- The paper quantifies that LLM-assisted reviewers inflate scores by up to 0.63 points for LLM-aided papers due to general review leniency.
- It employs causal regression and within-paper paired analysis to control for quality confounding and isolate LLM effect differences.
- Findings highlight that policy should avoid naive LLM-to-LLM review matching, as inflated ratings stem from leniency toward lower-quality submissions.
Quantifying Interaction Effects of LLM Usage in Peer Review
Introduction
The proliferation of LLMs has strongly impacted scientific publication workflows, with measurable incidence in both scholarly manuscript composition and peer review. This study addresses the central question of whether LLM-assisted reviewers systematically treat LLM-assisted papers differently—so-called “AI–AI” interaction effects—in high-stakes peer review. Leveraging a dataset of over 125,000 paper-review pairs from ICLR, NeurIPS, and ICML, the analysis applies both observational causal inference and controlled synthetic evaluation to quantify differential treatment and its downstream consequences.
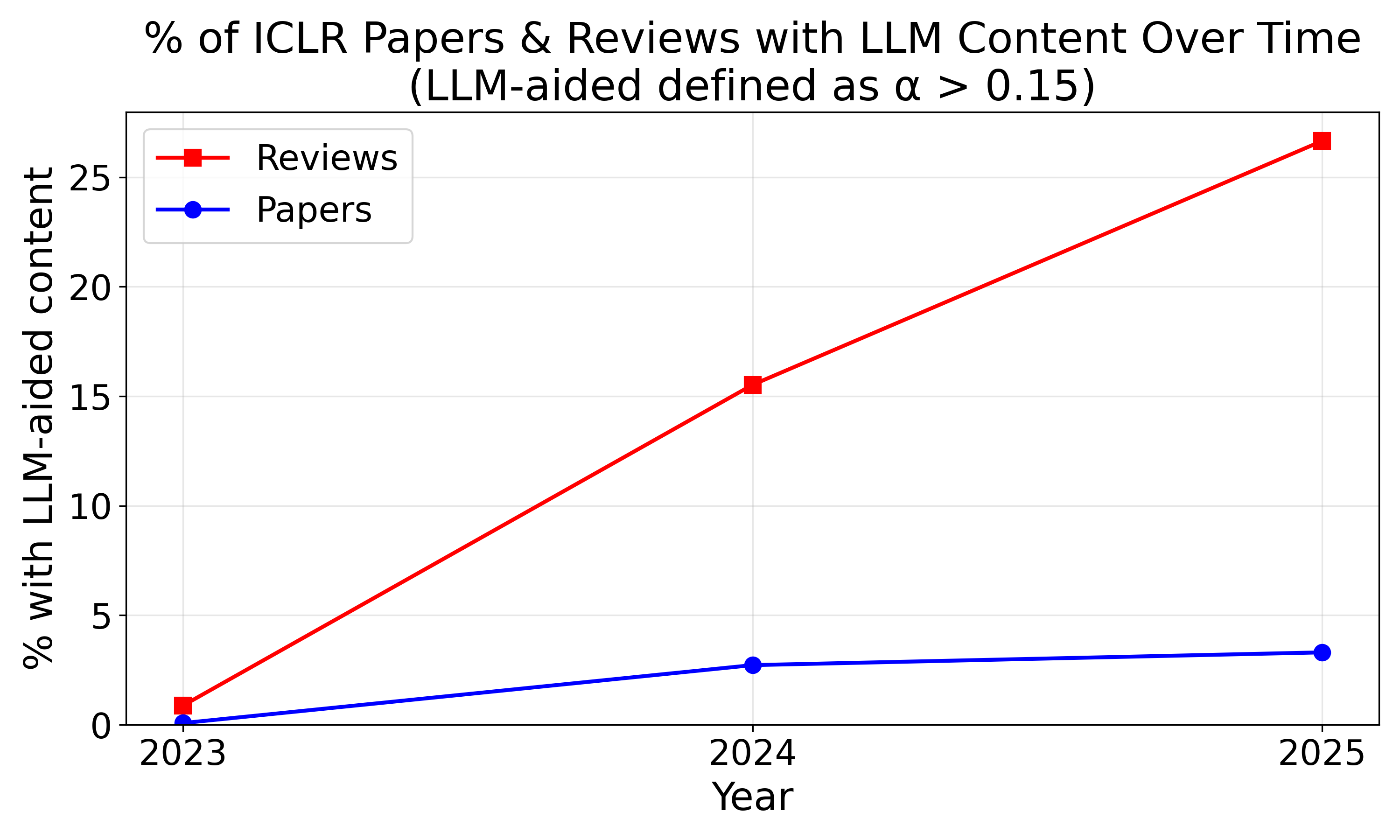
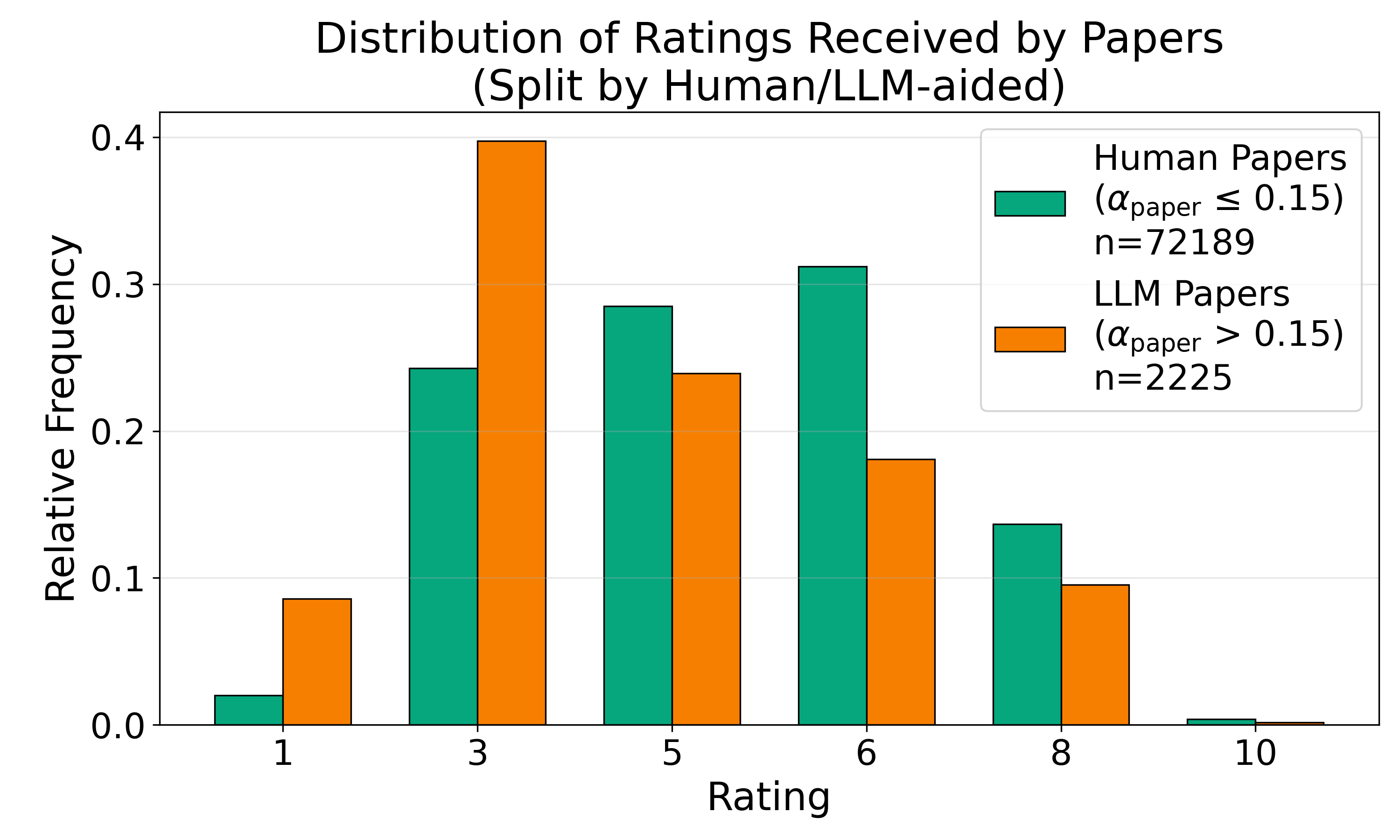
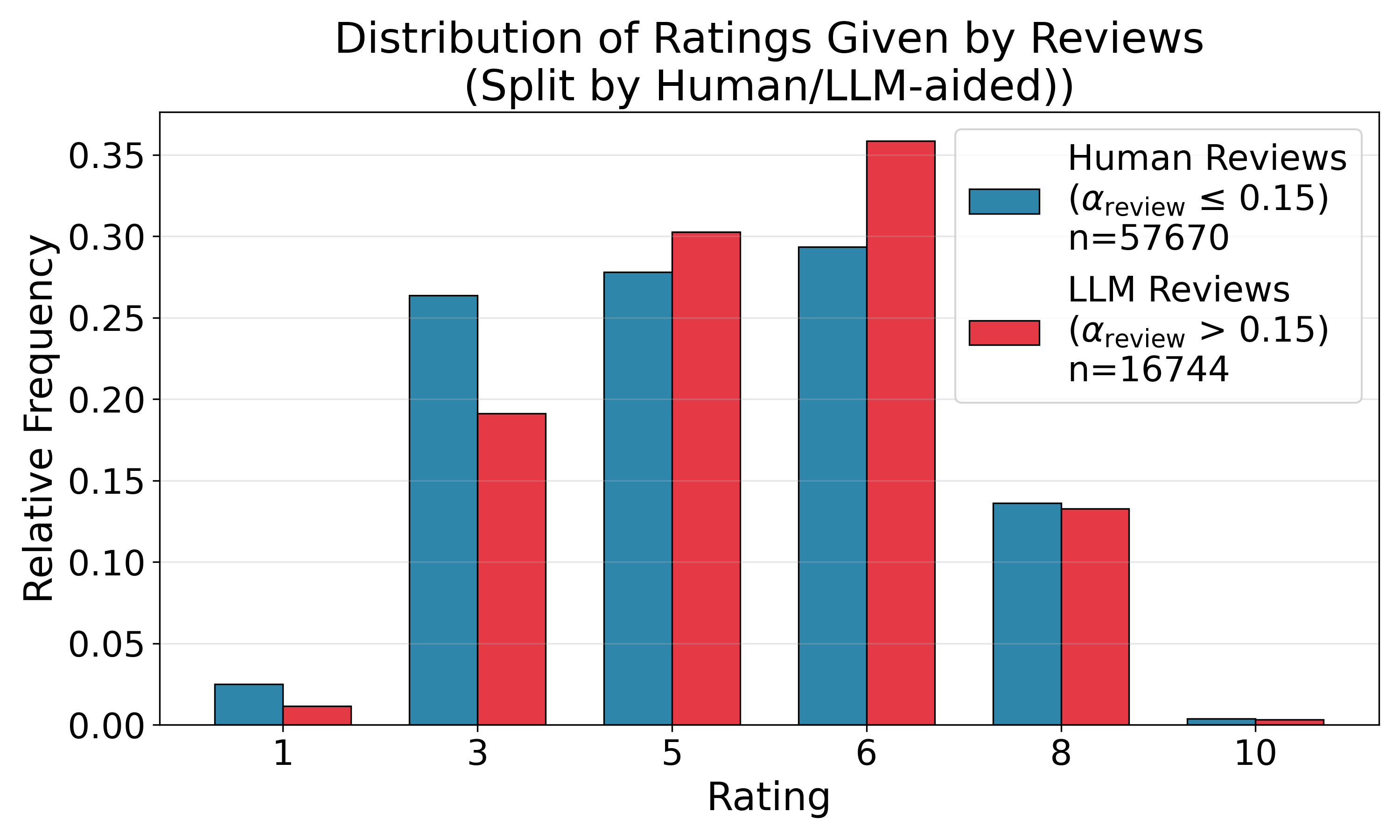
Figure 1: LLM usage incidence in scientific papers and peer review, displayed longitudinally.
Data and LLM Use Detection
Conference submissions and peer review data are aggregated from OpenReview for three leading venues. LLM involvement is identified using established mixture-based lexical distribution estimation, operationalizing the proportion α of vocabulary consistent with GPT-3.5/GPT-4o outputs. A threshold of α>0.15 demarcates LLM-aided text. Notably, LLM-assistance is more prevalent in reviews than in papers, exceeding 26% in ICLR 2025 reviews.
Observed Review and Rating Distributions
LLM-aided papers cluster toward lower reviewer scores, whereas LLM-aided reviews manifest moderate rating compression, eschewing extreme assessments. LLM-aided reviewers assign fewer highly negative or highly positive scores compared to human reviewers.
Quantifying Interaction: Are LLM-aided Reviewers “Nicer” to LLM-aided Papers?
Pairwise quadrant means suggest a substantial differential: LLM-aided reviews elevate ratings by 0.25 points for human papers but by 0.63 points for LLM-aided papers. However, simple marginal differences are confounded by correlated paper quality and LLM use.
A causal regression framework incorporating area fixed effects and a reviewer-paper LLM status interaction term reveals that:
- LLM-aided reviews inflate scores for all papers, with an increased conditional average treatment effect (CATE) for LLM-aided papers.
- The interaction term (β3) capturing differential “kindness” is positive and significant but inflated by quality confounding.
Within-paper paired analysis—directly comparing LLM-aided vs. human reviews of the same paper—grounds the CATE in the absence of cross-paper heterogeneity. The differential is much reduced (≈0.10 points), and statistical significance is marginal (p≈0.06).
Quality-Dependent Effects and Bucketed Analysis
When stratifying by exogenous paper quality (anchored on an independent human review), LLM-aided reviews are systematically more lenient toward low-quality papers, regardless of LLM authorship. Importantly, LLM-aided papers are overrepresented in these low-quality strata, resulting in a compositional artifact rather than genuine preferential treatment.
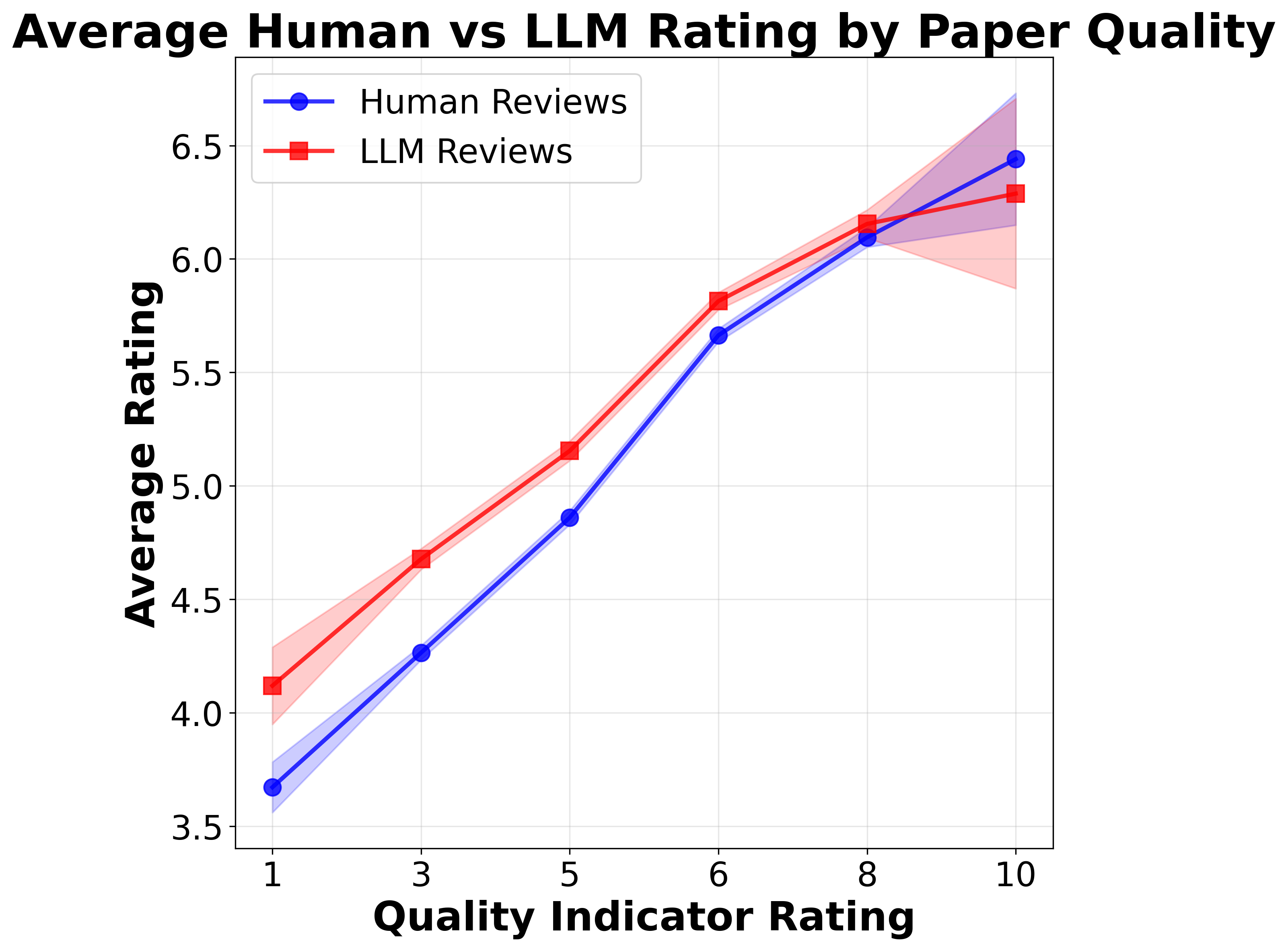
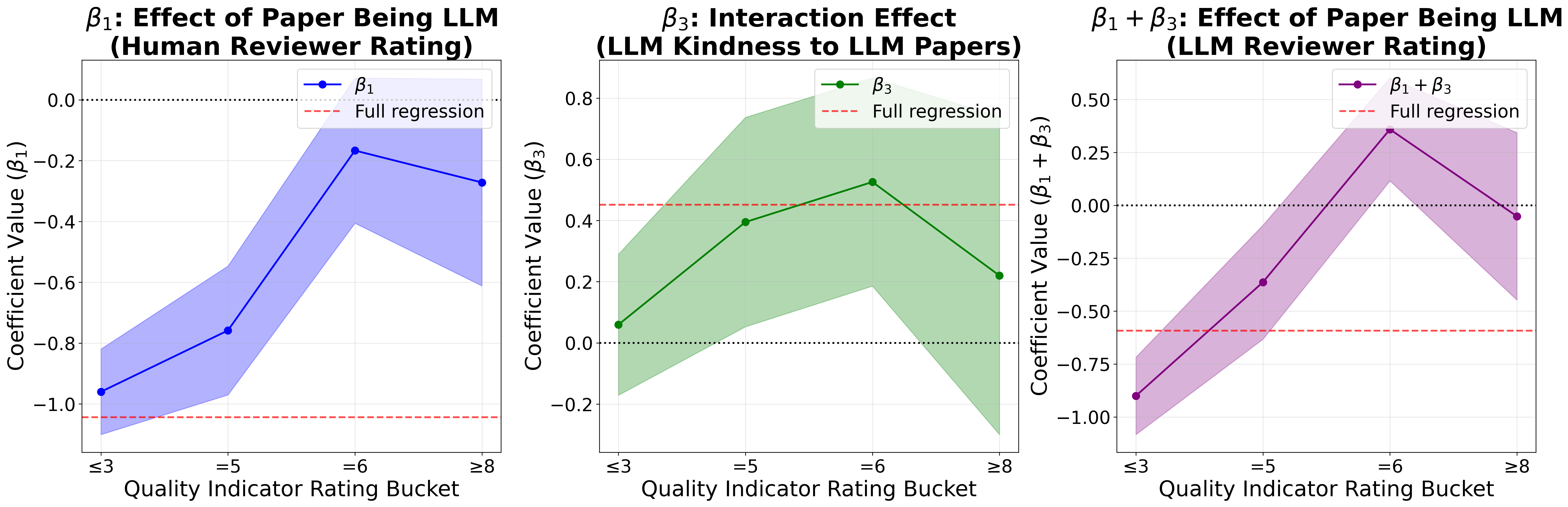
Figure 2: LLM-aided review vs. human review average ratings by paper quality bucket, with uncertainty bands.
Regression within buckets confirms that the LLM-aided review “kindness” to LLM-aided papers vanishes at high quality levels (β3∼0), appearing only in the mid-quality band. There is no statistically significant differential CATE in any quality tier with noise-adjusted paired analysis.
LLM-Aided Review Influence on Outcomes
LLM-aided reviews have lower alignment with final accept/reject decisions (73.8% vs. 77.7% for humans), especially for moderately rated or borderline submissions. Thus, LLM-assistance does not confer disproportionate influence on paper fate even in ambiguous cases.
Synthetic Evaluation: Fully LLM-Generated Reviews
To isolate LLM-side effects, the authors prompt GPT-4o to review papers without human-in-the-loop editing. Fully LLM-generated reviews exhibit extreme rating compression, assigning scores between 6–7 regardless of actual paper quality. Differentials are amplified relative to naturalistic LLM-assisted reviews, but this is an artifact of global leniency rather than “recognition” or preference for LLM-generated content.
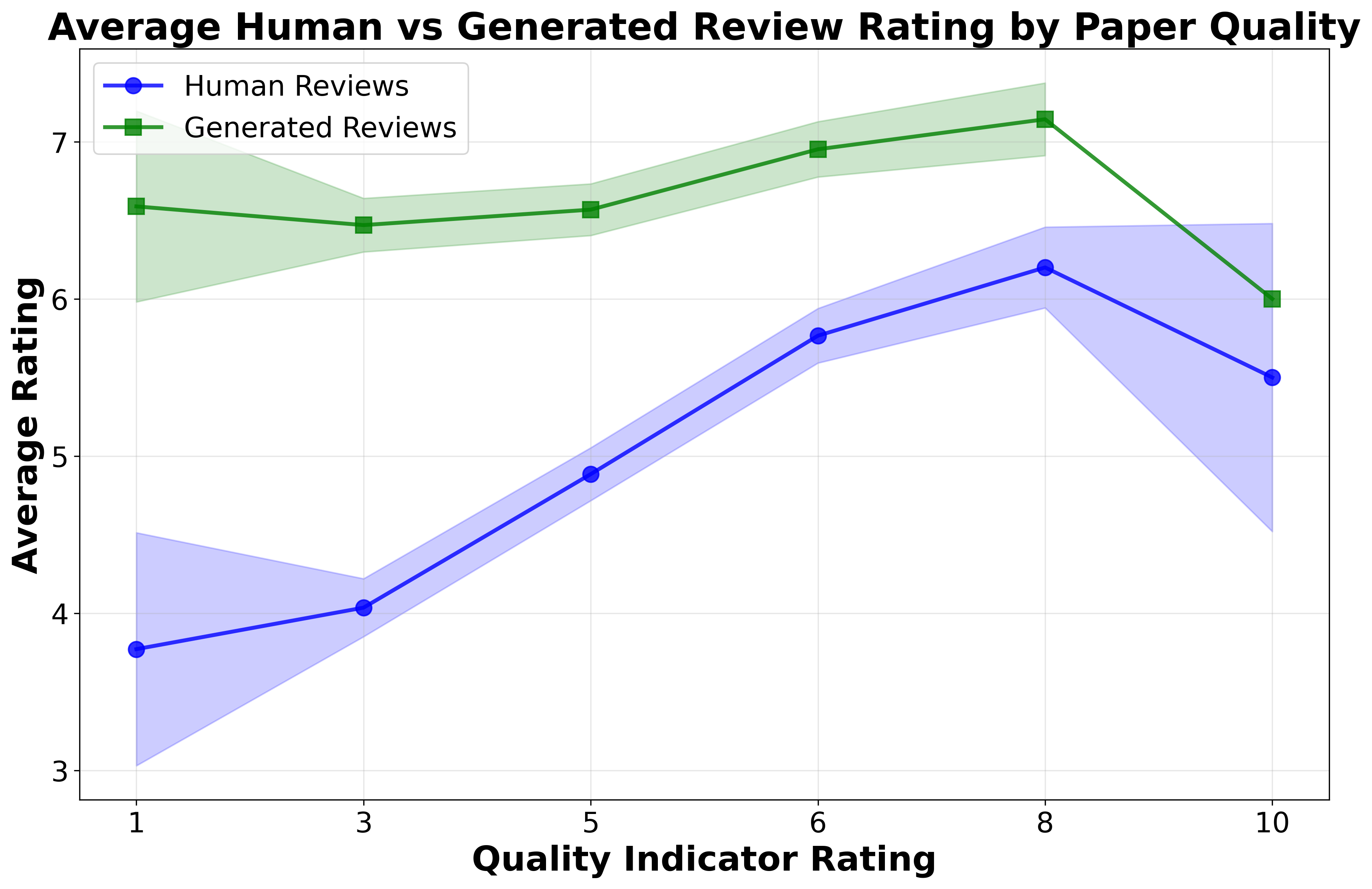
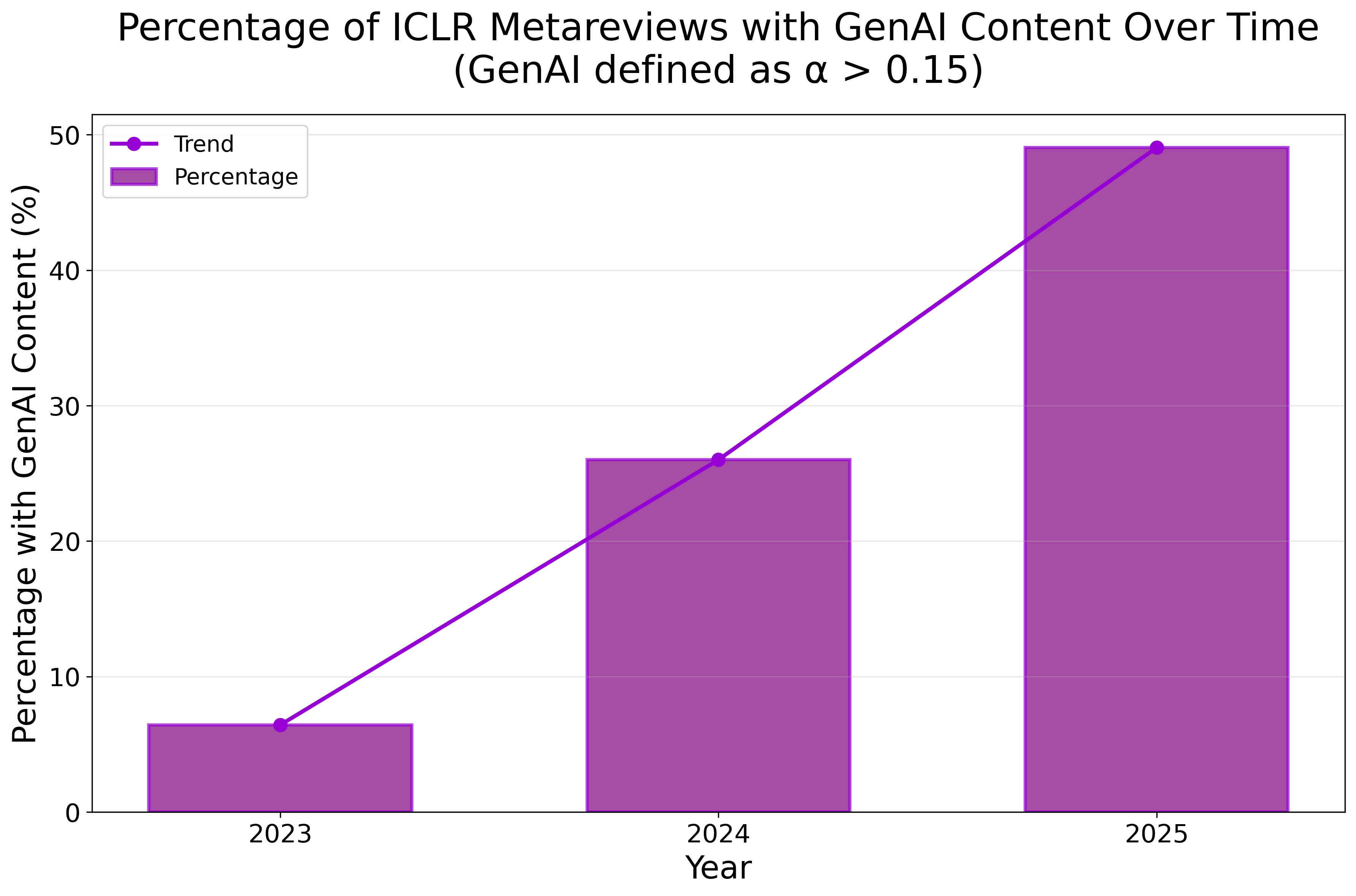
Figure 3: Human vs. synthetic (LLM-only) review ratings across paper quality buckets; synthetic reviewers fail to discriminate quality, yielding flat/slightly positive slopes.
LLM-aided metareviews (area chair recommendations) are strongly associated with higher acceptance odds (β3=+0.214, p<10−3), conditional on reviewer means and variance. However, fully synthetic LLM-generated metareviews are actually stricter—accepting only 19.1%—and disagree with human/LLM-aided decisions, indicating that in situ use is highly mediated and does not constitute blind outsourcing of selection authority.
Multimetric Analysis
Besides overall ratings, auxiliary metrics such as confidence, contribution, soundness, and presentation all reflect consistent patterns. LLM-assistance in reviewing compresses variances across sub-scores but has minimal effect at high paper quality.
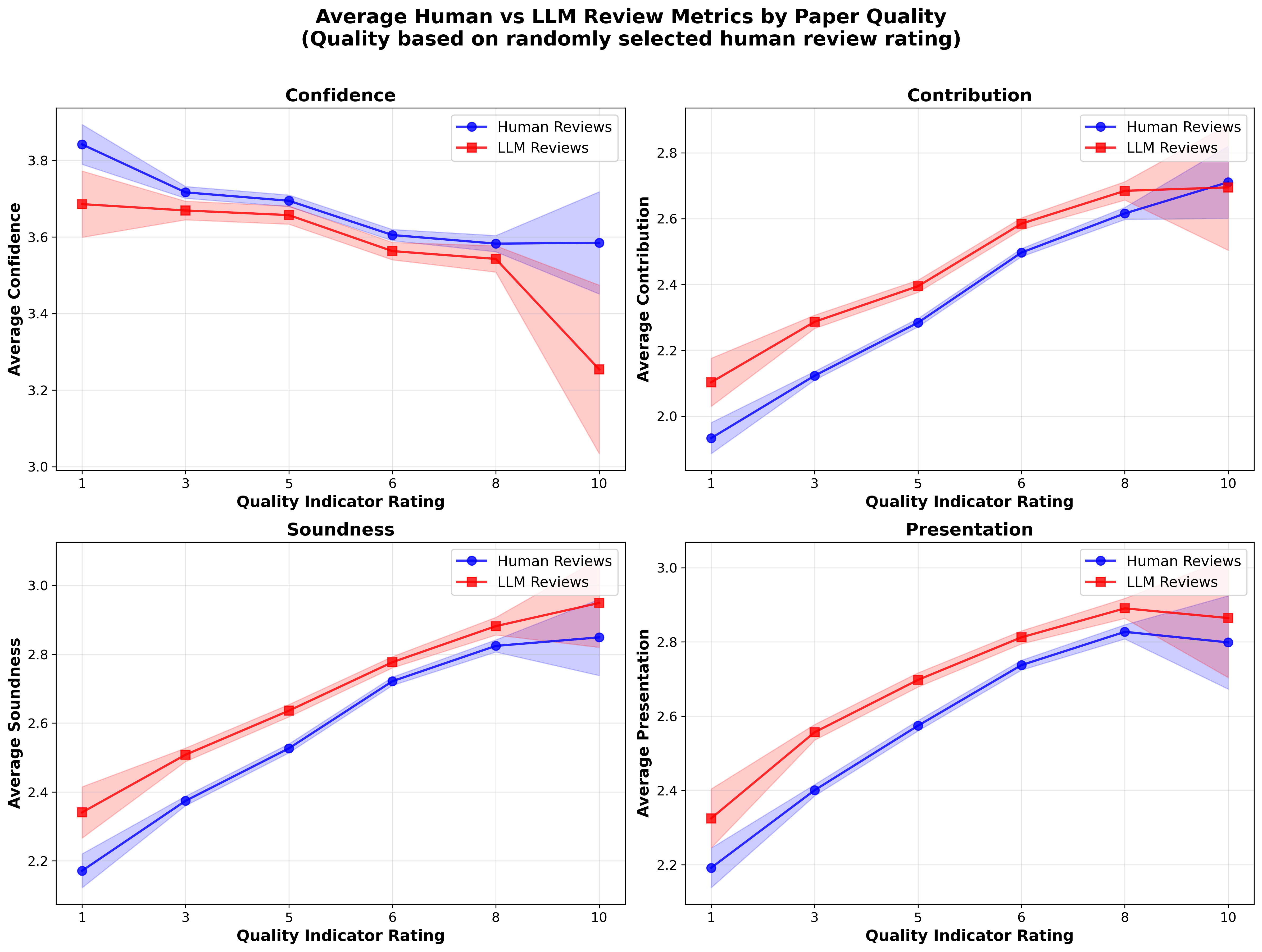
Figure 4: Comparison of confidence, contribution, soundness, and presentation ratings by human and LLM-aided reviewers, stratified by paper quality.
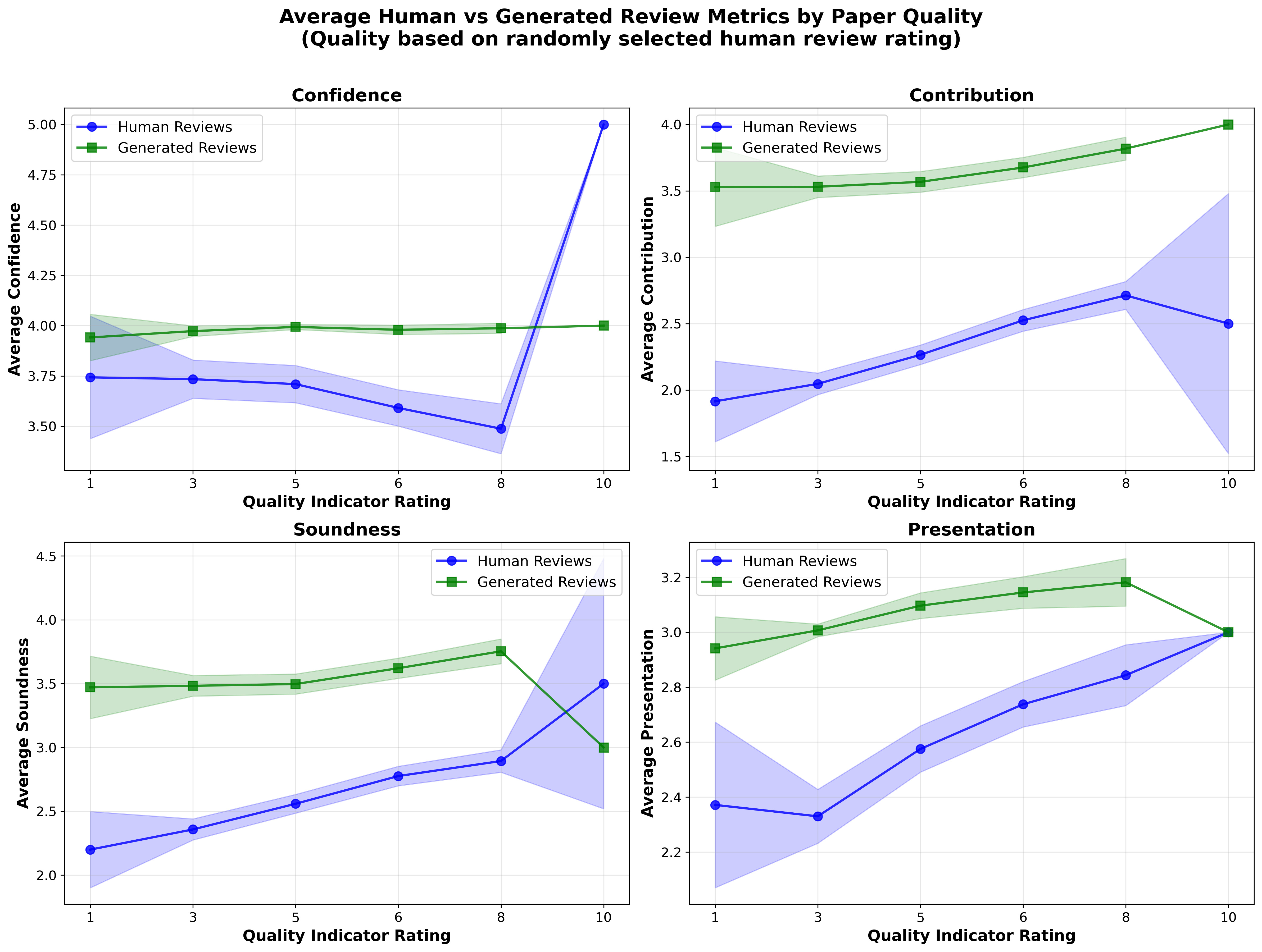
Figure 5: Trends in reviewer-provided submetrics vs. paper quality percentile for human and LLM-aided review sources.
Implications and Policy Considerations
The findings indicate that:
- Apparent “AI–AI” bias is not a true interaction effect but is instead explained by LLM-aided reviewers being broadly lenient to weaker papers, with LLM-aided papers disproportionately represented in those bins.
- Blind adoption of pairing policies (e.g., LLM-to-LLM review matching) may exacerbate acceptance of low-quality, LLM-authored submissions due to this correlated leniency, not genuine mutual recognition.
- Full LLM review automation is currently infeasible for meaningful peer discrimination given strong rating compression.
- Human agency in accepting/rejecting LLM “suggestions” mitigates, but does not eliminate, these compressive/leniency effects.
Practically, policy should resist naive automation or LLM-by-LLM pair assignment, focusing instead on transparency, targeted quality control, and the augmentation—not replacement—of reviewer signal. Moreover, increased LLM uptake among more senior metareviewers correlates with increased acceptance, raising new questions about adoption patterns among decision-makers.
Potential for Future Research
Structured user studies could clarify mechanism: e.g., what prompts do reviewers use, do they instruct LLMs to be harsher, and do metareviewers delegate only summaries or critical judgments? Extending analysis to journal review workflows and outside computer science, where public reviews scores are absent, will test the generality of these findings.
Conclusion
“Do LLMs Favor LLMs? Quantifying Interaction Effects in Peer Review” (2601.20920) provides rigorous evidence that perceived self-preferring AI–AI bias in peer review is almost entirely due to global LLM-derived leniency for lower quality papers, not an emergent AI “in-group” preference. Human reviewers using LLMs still mediate and modulate LLM outputs, and critical final decisions remain strongly subject to human oversight. Theoretical and practical consequences involve the design of review platforms, LLM disclosure and pairing policy, and highlight the necessity for ongoing measurement as both AI technology and human usage patterns evolve.