- The paper proposes a masked diffusion framework that redefines semantic ID generation through parallel codebook construction and adaptive noise scheduling.
- It introduces a two-stage inference strategy with a warm-up phase and parallel denoising, significantly reducing inference complexity and improving ranking metrics.
- Empirical results demonstrate up to 10.78% NDCG improvement and notable revenue gains, underscoring its practical impact on scalable, AI-driven recommender systems.
Masked Diffusion Generative Recommendation: A Technical Summary
Background and Motivation
Generative recommendation (GR) paradigms have recently shifted towards leveraging semantic ID (SID) quantization, mapping item content into discrete token representations optimized for both scalability and retrieval efficiency. Traditional autoregressive GR models, directly inherited from language modeling architectures, employ hierarchical codebooks and sequential token decoding, resulting in several key limitations: suboptimal modeling of global dependencies among item attributes, inability to adapt the generation path to heterogeneous user preference structures, and significant inefficiencies during inference. Single-step parallel decoding mitigates some global consistency issues, but lacks mechanisms for progressive semantic refinement and order-agnostic generation.
Masked Diffusion GR: Framework Overview
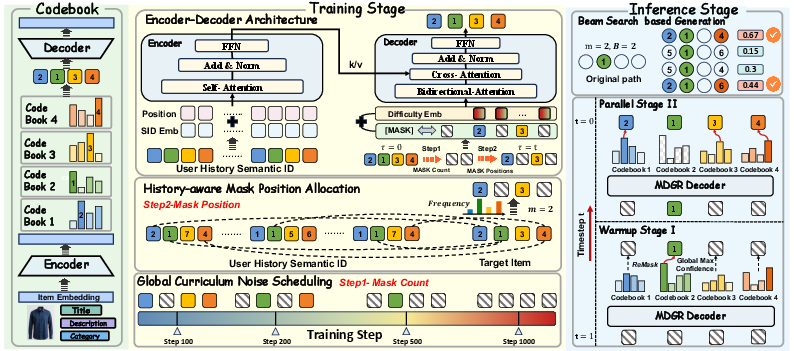
MDGR proposes a fundamentally different approach, framing SID generation as a masked diffusion process over parallel codebooks. This enables bidirectional modeling, flexible order-free generation, and multi-step semantic refinement. The system is decomposed into three principal components:
Codebook and Generation Paradigms
Parallel SID codebooks, central to MDGR, ensure each token reflects independent semantic content rather than residual hierarchies. This architecture supports arbitrary token filling orders and simultaneous denoising, essential for capturing bidirectional dependencies among attributes.
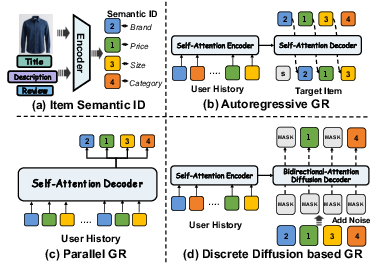
Figure 2: Item multimodal features are quantized into SIDs; masked diffusion GR (d) flexibly fills multiple positions in parallel, unlike autoregressive (b) or single-step (c) decoders.
Masked Diffusion Training Process
MDGR models SID generation as a discrete-time Markov chain, incrementally corrupting SID tokens via adaptive masking rates and learning a conditional denoising distribution. Global curriculum noise scheduling modulates instance difficulty over training steps, while history-aware masking allocates corruption preferentially to semantically infrequent dimensions for the user. Difficulty-aware embeddings are introduced to stabilize optimization with a direct signal about corruption intensity.
This regime ensures the model progressively learns to reconstruct increasingly complex partial SIDs, improving generalization and robustness. The masked diffusion objective is a cross-entropy over uncensored tokens, indexed by both temporal noise schedules and sample-wise semantic difficulty.
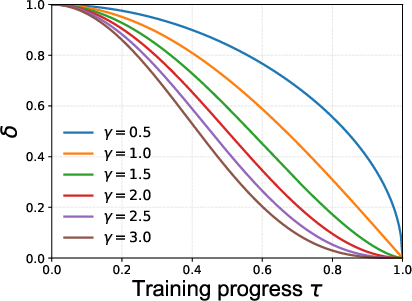
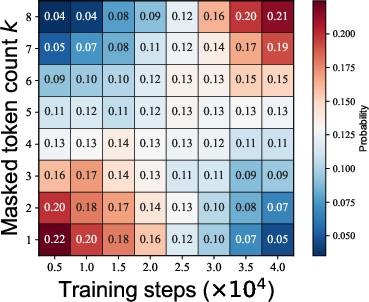
Figure 3: (a) Influence of γ on global curriculum difficulty; larger γ results in delayed noise ramp-up. (b) Empirical dynamics of mask count distributions as training advances for γ=2.
Efficient Inference: Warm-Up and Parallel Decoding
Efficient inference in MDGR starts from a fully masked SID and proceeds in two stages. The warm-up phase generates one token per step, always updating the most confident position as determined by the model. Once key dimensions (“anchors”) are filled, subsequent steps jointly fill mpar tokens in parallel, each selected with respect to top confidence scores. Parallel beam search extends candidate paths combinatorially, but maintains manageable computational cost due to reduced step count and bidirectional attention.
MDGR empirically reduces inference complexity to approximately LR of autoregressive GR, with R as the total diffusion steps and L as SID length, while maintaining or improving ranking metrics.
Ablation, Efficiency Trade-off, and Hyperparameter Analysis
Extensive ablation studies highlight the criticality of parallel codebooks and adaptive noise schedules, with fully random masking regimes (standard MDM) showing up to 3.4%–3.2% degradation across metrics. Removal of confidence-guided position selection, history-aware mask allocation, or difficulty embeddings each incurs consistent drops.
During inference, increasing the parallel positions decoded per step (mpar) accelerates query rate (QPS), but overly aggressive parallelization can degrade top-K recall due to compromised search space coverage under fixed beam widths. The most effective regime uses Rwarm=4 warm-up steps and mpar=2 for the industrial dataset.
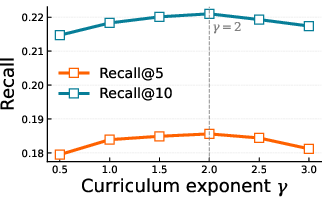
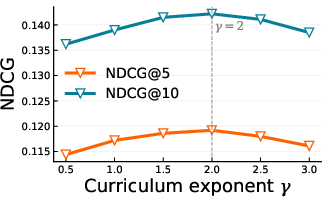
Figure 4: (a) Recall and (b) NDCG as a function of curriculum exponent γ; moderate γ yields optimal ranking performance.
MDGR substantially surpasses ten state-of-the-art baselines (both discriminative and generative), delivering up to 10.78% improvement in top-K NDCG and recall on real-world industrial datasets. Online A/B tests in a major e-commerce advertising platform report 1.20% revenue uplift, 3.69% increase in gross merchandise volume (GMV), and 2.36% improved click-through-rate (CTR).
Practical and Theoretical Implications
MDGR provides an effective paradigm for scalable, context-sensitive, and high-efficiency recommendation generation. By removing hierarchical generation constraints, adapting corruption to user preference heterogeneity, and exploiting parallel refinement with bidirectional attention, the architecture sets a new technical direction for SIDs in recommendation retrieval. The findings suggest that masked diffusion models, with task-specific noise schedules and codebook designs, generalize more robustly and efficiently than autoregressive alternatives for multi-attribute item generation.
From a theoretical perspective, this work strengthens the link between discrete diffusion models and efficient, globally consistent conditional generation in structured domains. Future avenues include refined noise scheduling, adaptive codebook expansion, and cross-modal alignment strategies to further enhance semantic expressivity and retrieval quality.
Conclusion
Masked Diffusion Generative Recommendation (MDGR) marks a significant advance in the generative recommendation landscape by introducing a fully parallel, curriculum- and history-adaptive masked diffusion approach for SID generation. Comprehensive evaluations demonstrate strong improvements in both recommendation accuracy and operational efficiency, supported by robust ablation analyses and large-scale online deployment. The masked diffusion approach described provides a promising foundation for next-generation generative retrieval strategies in AI-driven recommender systems (2601.19501).