- The paper introduces Spava, a framework that uses sequence-parallelism-aware approximate attention to speed up long-video inference while preserving accuracy.
- It leverages multi-GPU distributed algorithms with innovative components like frame parallelism and ZigZag virtual hosts to reduce computational load and memory overhead.
- Empirical results show up to 12.72× speedup over baselines with less than 1.5% accuracy loss across challenging video-language benchmarks.
Spava: Sequence-Parallel Approximate Attention for Efficient Long-Video Multimodal Inference
Overview
This work introduces Spava, a sequence-parallelism-aware approximate attention framework targeting the acceleration of long-video inference in Large Multimodal Models (LMMs). The primary objective is to transcend the speed and scalability limitations inherent in existing methods—such as single-GPU sparse attention and token pruning approaches—by leveraging multi-GPU distributed algorithms and system-level optimizations, while maintaining near lossless performance on challenging video-language benchmarks.
Motivation and Problem Setting
The quadratic complexity of transformer attention layers severely bottlenecks inference on ultra-long video sequences for LMMs. Visual encoders process an increased number of frames, significantly amplifying the volume of embeddings, which in turn blow up the sequence length for the LLM backbone. Existing approaches trade accuracy for speed via token pruning or sparse attention on a single GPU. However, these suffer substantial accuracy degradation (e.g., >25% on SlowFast for VNBench) and do not scale computation to accommodate increasing input lengths.
Spava is designed to address this through distributed sequence parallelism, approximate attention, and aggressive system-level engineering, enabling high-throughput, low-latency inference for longer and higher-resolution videos.
System Architecture
Spava's architecture is built around four key components:
- Frame Parallelism: Individual frames of a video are processed independently across multiple GPU hosts, distributing visual encoding workload and maximizing compute density.
- Context Splitting with ZigZag Virtual Hosts: Embeddings are partitioned into anchor, query, and context blocks. Using ZigZag arrangement, virtual hosts are mapped onto physical hosts to balance attention and communication load uniformly across the cluster.
- Approximate Attention Mechanism: Instead of full attention over the entire context, each host selects only the most essential KVs for cross-host computation. Passing blocks are constructed from top-scoring context embeddings, drastically reducing both communication and compute footprint.
- System-Level Fusions and Overlapping: Spava introduces fused forward passes for query and context, overlapping communication with computation, and load-balancing optimizations to minimize runtime bubbles and exploit hardware interconnects.
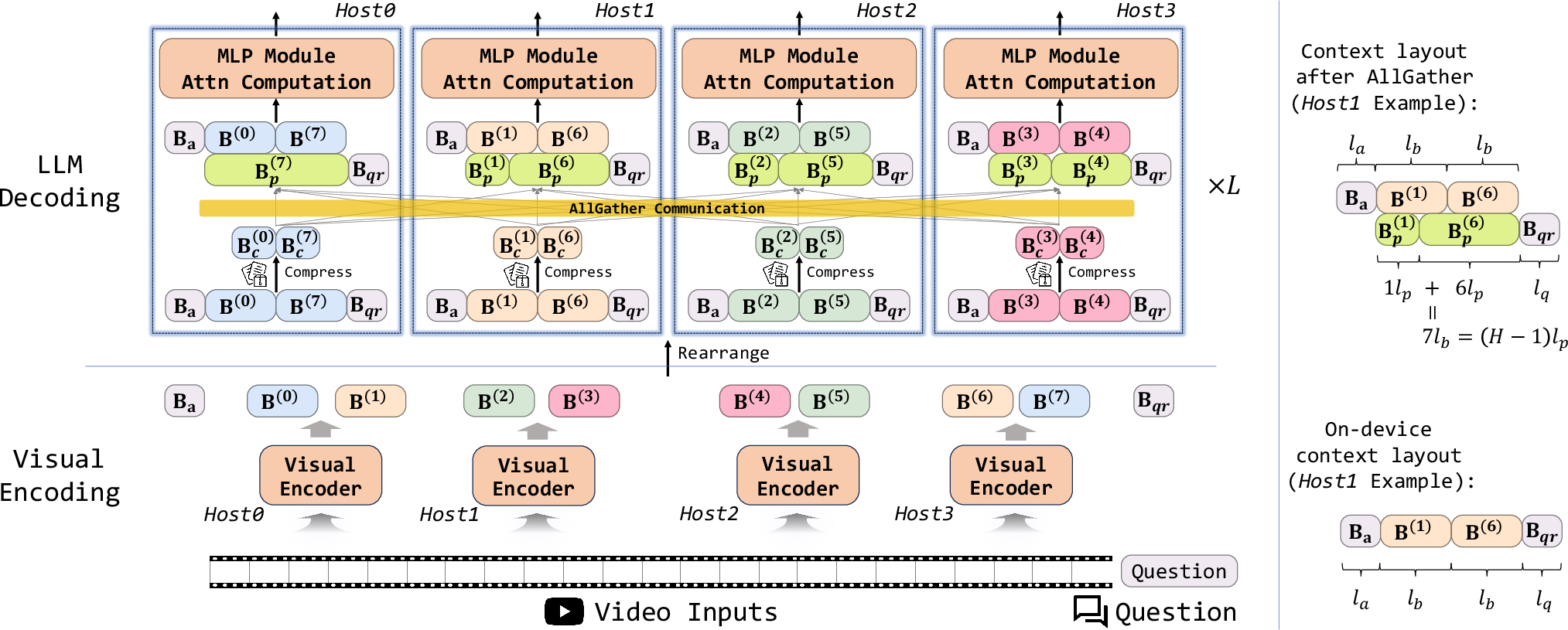
Figure 1: The Spava framework highlighting anchor, query, and distributed context blocks, with compressed communication for approximate attention.
Key Algorithmic Features
- Local KV Compression: Each virtual host computes attention scores between the query and its context block, extracting the top-lp most salient keys/values, which are broadcasted as passing blocks.
- Virtual Host Load Balancing (ZigZag): $2H$ virtual hosts per H physical hosts, assigned in a mirrored pattern to equalize compute and communication per host.
- Passing Block Attention: Cross-host dependencies are preserved by including the passing blocks in each attention computation, preventing loss of long-range context.
- Fused Linear Projections: Jointly processing anchors, context, and queries reduces redundant memory I/O, elevating throughput in the prefill stage.
- Overlapped Communication (AsyncAllGather routines): Communication for KVs and partial attention results is issued asynchronously and overlapped with local computation.

Figure 2: Attention load balancing achieved by ZigZag assignment of passing blocks across virtual hosts.

Figure 3: Illustration of overlapping communication and computation for efficient attention computation on virtual host h.
Empirical Results
On VNBench and LongVideoBench, Spava consistently ranks at or near the top in accuracy, outpacing approximate and sparse attention baselines:
- Speedup: Up to 12.72× over FlashAttn, 1.70× over ZigZagRing, and 1.18× over APB when processing a 64-frame, 1440p video on Qwen2.5VL-3B.
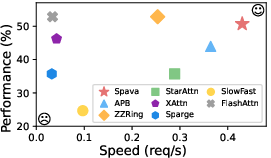
Figure 4: Spava's performance and inference speed using Qwen2.5VL-3B on VNBench with 64-frame, 1440p inputs.
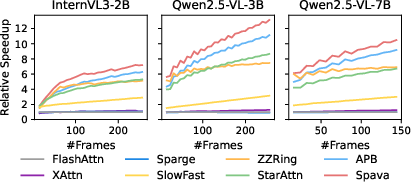
Figure 5: Relative speedup of Spava and baselines versus FlashAttn for increasing frame counts.
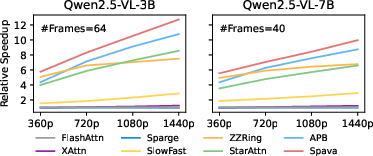
Figure 6: Relative speedup of Spava and baselines versus FlashAttn for different video resolutions.
- Accuracy Preservation: Performance across retrieval, ordering, and counting tasks is maintained within ≤1.5% of FullAttn despite large speed gains, unlike token pruning or sparse attention methods where degradation is severe.
Ablation and Scalability
Spava's efficacy is robust to host count scaling and communication media. Ablations disabling fused forward, frame parallelism, ZigZag load balancing, or communication overlap all result in substantial speed drops. Host scalability experiments demonstrate that Spava's throughput and accuracy remain stable up to 8 hosts. Use of InfiniBand interconnects in place of NVLINK shows only marginal (<1%) inference speed reduction, indicating communication overhead is well amortized by Spava’s design.
Memory and Communication Efficiency
Approximate attention with top-lp selection and overlapping eliminates superfluous cross-host communication, reducing memory bottlenecks compared to full-sequence methods. Hyperparameter sweeps over lp and la find lp=n/128, la=n/64 as optimal for balancing throughput and accuracy.
Selective Attention and Task Adaptivity
Spava’s passing block algorithm ensures that essential regions of the input video—those necessary for the query—are made available across hosts. Case studies on retrieval tasks in VNBench illustrate that the answer region (e.g., the location of a secret word in a frame) exhibits high selection frequency into passing blocks, reflecting effective preservation of crucial evidence for long-context question answering.

Figure 7: Case study from VNBench, showing that spatial regions aligned with the query answer are selected into passing blocks significantly more often.
- FlashAttn: Accurate but dense; does not scale to longer contexts or leverage distributed settings efficiently.
- Sparse Attention (XAttn/SpargeAttn): Limited scalability, degraded accuracy with aggressive sparsification.
- Token Pruning (SlowFast): Severe accuracy drop due to irrecoverable information loss.
- FastV: Prunes hidden states after attention, but incompatible with FlashAttn and has major memory constraints.
- StarAttn/APB: StarAttn accelerates via local anchor/context blocks, but misses long-range dependencies; APB adds passing blocks with trained heads but lacks load balancing and system-level fusion.
- Spava: Training-free, plug-and-play, scales with host count, and outperforms or matches best baselines in both speed and accuracy.
Practical and Theoretical Implications
Spava unlocks high-throughput, accurate long-video inference in practical multimodal applications—surveillance, autonomous driving, multi-turn QA over extended inputs—where time-to-first-token and resource scalability are critical. Theoretically, Spava highlights that carefully orchestrated system-level optimizations together with local approximate attention patterns can preserve model performance while slashing computation, providing a template for future distributed inference frameworks in large-scale multimodal systems.
Prospects for Future Work
Extension to encoder-decoder architectures, integration of trainable sparse attention policies for domain specialization, and deployment in bandwidth-constrained heterogeneous clusters are logical next steps. Combining Spava with retraining protocols for passing block selection could yield further performance gains, and hardware-aligned optimizations (e.g., exploiting low-precision communication) may amplify scalability.
Conclusion
Spava introduces a plug-and-play, training-free framework for distributed, efficient, and performant long-video understanding in large multimodal transformer models. Through sequence parallelism, approximate attention, and system-level concurrency, Spava attains order-of-magnitude acceleration over dense attention baselines, preserving fine-grained accuracy on demanding benchmarks. This approach sets a precedent for scalable inference in next-generation video-language applications, with strong implications for both deployment and further research in multimodal AI systems.