- The paper presents an action-context-aware router that jointly optimizes cache reuse, token pruning, and layer skipping, achieving up to 1.79× inference speedup.
- It integrates visual, language, and action inputs to dynamically allocate computation, reducing effective FLOPs to 29.4% of a dense baseline while maintaining task success rates.
- The study demonstrates that aligning computation with manipulation context enhances robustness and enables real-time control in dynamic robotic environments.
Action-Context-Aware Adaptive Computation for Efficient VLA Robotic Manipulation
Motivation and Background
Vision-Language-Action (VLA) models have gained traction as generalist policies for robotic manipulation, integrating visual perception, language grounding, and action prediction within large-scale multimodal backbones. While state-of-the-art VLA architectures--e.g., RT-2, OpenVLA, and CogACT--achieve robust performance on complex tasks, their closed-loop deployment is constrained by significant computational burdens. Typically, the inference pipeline must process high-dimensional visual observations and language instructions at each timestep via deep vision-language encoders, resulting in undesirable latency and reduced control frequencies in dynamic environments.
Existing works addressing VLA efficiency undertake static model compression (pruning, quantization), dynamic routing (token pruning, layer skipping), or temporal reuse (caching cognition vectors). However, these approaches primarily draw cues from visual complexity and static heuristics, overlooking the decisive influence of action context on computation demand. This divergence results in strategies that may prune resource use aggressively during visually complex but manipulation-irrelevant phases and under-provision reasoning capacity during visually trivial yet interaction-critical stages.
AC²-VLA: Methodology
AC²-VLA introduces an action-context-aware, unified adaptive computation paradigm for VLA models. The principal contribution is an action-prior router, which predicts and coordinates cache reuse, token selection, and layer execution gates jointly according to the history of actions, the visual scene, and the current language instruction. Unlike existing methods that independently apply efficiency mechanisms, AC²-VLA leverages the robot's ongoing manipulation context for inference-time routing across the temporal (cognition reuse), spatial (token pruning), and depth (layer skipping) axes.
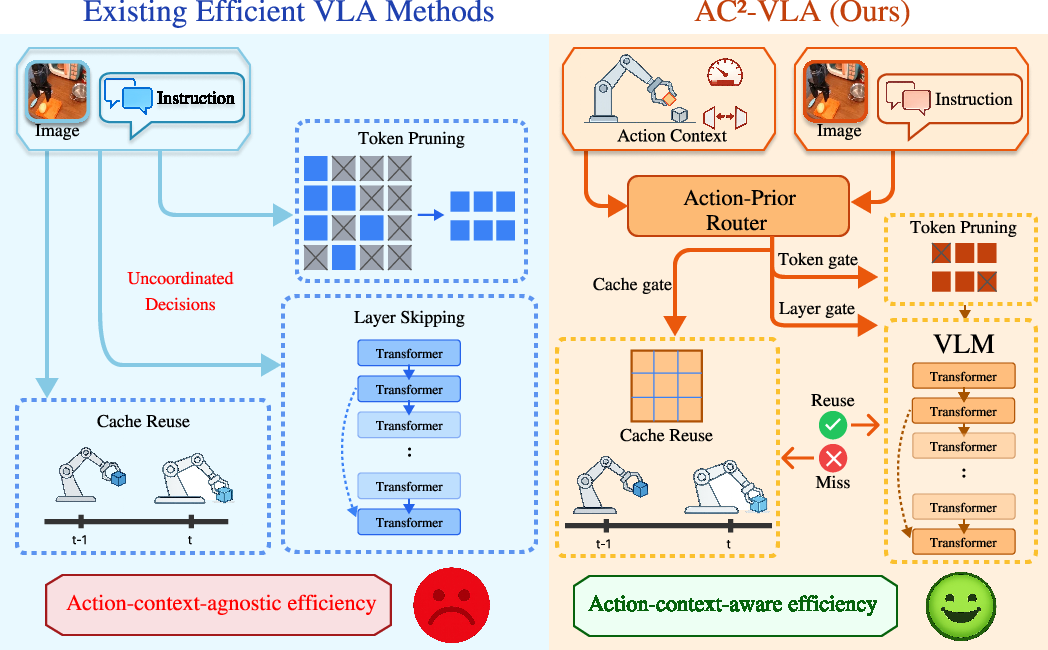
Figure 1: AC²-VLA's unified, action-context-aware computation gates outperform conventional approaches by integrating cache reuse, token pruning, and layer skipping through joint action-aware mechanisms.
The router constructs a context vector by fusing representations of the previous action, pooled vision features, instruction embeddings, and control step index. Each component is projected through component-specific encoders, aggregated via an MLP, and used as input to three gating heads: a scalar for cache reuse; token keep scores for vision patches; and binary gates for transformer block execution. Training utilizes an action-guided self-distillation regime, distilling both action outputs and backbone features from the dense teacher to the sparse student, augmented by regularization for gating budget and temporal consistency.
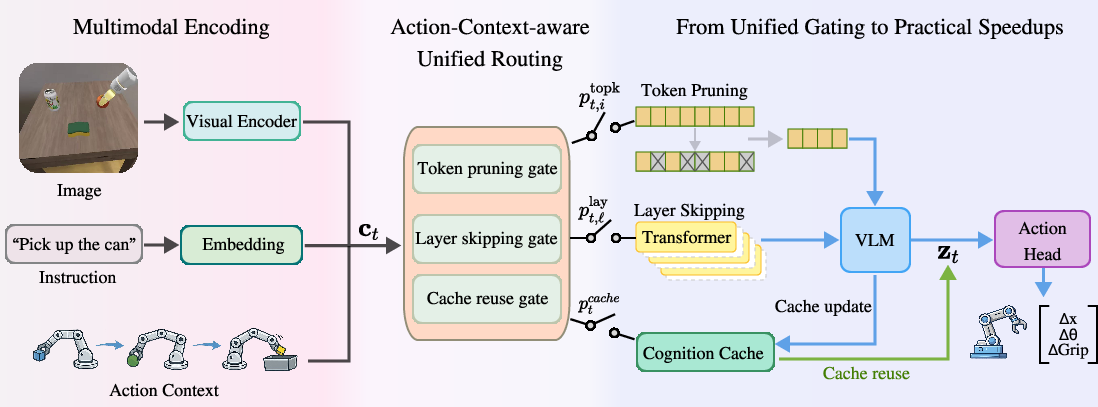
Figure 2: Diagram of AC²-VLA's architecture, illustrating action-context-driven construction of routing gates guiding token pruning, layer skipping, and reuse decisions at each timestep.
Practical Implementation and Inference Mechanisms
At each timestep, AC²-VLA attempts to maximize computational reuse and optimize inference speed via the following mechanisms:
These mechanisms are exercised jointly, delivering both pronounced inference speedups and consistent performance. Soft gating during training stabilizes optimization, with binarization enforced only during deployment.
Experimental Results and Comparative Evaluation
Comprehensive evaluation is performed on the SIMPLER manipulation benchmark, encompassing diverse protocols for Google Robot and WidowX platforms. AC²-VLA is implemented atop CogACT with a frozen Prismatic-7B backbone, exposing the isolated effect of the routing policy. Results are presented vis-à-vis generalist models (RT-1, RT-2-X, Octo, OpenVLA, CogACT) and efficiency-oriented baselines (VLA-Cache, EfficientVLA, FastV, MoLe-VLA).
Key findings include:
- Efficiency: AC²-VLA achieves up to 1.79× inference speedup and reduces effective FLOPs to 29.4% of the dense baseline (CogACT) on Google Robot Visual Matching.
- Performance: Task success rates are maintained or improved relative to dense policies: 76.8% for AC²-VLA versus 74.8% for CogACT, with notable performance on precision-critical tasks such as "Drawer Opening" (80.6% vs. 71.8%).
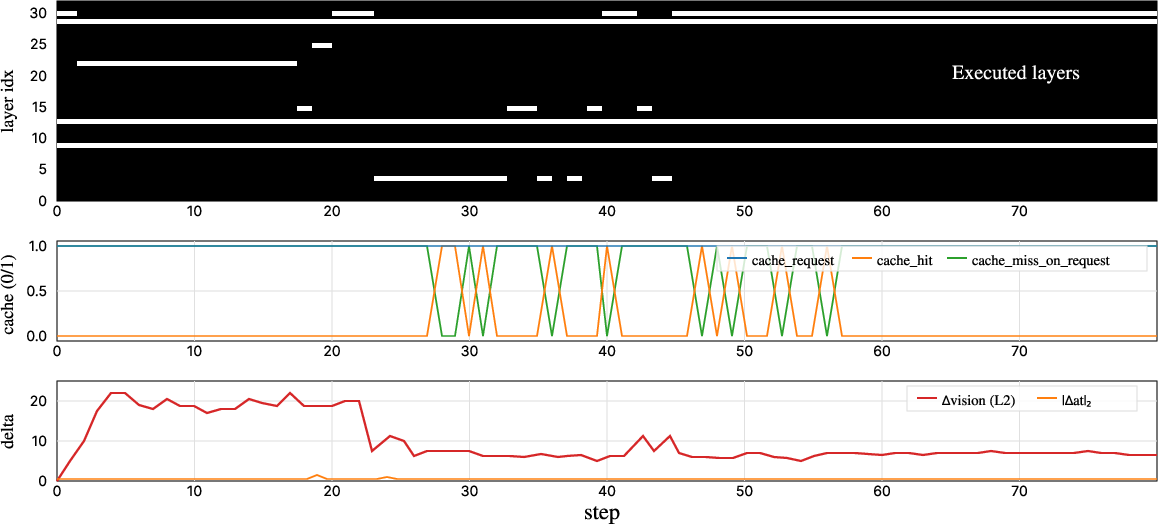
- Consistency: Action-context-aware routing delivers temporally stable decisions, suppressing distractors and mitigating high-frequency jitter in action outputs.
- Comparative Strength: In ablation, cache reuse and token pruning contribute compellingly to both acceleration and robustness, with all three computation axes required for optimal trade-off.


Figure 4: Token-level importance overlays, output by the action-conditioned router and visualized atop input observations, demonstrate context-adaptive spatial focusing that suppresses irrelevant regions and prioritizes manipulation-critical patches.
Efficiency-accuracy tradeoffs are illustrated by a Pareto frontier over token keep ratios and layer counts. Aggressive token sparsification (rtopk<0.4) precipitates sharp accuracy declines, while minimal pruning (rtopk≥0.6) inflates FLOPs without commensurate gains. Similar trends emerge for transformer depth. Cache reuse, controlled via gating threshold, yields concurrent gains in robustness and speed.
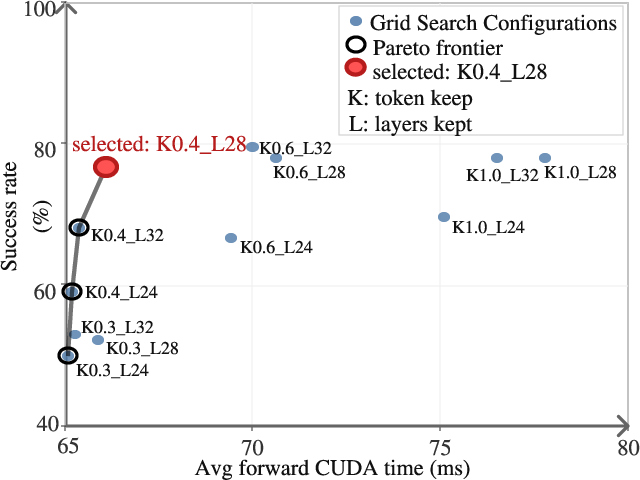
Figure 5: Pareto frontier reveals optimal trade-offs in token pruning and layer skipping, guiding practitioners on configuration choices for target efficiency/accuracy profiles.
Broader Implications and Future Directions
The results substantiate the thesis that computation redundancy in VLA models aligns more closely with action context than visual complexity. By centering adaptive computation on the agent's manipulation state, AC²-VLA demonstrates that action-guided sparsification not only accelerates inference but also regularizes decision making for enhanced stability and success rates.
Practically, the approach lowers the hardware barriers for deploying large VLA agents on real robots under demanding real-time constraints. Theoretically, it highlights a shift from visual- or heuristic-driven efficiency towards closed-loop control-aware adaptivity, suggesting that scalable generalist robot policies will benefit from inference paradigms that co-opt action history and control context as first-class citizens in computation allocation.
Future extensions may explore hierarchical routers conditioned on longer action histories, tighter integration with open-world generalization mechanisms (e.g., π0/π0.5 families), or meta-learned sparsity control for deployment over heterogeneous, resource-constrained robot platforms.
Conclusion
AC²-VLA sets forth a unified, action-context-aware routing framework for efficient VLA inference in robotic manipulation. By adaptively gating cache reuse, token pruning, and layer skipping based on manipulation state, the method achieves superior speed-accuracy trade-offs and improves action consistency. This paradigm underscores the criticality of aligning computation allocation to embodied action context in scalable robot intelligence and posits adaptive inference as a cornerstone for future VLA architectures.