that measures the monotonic correlation between predicted and ground-truth rankings. "achieving Spearmanâs Rank Correlation Coefficients (SRCC) of 0.81 and 0.84 under the EG and RG protocols, respectively."
- Spatio-Temporal Aggregation Strategy: A method to compress dense motion cues into composite frames to preserve temporal detail within token limits. "To mitigate the trade-off between temporal resolution and computational efficiency, we propose a Spatio-Temporal Aggregation Strategy"
- Supervised Fine-Tuning (SFT): Task-specific training of a model using labeled data to improve evaluation performance. "the model is optimized via Supervised Fine-Tuning (SFT) using Cross-Entropy Loss."
- Teleoperation: Human-driven control of a robot, often used to collect expert demonstrations. "distinguishing genuine policy behaviors from human teleoperation"
- Trajectory provenance: The origin of an execution trajectory, crucial for verifying autonomy vs. human control. "the trustworthiness of the evaluation is further compromised by the uncertainty of trajectory provenance (Gap 2)."
- Uniformity metrics: Variance-based measures of joint velocity and acceleration used to detect instability. "we define the uniformity metrics () as the maximum variance across all joints"
- VRAM: GPU memory required for processing visual tokens, a constraint in high-frame input settings. "it incurs a heavy computational burden, manifesting as excessive visual tokens and prohibitive VRAM usage."
- Z-score normalization: Standardization technique used to align algorithmic scores with human scoring scales. "The final calibrated score is computed as: ... via Z-score normalization."
Practical Applications
Practical, real-world applications of “Trustworthy Evaluation of Robotic Manipulation: A New Benchmark and AutoEval Methods”
Below, we distill actionable use cases that arise from the paper’s benchmark (Eval-Actions) and evaluator (AutoEval-S/AutoEval-P), mapped to sectors and flagged as Immediate Applications or Long-Term Applications. Each item includes potential tools/products/workflows and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Fine-grained pre-deployment evaluation and acceptance testing
- Sectors: robotics, manufacturing, logistics, consumer/service robotics, healthcare (non-surgical), agritech
- What: Replace binary “success rate” with multi-metric assessment (success, smoothness, safety, efficiency) to decide if a manipulation policy is field-ready. Use AutoEval-S’s SRCC ~0.81–0.84 and source verification (~99.6%) for trustable go/no-go decisions.
- Tools/workflows: “Evaluation suite” microservice; batch test runner over validation scenarios; dashboard with radar charts and trend lines; ROS/ROS2 integration node for uploading videos/kinematics and retrieving scores.
- Assumptions/dependencies: Access to RGB(-D) video and joint telemetry; camera placement comparable to training; evaluator fine-tuned for the robot/task class; compute for inference; acceptance thresholds calibrated to risk profile.
- CI/CD quality gating for robot MLOps
- Sectors: software and robotics platforms
- What: Add an AutoEval-powered gate in model deployment pipelines; block rollouts that regress on execution quality, safety, or efficiency even if success rate is unchanged.
- Tools/workflows: GitHub/GitLab CI step; containerized AutoEval runner; regression detection against baselines; automatic A/B comparisons.
- Assumptions/dependencies: Stable dev/test datasets; reproducible telemetry capture in simulation and real; policy versioning; GPU availability for accelerated inference.
- Source authenticity auditing (detect hidden teleoperation)
- Sectors: academia, industry R&D, benchmarking platforms, competitions, procurement
- What: Verify “autonomous” claims by classifying video/trajectory source (policy vs. teleop) with reported ~99.6% accuracy; deter benchmark gaming and strengthen reproducibility.
- Tools/workflows: “Authenticity verifier” service; badges in leaderboards and internal QA reports; vendor audit checklists.
- Assumptions/dependencies: Distribution match to target domain; adversarial spoofing resistance not formally guaranteed; potential need for periodic re-fine-tuning as tactics evolve.
- Dataset curation and failure mining
- Sectors: academia, labs, data operations for robotics
- What: Auto-score collected trajectories to filter out low-quality/out-of-distribution data, upsample hard failures, and attach CoT rationale (with AutoEval-P) for explainable triage.
- Tools/workflows: Data lake scoring pipeline; “smart sampler” for training sets; curator UI showing quality distributions and CoT summaries.
- Assumptions/dependencies: Sufficient coverage of your robot/task in the evaluator; accurate time-normalization for efficiency comparisons; storage/compute for large-scale batch scoring.
- Vendor benchmarking, SLAs, and procurement support
- Sectors: manufacturing, logistics, retail, facilities services
- What: Compare offerings with standardized, fine-grained metrics instead of success-only demos; embed quality clauses in SLAs (e.g., minimum smoothness/safety thresholds).
- Tools/workflows: Standardized test suite derived from Eval-Actions task templates; procurement scorecards; periodic re-audits.
- Assumptions/dependencies: Agreement on task definitions; matched sensor setups; clear normalization for efficiency (distance/time) across environments.
- Post-mortem safety and incident analysis
- Sectors: all robotic deployments; insurance/risk management
- What: Diagnose near-misses or incidents using fine-grained quality timelines to identify jitter, collisions, or inefficiencies leading up to failure.
- Tools/workflows: Incident replay with AutoEval overlays; anomaly heatmaps; safety committee reports.
- Assumptions/dependencies: Retained logs (video + kinematics); consistent timestamps; privacy/compliance approvals.
- Simulation-to-real validation and progress tracking
- Sectors: robotics R&D
- What: Use the same evaluator across sim and real benches to quantify sim-to-real gaps on smoothness/safety/efficiency, not only task success.
- Tools/workflows: Paired sim/real scenario bank; domain gap dashboards; ablation tracking (e.g., controller changes).
- Assumptions/dependencies: Comparable camera viewpoints; realistic sim kinematics/dynamics; calibration of evaluator to both domains.
- Teleoperator training and QA
- Sectors: teleoperation platforms, remote assistance services
- What: Score human operators on smoothness/safety/efficiency to guide training and certify “assist quality.”
- Tools/workflows: Operator performance dashboards; targeted coaching from CoT rationales; certification badges.
- Assumptions/dependencies: Operator consent and privacy; fair normalization across tasks and initial conditions.
- Academic benchmarking and reproducibility
- Sectors: academia, open-source community
- What: Adopt Eval-Actions to supplement success rates with dense labels (EG, RG, CoT) and failure cases; standardize reporting of execution quality and authenticity.
- Tools/workflows: Leaderboards with multi-metric ranking; public code templates; challenge tracks rewarding robust, smooth, and safe execution.
- Assumptions/dependencies: Community buy-in; clear evaluation protocols; updates to combat overfitting to the benchmark.
- Quality analytics for consumer/service robots
- Sectors: consumer robotics, hospitality, retail
- What: Batch scoring of in-the-wild logs to identify problematic tasks/contexts (e.g., table clearing with high jitter), feeding into OTA updates and user guidance.
- Tools/workflows: Opt-in telemetry program; periodic cohort reports; auto-generated “skill improvement” suggestions.
- Assumptions/dependencies: User privacy; compute/energy constraints; heterogeneous home environments may require domain adaptation.
Long-Term Applications
- Real-time autonomy gating and shared control handover
- Sectors: logistics, manufacturing, healthcare, domestic service robots
- What: Integrate a lightweight on-robot evaluator to detect degrading quality in-flight and trigger slowdown, safer trajectory re-planning, or handover to a human.
- Tools/products: “Safety copilot” runtime; ROS2 behavior tree plugin; on-edge model distillation for latency.
- Assumptions/dependencies: Tight latency budgets; robustness under partial observability; on-device compute; high recall for unsafe behaviors.
- Evaluator-as-reward for policy improvement (RL/PPO/GRPO/DPO-style)
- Sectors: robotics research and product teams
- What: Use AutoEval as a learned reward model to optimize policies for smoothness/safety/efficiency, not just task completion—akin to RLHF for embodied agents.
- Tools/workflows: Preference-based optimization; reward shaping from evaluator scores/CoT; closed-loop training with periodic evaluator refresh.
- Assumptions/dependencies: Avoiding reward hacking/Goodhart’s law; maintaining evaluator generalization; alignment between evaluator and deployment distribution.
- Standardized certification and regulatory assessment
- Sectors: policy/regulation, safety certification bodies, compliance
- What: Define multi-metric conformance tests for manipulation safety and execution quality; formal authenticity checks to certify “no hidden teleop.”
- Tools/workflows: NIST/ISO-style test suites; certification labs; standardized reports for public disclosure.
- Assumptions/dependencies: Multi-stakeholder consensus; evolving standards for camera/telemetry requirements; legal and ethical frameworks.
- Insurance underwriting and risk-based pricing for robotics
- Sectors: finance/insurance, enterprise risk management
- What: Use longitudinal quality metrics to quantify operational risk and adjust premiums; incentivize safer/smoother policies.
- Tools/workflows: Risk dashboards; incident likelihood models; contractual thresholds tied to evaluator KPIs.
- Assumptions/dependencies: Access to de-identified operational data; actuarial validation; safeguards against gaming metrics.
- Cross-domain extensions: surgical robotics, exoskeletons, drones, mobile manipulation
- Sectors: healthcare (surgical, rehab), wearables, aerial/field robotics
- What: Adapt fine-grained AQA and authenticity verification to domains where smoothness and safety are critical but task success alone is insufficient.
- Tools/workflows: Domain-specific kinematic cues (e.g., force/torque, contact events), tailored CoT templates (clinical/aviation semantics).
- Assumptions/dependencies: New datasets and labels; stronger privacy constraints; specialized sensors; regulator involvement (especially in medicine).
- Provenance certification and cryptographic attestation for autonomy claims
- Sectors: policy, platforms, marketplaces
- What: Combine evaluator-based source detection with cryptographic logs/signed telemetry to certify autonomy levels in demos and deployments.
- Tools/workflows: Attestation protocols; chain-of-custody for data; authenticity “seal” on videos and reports.
- Assumptions/dependencies: Ecosystem cooperation; secure hardware/firmware roots of trust; anti-tamper measures.
- Skill marketplaces with quality and authenticity badges
- Sectors: software platforms, robotics app stores
- What: Curate third-party manipulation “skills” with badges for execution quality and verified autonomy, improving user trust and discoverability.
- Tools/workflows: Submission pipeline with AutoEval checks; periodic revalidation; user-facing scorecards.
- Assumptions/dependencies: Governance and dispute resolution; evaluator fairness across embodiments; scalability.
- Fleet-level health monitoring and privacy-preserving analytics
- Sectors: enterprise robotics, platforms
- What: Aggregate evaluator metrics across fleets to detect systemic degradations (e.g., after firmware updates) without sharing raw video (via edge scoring or secure enclaves).
- Tools/workflows: Federated scoring; secure aggregation; drift detection alerts.
- Assumptions/dependencies: Edge deployment feasibility; privacy architectures; calibration across sites.
- Autonomous dataset generation and lifelong learning loops
- Sectors: robotics R&D, data ops
- What: Use the evaluator to autonomously label, filter, and prioritize data collection, focusing on low-quality or unsafe behaviors to target improvement.
- Tools/workflows: Active data selection; auto-curation with confidence thresholds; periodic human-in-the-loop audits.
- Assumptions/dependencies: Robust evaluator uncertainty estimates; safeguards against feedback loops that entrench biases.
- Education and workforce development
- Sectors: education, professional training
- What: Courseware and labs using fine-grained scoring and CoT rationales to teach safe, efficient manipulation and robust evaluation practices.
- Tools/workflows: Curricula, assignments with Eval-Actions; capstone competitions scoring beyond success rate.
- Assumptions/dependencies: Institutional adoption; accessible hardware/sim setups; open licensing for teaching materials.
Notes on feasibility, assumptions, and dependencies drawn from the paper’s evidence
- Modalities: Best performance assumes access to synchronized video and kinematics; quality and authenticity accuracy may degrade with video-only inputs or unusual camera views.
- Domain shift: Reported generalization to different arms (e.g., Franka) shows a measurable drop (e.g., SRCC ~0.71 vs. ~0.81–0.84), indicating the need for light re-fine-tuning or domain adaptation per platform/task family.
- Real-time suitability: Paper emphasizes batch evaluation; on-robot, low-latency use likely needs model compression/distillation and tighter engineering.
- Robustness to gaming: Authenticity detection is strong in-benchmark; adversarial mimicry and spoofing remain open risks—regular re-benchmarking and adversarial testing recommended.
- Metric calibration: Efficiency normalization relies on fair distance/time baselines; thresholds for “safe/smooth” should be set per risk tolerance and application.
- Compute and privacy: Inference typically requires GPU; policy logs may include sensitive video—privacy-preserving pipelines and retention policies are necessary.
- Governance: For certification/insurance use, multi-party agreement on protocols, sensors, environments, and disclosures is required to prevent Goodhart’s law effects.
Collections
Sign up for free to add this paper to one or more collections.