- The paper introduces Distributional Active Inference (DAIF), a novel framework that unifies active inference and distributional reinforcement learning without explicit transition dynamics.
- It employs probabilistic latent embeddings and quantile regression with Asymmetric Laplace Distribution to improve state abstraction and convergence in control tasks.
- Empirical results demonstrate DAIF's superior sample efficiency and final returns across diverse environments, especially in high-dimensional and latent control scenarios.
Distributional Active Inference: Theory, Algorithmics, and Empirical Results
Abstract and Motivation
The paper "Distributional Active Inference" (2601.20985) introduces a unified framework bridging active inference (AIF) and distributional reinforcement learning (DRL), presenting a rigorous abstraction that enables the practical benefits of AIF without explicit transition dynamics modeling. The main contribution is the formulation and implementation of Distributional Active Inference (DAIF), a policy optimization method that leverages probabilistic embeddings and quantile-based value estimation, thereby increasing data efficiency and robustness in complex control tasks.
Theoretical Foundations
Active inference, inspired by variational Bayesian principles, proposes that action and perception co-evolve to minimize expected free energy (EFE) over trajectories. This unification of action selection and sensory information organization is theorized as a core principle of biological intelligence. Historically, applications to artificial agents have been model-based and computationally demanding, relying on learned world models and multi-step planning.
The paper reformulates AIF using a rigorous measure-theoretic and causal inference perspective, showing that the canonical AIF objective can be simplified via intervention calculus, resulting in decoupled terms and reducing the complexity commonly associated with latent-variable inference in the literature. By analyzing AIF through the lens of push-forward measures, the authors demonstrate that trajectory distributions defined by policies and return functionals are central to both model-based and model-free RL paradigms.
Push-Forward RL and Distributional Bellman Operators
A generalized theoretical framework, termed push-forward RL, is introduced to formalize how return distributions emerge by pushing the Markov process measure induced by a policy through a return functional. This framework establishes clear connections between Bellman backups and trajectory-level equivalence classes in latent embedding spaces. The key theoretical result is a novel contraction lemma for the distributional Bellman operator applied to push-forward measures, showing that convergence rates depend not only on the discount factor γ but also on the Lipschitz moduli of the encoder and decoder.
This mathematical foundation justifies the use of probabilistic latent embeddings and composite kernel operators in RL, providing a mechanism for efficient state abstraction via learned representations. The authors prove that these operations yield tighter contraction properties in Bellman updates, which in turn guarantees improved convergence and sample efficiency compared to classical approaches.
Distributional Active Inference Algorithm (DAIF)
DAIF is instantiated as a distributional actor-critic algorithm operating directly on probabilistic latent space, eschewing the need for explicit transition model learning. It leverages quantile regression with Asymmetric Laplace Distribution (ALD) as a generative model, parameterized via state-action amortized neural networks. The policy and critic jointly optimize a free-energy based objective, with critic targets computed by temporal-difference quantile matching over latent-path distributions.
DAIF integrates model update, policy search, and exploration through the variational objective, with intrinsic randomness in the embedding space facilitating directed exploration. The algorithm is compatible with modern deep RL architectures and maintains computational efficiency despite additional uncertainty quantification.
Empirical Evaluation
The paper provides comprehensive experimental validation across tabular and continuous-control domains, including EvoGym, DeepMind Control Suite (DMC), and DMC Vision environments. Results demonstrate that DAIF matches or significantly outperforms state-of-the-art baselines in sample efficiency and final returns—especially in environments with high-dimensional state or action spaces and in tasks where the dynamics are governed by low-dimensional latent manifolds.
In more challenging environments (complex dynamics, high dimensionality), DAIF's abstraction of return distributions yields substantial practical gains (Figure 1).
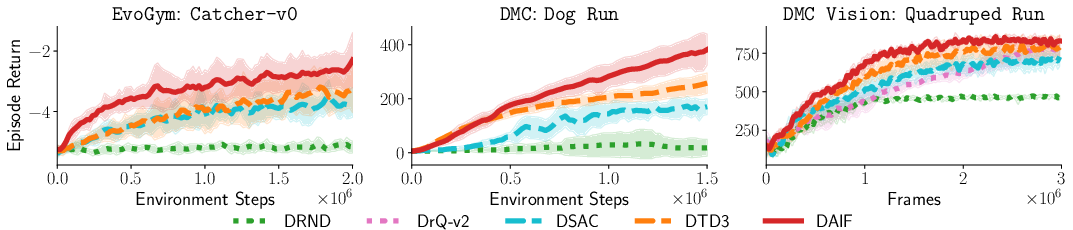
Figure 1: Evaluation curves for three representative environments (EvoGym, DMC, DMC Vision), exhibiting DAIF's superior sample efficiency and final performance on hard tasks.
Further analysis in custom tabular and latent environments distinguishes scenarios where latent trajectory modeling confers advantage, versus those where standard DRL suffices.
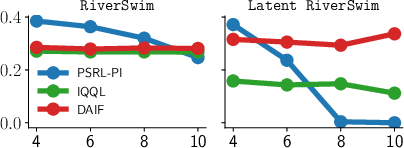
Figure 2: Horizontal axis—distance to the most desired state; vertical axis—visitation frequency. DAIF excels when latent state abstraction is effective, otherwise matches vanilla DRL performance.
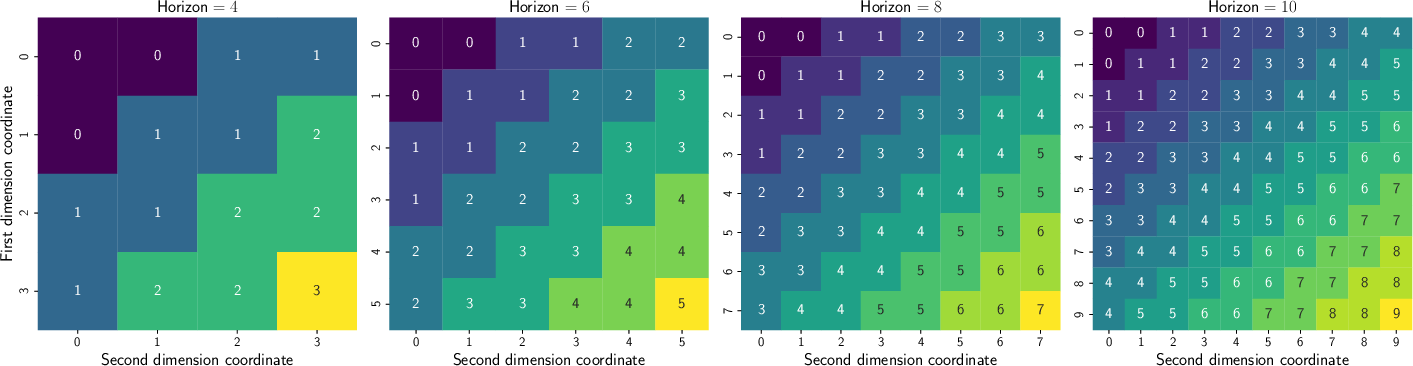
Figure 3: Observation-to-latent state mappings in Latent RiverSwim show the encoder forming equivalence classes, yielding favorable conditions for RL.
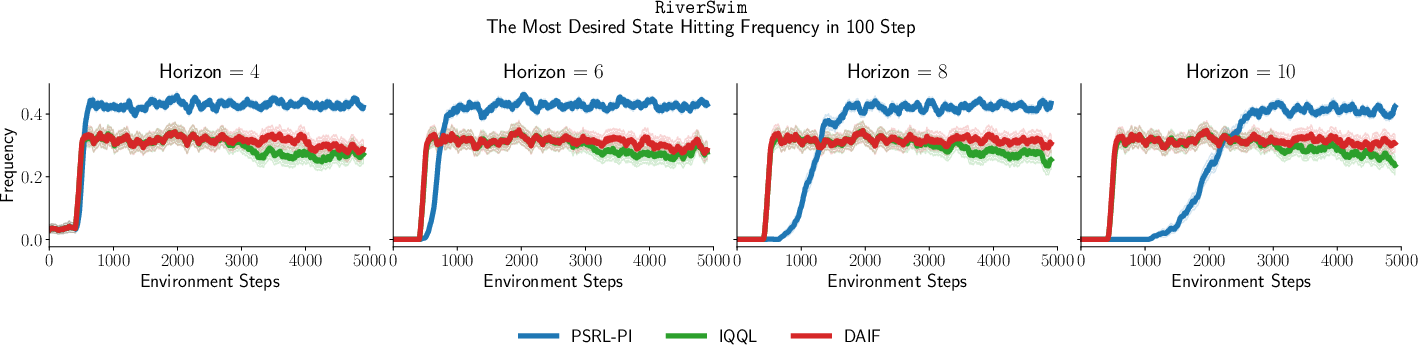
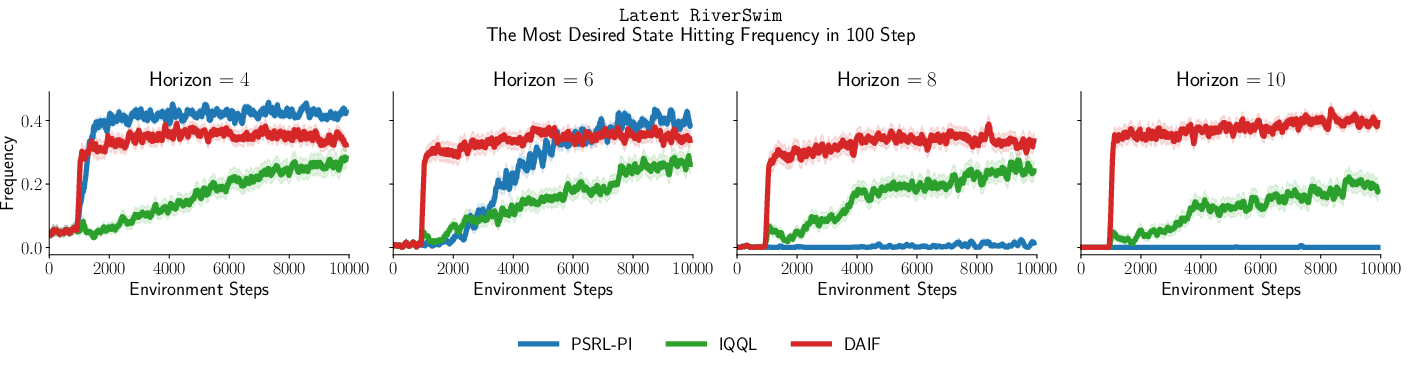
Figure 4: RiverSwim and Latent RiverSwim results: DAIF robustly maintains optimal visitation rates as horizon increases.
Implications and Future Directions
DAIF inherits the theoretical guarantees of distributional RL, but with an analytically improved contraction modulus due to latent embedding compression. This has both practical and theoretical implications:
- Practical Sample Efficiency: DAIF accelerates learning in tasks where low-dimensional latent representations support efficient policy iteration, reducing computational overhead and data requirements.
- Unification of Exploration and Control: The approach demonstrates principled exploration as a byproduct of predictive coding and uncertainty quantification in the embedding space.
- Elimination of Model Learning Bottlenecks: DAIF sidesteps explicit world-model learning, which traditionally limits the scalability of active inference agents.
- Groundwork for Advanced Abstraction Theory: The push-forward RL paradigm provides a foundation for further formal analysis of abstraction and compression in RL, potentially extending to environments with structured partial observability or non-Markovian dynamics.
Open problems remain in rigorously characterizing finite-sample behavior and sample complexity in high-dimensional or non-linear settings. Extension to risk-sensitive RL, meta-learning, and transfer in multi-task domains is natural. Computational improvements are possible via further advances in latent state representation learning and distributional critics.
Conclusion
This paper delivers both a formal conceptual bridge and an algorithmic instantiation connecting active inference with modern distributional RL. By abstracting trajectory measures and integrating variational inference in latent spaces, DAIF attains strong empirical results in challenging, high-dimensional control tasks with reduced reliance on explicit model learning. The framework supports dissociable improvements in convergence and exploration and lays the groundwork for further theoretical and practical developments in scalable, biologically inspired RL.