- The paper presents vllm-mlx, a framework that achieves efficient native LLM and MLLM inference on Apple Silicon by leveraging unified memory and MLX optimizations.
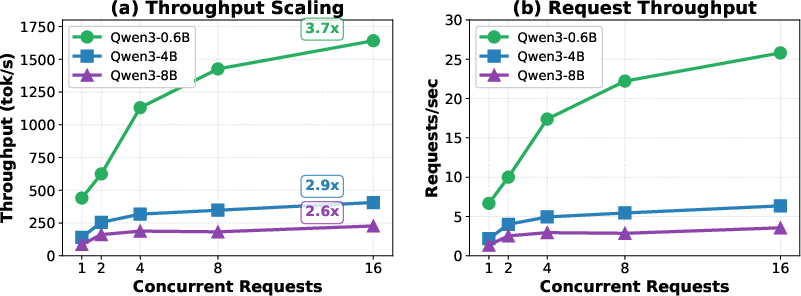
- It reports significant throughput and latency improvements, with up to 87% higher token rates and a 28x reduction in multimodal latency for repeated image queries.
- The study introduces novel content-based prefix caching and continuous batching that enable real-time, privacy-preserving AI deployment on edge devices.
Efficient Native LLM and MLLM Inference on Apple Silicon: Framework, Design, and Implications
Introduction
The paper "Native LLM and MLLM Inference at Scale on Apple Silicon" (2601.19139) presents vllm-mlx, a framework that addresses the gap in scalable and efficient LLM and multimodal LLM (MLLM) inference on Apple Silicon architectures. While current solutions emphasize text-only LLMs or adapt GPU-centric inference paradigms to Metal, multimodal applications on Apple hardware have been constrained by repeated vision encoding and limited concurrency. By leveraging the unified memory architecture and MLX, vllm-mlx provides a performant, comprehensive solution for both text and multimodal inference, introducing novel content-based prefix caching for vision embeddings.
Framework Capabilities and Differentiation
The framework introduces unique capabilities that surpass existing solutions by covering high-throughput text inference, continuous batching, OpenAI-compatible APIs, and multimodal support via vision caching. Unlike llama.cpp, which is limited to sequential text processing, and vLLM-metal, which lacks multimodal caching, vllm-mlx integrates continuous batching with content-based caching for vision tasks.
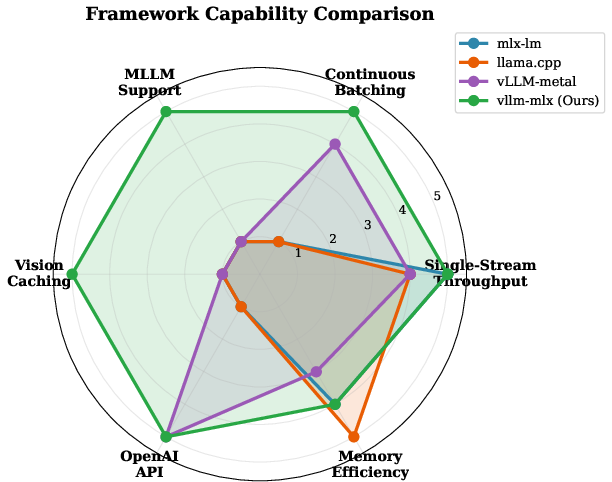
Figure 1: Framework capability comparison, highlighting vllm-mlx's unique comprehensive support for throughput, batching, API, and multimodal caching.
Key differentiators include native MLX support optimized for unified memory, efficient continuous batching for high concurrency throughput, and hashing-based caching mechanisms for both text prefixes and multimodal embeddings.
System Architecture and Inference Optimizations
Text Model Inference
For text models, vllm-mlx wraps mlx-lm and implements a continuous batching scheduler that dynamically admits and removes requests at token boundaries, maximizing GPU utilization. This is combined with token-wise streaming that handles multi-byte UTF-8 and tokenizer artifacts for robust output regardless of language. The system also features prefix-based KV cache reuse, yielding substantial speedups in prompt processing.
Multimodal Inference and Content-Based Caching
In multimodal workloads, content-based caching overcomes redundant encoding by hashing pixel-level representations of incoming images, regardless of format. Both vision embeddings and prompt-derived KV cache states are stored for reuse, with LRU eviction to bound memory growth. This enables instant response for repeated image or video inputs, accelerating interactive use cases.
The experimental results on Apple M4 Max with 128GB unified memory confirm major throughput, latency, and scalability gains.
Ablations reveal vision embedding caching contributes the majority of the speedup in multimodal latency, with higher image and video resolutions amplifying the cache's impact.
Practical and Theoretical Implications
Edge Deployment and Privacy
By exploiting Apple Silicon's unified memory, vllm-mlx enables high-throughput, low-latency inference for both text and multimodal models on consumer hardware. Continuous batching and content-based caching support the deployment of real-time, privacy-preserving AI agents and multi-agent architectures entirely on-device. The OpenAI-compatible API facilitates integration with frameworks such as LangChain, AutoGPT, and CrewAI, providing drop-in replacement functionality for cloud-based services.
Multimodal Caching Paradigm
The prefix caching methodology extends KV cache reuse from text to multimodal scenarios, solving long-standing latency bottlenecks due to repeated vision encoding. This paradigm could be further generalized to other modalities (audio, sensor) and hardware targets, inviting research into cross-modal cache management and neural embedding deduplication strategies.
Architecture Dependence and Future Work
Current deployment is limited to Apple Silicon platforms, and model support is bounded by MLX ecosystem progress. Potential future advances include speculative decoding, distributed inference over Mac clusters, energy/battery profiling, audio modality caching, and tensor-level parallelism across heterogeneous Apple GPU cores.
Related Work Context
vllm-mlx builds upon attention paging and KV cache reuse techniques (PagedAttention in vLLM, LMCache for multimodal caching), integrating these natively into MLX for zero-copy caching. It distinguishes itself from systems such as llama.cpp, MLC-LLM, and vLLM-metal by directly supporting multimodal inference and efficient resource utilization specific to unified memory architectures.
Conclusion
This study demonstrates that native, concurrent, and multimodal LLM inference can be achieved at scale on Apple Silicon through content-based caching and unified memory optimization. The vllm-mlx framework allows high-throughput, low-latency inference for a diverse set of models, enabling new edge AI applications and agent systems with privacy-centered design. The open-source release is positioned to catalyze further research and deployment of efficient multimodal AI solutions on consumer platforms.