Teaching LLMs to Ask: Self-Querying Category-Theoretic Planning for Under-Specified Reasoning
Abstract: Inference-time planning with LLMs frequently breaks under partial observability: when task-critical preconditions are not specified at query time, models tend to hallucinate missing facts or produce plans that violate hard constraints. We introduce \textbf{Self-Querying Bidirectional Categorical Planning (SQ-BCP)}, which explicitly represents precondition status (\texttt{Sat}/\texttt{Viol}/\texttt{Unk}) and resolves unknowns via (i) targeted self-queries to an oracle/user or (ii) \emph{bridging} hypotheses that establish the missing condition through an additional action. SQ-BCP performs bidirectional search and invokes a pullback-based verifier as a categorical certificate of goal compatibility, while using distance-based scores only for ranking and pruning. We prove that when the verifier succeeds and hard constraints pass deterministic checks, accepted plans are compatible with goal requirements; under bounded branching and finite resolution depth, SQ-BCP finds an accepting plan when one exists. Across WikiHow and RecipeNLG tasks with withheld preconditions, SQ-BCP reduces resource-violation rates to \textbf{14.9\%} and \textbf{5.8\%} (vs.\ \textbf{26.0\%} and \textbf{15.7\%} for the best baseline), while maintaining competitive reference quality.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
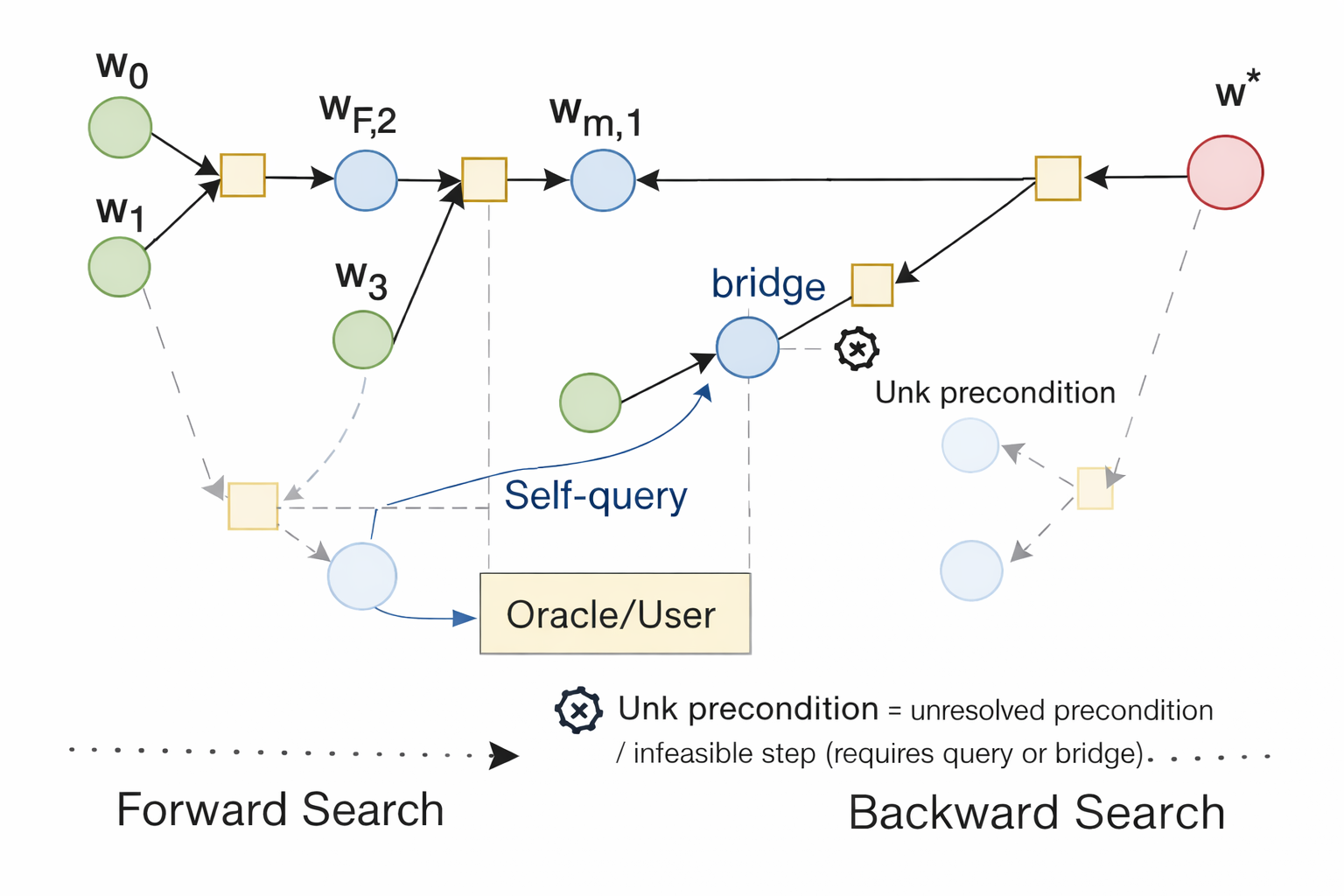
This paper is about teaching LLMs to plan better when the instructions they get are missing important details. Instead of guessing or making things up, the model learns to notice what it doesn’t know, ask focused questions, or add small setup steps before committing to a plan. The method is called SQ-BCP (Self-Querying Bidirectional Categorical Planning).
What problem are they solving?
In real life, people often give incomplete instructions. For example: “Make a toy car from a wooden table.” That sounds doable, but we don’t know:
- Do you have tools to cut wood?
- Is it okay to damage the table?
- Is the wood thick enough?
Many LLMs will still write a step-by-step plan—but it might use tools you don’t have or break your rules. The paper’s goal is to stop these “looks good but can’t actually do it” plans.
What questions did the researchers ask?
They focused on three simple questions:
- How can we make the model clearly track what it knows, what it doesn’t know, and what breaks the rules?
- When something is unknown, can the model either ask a good question or add a small “setup” action to make the plan possible?
- Can we verify that a final plan actually fits the goal and the rules, instead of just trusting that it “seems close”?
How does their method work?
Think of planning like building with Lego:
- Each action is a Lego piece that only fits if the connectors match (the “preconditions”).
- If a connector is unknown, you either ask for the missing piece (question) or add a new piece that makes it fit (bridge/setup step).
- Before you accept the final build, you check that all pieces actually fit together and match the picture on the box (verification).
Here are the key ideas, explained in everyday terms:
- Traffic-light labels for requirements (preconditions):
- Sat = satisfied (green light): you know it’s okay to do the step.
- Viol = violates a rule (red light): definitely not allowed.
- Unk = unknown (yellow light): you need to resolve it.
- Self-querying:
- When the model sees an “Unk,” it asks a short, targeted question (like “Do you have a saw?”).
- Bridging:
- If something is missing, the model adds a quick setup step to make it true (like “Borrow a saw from your neighbor” or “Measure the table leg first”).
- Bidirectional search:
- The model plans forward from the start and backward from the goal, trying to meet in the middle. This helps it stay on track.
- Verification using category theory (simple analogy):
- Category theory here is like a strict set of rules about how pieces can be connected.
- A “pullback” check is like verifying that two parts of the plan meet at a corner that is compatible from both sides—so the final plan fits the goal without breaking rules.
- Importantly, the model doesn’t accept a plan just because it “looks close.” It only accepts plans that pass these strict checks.
- Heuristics only for speed, not truth:
- The method uses a distance score to rank which ideas to try first (speeding up search).
- But passing the score never means “correct.” Only the hard checks and the verifier can approve a plan.
What did they test and what did they find?
They tested on two types of real-world instructions where details are often missing:
- WikiHow “how-to” tasks (like crafts, repairs, etc.)
- RecipeNLG cooking tasks (recipes and substitutions)
They hid some important preconditions (like required tools or ingredients) and compared methods on:
- Similarity to reference answers (ROUGE/BLEU scores)
- Resource violations (e.g., using tools/ingredients you don’t have)
Main results:
- SQ-BCP had far fewer rule/resource violations:
- WikiHow: 14.9% violations (best baseline: 26.0%)
- RecipeNLG: 5.8% violations (best baseline: 15.7%)
- It kept competitive quality on standard text metrics (ROUGE/BLEU), even though it focused more on making plans executable.
Why this matters:
- Some methods write beautiful plans that you can’t actually follow.
- SQ-BCP prefers plans you can really do, and still writes good-quality steps.
They also proved three helpful guarantees:
- The “ask-or-bridge” process always stops (no endless loops).
- If a plan passes their verifier, it fits the goal and rules.
- Under normal limits (not too many choices, not too deep), the search will find a valid plan if it exists.
What does this mean for the future?
This approach shows that:
- Teaching models to admit uncertainty, ask for missing facts, and add setup steps makes their plans more realistic and safer.
- Having a strict final check (the verifier) prevents “pretty but wrong” answers from slipping through.
- This could help in many areas—home projects, cooking, robotics, and more—where missing information is common.
A few practical limits:
- The paper used an “oracle” to answer questions (like a perfect user). Real people might give incomplete or noisy answers.
- The method adds extra computation (asking, checking, verifying), which can be slower.
- Some real-life constraints (like exact geometry or safety margins) are hard to check perfectly in text.
Quick example to tie it together
Task: “Make a toy car from a wooden table.”
- Unknowns: Do you have a saw? Is it okay to cut the table? Is the leg thick enough?
- SQ-BCP:
- Labels these as Unk (yellow).
- Asks: “Do you have a saw?” and “Is it okay to cut the table?”
- If no saw: adds a bridge step (“Borrow or buy a small hand saw”).
- Verifies the final plan doesn’t break your rules and uses only what you can actually get.
- Accepts the plan only if all checks pass.
In short: SQ-BCP trains LLMs to slow down, ask smart questions, and verify plans—so the steps you get are not just convincing, but also doable.
Knowledge Gaps
Open Questions and Knowledge Gaps
Below is a single, concrete list of limitations, unresolved questions, and missing analyses left by the paper that future work could address:
- Robust interaction: How to handle noisy, partial, contradictory, or delayed user/oracle responses, and how to make SQ-BCP robust to unreliable feedback while minimizing user burden.
- Cost-aware querying: How to explicitly optimize the trade-off between query cost (latency, cognitive load) and plan quality, including stopping rules and query scheduling under budgets.
- Precondition extraction reliability: How to calibrate, evaluate, and improve the backbone LLM’s Sat/Viol/Unk precondition labeling; lack of a benchmark and error analysis for precondition discovery accuracy.
- Learning to label preconditions: No mechanism to learn or adapt precondition identification from data or feedback; open how supervision or self-training could reduce misclassifications.
- From language to category objects/morphisms: Unspecified pipeline for mapping natural-language states/actions into categorical objects/morphisms at scale; reproducibility and domain portability remain unclear.
- Pullback verifier generality: The pullback-based verification is treated as a black box; details about implementation, computational cost, and how to instantiate it in new domains are missing.
- Continuous and stochastic constraints: Verification handles discrete, exact predicates; extending to continuous geometry, stochastic effects, and safety margins (e.g., via differentiable or probabilistic verification) is not addressed.
- Temporal/logical constraint evaluation: Although temporal and logical checks are implemented, experiments only report resource violations; temporal and logical violation rates are not measured.
- Heuristic pruning risks: The distance function D is used for ranking/pruning without analysis of sensitivity to weights, thresholds, or risks of pruning away valid solutions; no learning or calibration of D is provided.
- Completeness under pruning: Theoretical guarantees assume “no-pruning” and bounded unknowns; there is no guarantee or analysis of completeness when heuristic pruning is active in practice.
- Bridging policy optimality: The fixed “bridge-then-query” policy lacks a cost model or optimality analysis; no comparison to information-value or decision-theoretic strategies for deciding when to bridge vs. query.
- Bridge side effects and safety: Bridging actions may introduce side effects or safety risks; there is no framework to detect unsafe bridges or incorporate safety constraints in bridging.
- Cycle detection robustness: Signature-hash–based cycle detection may collide or miss semantic cycles; stronger, semantics-aware methods for preventing bridging loops are not explored.
- Query generation details: The paper does not specify how preconditions are transformed into unambiguous, well-scoped questions, nor how to handle multi-hop or conditional clarifications.
- Contingent execution: SQ-BCP requires all preconditions resolved before acceptance; it does not support contingent plans that defer queries or sensing to execution time, limiting applicability under dynamic uncertainty.
- Uncertainty modeling: Sat/Viol/Unk is ternary and non-probabilistic; no confidence scores, belief updates, or probabilistic reasoning are used, making it hard to act under noisy answers or partial resolutions.
- Long-horizon scalability: Experiments are on 4–10 step tasks; computational scaling, memory use, and latency for longer or more complex domains are not analyzed.
- Domain generalization: Evaluation is limited to textual procedural tasks (WikiHow, RecipeNLG); transfer to embodied, web, code generation, or multimodal settings is untested.
- Real-world execution: No validation with physical or simulated execution to verify feasibility in practice; typed effects remain language-level without grounding to sensors/actuators or tool APIs.
- Broader metrics: User-centric metrics (queries per task, response burden), execution time, compute cost, and success under noisy feedback are not reported; only resource violations and ROUGE/BLEU are used.
- Dataset and annotation fidelity: Withheld “latent preconditions” are derived from heuristics (e.g., “Things You’ll Need”); the completeness and accuracy of these labels, and their effect on results, are not validated.
- Precondition-type difficulty: The impact of which preconditions are withheld (resource vs. temporal vs. logical) on performance is not analyzed beyond k-reveal counts.
- Baseline parity: While baselines can call the oracle, they lack structured precondition tracking; it remains unclear how much of SQ-BCP’s gains stem from improved information access vs. structural modeling.
- Parameter sensitivity: No sensitivity study for T_bridge, ε (penalty), pruning thresholds, or distance cutoffs; default settings may materially affect results and completeness.
- Failure modes: There is no qualitative error analysis of cases where SQ-BCP still violates constraints or fails verification, limiting insight into remaining bottlenecks.
- Learning components: The framework is largely rule-based; it remains open how to learn better precondition extractors, question policies, or distance functions from data.
- Categorical scalability: The computational overhead and caching strategies for pullback verification across long compositional chains are not quantified.
- Goal parsing: How goal states (r*, s*, ℓ, t) are reliably extracted from natural language is unspecified, leaving a gap in end-to-end reproducibility.
- Safety and ethics: No safeguards against unsafe or non-compliant actions in bridging or plans; ethical and safety considerations for interactive querying and action proposals are unaddressed.
- Multi-agent and multi-user settings: Coordination with multiple stakeholders or conflicting constraints is not modeled.
- Adversarial robustness: Robustness to prompt attacks, adversarial user inputs, or maliciously misleading answers is unexamined.
- Reproducibility: Prompts, implementation details of the verifier, thresholds, and code are not provided, hindering independent replication and extension.
Practical Applications
Immediate Applications
Below are actionable, sector-linked uses that can be deployed now with modest engineering effort, leveraging SQ-BCP’s Sat/Viol/Unk precondition tracking, targeted self-querying, bridging actions, and verification-based acceptance.
- Feasibility-first planning layer for enterprise LLM agents
- Sector: software, finance (back-office), procurement, healthcare administration
- Tools/products/workflows: “Ask-before-act” and “verify-before-accept” middleware for chatbots and copilots; precondition tracker UI; Oracle connectors to CMDB/EHR/ERP; categorical verifier service to gate plans
- Assumptions/Dependencies: Access to domain data sources as oracles (e.g., APIs, databases, user inputs); crisp hard constraints expressible as predicates; backbone LLM can correctly label preconditions and propose bridge steps
- Clarify-then-act assistants for recipes and DIY tasks
- Sector: consumer (daily life), education
- Tools/products/workflows: “Feasibility-first” recipe/How-to assistant that asks about ingredients/tools, proposes substitutions (bridging), and rejects infeasible steps via hard checks and verification
- Assumptions/Dependencies: User acts as oracle; resource lists and constraints are captured in simple predicates; tolerance for interactive questioning
- DevOps and incident-response runbook copilots with precondition gates
- Sector: software (SRE/DevOps)
- Tools/products/workflows: Copilots that ask targeted questions (e.g., permissions, blast radius, service health), run bridging checks (smoke tests, canaries), and only accept plans that pass categorical verification; CI/CD gating
- Assumptions/Dependencies: Observability/CMDB APIs available; policies expressed as hard constraints; integration into existing runbooks and pipeline tools (e.g., GitHub Actions, Jenkins)
- Robotic Process Automation (RPA) bots with explicit applicability checks
- Sector: operations, customer support, finance operations
- Tools/products/workflows: RPA that labels preconditions per action (Sat/Viol/Unk), issues queries to systems/users, and inserts bridge steps (e.g., gather missing document) before execution
- Assumptions/Dependencies: Mappings from RPA actions to preconditions/effects; access to enterprise systems; bounded branching to keep latency acceptable
- Data engineering pipeline planner with “preflight” checks
- Sector: software/data
- Tools/products/workflows: Pipeline planning assistants that verify schema availability, permissions, SLAs, and data freshness; bridging via test queries or sample jobs; plan verifier to gate deployments
- Assumptions/Dependencies: Metadata catalogs (e.g., DataHub), IAM APIs, test harnesses; predicates that capture data constraints (schema, lineage, quotas)
- Customer support troubleshooting assistant
- Sector: software/hardware support
- Tools/products/workflows: Agents that ask precise diagnostic questions before proposing fixes; bridging steps to collect logs/telemetry; verification to ensure proposed fix aligns with constraints (warranty, security)
- Assumptions/Dependencies: Telemetry/log access; knowledge base for constraints; user cooperation for queries
- Education tutor and study planner that checks prerequisites
- Sector: education
- Tools/products/workflows: Tutors that verify prerequisite knowledge/resources/time (ℓ/t), ask clarifying questions (e.g., mastered topics, lab materials), and propose bridging study modules before advanced tasks
- Assumptions/Dependencies: Access to learner profile/calendar; content prerequisite graph; acceptance of interactive questioning
- Plan verification “lint” for LLM outputs
- Sector: academia, software, governance
- Tools/products/workflows: A plan-checker service that ingests LLM plans, annotates preconditions as Sat/Viol/Unk, asks targeted queries, and runs categorical verification; integrates into prompt pipelines (LangChain/AutoGen)
- Assumptions/Dependencies: Domain-specific predicates and state schemas (r, s, ℓ, t); oracle integration; tolerance for rejection or revision loops
- Procurement and inventory planning assistant
- Sector: procurement/supply chain
- Tools/products/workflows: Agents that confirm availability, compliance, and delivery windows; bridging through alternative suppliers or substitutions; verification to avoid resource-violation plans
- Assumptions/Dependencies: Inventory and supplier APIs; governance rules as hard constraints; user answers for missing info
- Policy and governance “minimum standard” for LLM agents
- Sector: policy/compliance
- Tools/products/workflows: Audit-ready logging of precondition labels, queries, bridges, and verification outcomes; mandate “clarify-then-act” workflows in enterprise AI usage guidelines
- Assumptions/Dependencies: Organizational buy-in; log retention and audit processes; mapping of constraints to formal predicates
Long-Term Applications
Below are forward-looking uses that require additional research, domain modeling, scaling, or regulatory maturation before broad deployment.
- Embodied robotics planning under partial observability
- Sector: robotics
- Tools/products/workflows: Robots that treat sensing as bridging, ask humans targeted questions, and gate action sequences via categorical verification; integration with motion planning and POMDP solvers
- Assumptions/Dependencies: Sensor models and continuous constraints (geometry, safety margins) formalized; reliable perception-to-state mappings; real-time performance and safety certification
- Clinical decision support with verified preconditions
- Sector: healthcare
- Tools/products/workflows: Systems that check clinical prerequisites (labs, vitals, contraindications), query EHRs/patients, insert bridging steps (order missing tests), and verify treatment plans against guideline constraints
- Assumptions/Dependencies: Regulatory approval; robust handling of noisy/incomplete EHR data; formalization of medical constraints; human-in-the-loop oversight
- Autonomous infrastructure operations (energy, transportation) with feasibility gates
- Sector: energy, transportation
- Tools/products/workflows: Control assistants that verify resource/timing constraints before scheduling maintenance or load shifts; bridging diagnostics; categorical verification against safety/operational goals
- Assumptions/Dependencies: Access to real-time telemetry and digital twins; formal safety predicates; rigorous fail-safe design and audits
- Multi-agent collaboration with shared precondition semantics
- Sector: software, logistics, manufacturing
- Tools/products/workflows: Agents negotiating resource usage and resolving conflicting preconditions via joint querying and bridging; shared categorical verifier for team-level goals
- Assumptions/Dependencies: Protocols for precondition exchange; conflict resolution policies; scalable verification across agents
- Domain operator libraries and standardized state schemas
- Sector: cross-domain (software, healthcare, robotics)
- Tools/products/workflows: Curated morphism/operator sets with explicit Pre/Eff typing, standardized (r, s, ℓ, t) schemas, and reusable bridging actions per domain
- Assumptions/Dependencies: Community-driven standards; ontologies/taxonomies; maintenance of operator correctness
- Formal verification and SMT integration for richer constraints
- Sector: software verification, safety-critical systems
- Tools/products/workflows: Hybrid categorical + SMT (e.g., Z3) verification layers to handle arithmetic, permissions, timing, and resource conflicts; certified acceptance pipelines for LLM plans
- Assumptions/Dependencies: Translating natural-language constraints to formal predicates; performance optimization; correctness proofs for combined verifiers
- Regulatory certification schemes for AI planning agents
- Sector: policy/regulation
- Tools/products/workflows: Certification frameworks that require explicit precondition tracking, logs of queries/bridges, and verification gates before plan execution in regulated domains
- Assumptions/Dependencies: Regulator engagement; standardized audits; interoperability with enterprise compliance systems
- Strategy gating and compliance in financial decision-making
- Sector: finance
- Tools/products/workflows: LLM-driven portfolio/risk workflows that verify preconditions (data quality, limits, mandates), query missing facts, and gate actions via categorical verification to reduce compliance violations
- Assumptions/Dependencies: Formal risk/compliance predicates; access to market/inventory data; latency and reliability guarantees
- Personal digital twin planning across resources, structure, predicates, time
- Sector: consumer (daily life), productivity
- Tools/products/workflows: Unified planner that tracks personal resources (budget/tools), structure (plans), predicates (preferences/constraints), and time (calendar), resolving unknowns via questions and bridging (e.g., scheduling, shopping)
- Assumptions/Dependencies: Secure integration with calendars, finances, devices; privacy controls; robust preference modeling and user interaction design
Glossary
- Acceptance gate: A verification step that must be passed before a plan is accepted. Example: "SQ-BCP positions verification as an acceptance gate: hard constraints are checked by exact predicates, and categorical verification certifies goal compatibility"
- Active perception/next-best-view: A planning paradigm that chooses sensing or viewpoint actions to reduce uncertainty about the environment. Example: "via active perception/next-best-view methods"
- Admissibility (A*): A property of a heuristic ensuring it never overestimates the true cost to reach a goal in A* search. Example: "cf. A* admissibility"
- AND-OR search graphs: Graph structures mixing AND nodes (all children must succeed) and OR nodes (any child can succeed), commonly used in problem decomposition. Example: "The bidirectional search pipeline maintains two AND-OR search graphs:"
- Bidirectional categorical search: A search procedure that grows paths from both start and goal within a categorical (compositional) framework. Example: "pullback-based verification integrating into bidirectional categorical search."
- Bidirectional search: A search strategy that expands from both the initial state and the goal to meet in the middle. Example: "SQ-BCP performs bidirectional search"
- BLEU: An n-gram precision-based metric for evaluating text generation quality. Example: "BLEU Score"
- Bridging hypotheses: Auxiliary actions proposed to establish missing preconditions before executing a main action. Example: "bridging hypotheses that establish the missing condition through an additional action."
- Categorical certificate: A formal categorical (category-theoretic) witness that a constructed plan is compatible with the goal. Example: "as a categorical certificate of goal compatibility"
- Categorical planning framework: A planning formulation based on category theory, where plans compose as morphisms. Example: "by extending the categorical planning framework"
- Category (in category theory): A mathematical structure consisting of objects and morphisms (arrows) that compose associatively with identities. Example: "We model task planning as a category whose objects are states and whose morphisms are valid operations."
- Conformant planning: Planning under uncertainty where the agent has no sensing and the plan must succeed from all possible initial states. Example: "conformant planning and POMDP formulations"
- Contingent planning: Planning with conditional branches based on information gathered during execution. Example: "conformant/contingent planning and POMDP formulations"
- Deterministic hard-constraint checks: Exact, non-probabilistic validations that ensure required constraints (resource, logical, temporal) are satisfied. Example: "Deterministic hard-constraint checks"
- Distance screening: A heuristic pre-filter using distance thresholds to avoid unnecessary expensive verification calls. Example: "Distance screening (efficiency heuristic)."
- Epistemic uncertainty: Uncertainty due to lack of knowledge about the world or preconditions. Example: "using self-querying to reduce epistemic uncertainty about preconditions"
- Fast Downward: A classical AI planning system that uses heuristic search over PDDL domains. Example: "Fast Downward"
- FF (Fast-Forward) planner: An influential heuristic planner that uses relaxed plan heuristics for speed. Example: "FF"
- Goal compatibility: Satisfaction of the goal specification by a plan, as checked by the verifier. Example: "as a categorical certificate of goal compatibility"
- Hard constraints: Non-negotiable requirements (e.g., resources, predicates, time) that must be satisfied for plan feasibility. Example: "plans that violate hard constraints."
- Heuristic distance: A task-specific metric used only to rank/prune candidates during search, not to certify correctness. Example: "using heuristic distance only for ranking/pruning."
- k-reveal protocol: An evaluation setup that reveals k of m latent preconditions to control observability during testing. Example: "a controlled -reveal protocol that withholds annotated preconditions"
- Latent preconditions: Necessary but initially hidden applicability conditions that must be discovered or established. Example: "latent preconditions correspond to missing but necessary recipe facts"
- Makespan: The total duration or completion time of a plan. Example: "Classical planning metrics (e.g., makespan and plan distance/edit measures)"
- Model checking: A formal verification technique that exhaustively checks whether a system satisfies a given specification. Example: "Formal verification tools such as model checking"
- Morphism (category theory): An arrow representing a structure-preserving transformation between objects (states). Example: "A morphism applies typed effects:"
- Oracle agent: An external entity that answers targeted queries with ground-truth facts during inference. Example: "There is an oracle agent that answers queries using ground-truth annotations."
- Partial observability: A setting where the agent lacks full information about the environment or preconditions at decision time. Example: "inference-time planning with LLMs frequently breaks under partial observability"
- PDDL (Planning Domain Definition Language): A standard language for specifying planning problems and domains. Example: "as in STRIPS and PDDL"
- POMDP (Partially Observable Markov Decision Process): A decision-making framework under uncertainty about both state and outcomes. Example: "POMDP formulations"
- Pullback-based verification: A categorical verification procedure that certifies compositional compatibility between a plan and a goal via pullbacks. Example: "We perform a pullback-based verification procedure"
- Resource-violation rate: The frequency with which generated plans misuse or require unavailable resources. Example: "reduces resource-violation rates to 14.9% and 5.8%"
- ROUGE: A recall-oriented n-gram overlap metric for summarization and generation quality. Example: "reference-similarity metrics (ROUGE/BLEU)"
- SAT/SMT solving: Constraint solving over Boolean (SAT) or richer first-order theories (SMT) used in verification. Example: "SAT/SMT solving"
- Self-querying: The process where the system autonomously asks targeted questions to resolve unknown preconditions. Example: "resolves unknowns via (i) targeted self-queries to an oracle/user"
- Sensing actions: Actions whose purpose is to acquire information about unknown aspects of the state. Example: "contingent planning with sensing actions"
- Signature hashing: A cycle-detection technique that hashes refinement signatures to prevent infinite loops. Example: "Cycle detection via signature hashing ... prevents infinite bridging loops."
- STRIPS: A classical action representation with explicit preconditions and effects for planning. Example: "as in STRIPS"
- Temporal feasibility: The property that a plan fits within temporal budgets or scheduling constraints. Example: "temporal feasibility"
- Tree-of-Thoughts (ToT): A reasoning method that explores alternative solution branches as a tree during inference. Example: "Tree-of-Thoughts (ToT)"
- Typed effects: Structured annotations of how an action changes state components (resources, predicates, etc.). Example: "Eff is typed effects"
- Sat/Viol/Unk semantics: Three-way labels indicating whether a precondition is satisfied, violated, or unknown. Example: "explicitly tracks reconditions with Sat/Viol/Unk semantics"
Collections
Sign up for free to add this paper to one or more collections.