Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Abstract: Despite the significant advancements represented by Vision-LLMs (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from vision-as-input'' tovision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Youtu-VL, a new kind of AI model that can understand both pictures and text. The big idea is simple: instead of treating images as something the model only “looks at” while mainly predicting words, Youtu-VL also asks the model to predict image details directly. This helps the model keep fine-grained visual information (like small objects, exact shapes, and precise positions) so it can do more detailed vision tasks—not just write captions.
What questions does the paper try to answer?
The paper focuses on two main questions:
- How can we stop vision-LLMs from losing tiny visual details when they mostly learn to predict words?
- Can one standard model (without extra special parts) handle many visual tasks—like detection, segmentation, depth estimation, and reading coordinates—alongside general multimodal tasks (like captioning and Q&A)?
How did they do it?
Think of the model’s job like building with LEGO:
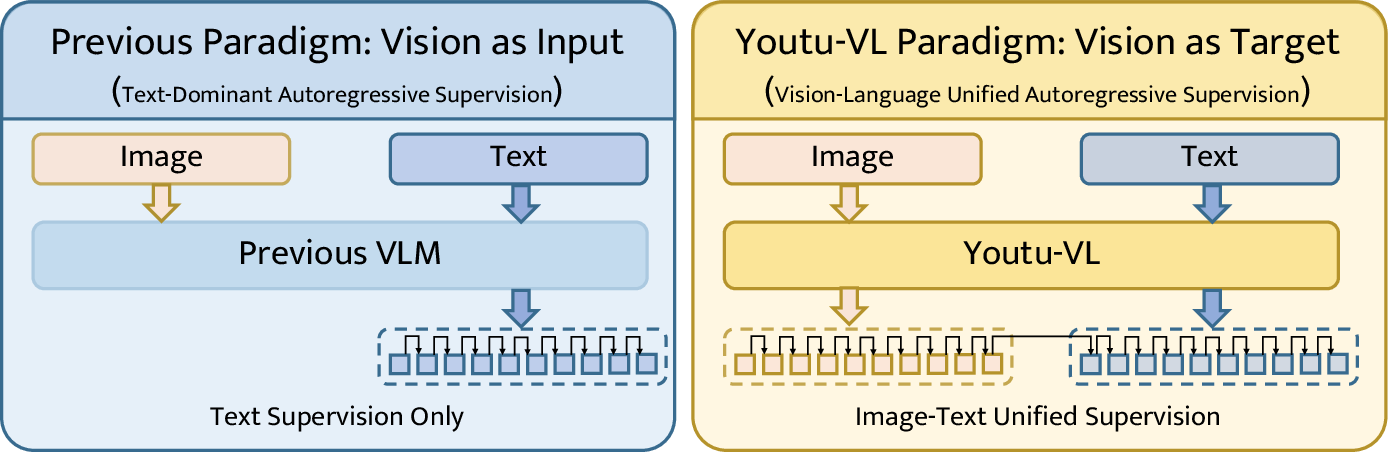
- Older models mostly tried to predict the next word in a sentence, using the image as a hint. That’s like looking at a picture and only describing it with rough words.
- Youtu-VL asks the model to predict both words and visual “LEGO pieces” that represent parts of the image. This keeps detailed visual pieces in the model’s “memory.”
Here’s the approach in everyday terms:
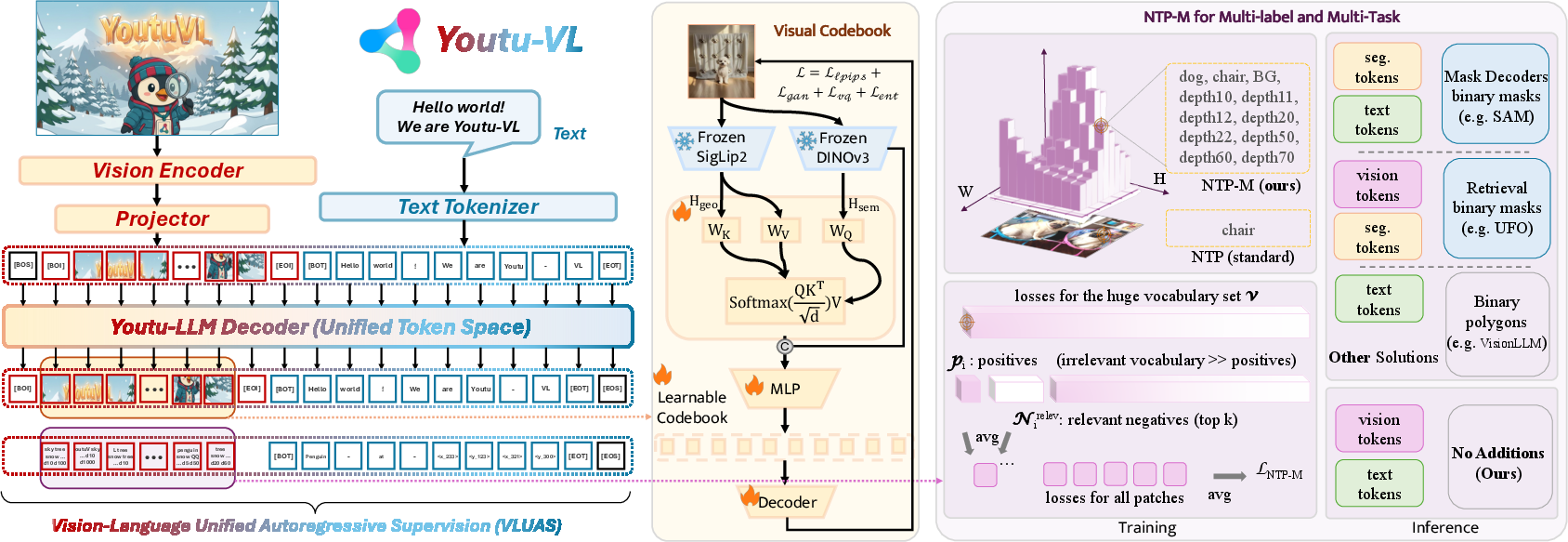
A unified “alphabet” for images and text
- The model uses a shared vocabulary (a big dictionary) that includes both word tokens and special visual tokens.
- A visual tokenizer (like a translator for pictures) turns an image into discrete codes—tiny chunks that represent both what’s in the picture (semantics) and its structure (geometry, shapes, boundaries). To do this well, it blends:
- Semantic features (what things mean) from a model aligned with language.
- Geometric features (where things are, their boundaries) from a model good at preserving structure.
- These codes come from a learnable “codebook” (like a huge dictionary of image pieces). The tokenizer is trained to reconstruct images from these codes so the codes actually represent the image well.
Predicting images and text in the same way
- The model learns to predict the next item in a sequence—sometimes it’s a word, sometimes it’s a visual token—using the same training style. This is called “autoregressive supervision.”
- For inputs, the model still uses continuous visual features (smooth, detailed signals) so it doesn’t lose information. For targets, it predicts discrete tokens (words or image codes). This setup keeps input quality high and makes training stable.
Doing vision tasks with the standard model
The model handles two kinds of vision tasks without special add-ons:
- Text-based prediction tasks:
- Object detection and visual grounding: the model outputs category names and exact coordinates using special coordinate tokens like <x_123>, <y_456>.
- Pose estimation: predicts keypoint coordinates (like elbow, knee).
- Polygon segmentation: outputs a sequence of points outlining an object.
- Counting: either directly outputs a number or “detects then counts.”
- Using absolute pixel coordinates avoids messy scaling issues and keeps results precise.
- Dense prediction tasks (pixel-level results):
- Semantic segmentation (coloring each pixel by class) and depth estimation (how far each pixel is).
- Instead of using extra decoders, the model uses its own output scores (logits) to build dense maps:
- It picks the best-matching category for each patch/pixel using its vocabulary and combines scores into a grid.
- It upsamples the grid to the original image size and can optionally refine it with a standard post-processing step (CRF).
- For depth, it predicts bins (ranges) of distance, supporting both linear and log-scale setups.
A smarter training loss for multiple labels
- One image patch can belong to several targets (e.g., part of a person and part of “foreground”). So the authors use a multi-label version of next-token prediction (called NTP-M).
- It treats each possible token like its own yes/no question and focuses training on the most confusing “negative” tokens (the ones the model mistakenly thinks are present), instead of averaging over millions of irrelevant negatives. This makes learning efficient and stable.
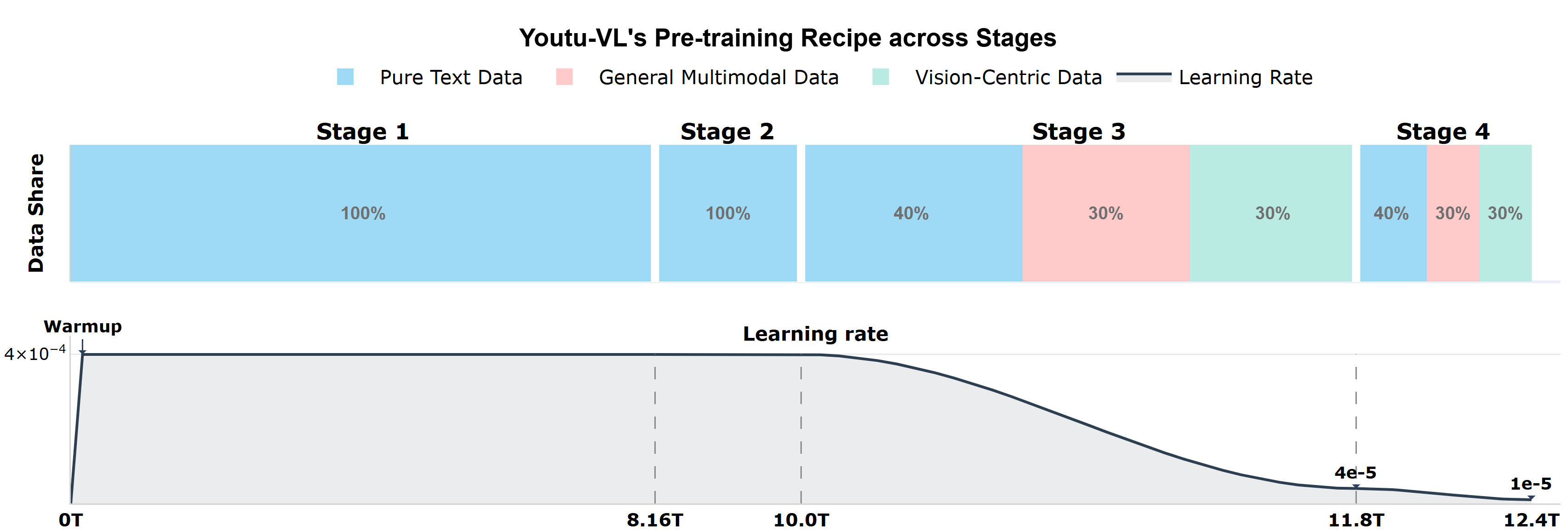
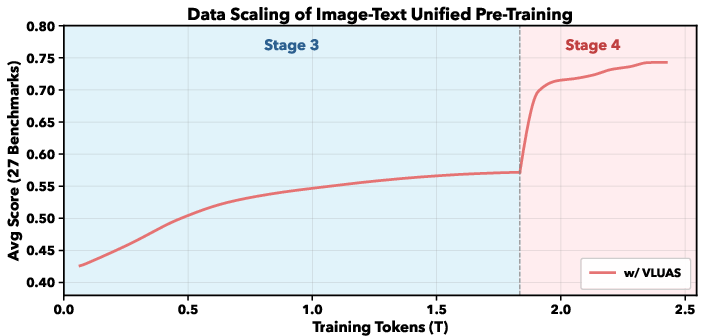
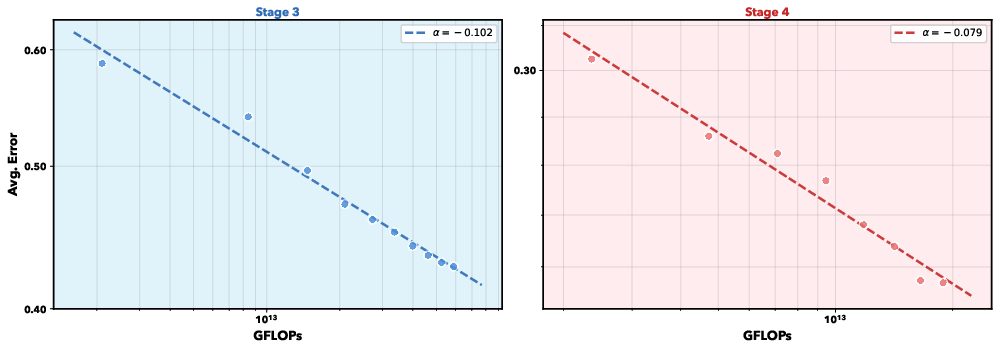
Training in four stages
To teach the model step by step:
- Stage 1–2: Pure text training (about 10 trillion tokens) to make the language part strong in reasoning, STEM, and coding.
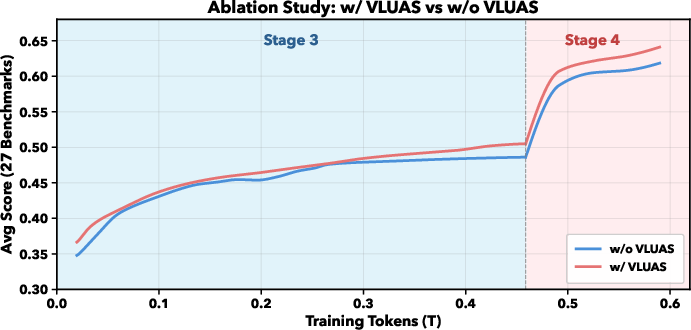
- Stage 3: Multimodal training (about 1.8 trillion tokens) mixes images and text, teaching the model to predict both word and visual tokens.
- Stage 4: Task-focused instruction tuning (about 0.6 trillion tokens) across many domains: VQA, OCR, STEM, GUI, detection, segmentation, grounding, and pose.
Carefully built datasets
They assembled and cleaned huge datasets:
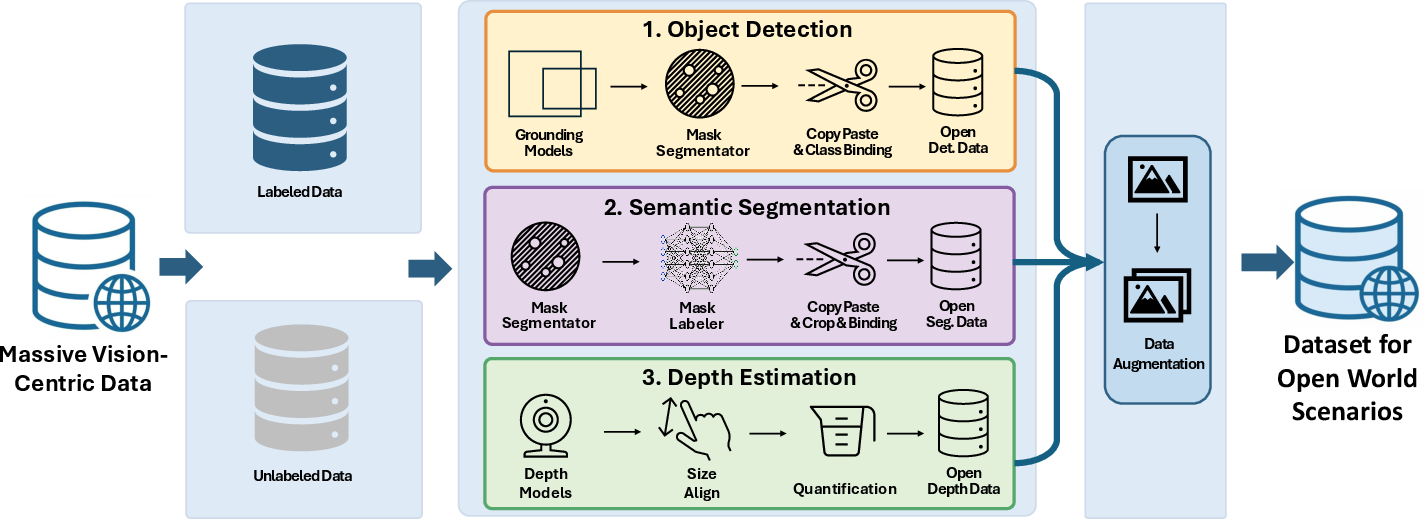
- Vision-centric data for detection, segmentation, and depth (with synthesis for open-world scenarios).
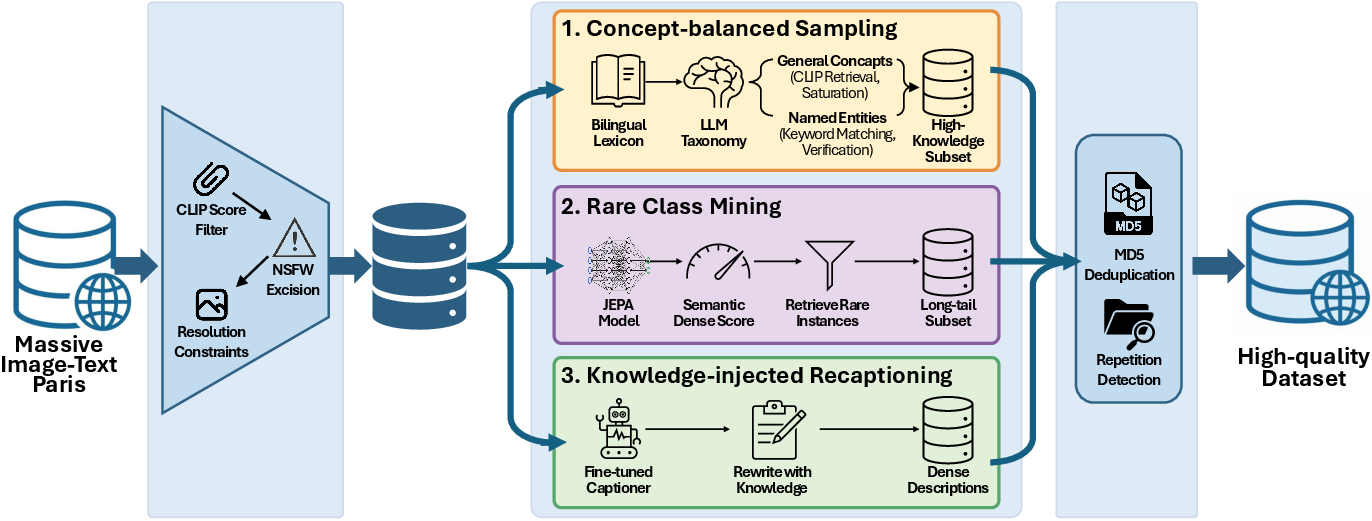
- Image-text pairs filtered and enhanced with knowledge-rich recaptions so descriptions are detailed and accurate.
- OCR data (including charts and documents) with synthetic samples that simulate real-world camera noise and layouts.
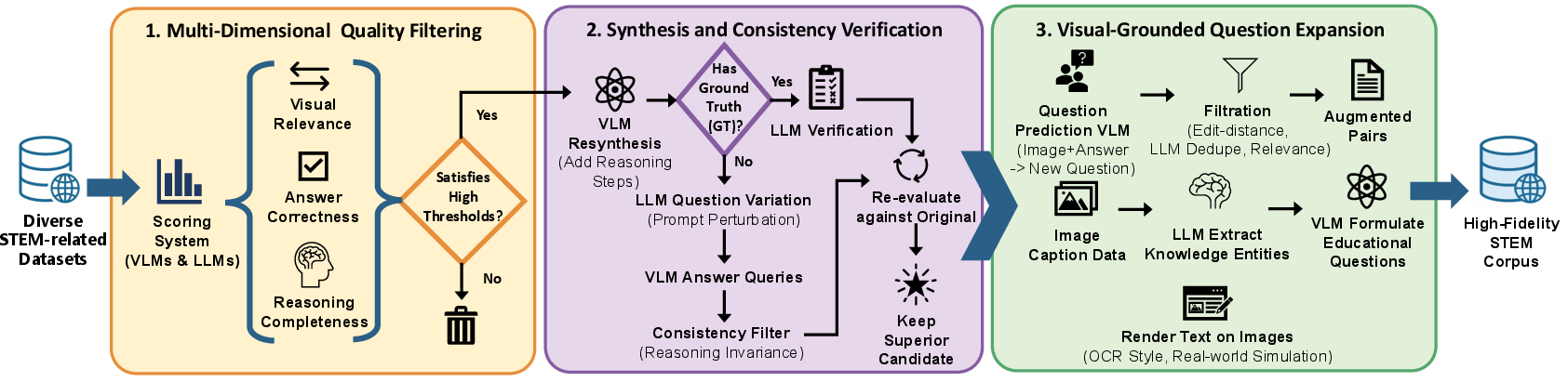
- STEM data with multi-step reasoning and consistency checks.
- GUI data for grounding UI elements and learning multi-step interactions.
What did they find?
The main results are:
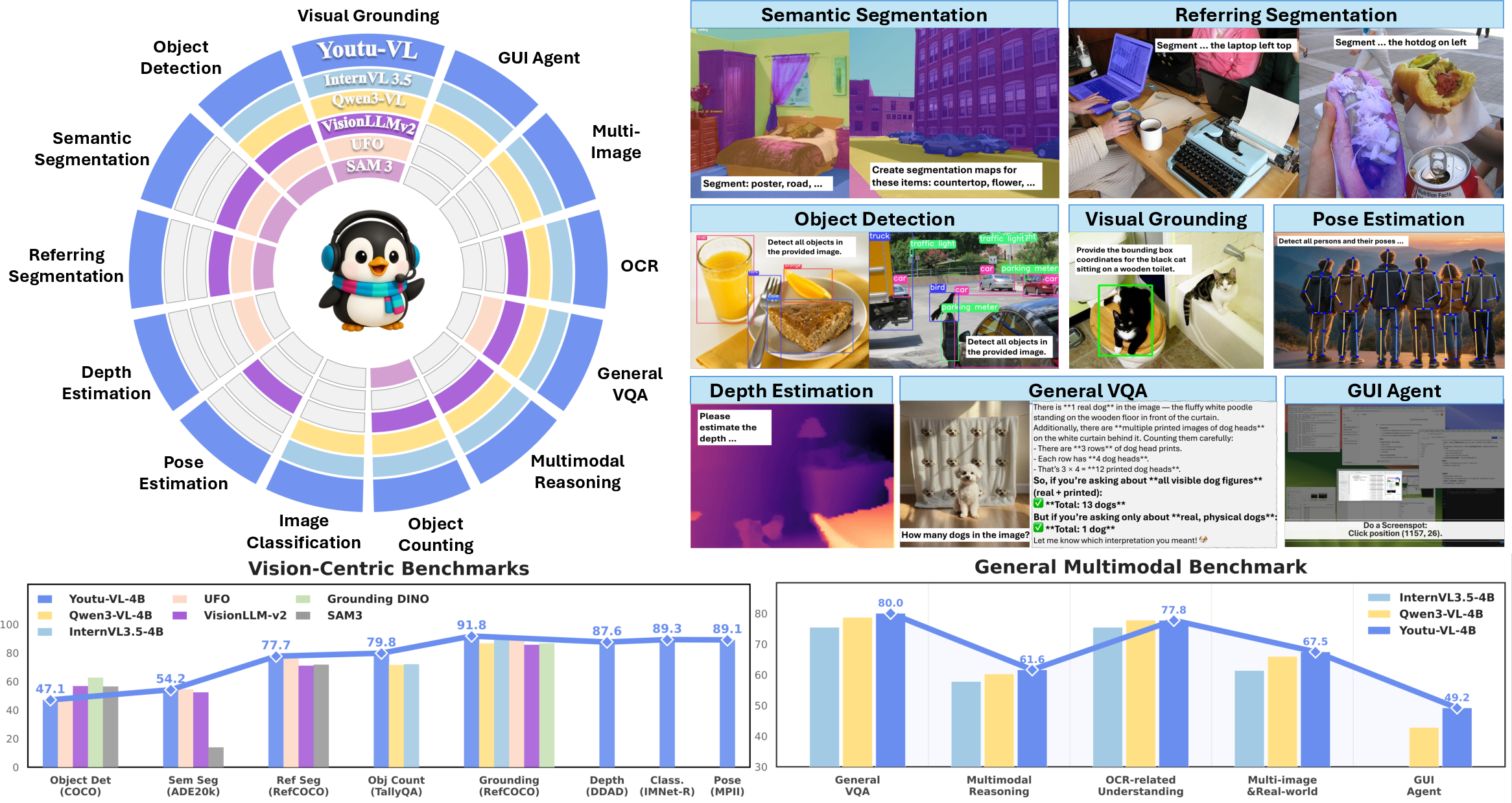
- Youtu-VL achieves competitive performance in both general multimodal tasks (like captioning and visual Q&A) and vision-centric tasks (like detection, segmentation, depth, grounding, and pose).
- It does these tasks using a standard architecture—no task-specific heads or extra modules.
- Treating images as prediction targets (not just inputs) helps the model keep fine-grained details that older models often lost.
- The unified approach allows smooth switching between high-level reasoning (like answering questions about an image) and low-level perception (like painting exact object masks), all within one model.
Why is this important?
In simple terms:
- It makes AI “see” better: by predicting visual tokens, the model remembers small details.
- It simplifies AI design: one model can handle many vision tasks without bolt-on parts, making training and deployment easier.
- It builds stronger generalist “visual agents”: assistants that can read, analyze, and act on visual information—from photos and diagrams to screens and documents—more reliably.
What could this lead to?
If widely adopted, this paradigm could:
- Improve apps that need precise visual understanding (medical imaging, robotics, AR, autonomous tools).
- Enable smarter assistants that can read charts, follow visual instructions, and operate software interfaces.
- Reduce the need for many specialized models, making AI systems more unified, maintainable, and scalable.
In short, Youtu-VL shows a practical way to teach AI to treat vision and language as equal citizens, leading to richer, more accurate understanding of the world.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a single, consolidated list of specific gaps and open questions that the paper does not fully resolve and that future work could address.
- Quantitative evidence is missing: no benchmark tables, task-wise metrics, or statistical significance tests are reported to substantiate the “competitive” claims across general multimodal and vision-centric tasks.
- Lack of ablations: the paper does not isolate contributions of VLUAS vs. baseline training, NTP-M vs. standard losses, the synergistic tokenizer vs. single-encoder tokenizers, axis-specific coordinate vocabulary vs. conventional encodings, or the impact of removing L1 loss in tokenizer training.
- Efficiency and scaling unclear: the computational cost of predicting over a unified vocabulary (≈150k visual tokens plus text tokens) in training and inference is not reported (throughput, memory footprint, latency), especially for dense prediction requiring per-patch/full-vocab logits.
- NTP-M hyperparameters unspecified: the top‑k “relevant negative” selection, its adaptivity across tasks/classes, and its computational overhead are not detailed; effects on convergence stability, calibration, and class imbalance are unquantified.
- Multi-label target construction is under-specified: how multi-hot labels are assigned per patch across tasks (e.g., segmentation, detection, depth) is unclear—especially when patches cover multiple objects/classes or ambiguous boundaries, and how label noise/incompleteness is handled beyond validity masks.
- Asymmetric input/target representation not analyzed: treating inputs as continuous embeddings and targets as discrete tokens may induce a distribution mismatch; the impact on optimization stability and cross-modal alignment is not evaluated.
- Tokenizer generalization and robustness not evaluated: the 150k-codebook synergistic tokenizer (SigLIP-2 + DINOv3, IBQ, LPIPS+GAN) is not tested across domains (e.g., medical, remote sensing) or under degradations (blur, noise), nor are failure modes (e.g., texture vs. structure bias) analyzed.
- Codebook design choices unexamined: sensitivity to codebook size, embedding dimension, and entropy regularization is not explored; risk of codebook overfitting or latent collapse beyond utilization rate is not studied.
- Sequence length and context budget trade-offs are not discussed: integrating visual tokens into the prediction stream may lengthen sequences; how this interacts with long-context reasoning and memory scaling is unreported.
- Dense prediction upsampling is rudimentary: bilinear interpolation plus optional Dense CRF may limit fine-structure accuracy; alternatives (learnable upsamplers, edge-aware refinement) and their trade-offs are not compared.
- Spatial resolution limits for small objects not assessed: the Spatial Merge (2×2) downsampling and window attention might impair detection/segmentation of tiny objects; mitigation strategies and empirical analysis are absent.
- Coordinate tokenization constraints: the axis-specific absolute pixel vocabulary is capped at 2048 bins; it is unclear how images larger than this are handled, how aspect ratios/resolution variability affect generalization, or whether dynamic or hierarchical coordinate tokens are needed.
- Polygon segmentation capped at 20 points: the fidelity/accuracy trade-off for complex shapes is not quantified, nor are strategies like adaptive point budgets or spline-based representations evaluated.
- Depth discretization uncertainties: the choice of bin counts, linear vs. logarithmic quantization, camera-parameter prompts, and dequantization calibration (scale ambiguities across cameras) are not systematically validated; generalization across camera models is untested.
- Open-world semantics via text tokens: segmentation/detection categories mapped to subword tokens raises ambiguity (synonyms, homonyms, multi-token classes); the paper does not define canonical labels, disambiguation, or handling of unseen/rare categories at inference.
- Logit aggregation for multi-token labels: averaging subword logits may be suboptimal; no comparison to dedicated class tokens, learned label embeddings, or constrained decoding is provided.
- Calibration of dense predictions is not addressed: how well per-pixel/patch logits are calibrated, how uncertainty is quantified, and how thresholds are chosen for binary/instance masks remain open.
- Task prompting and ambiguity: the mechanism for selecting tasks (text prompts only) and resolving ambiguous instructions without task-specific tokens is not stress-tested; potential task interference or prompt sensitivity is not analyzed.
- Catastrophic interference and loss balancing: lambda for text vs. image supervision is fixed (0.5) without sensitivity analysis; interactions/conflicts among many tasks (VQA, OCR, detection, segmentation, depth, pose) during joint training are unstudied.
- Comparison to task-specific decoders: while the approach removes auxiliary heads, there is no head-to-head evaluation of accuracy/efficiency vs. modern decoders for dense tasks, nor a study of when lightweight decoders might still be beneficial.
- Inference-time behavior of visual tokens: visual tokens are optimized as targets during training; the paper does not clarify whether and when they are generated at inference (beyond using logits for dense predictions) and how this affects usability, latency, and stability.
- Data provenance and reproducibility gaps: heavy reliance on internal/synthetic data and unspecified mixtures limits reproducibility; precise dataset compositions, licenses, and availability are not provided.
- Bias, safety, and fairness evaluations are missing: the impact of data curation on demographic/semantic biases and the safety profile of the model (e.g., OCR on sensitive documents) are unassessed.
- Multilingual coverage is unclear: despite bilingual concept sampling, cross-lingual performance on vision-language benchmarks and OCR with non-Latin scripts is not reported.
- Video and temporal extension left open: the framework focuses on images; how VLUAS, tokenizer design, and dense prediction would extend to video (temporal consistency, motion) is not addressed.
- Robustness under distribution shift: no evaluations on corrupted datasets, occlusions, extreme resolutions, or domain shifts are presented.
- Parameter/computation transparency lacking: model sizes, training compute, memory usage, and energy cost are not disclosed; practical deployment guidance (real-time feasibility on edge devices, batching strategies) is absent.
- Post-processing dependencies: reliance on Dense CRF, temperature scaling, and image zooming raises questions about robustness, reproducibility of results, and additional compute; their quantitative impact is not ablated.
- Failure analysis is absent: the paper provides no qualitative or quantitative error analysis for typical failure modes across tasks (e.g., small object misses, boundary leakage, depth scale errors), limiting actionable insights for improvement.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, directly leveraging Youtu‑VL’s “vision‑as‑target” paradigm, unified vocabulary, axis‑specific coordinate tokens, and decoder‑free dense prediction from logits. Each item notes sectors, potential tools/products/workflows, and feasibility considerations.
- Unified perception-as-a-service API for product teams Sector(s): software, robotics, media, retail Tools/Products/Workflows: one API that serves captioning, detection/grounding (XYXY absolute tokens), pose estimation, polygon segmentation, semantic segmentation, and depth—all from a single VLM; simplifies tech stacks vs. multiple task-specific models Assumptions/Dependencies: GPU/TPU inference; latency budgets; adherence to the model’s license; domain-specific fine-tuning for edge cases
- Retail inventory and shelf analytics (detect‑then‑count, open‑world) Sector(s): retail, logistics Tools/Products/Workflows: automated planogram compliance, stock-out detection, product counting using textual and axis-specific coordinate tokens; open‑world detection for new SKUs; receipt OCR for reconciliation Assumptions/Dependencies: consistent camera placement/quality; store-specific category taxonomies; privacy compliance for in-store video
- Document intelligence and OCR with reasoning (charts/tables/forms) Sector(s): finance, insurance, government, legal, logistics Tools/Products/Workflows: end-to-end parsing of invoices, forms, and statements; chart/question answering with short chain-of-thought; visual-grounded extraction for audit trails Assumptions/Dependencies: multi-language/script coverage; PII handling and data governance; evaluation on in-domain document styles
- GUI automation and test/RPA co-pilot Sector(s): software/QA, enterprise IT, customer support Tools/Products/Workflows: element grounding, dense captioning, and action sequencing for test automation; robust locators that survive UI changes (visual grounding instead of brittle XPath); long-horizon tutorial execution Assumptions/Dependencies: permissive terms for automating target applications; guardrails for destructive actions; scaling to diverse OS/browser renderings
- Manufacturing quality inspection and assembly assistance Sector(s): manufacturing, electronics, automotive Tools/Products/Workflows: defect detection and polygon segmentation; pose estimation for component placement; unified model reduces maintenance cost across lines Assumptions/Dependencies: domain adaptation with plant imagery; real-time constraints on edge GPUs; safety certification for in-line deployment
- Construction/AEC safety and progress monitoring Sector(s): construction, architecture/engineering Tools/Products/Workflows: PPE detection, worker counting, instance/semantic segmentation for site progress; depth estimation for rough volumetrics Assumptions/Dependencies: camera calibration (for depth), occlusion management; union/privacy policies; model validation for safety checks
- Energy and utilities asset inspection (drone or fixed cameras) Sector(s): energy (solar, wind, grid), transportation Tools/Products/Workflows: detection/segmentation of defects (e.g., hotspots, corrosion), vegetation encroachment; open-world categories via unified vocabulary; measurement with depth bins where applicable Assumptions/Dependencies: latency/throughput on edge; weather/lighting robustness; regulatory approvals for autonomous inspection
- Assistive vision on mobile (reading and finding objects) Sector(s): consumer, accessibility Tools/Products/Workflows: on-device or cloud‑assisted app to read signs/documents (OCR), locate objects (“find my keys”), and provide basic spatial cues (depth bins) Assumptions/Dependencies: privacy-by-design; on-device optimization/quantization; real-world clutter and low‑light handling
- STEM education and assessment tools Sector(s): education, edtech Tools/Products/Workflows: step-by-step solutions for diagram-based problems; teacher tooling to generate new questions from images; feedback with visual grounding Assumptions/Dependencies: academic integrity safeguards; alignment to curricula; bias/accuracy monitoring for high-stakes use
- Medical image pre-annotation and review assistance (non‑diagnostic) Sector(s): healthcare (radiology, pathology, surgical video) Tools/Products/Workflows: pre-annotating masks/regions (semantic/instance segmentation), object localization for triage; human-in-the-loop labeling acceleration Assumptions/Dependencies: strict domain fine-tuning; regulatory scope limited to assistive/pre-annotation; HIPAA/GDPR compliance; not for autonomous diagnosis
Long-Term Applications
These opportunities build on Youtu‑VL’s unified supervision (VLUAS), synergistic tokenizer, multi-label NTP‑M loss, and native-resolution processing, but require additional research, scaling, or domain adaptation before broad deployment.
- Generalist visual robotic agent (home/industrial) Sector(s): robotics, logistics, service robots Tools/Products/Workflows: a single perception-and-reasoning stack for grasping, manipulation, and navigation—using detection, segmentation, pose, depth, and language grounding in one model Assumptions/Dependencies: hard real-time performance, sim‑to‑real transfer, safety and fail-safe policies, integration with control stacks
- Unified perception for autonomous vehicles and drones Sector(s): automotive, aerospace Tools/Products/Workflows: replacing fragmented perception modules (detection/segmentation/depth) with a single VLM-based backbone to reduce system complexity Assumptions/Dependencies: video/temporal extensions, stringent robustness tests, redundancy requirements, regulatory validation
- Interactive medical assistant (surgical and radiology guidance) Sector(s): healthcare Tools/Products/Workflows: intraoperative scene understanding, instrument tracking, anatomy segmentation with language-guided prompts; radiology findings grounded to regions Assumptions/Dependencies: extensive clinical trials, FDA/CE approvals, calibrated depth/geometry, certified reliability
- Autonomous enterprise UI co-pilot for end-to-end workflows Sector(s): enterprise software, ops, finance Tools/Products/Workflows: agents that plan and execute multi-step tasks across heterogeneous GUIs, supported by visual grounding and state tracking Assumptions/Dependencies: robust long-horizon reasoning, rollback/recovery, enterprise IAM integration, auditability
- City-scale visual analytics for public policy Sector(s): government, urban planning, public safety Tools/Products/Workflows: open-world detection/segmentation for traffic flow, sidewalk accessibility, waste/cleanliness indices; depth-informed measurements Assumptions/Dependencies: privacy-preserving analytics, de-identification, public buy-in, infrastructure for large-scale video
- Scientific multimodal assistant for labs Sector(s): R&D, pharmaceuticals, materials Tools/Products/Workflows: interpret plots/gel images/microscopy, extract experimental setups from figures, generate hypotheses grounded in visuals and text Assumptions/Dependencies: domain‑specific pretraining; provenance tracking; integration with ELNs/LIMS
- Digital twins with unified visual grounding Sector(s): construction, manufacturing, smart cities Tools/Products/Workflows: align as‑built scenes to BIM/CAD using segmentation/depth; close the loop for progress, clash detection, and maintenance scheduling Assumptions/Dependencies: precise calibration and geo-referencing; 3D/temporal modeling; data interoperability standards
- Open-world compliance monitoring (industry and retail) Sector(s): compliance, EHS, retail ops Tools/Products/Workflows: dynamically track signage, labeling, safety zones, and procedural adherence without fixed taxonomies Assumptions/Dependencies: policy frameworks for surveillance ethics; continuous category updates; low false-positive/negative rates
- On-device AR assistants and wearables Sector(s): consumer electronics, industrial AR Tools/Products/Workflows: real-time overlays with object labels, masks, and depth cues for assembly or navigation Assumptions/Dependencies: aggressive model compression/distillation, battery/thermal constraints, low-latency rendering
- Automated dataset creation and active labeling platforms Sector(s): ML tooling, academia, industry labs Tools/Products/Workflows: use VLUAS visual tokens and decoder-free dense outputs to bootstrap masks, boxes, and captions; human-in-the-loop QA Assumptions/Dependencies: quality assurance loops, bias control, scalable annotation UIs, dataset licensing governance
Cross-cutting assumptions and dependencies
- Compute and latency: Real-time deployment may require pruning/quantization, distillation, or hardware acceleration.
- Domain shift: Many sectors will need fine-tuning on in-domain data and robust evaluation suites.
- Calibration and geometry: Depth and precise coordinates depend on camera calibration and scene setup.
- Safety and regulation: Healthcare, automotive, and public-sector uses require strong validations, monitoring, and compliance.
- Privacy and security: OCR/document and city-scale analytics must ensure PII protection and secure data handling.
- Licensing and IP: Confirm model/data licenses and third-party component terms for commercial deployment.
- Monitoring and guardrails: For agentic/automation uses, implement rollout controls, audit logs, and safe action sets.
Glossary
- 2D Rotary Position Embedding (RoPE): A positional encoding technique for transformers that applies rotary embeddings in two spatial dimensions to capture image layout. "This architecture incorporates 2D Rotary Position Embedding (RoPE) according to spatial shapes for positional encoding."
- Absolute pixel coordinates: Coordinates expressed directly in pixel units rather than normalized values, enabling precise localization without rescaling. "Absolute pixel coordinates: the model operates directly on absolute pixel coordinates rather than normalized relative coordinates."
- Adversarial discriminator loss: A GAN-based loss that encourages reconstructed outputs to look realistic by training against a discriminator. "and $\mathcal{L}_{\text{gan}$ denotes the adversarial discriminator loss."
- Argmax: An operation that selects the index of the maximum value, used to convert logits into discrete predictions. "with the argmax operation to obtain the results."
- Axis-specific vocabulary: A specialized token set that encodes X and Y coordinates separately to reduce sequence length and ambiguity. "Axis-specific vocabulary: we expanded the tokenizer’s vocabulary by introducing 2048 coordinates for both the X-axis and the Y-axis (e.g., <x\_0>)."
- Bernoulli trials: Independent binary probability events used to model multi-label token presence. "as the joint probability of independent Bernoulli trials over the vocabulary:"
- Bilinear interpolation: A grid-based resampling method used to upsample spatial logits to pixel resolution. "upsampled via bilinear interpolation () to recover pixel-level granularity."
- Chain-of-Thought (CoT): Structured, step-by-step reasoning traces added to training data to improve reasoning skills. "we incorporate a substantial volume of high-quality, synthetic short Chain-of-Thought (CoT) data."
- CLIP scores: Image-text similarity metrics from CLIP used to filter and align multimodal datasets. "strict image-text alignment filtering via CLIP scores"
- Codebook: A learned set of prototype vectors used by vector quantization to discretize continuous features into tokens. "a learnable codebook , configured with a vocabulary size of and embedding dimension ."
- Codebook collapse: A failure mode where only a few codebook entries are used, reducing representational diversity. "To preclude codebook collapse, we integrate a vector quantization loss $\mathcal{L}_{\text{vq}$ alongside an entropy regularization term $\mathcal{L}_{\text{ent}$."
- Copy-Paste strategy: Data augmentation that pastes objects onto backgrounds to synthesize diverse detection/segmentation scenes. "Specifically, the 'arbitrary category' scenario employs a Copy-Paste strategy where transparent objects undergo random resizing and rotation before being densely placed on backgrounds."
- Cross-attention: An attention mechanism where queries from one feature set attend to keys/values from another to fuse modalities. "we employ a cross-attention fusion mechanism that probes semantic features under structural constraints."
- Cross-entropy: A standard loss for token prediction that measures the negative log-likelihood of correct tokens. "enables direct token-level dense supervision via cross-entropy."
- Cumulative sequence length mechanism: An attention optimization that handles variable-length sequences efficiently by accumulating lengths. "leverages FlashAttention through the cumulative sequence length mechanism to handle variable-length sequences within a batch."
- Dense CRF: A Conditional Random Field post-processing step used to refine pixel-level segmentation masks. "a Dense CRF can be optionally employed as a post-processing step following interpolation."
- Dense prediction: Pixel/patch-level outputs (e.g., segmentation, depth) produced directly from model logits without auxiliary decoders. "Youtu-VL achieves direct dense prediction without auxiliary decoders or task-specific tokens."
- Depth estimation: Predicting scene depth, often via discretized bins and subsequent dequantization. "targeting pixel-level tasks like semantic segmentation and depth estimation, we utilize the model's native logit representations."
- DINOv3: A self-supervised vision model offering boundary-consistent local correspondences via self-distillation. "DINOv3 offers boundary-consistent local correspondences via self-distillation, which helps maintain spatial structure."
- Entropy regularization: A regularizer that encourages diverse token/codebook usage by increasing entropy. "alongside an entropy regularization term $\mathcal{L}_{\text{ent}$."
- FlashAttention: A memory-efficient exact attention algorithm that speeds training/inference for long sequences. "leverages FlashAttention through the cumulative sequence length mechanism"
- Global attention: Full-context attention periodically inserted into windowed attention stacks to provide global information flow. "with global attention inserted every 8 layers."
- Index Backpropagation Quantization (IBQ): A quantization approach that allows gradients to flow through discrete index assignments. "discretize it using Index Backpropagation Quantization (IBQ)"
- JEPA (Joint-Embedding Predictive Architecture): A framework for learning predictive joint embeddings used here to compute semantic density and mine rare samples. "we utilized state-of-the-art JEPA (Joint-Embedding Predictive Architecture) series models to compute a 'semantic density score' for each data point"
- LLM-as-a-judge framework: A strategy that uses one or more LLMs to evaluate and filter labels or outputs for quality. "utilizing an ensemble LLM-as-a-judge framework to ensure label correctness."
- Logit: An unnormalized score output by a model prior to softmax/sigmoid, used for category selection. "we utilize the model's native logit representations."
- Log-uniform quantization: Discretization using logarithmically spaced bins to capture wide dynamic ranges (e.g., depth). "We utilize log-uniform quantization with flexible prompt placement to define a valid depth range of 0.5m to 100m;"
- MD5 checksum deduplication: Removal of duplicate data by hashing items with MD5 checksums. "We applied MD5 checksum deduplication to remove redundancy"
- Multi-hot target vector: A binary vector with multiple ones, indicating multiple labels present for a single token/patch. "by constructing a multi-hot target vector for each image patch"
- Multi-Layer Perceptron (MLP): A feedforward neural network used to project features into another dimensionality. "Finally, a two-layer Multi-Layer Perceptron (MLP) projects these compressed features into the LLM's input space."
- Multi-label next-token prediction (NTP-M): An extension of NTP modeling independent Bernoulli probabilities per token with relevant negative sampling. "We term this NTP-M, a variant of the standard NTP adapted for multi-label and multi-task scenarios."
- Next-token prediction (NTP): Autoregressive objective that predicts the next token given the previous context. "We extend the next-token prediction (NTP) paradigm to vision tokens"
- Online hard example mining: A training scheme that prioritizes challenging samples; contrasted here with separate positive averaging and top‑k negatives. "Distinct from standard online hard example mining, which ranks positive and negative samples jointly"
- Perceptual similarity: A loss/metric that aligns reconstructions with human perception rather than pixel-wise error. "where $\mathcal{L}_{\text{lpips}$ enforces textural realism via perceptual similarity"
- Relevant negative sampling (top‑k): Selecting the highest-probability negative tokens to focus gradient updates and avoid dilution. "compute the average loss only for the top- relevant negatives."
- Semantic segmentation: Assigning a semantic class label to every pixel in an image. "For semantic segmentation, categories are standard text tokens."
- SigLIP-2: A multilingual vision-language encoder providing rich language-aligned semantics for visual features. "SigLIP-2 provides rich language-aligned semantics"
- Sigmoid: An activation function mapping logits to probabilities in [0,1] for independent token modeling. "σ() represents the sigmoid-activated probability for token at vision patch "
- Spatial Merge operation: Concatenating adjacent patch features to reduce token count and sequence length. "The Vision-Language Projector employs a Spatial Merge operation to concatenate adjacent patch features"
- Spatial Merge Projector: A projector module that merges spatial patches and maps visual features into the LLM token space. "integrates a Vision Encoder and Youtu-LLM via a Spatial Merge Projector"
- Synergistic Vision Tokenizer: A tokenizer that fuses semantic and geometric features to produce discrete visual tokens aligned with language. "Central to this design is our Synergistic Vision Tokenizer, which fuses high-level semantic concepts with low-level geometric structures"
- Token activation map: A technique/visualization indicating token-level activations, inspiring dense predictions from standard VLMs. "Inspired by the token activation map, we contend that a standard VLM is inherently a dense predictor"
- Unified Image-Text Vocabulary: A combined vocabulary of text and image tokens enabling unified autoregressive modeling across modalities. "Unified Image-Text Vocabulary ($\mathcal{V}_{\text{unified}$)"
- Vector quantization: Mapping continuous embeddings to nearest codebook vectors to produce discrete indices. "maps an image to a sequence of discrete indices through vector quantization."
- Vision tokenizer: A module that discretizes visual features into token indices serving as generation targets. "we introduce a vision tokenizer that maps an image to a sequence of discrete indices through vector quantization."
- Vision-LLMs (VLMs): Architectures combining visual encoders with LLMs to perform multimodal tasks. "Vision-LLMs (VLMs) have achieved significant proficiency in multimodal tasks"
- Vision-Language Unified Autoregressive Supervision (VLUAS): A training paradigm treating vision as a generation target to unify supervision over image and text. "Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm"
- Visual grounding: Localizing objects referenced by text by predicting bounding-box coordinate tokens. "Visual grounding is presented as the prediction of four coordinate tokens XYXY defining the bounding box."
- Window attention: Localized attention over non-overlapping windows to improve efficiency in vision transformers. "It further employs window attention for efficiency"
Collections
Sign up for free to add this paper to one or more collections.