- The paper proposes a novel Fourier-based surrogate modeling approach that stabilizes quantization-aware training at ultra-low bitwidths.
- It introduces the Rotated Damped Fourier Surrogate (RDFS) that reduces gradient variance and computational overhead compared to traditional STE and soft quantizers.
- Experimental results on LLMs and Vision Transformers demonstrate that StableQAT significantly enhances training stability and model performance at 2-4 bit precisions.
Introduction
The paper "StableQAT: Stable Quantization-Aware Training at Ultra-Low Bitwidths" (2601.19320) introduces StableQAT, a novel framework for quantization-aware training (QAT) in ultra-low-bit settings. The framework addresses significant challenges associated with optimization stability and performance degradation that typically arise at 2-4 bit precision levels. Common approaches such as straight-through estimators (STE) and soft quantizers often struggle with gradient mismatch and high computational overhead. StableQAT proposes a theoretically grounded surrogate modeling technique derived from discrete Fourier analysis, which stabilizes backpropagation at these bitwidths and improves overall training performance.
Forward-Backward Mismatch in QAT
A key challenge in QAT arises from the non-differentiability of the rounding operator, which is essential for discretizing continuous values during quantization. Traditional methods rely on the STE, which approximates the derivative of the non-differentiable rounding operation using an identity function, leading to significant approximation error and optimization instability. Soft surrogate quantization methods attempt to smoothen the quantization effect using approximations such as tanh and sigmoid functions. These methods aim to balance fidelity to discrete inference while maintaining optimization stability but often incur additional computational overhead.
StableQAT Framework
StableQAT introduces Rotated Damped Fourier Surrogate (RDFS) to address the optimization bottlenecks in QAT. By modeling the rounding operator through Fourier analysis and geometric rotation, StableQAT provides a smooth, bounded optimization direction that is both computationally efficient and robust. The framework generalizes STE, providing a more expressive surrogate family that reduces variance and enhances QAT performance without incurring additional computational costs.
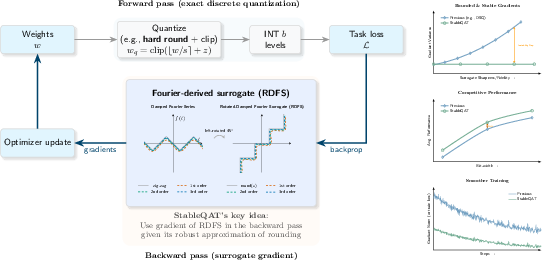
Figure 1: StableQAT procedure.
Theoretical Analysis
The paper presents a comprehensive theoretical analysis comparing StableQAT with existing methods like STE and DSQ. It demonstrates that StableQAT provides lower L2 approximation error and maintains bounded gradient variance, offering significant advantages over prior approaches. StableQAT's approach ensures more consistent gradient signals, which translates to improved training stability and convergence behavior.
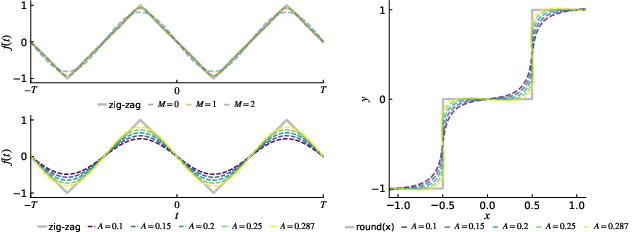
Figure 2: Rotated Damped Fourier Surrogate (RDFS) under different orders and amplitudes.
Experimental Results
Extensive experiments are conducted on LLMs and Vision Transformers (ViTs) to validate the efficacy of StableQAT. The framework consistently improves training stability and model performance at 2-4 bit precision without additional computational overhead. In particular, StableQAT outperforms traditional baselines and other recent QAT methods, highlighting its robustness and scalability in ultra-low-bit regimes.
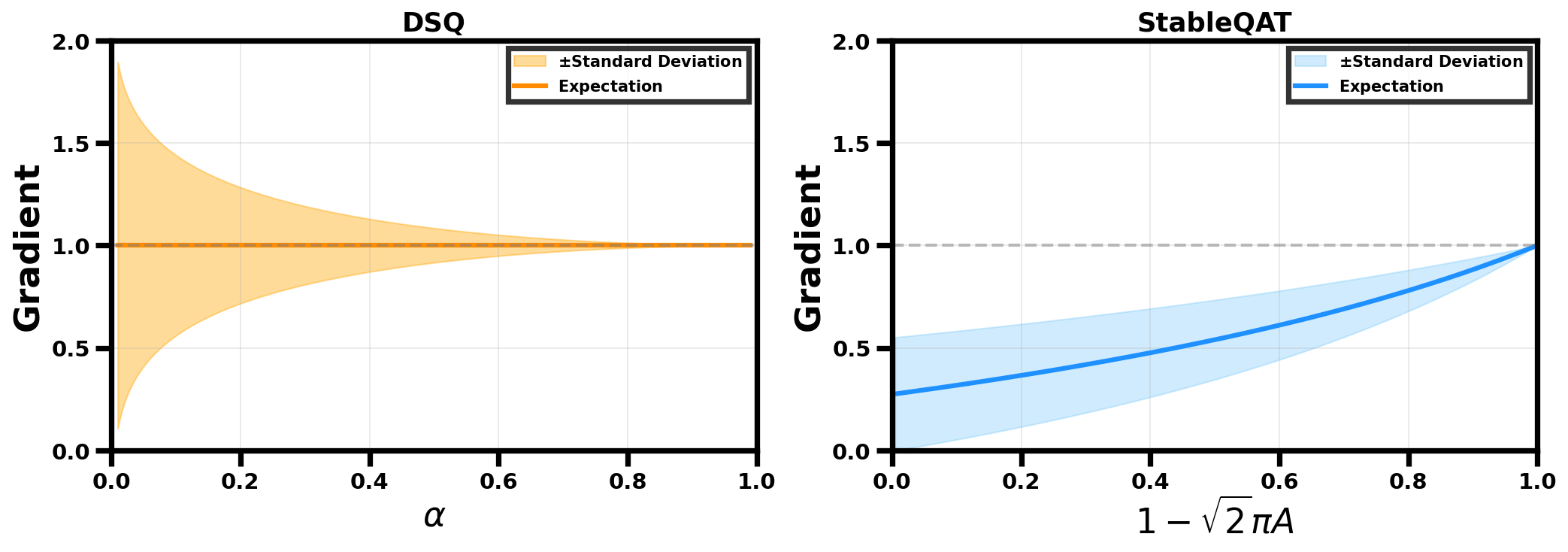
Figure 3: Gradient spread of DSQ and StableQAT. As the surrogate sharpens toward rounding operator, DSQ exhibits exploding variance, while StableQAT shows bounded variance.
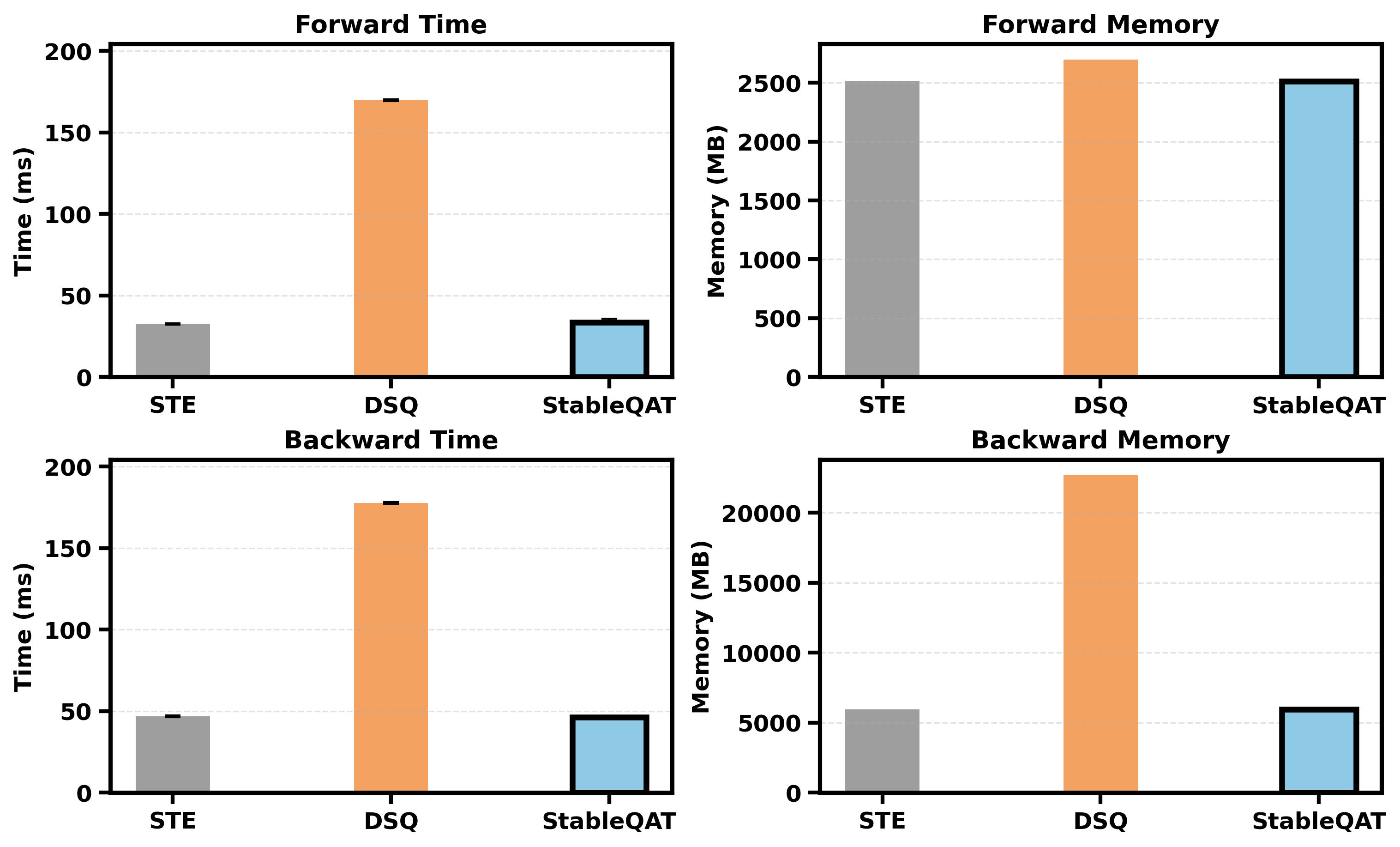
Figure 4: Time and space cost comparison (lower is better). They are measured on an input tensor with batch size 4 and sequence length 128. Each method is repeated 20 times.
Conclusion
StableQAT emerges as a promising solution to the challenges faced by QAT in ultra-low-bit regimes. By leveraging a novel Fourier surrogate, it effectively bridges the gap between discrete quantization and continuous optimization, providing both theoretical and practical advancements. Future research in ultra-low-bit QAT could benefit from exploring dynamic amplitude tuning and curriculum-based designs to further enhance stability and performance.