- The paper introduces KAPSO as a knowledge-grounded framework that transforms natural language goals into high-quality software through evaluator-contract driven iterative search.
- It integrates a git-native experimentation engine, dynamic cognitive memory, and hybrid knowledge retrieval to enhance error recovery and convergence.
- Empirical benchmarks on MLE-Bench and ALE-Bench demonstrate KAPSO's superior performance and cost-efficiency compared to leading open-source coding agents.
A Knowledge-grounded Framework for Autonomous Program Synthesis and Optimization: An Expert Review of KAPSO
System Architecture and Design Principles
KAPSO proposes a comprehensive framework for autonomous program synthesis and optimization, targeting the resolved translation of natural-language goals into deployable, high-quality software solutions. Unlike prior code-generation agents that treat synthesis as a terminal objective, KAPSO frames code synthesis as a primitive operator in an iterative, evaluator-driven optimization process, explicitly designed to address long-horizon failures such as state loss, repeated integration errors, and inadequate reuse of engineering knowledge.
The framework architecture is rigorously modular, integrating three tightly coupled subsystems: a git-native experimentation engine for artifact isolation and provenance, a knowledge pipeline hosting heterogeneous domain expertise in a curated MediaWiki and graph/vector indices, and a cognitive memory layer for episodic learning and retrieval. Each experiment is encapsulated as a reproducible git branch, enabling debug- and audit-traceability throughout the optimization trajectory.
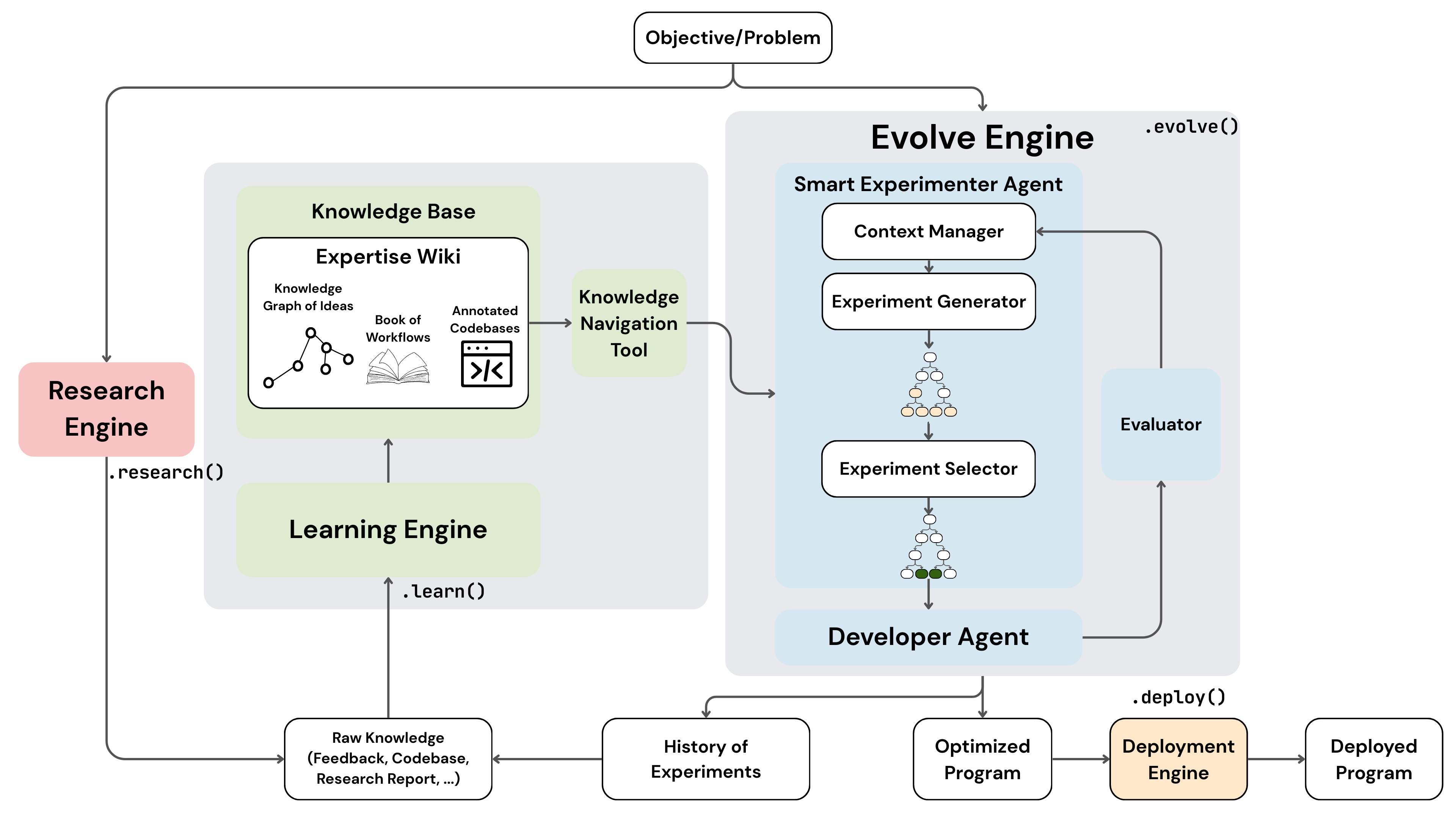
Figure 1: KAPSO framework architecture integrates a git-native experimentation engine, knowledge aggregation/retrieval via MediaWiki and graph/vector backends, and episodic memory for long-horizon optimization.
KAPSO formalizes the synthesis and improvement process as an evaluator-contract-driven search over executable artifacts. Runs are parameterized by goals, budget constraints, and explicit evaluation protocols. The orchestration layer manages experiment history with documented measurement records (success/error flags, quantitative metrics, qualitative diagnostics, and auxiliary artifacts).
Experiments iteratively execute under strict evaluator boundaries, and solution selection is grounded in either scalar utility mappings or explicit preference relations, supporting both automated and LLM-augmented grading. The framework distinguishes stochastic evaluation dynamics, isolating expected utility estimation using Monte Carlo aggregations.
Optimization is grounded in knowledge retrieval and error-recovery augmentation, leveraging a typed knowledge graph ingesting principles, heuristics, implementations, and environment constraints from a curated repository corpus and external sources. Repository selection leverages hybrid embedding and metadata filters, seeding initial artifacts when confidence thresholds are met, or defaulting to scaffolded templates. When failures are detected, error-conditioned augmentation retrieves targeted diagnostics and recovery heuristics.
Cognitive Memory and Episodic Learning
KAPSO differentiates itself with a workflow-aware cognitive memory system. Episodic memory entries—extracted from run traces, diffs, and evaluator feedback—encode generalized lessons and fix patterns, annotated with provenance. On experiment failure or contract violation, the system constructs actionable memory packets and augments the active context for subsequent iterations. Integration of these insights into the search and debugging loop demonstrably reduces repeated error modes and accelerates convergence, yielding effective long-horizon improvement.
Controller policies are formalized to decide between retry, exploration pivot, or completion, with context constructed from the goal, active knowledge packet, latest experiment outcome, and episodic insights. This design supports dynamic transitions between workflows, encouraging exploration when repeated failures occur.
Practical Implementation: Experimentation, Knowledge, and Deployment
Experimentation sessions are implemented as isolated git branches, tagging all artifacts (code changes, evaluator configs, logs, diagnostics, and outputs) for reproducibility and downstream audit. Execution is evaluator-agnostic, supporting both local and containerized runs as required by the problem specification, with the underlying engine capable of concurrent session scheduling and extensible to remote backends for resource-intensive workloads.
Knowledge acquisition processes ingest over 2,000 high-signal data and ML repositories, extracting structured expertise and indexing it for fast graph/vector retrieval. Typed page models (Principle, Implementation, Environment, Heuristic) encode domain patterns, with explicit linkage and provenance, supporting both human curation and retrieval-facing agent interactions.
Deployment exposes a unified Python Software interface, packaging selected solutions with invariant run semantics, lifecycle management, and extensibility for multiple runtime strategies (local, Docker, Modal, BentoML, LangGraph Platform).
Empirical Evaluation: MLE-Bench and ALE-Bench
KAPSO's capabilities were benchmarked on MLE-Bench (Kaggle-style ML competitions) and ALE-Bench (AtCoder heuristic optimization contests), providing rigorous evidence of system efficacy and domain transferability. On MLE-Bench, KAPSO (Leeroo) surpasses major open-source coding agents, particularly in medium and hard challenges—achieving medal rates of 44.74% and 40.00%, contrasting sharply with RD-Agent’s 21.05% and 22.22%, respectively. These results highlight superior long-horizon engineering and specialization in complex ML workflows.
On ALE-Bench, Leeroo obtained a final performance of 1909.4 (rank percentile 6.1%) on aggregate, outpacing the original ALE-Agent both in efficacy (score: 1879.3, rank percentile: 6.8%) and cost-efficiency ($914.8 vs$1003.3). In most AHC competitions, Leeroo demonstrated substantial margins—e.g., ahc016 (2022 vs 1457), ahc026 (2040 vs 1965)—with consistent or improved rank percentile. These outcomes affirm reliable generalization and cost-effective optimization across diverse algorithm engineering regimes.
Theoretical and Practical Implications, Future Directions
KAPSO’s architecture advances autonomous program synthesis by bridging evaluator-driven optimization with scalable knowledge retrieval and continual episodic learning. The explicit provenance and modular orchestration enable robust auditability and adaptation across domains, lowering barriers to industrial deployment and research reproduction. The cognitive memory design addresses systematic error recurrence and brings forward an actionable episodic knowledge layer unseen in legacy agents.
Potential future directions include expanding benchmark coverage for more robust agent comparison, further integration of dynamic, heterogeneous knowledge sources, and improving the retrieval fidelity of error-conditioned heuristics and alternative implementations. Long-term, modular deployment strategies and adaptive controller policies may further catalyze both research and production-grade AI-driven software engineering.
Conclusion
KAPSO introduces a rigorous, evolvable framework for evaluator-grounded autonomous software synthesis and optimization. By unifying artifact provenance, scalable domain knowledge, and episodic learning in a modular stack, it achieves substantial advances in reliability, specialization, and efficiency across synthetic and real-world coding benchmarks, with demonstrable implications for future AI-driven engineering systems (2601.21526).