Advancing Open-source World Models
Abstract: We present LingBot-World, an open-sourced world simulator stemming from video generation. Positioned as a top-tier world model, LingBot-World offers the following features. (1) It maintains high fidelity and robust dynamics in a broad spectrum of environments, including realism, scientific contexts, cartoon styles, and beyond. (2) It enables a minute-level horizon while preserving contextual consistency over time, which is also known as "long-term memory". (3) It supports real-time interactivity, achieving a latency of under 1 second when producing 16 frames per second. We provide public access to the code and model in an effort to narrow the divide between open-source and closed-source technologies. We believe our release will empower the community with practical applications across areas like content creation, gaming, and robot learning.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Advancing Open-source World Models” (LingBot-World)
Overview
This paper introduces LingBot-World, an open-source AI system that can create and run interactive virtual worlds in real time. Instead of just making short videos from text (like many “text-to-video” tools do), LingBot-World aims to be a true simulator: it keeps track of what’s happening over time, responds to user actions (like pressing W/A/S/D), and maintains logical rules (like objects not suddenly disappearing). The goal is to make a high-quality, controllable, and fast world model that anyone can use and improve.
Objectives and Questions
The paper sets out to solve a few clear problems:
- Can we build a “world model” that understands cause-and-effect, not just how pixels should look, so it behaves like a game world rather than a dream?
- Can the world stay consistent for minutes (not just seconds) so it remembers where things are and what has happened?
- Can it respond to user inputs in real time (under 1 second delay at 16 frames per second)?
- Can this be done across many styles (realistic, scientific animations, cartoons) and be fully open-source so the community can use and improve it?
Methods and Approach
The authors use three main ideas: a smarter data pipeline, a multi-stage training strategy, and speed-focused engineering.
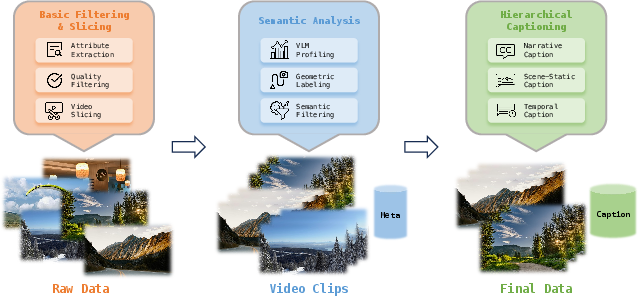
The Data Engine (collecting and labeling the right data)
Think of training a world model like teaching an AI to play and react inside different environments. You need good examples. The team gathers three kinds of data:
- General videos: High-quality clips from the real world (first-person and third-person) showing people, animals, and vehicles moving around.
- Game recordings: Videos matched perfectly with player actions (like W/A/S/D) and camera info. This teaches the AI how the world should react when someone presses a key or moves the camera.
- Synthetic scenes from Unreal Engine (UE): Computer-made environments with precise camera positions. This adds rare motions and accurate 3D information that’s hard to get from real videos.
They then “profile” the data—cleaning up bad clips, estimating missing camera information, and using a vision-LLM to sort videos by quality, motion, and viewpoint.
Finally, they add “hierarchical captions,” which are layered descriptions of each video:
- A narrative caption: a story-like summary of what’s happening and where.
- A scene-static caption: only details about the environment (no camera movement or actions), so the model learns what the place looks like.
- Dense temporal captions: time-stamped event descriptions, like a timeline, so the model knows when things happen.
This layered labeling helps the model separate “what the world is” from “how it moves,” which is key to good control.
The Training Pipeline (teaching the model step by step)
Training happens in three stages, like leveling up a character:
- Stage I: Pre-training. Start from a powerful video model (Wan2.2) so the AI already knows how to make sharp, coherent videos. This gives strong “visual instincts.”
- Stage II: Middle-training. Evolve the model into a world simulator:
- Use longer sequences (up to 60 seconds) to teach “long-term memory” so the world stays consistent.
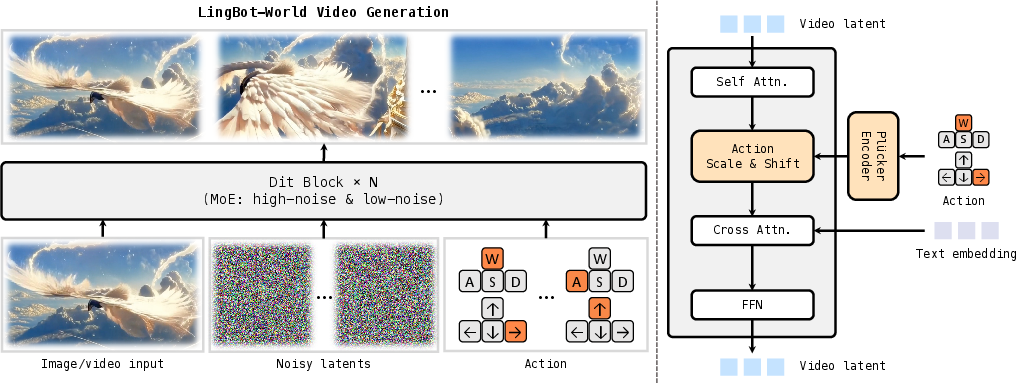
- Add action control (like W/A/S/D and camera rotation), injected using a gentle method called adaptive layer normalization. In simple terms, the actions guide the model without breaking its visual skills.
- Use a mixture-of-experts (MoE) design: imagine two specialist teams inside the model—one handles big-picture structure, the other polishes fine details. Only one team is active at a time, which keeps it efficient.
- Stage III: Post-training. Make it fast and interactive:
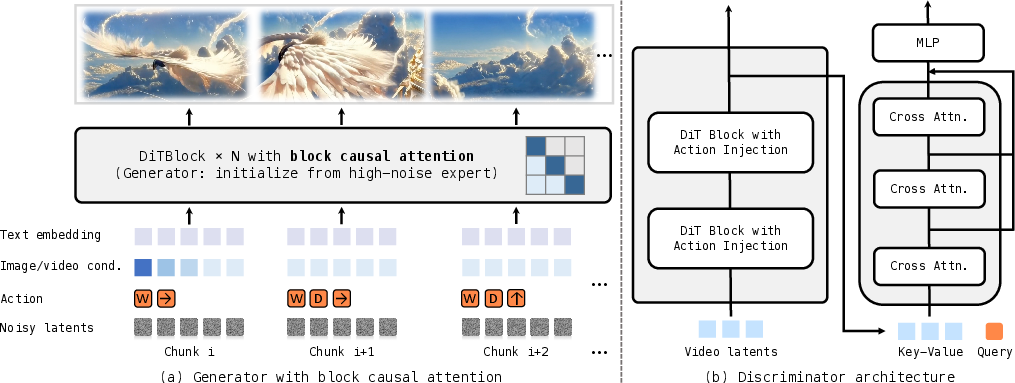
- Change the model’s attention to be “causal,” meaning it only looks at the past and present, not the future. This allows real-time, step-by-step generation.
- Do “few-step distillation,” where a fast student model learns from the stronger teacher to generate good frames in fewer steps. Think of it as compressing wisdom into speed.
- Train the student using its own outputs (self-rollouts) so it learns to handle mistakes and avoid drifting off-topic over long periods.
Action Control (how the model follows your inputs)
Actions are encoded in two ways:
- Camera rotations as continuous 3D signals (using a math-friendly representation called Plücker embeddings).
- Keyboard presses (W/A/S/D) as simple on/off codes. These are blended and fed into the model so it follows the user’s choices precisely.
Training at Scale (engineering to make it possible)
The model is large (tens of billions of parameters) and handles long videos, which is heavy on memory. To train it:
- FSDP2 splits the model across many GPUs so no single card has to hold everything.
- Context parallel splits long sequences across GPUs, then cleverly shares the needed pieces so attention can be computed efficiently.
Main Findings and Why They Matter
The paper reports that LingBot-World:
- Generates high-fidelity videos across many environments (realistic nature and cities, scientific visuals, cartoons).
- Maintains consistency over minutes, showing strong “long-term memory.” For example, landmarks don’t randomly change, and the model remembers objects and layout.
- Responds to user actions in real time, with under 1 second latency at 16 frames per second, making it feel interactive like a game.
- Provides a higher “dynamic degree” than many other systems—meaning it supports a wider range of movements and reactions—while being fully open-source.
- Supports prompts that change global conditions (like weather) and local behavior, and even enables stable 3D reconstruction from its videos, suggesting it understands geometry well.
This is important because it moves AI from passively making short clips to actively simulating worlds you can explore and control. It helps bridge the gap between “dreaming” and “simulating,” which is crucial for realistic games, training robots, and building virtual labs.
Implications and Impact
If widely adopted, LingBot-World could:
- Help creators and game developers build interactive scenes faster and at lower cost, with high visual quality.
- Offer a powerful testbed for robot learning, where robots can practice navigating and acting in simulated worlds before going into the real world.
- Enable scientific visualization and education tools that are interactive and engaging, not just videos you watch.
- Encourage community innovation, since it’s open-source. Researchers and developers can inspect the code and models, add features, fix problems, and build new applications.
In short, the paper shows a practical path from “text-to-video” to “text-to-world.” By combining good data, careful training, and smart engineering, LingBot-World brings us closer to AI that can run believable, responsive virtual worlds—and makes that capability available to everyone.
Knowledge Gaps
Below is a single, actionable list of knowledge gaps, limitations, and open questions the paper leaves unresolved:
- The paper’s core artifact name and several placeholders are missing (e.g., “We present , …”), causing ambiguity about the exact model release and hindering reproducibility and citation.
- No quantitative evaluation is provided for claimed capabilities (e.g., “high fidelity,” “robust dynamics,” “minute-level horizon,” “long-term memory,” “high dynamic degree”), leaving performance unsubstantiated.
- Definitions and measurement protocols for “dynamic degree,” “long-term memory,” and “interactive logic” are absent; standardized metrics and benchmarks for these properties are needed.
- Real-time latency claims (sub-second at 16 fps) lack hardware specification, resolution/bitrate settings, batch size, warm-start vs cold-start details, and variability under different action rates; a reproducible inference benchmark is needed.
- The resolution ceiling (720p) is noted in the comparison table but scaling to 1080p/4K, multi-stream generation, and associated latency/quality trade-offs are not explored.
- The middle-training stage’s emphasis on long-horizon generation is asserted, but there are no experiments quantifying temporal drift, scene identity preservation, or object permanence over minutes.
- “Spatial memory” is claimed to emerge, but there is no formal test (e.g., re-localization accuracy, loop closure robustness, identity tracking) to validate persistent world-state retention.
- Physics and causality are central motivations, yet no tasks or metrics evaluate physical consistency (e.g., collision handling, conservation laws, stable contacts, occlusion logic, causal intervention outcomes).
- The action space is limited and underspecified: WASD and camera rotation via Plücker embeddings are mentioned, but support for continuous translation, richer interactions (grasp/manipulate), and multi-agent dynamics is unclear.
- The mapping of discrete actions (e.g., WASD semantics) across heterogeneous domains (photorealistic, scientific, cartoon) is not defined; generalizable action ontologies and cross-domain alignment strategies are missing.
- Text prompts and action signals are both used for control, but conflict resolution, precedence rules, and compositional control (how text and actions interact or override each other) are not addressed.
- Hierarchical captioning relies on VLMs, yet caption correctness, temporal alignment accuracy, and the impact of VLM hallucinations on training are not measured or mitigated.
- Pseudo camera pose estimation for general videos (via MegaSAM and related methods) may be noisy; the effect of pose inaccuracies on training and action-controlled consistency is not ablated.
- The Unreal Engine synthetic pipeline claims “collision-free” trajectories, but validation, failure cases, and realism gaps (e.g., motion priors vs human behavior) are not quantified.
- Domain shift between synthetic UE/game data and real-world videos is not analyzed; robustness to out-of-distribution environments and actions remains open.
- The data engine’s scale, composition, licensing, and demographic/scene biases are not reported; ethical and legal considerations for data use and redistribution are missing.
- The MoE design (two 14B experts) lacks details on routing, load balancing, expert utilization, and training stability; risks of expert collapse or imbalance are not discussed or ablated.
- The post-training causal adaptation chooses the high-noise expert for initialization; the trade-off between coarse dynamics modeling and fine detail fidelity is not quantified against the low-noise expert.
- Block causal attention’s chunk size, stride, and KV cache policy are not studied; sensitivity analyses for drift, memory footprint, and latency under different chunking strategies are needed.
- Few-step distillation and self-rollout training lack hyperparameter details (target timesteps, rollout horizon, truncation window K, learning rates) and empirical ablations.
- The DMD/adversarial optimization section ends with a truncated gradient equation; the complete formulation, discriminator architecture, training stability, and failure cases are missing.
- No head-to-head quantitative comparisons with closed-source baselines (e.g., Genie 3, Mirage 2) on shared benchmarks; the comparison table is qualitative without standardized evaluation.
- There is no human evaluation protocol (e.g., controlled user studies) for interactivity quality, responsiveness, and subjective realism across domains.
- Long-horizon consistency for camera intrinsics/extrinsics and scene geometry is asserted, but 3D reconstruction validation (e.g., PSNR/SSIM against ground truth, pose accuracy, mesh consistency) is not reported.
- No robustness tests for action perturbations, rapid action switching, or adversarial inputs; failure modes (e.g., flicker, identity-switching, action-mismatch) are not cataloged.
- The framework’s applicability to robotics is stated, but transfer to real robot control (sim-to-real gap, action abstractions, safety constraints) and benchmarks (e.g., embodied tasks) are absent.
- Multi-agent environments, social interactions, and emergent behaviors are not explored; how the model handles multiple controllable entities remains open.
- Multimodal extensions (audio, tactile, language feedback loops) and their integration with action-conditioned generation are not investigated.
- Memory beyond “minute-level” horizons (e.g., tens of minutes/hours), cross-session persistence, and mechanisms for world-state serialization/loading are not discussed.
- Energy usage, training compute (GPU hours), and cost of the 28B MoE training and distillation pipeline are not reported; reproducibility and resource accessibility for the community are unclear.
- Safety, alignment, and content moderation in interactive worlds (e.g., harmful scenarios, misinformation in scientific contexts, age-appropriate content) are not addressed.
- Licensing terms for released weights/code and any constraints on commercial use, dataset redistribution, or UE asset inclusion are unspecified.
- The release plan omits instructions for end-to-end reproduction (data acquisition scripts, preprocessing, exact checkpoints, configs), making independent verification difficult.
- Scalability and maintainability of the parallelism stack (FSDP2 + Ulysses) under diverse cluster topologies, network fabrics, and mixed precision settings are not evaluated.
- Generalization across styles (realism vs cartoon vs scientific) is claimed, but cross-domain performance degradations and per-domain fine-tuning needs are unquantified.
- The impact of progressive curriculum design (noise schedules, flow shift scaling) on long-horizon stability lacks controlled ablations and theoretical explanation.
- The model’s ability to handle complex event chains (“promptable world events”) is not benchmarked (event accuracy, latency to enact, causal side-effects, reversibility).
Practical Applications
Immediate Applications
Below are practical applications that can be deployed now, drawing directly from the paper’s released code, models, data engine, and training pipeline.
- Actionable world-simulation sandbox for research and teaching
- Sector: Academia, Software
- Use cases:
- Benchmarking and ablations on long-horizon, action-conditioned video generation; evaluating block-causal attention, few-step distillation, and MoE design.
- Coursework labs on generative modeling, sequence modeling, and sim-to-real basics.
- Potential tools/workflows: “Reproduce-and-extend” notebooks; plug-in evaluators for rollout drift, action-following accuracy, and memory retention.
- Assumptions/dependencies: Access to the open-source repo and checkpoints; a single high-memory GPU for real-time demos or multi-GPU cluster for fine-tuning.
- Rapid previsualization and concepting for scenes
- Sector: Media/Entertainment, Advertising
- Use cases:
- Directors or art teams interactively scout camera moves, compositions, and lighting moods.
- Producing draft background plates or storyboards with text prompts + W/A/S/D exploration.
- Potential tools/workflows: Real-time “virtual camera” operator; shot library generator with hierarchical captions to maintain narrative continuity.
- Assumptions/dependencies: Legal review for asset usage; acknowledge that physics is plausible but not physically guaranteed.
- Game design ideation and level “feel” exploration
- Sector: Gaming
- Use cases:
- Designers explore traversal flows, sightlines, or pacing in generated spaces before blocking levels in UE/Unity.
- Automated “world beats” generation using scene-static vs. dense temporal captions to decouple art direction from motion logic.
- Potential tools/workflows: UE integration for quick camera-path prototyping; in-editor panel to steer world state with prompts.
- Assumptions/dependencies: Requires content pipeline alignment with existing engines; quality varies by domain.
- Data augmentation and curriculum creation for embodied AI
- Sector: Robotics, Autonomous Systems
- Use cases:
- Generate action-labeled rollouts for imitation or RL pretraining (navigation, exploration, camera control).
- Domain randomization via text-driven world condition changes to improve robustness.
- Potential tools/workflows: Offline dataset generator producing action-conditioned trajectories; scripted “event injections” for curriculum learning.
- Assumptions/dependencies: Sim-to-real gap persists; current interactions are richer for ego-motion and navigation than for dexterous manipulation.
- Hierarchical video captioning to bootstrap downstream video understanding tasks
- Sector: Software, NLP/CV
- Use cases:
- Enrich existing video corpora with narrative, scene-static, and dense temporal captions to improve retrieval, summarization, and grounding.
- Potential tools/workflows: Captioning service that outputs three-layer annotations; dataset profiling pipeline (quality/motion/POV).
- Assumptions/dependencies: VLM quality gates; compute for batch captioning; careful filtering to avoid propagating VLM biases.
- Synthetic data generation with precise camera poses
- Sector: Vision/3D, Robotics
- Use cases:
- Training camera pose estimators, SLAM components, and novel view synthesis using UE-generated trajectories with exact intrinsics/extrinsics.
- Potential tools/workflows: UE batch renderer + automated trajectory generator (procedural patterns, multi-point interpolation, real-path imports).
- Assumptions/dependencies: UE licenses; storage for rendered sequences; tuning trajectory distributions to match target use.
- Consistent 3D reconstruction from generated videos
- Sector: Vision/3D, Media
- Use cases:
- Convert stable generated sequences into implicit/explicit 3D assets (NeRF, Gaussian Splatting) for VR previews, virtual tours, or previsualization.
- Potential tools/workflows: Pipeline that takes generated rollouts → camera pose estimation (if needed) → 3D reconstruction → quick turntable renders.
- Assumptions/dependencies: Visual consistency is good but not perfect; reflective/texture-heavy scenes need QA; reconstruction quality depends on motion coverage.
- Privacy-preserving content synthesis and sanitization
- Sector: Policy, Compliance, Advertising
- Use cases:
- Replace sensitive real footage with semantically equivalent synthetic scenes for training or concept testing.
- Potential tools/workflows: “Synthetic stand-in” generator driven by scene-static captions; audit logs linking prompts to outputs.
- Assumptions/dependencies: Clear disclosure and provenance required; ensure no inadvertent leakage from training data.
- Teaching and demos for camera geometry and navigation
- Sector: Education
- Use cases:
- Interactive lessons on camera motion, pose, parallax, and scene continuity using low-latency world simulation.
- Potential tools/workflows: Classroom kits with pre-scripted prompts and action macros demonstrating long-term memory and continuity.
- Assumptions/dependencies: Modest GPU for real-time; curated lesson plans to avoid content drift.
- Real-time generative backdrops for livestreamers and virtual events
- Sector: Creator Economy, Events
- Use cases:
- Host navigates a stylized environment as a dynamic background responding to text cues.
- Potential tools/workflows: OBS plugin for scene control; preset “world moods” mapped to prompts and macro actions.
- Assumptions/dependencies: Performance tuning for streaming PCs; content safety filters.
Long-Term Applications
These applications are feasible with further advances in interactivity, physics fidelity, content controls, scaling, and tooling integration.
- Text-to-playable level generation and runtime expansion
- Sector: Gaming
- Use cases:
- Generate shippable, coherent, and persistently interactive levels and side-quests on demand; dynamic live ops content.
- Potential tools/workflows: Engine middleware that converts narrative + scene-static captions into asset graphs and navmeshes, with runtime “world events.”
- Assumptions/dependencies: Stronger physics, object interaction semantics, memory across sessions, and content moderation; engine-level integrations.
- High-fidelity digital twins for planning and what-if analysis
- Sector: Smart Cities, Manufacturing, Logistics, Energy
- Use cases:
- Scenario testing (evacuations, disruptions), layout optimization, operator training in synthetic replicas of facilities or urban blocks.
- Potential tools/workflows: “Twin composer” that binds CAD/BIM data to generative world dynamics; policy testing dashboards with scripted events.
- Assumptions/dependencies: Accurate causal dynamics and constraints; data governance for sensitive blueprints; rigorous validation against real KPIs.
- Sim-to-real training of mobile robots and autonomous vehicles
- Sector: Robotics, Automotive, Aviation
- Use cases:
- End-to-end policy training with text-controlled environment randomization; rare event and edge-case generation at scale.
- Potential tools/workflows: RL stacks tied to action-conditioned rollouts; curricula that target long-horizon dependencies and recovery from compounding errors.
- Assumptions/dependencies: Improved contact dynamics and sensor fidelity; calibrated photometry; domain adaptation pipelines; safety certification workflows.
- On-set real-time virtual production with generative worlds
- Sector: Film/TV
- Use cases:
- Directors steer backgrounds and set extensions live; camera tracking drives world response; long takes without resets.
- Potential tools/workflows: Ingest lens/camera tracking → causal world generator with KV-cached streaming; color-managed pipeline to LED walls.
- Assumptions/dependencies: Film-grade fidelity, latency < 100 ms target, deterministic scene replay, content IP guardrails.
- Immersive skill training and simulation for healthcare and public safety
- Sector: Healthcare, Public Sector
- Use cases:
- Procedure rehearsal, triage drills, disaster response training with controllable world states and minute-level memory.
- Potential tools/workflows: Scenario authoring via hierarchical captions; assessment layers logging trainee actions and world reactions.
- Assumptions/dependencies: Domain-validated causal models; ethics and safety review; integration with haptics and medical devices.
- Personalized, interactive learning environments
- Sector: Education
- Use cases:
- Tutor-guided explorations where the environment adapts to learner progress; science labs with configurable experiments.
- Potential tools/workflows: LLM + world model orchestration; assessment-aware world events; teacher dashboards for pathway control.
- Assumptions/dependencies: Stronger grounding of physics and causality; classroom device constraints; content governance.
- Autonomous agent safety sandboxes and regulatory testbeds
- Sector: Policy/Regulation, Safety
- Use cases:
- Stress-test agents under adversarial or rare conditions; standardized evaluation suites for deployment approvals.
- Potential tools/workflows: Scenario banks with measurable benchmarks (action-following, recovery, hazard response); audit trails and reproducible seeds.
- Assumptions/dependencies: Accepted standards for synthetic evaluations; traceability; bias audits to avoid overfitting to simulator artifacts.
- CAD-to-world generators for rapid prototyping
- Sector: Industrial Design, Architecture
- Use cases:
- Convert floorplans and CAD into interactive mockups for spatial experience testing before fabrication.
- Potential tools/workflows: Procedural camera-path and event scripting layered over imported geometry; multi-user walkthroughs.
- Assumptions/dependencies: Robust geometry ingestion; scale-aware rendering; accurate collision and accessibility constraints.
- Synthetic data mills for video-LLMs and AV perception
- Sector: CV/NLP, Automotive
- Use cases:
- Generate richly captioned, action-grounded video corpora to reduce reliance on sensitive or scarce real footage.
- Potential tools/workflows: Programmatic data factories using hierarchical captions; bias/coverage dashboards.
- Assumptions/dependencies: Prevent simulator-induced biases; maintain domain diversity; governance for synthetic-to-real performance claims.
- Everyday personal worlds and companions
- Sector: Consumer, XR
- Use cases:
- Persistent, user-steerable virtual spaces for relaxation, journaling, or co-working; “walk-and-talk” interfaces.
- Potential tools/workflows: Mobile/AR clients streaming from causal generators; voice/text action control.
- Assumptions/dependencies: Edge/cloud latency budgets; safety filtering; memory that spans sessions and devices.
Cross-cutting assumptions and dependencies
- Compute and latency: Real-time claims (≤1 s at 16 FPS) depend on modern GPUs and optimized KV caching; mobile or edge deployments require additional distillation/quantization.
- Physics and causality: Current dynamics are plausible but not fully physically grounded; high-stakes uses need validated simulators or hybrid pipelines.
- Data/IP governance: UE assets, game captures, and web videos must meet licensing and privacy requirements; synthetic provenance and watermarking are advisable.
- Safety and content controls: Open-ended generation needs guardrails for harmful or biased content; policy-facing uses require auditability and reproducibility.
- Integration effort: Engine plugins, training stacks (FSDP2, context parallel), and captioning VLMs must be operationalized; MLOps and dataset curation pipelines are non-trivial.
Glossary
- Activation checkpointing: A memory-saving technique that recomputes intermediate activations during backpropagation instead of storing them. "memory-intensive operations such as gradient computation, optimizer state management, and activation checkpointing."
- Action-contingent dynamics: Environment changes that are explicitly conditioned on or caused by an agent’s actions. "allowing the model to learn precise action-contingent dynamics."
- Adaptive layer normalization (AdaLN): A conditioning method that injects control signals by modulating the scale and shift parameters of layer normalization. "we utilize an adaptive layer normalization (AdaLN) mechanism"
- Adversarial optimization: Training with an adversary (e.g., GAN-style) to better align generated and real data distributions. "augmented with self-rollout training and adversarial optimization"
- All-to-all collective communication: A distributed systems primitive where each device exchanges data with all others, used to redistribute tensor shards efficiently. "an efficient all-to-all collective communication pattern"
- Autoregressive system: A model that generates each new element conditioned only on past outputs, enabling step-by-step inference. "the bidirectional diffusion model is post-trained into an efficient autoregressive system"
- Bidirectional diffusion model: A diffusion model that attends to both past and future frames during training/inference to capture global temporal dependencies. "the bidirectional diffusion model is post-trained into an efficient autoregressive system"
- Block causal attention: An attention scheme that is bidirectional within local chunks but causal across chunks to enable streaming generation. "We replace full temporal attention with block causal attention, combining local bidirectional dependencies within chunks and global causality across chunks."
- Camera extrinsics: Parameters that describe the camera’s position and orientation in the world coordinate system. "ground-truth camera intrinsics and extrinsics."
- Camera intrinsics: Parameters that describe the internal characteristics of the camera (e.g., focal length, principal point). "ground-truth camera intrinsics and extrinsics."
- Causal architecture adaptation: Modifying a model to enforce causality so that predictions depend only on past information for real-time rollout. "Causal architecture adaptation: We replace full temporal attention with block causal attention"
- Causal paradigm: A modeling approach where outputs are conditioned only on past inputs, not future ones. "our formulation seamlessly shifts to the causal paradigm"
- Context parallel (CP): Distributing a long sequence across multiple devices so each processes a shard of the context. "Context parallel (CP). To mitigate the memory bottleneck arising from long token length, we adopt Ulysses"
- Dense temporal caption: Fine-grained, time-aligned annotations that describe events over small temporal segments. "Dense temporal caption: This type offers fine-grained, time-aligned descriptions"
- Diffusion forcing: A training strategy that adapts diffusion models to causal generation by supervising specific timesteps under causal constraints. "through diffusion forcing mechanism"
- Diffusion model: A generative model that iteratively denoises samples from noise to data. "standard bidirectional diffusion models are computationally prohibitive"
- Distribution matching distillation (DMD): A distillation method that aligns the student’s distribution with real data via score-based or divergence objectives. "We employ distribution matching distillation (DMD) augmented with self-rollout training and adversarial optimization"
- Ego-centric perspective: A first-person viewpoint where the camera is aligned with the agent’s eyes or head. "ranging from human and animal ego-centric perspectives to third-person camera angles."
- Few-step distillation: Compressing a multi-step generative sampler into a small number of steps while preserving quality. "employing causal attention and few-step distillation to achieve low latency and strict causality."
- Fully sharded data parallel 2 (FSDP2): A data-parallel training method that shards parameters, gradients, and optimizer states across devices. "Fully sharded data parallel 2 (FSDP2). To support efficient training of 28B-parameter , we employ FSDP2"
- GAN classification head: A discriminator head that classifies real vs. generated samples to reduce drift or improve realism. "a GAN classification head "
- Key-value caching (KV caching): Reusing stored attention keys and values from previous steps to speed up autoregressive inference. "enabling efficient autoregressive generation via KV caching"
- Latents: Compressed intermediate representations on which generative models operate (e.g., in latent diffusion). " uses an image or a video, noisy latents, and user-defined action signals"
- Mixture-of-experts (MoE): A model architecture that routes inputs to specialized expert sub-networks to improve capacity and efficiency. "we employ a mixture-of-experts (MoE) architecture"
- Plücker embeddings: A representation based on Plücker coordinates for encoding 3D geometric entities (e.g., camera rotations/lines) as features. "Plücker Encoder, where the input actions are projected into Plücker embeddings"
- Pose estimation: Inferring camera or object position and orientation from visual data. "state-of-the-art pose estimation models"
- Progressive curriculum training: Gradually increasing task difficulty or sequence length during training to stabilize learning. "Progressive curriculum training. To enable to achieve long-term video consistency and spatial memory, we adopt a progressive curriculum training strategy."
- Pseudo-labels: Labels generated by a model (rather than manual annotation) used to supervise training. "generate pseudo-labels for camera intrinsics and extrinsics"
- Self-attention: An attention mechanism where tokens attend to other tokens within the same sequence to model dependencies. "video latent first passes through a self-attention layer"
- Self-rollout training: Training a model on its own generated sequences to reduce train–test distribution mismatch. "augmented with self-rollout training"
- Sequence parallelism: Sharding the sequence dimension across devices to reduce memory for attention and activations. "Ulysses introduces sequence parallelism by partitioning the input tensor"
- Spatiotemporal coherence: Consistency of generated content across both space (frames) and time (sequence). "which endows with strong spatiotemporal coherence"
- Temporal chunk: A contiguous block of frames processed together, often with local bidirectional attention. "Within each temporal chunk, tokens attend bidirectionally"
- Vision-LLM (VLM): A model jointly trained on visual and textual data to perform multimodal understanding or generation. "vision-LLM (VLM)"
- World model: A model that captures environment dynamics to predict or simulate future states given actions. "We formulate the world model as a conditional generative process that simulates the evolution of visual states driven by agent actions."
Collections
Sign up for free to add this paper to one or more collections.