Deep Models, Shallow Alignment: Uncovering the Granularity Mismatch in Neural Decoding
Abstract: Neural visual decoding is a central problem in brain computer interface research, aiming to reconstruct human visual perception and to elucidate the structure of neural representations. However, existing approaches overlook a fundamental granularity mismatch between human and machine vision, where deep vision models emphasize semantic invariance by suppressing local texture information, whereas neural signals preserve an intricate mixture of low-level visual attributes and high-level semantic content. To address this mismatch, we propose Shallow Alignment, a novel contrastive learning strategy that aligns neural signals with intermediate representations of visual encoders rather than their final outputs, thereby striking a better balance between low-level texture details and high-level semantic features. Extensive experiments across multiple benchmarks demonstrate that Shallow Alignment significantly outperforms standard final-layer alignment, with performance gains ranging from 22% to 58% across diverse vision backbones. Notably, our approach effectively unlocks the scaling law in neural visual decoding, enabling decoding performance to scale predictably with the capacity of pre-trained vision backbones. We further conduct systematic empirical analyses to shed light on the mechanisms underlying the observed performance gains.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Deep Models, Shallow Alignment: A Simple Explanation
Overview
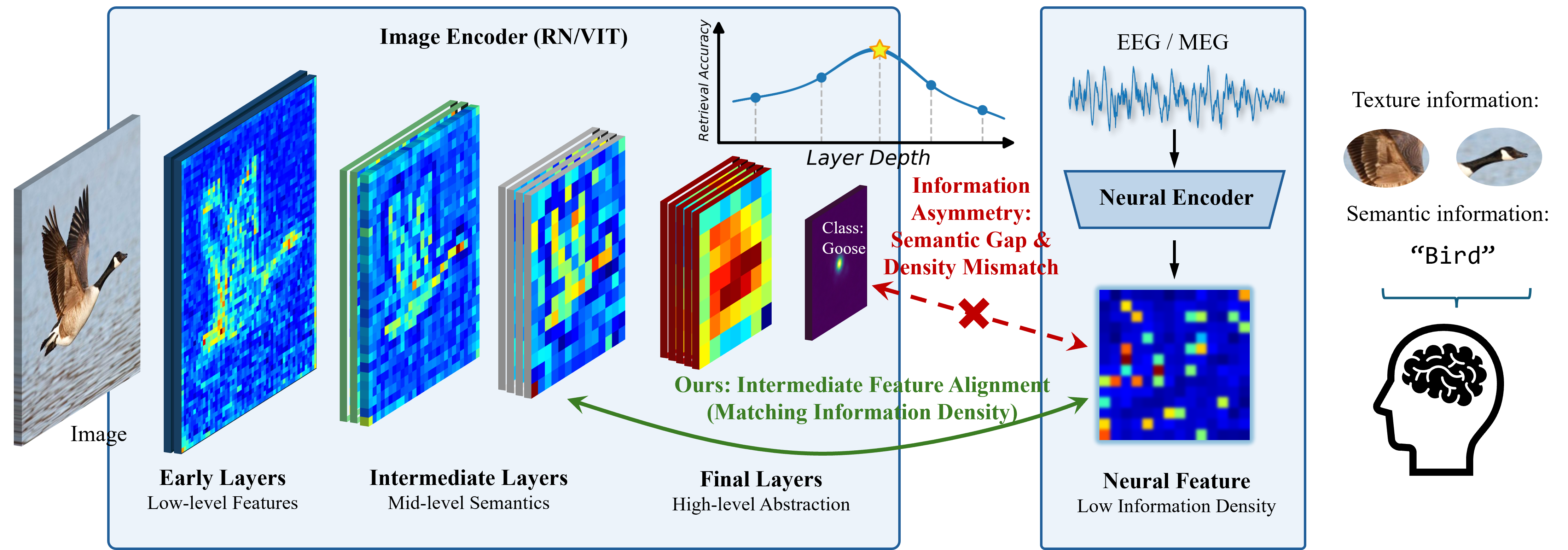
This paper is about “neural visual decoding,” which means trying to figure out what someone is seeing by reading their brain signals. The authors noticed a problem: computer vision models (like CLIP or big Vision Transformers) are great at recognizing what an object is, but they often ignore small details like textures and edges. Meanwhile, brain signals (from EEG or MEG) contain a mix of both small visual details and big-picture meaning. The paper’s main idea, called “Shallow Alignment,” connects brain signals to the middle layers of vision models—where both detail and meaning are present—rather than the very last layer, which is mostly about high-level categories.
Key Objectives
The paper sets out to do three main things:
- Show that matching brain signals to the final layer of vision models is not ideal because it loses important visual details.
- Test whether aligning brain signals to intermediate (middle) layers of vision models gives better results.
- See if this change lets bigger, stronger vision models actually help more (i.e., “unlock” scaling), since previously their final layers were too abstract to match well with brain signals.
Methods in Everyday Language
Here’s how the researchers approached the problem:
- Brain signals: They used EEG and MEG, which are ways of measuring brain activity with sensors on the scalp. EEG/MEG pick up fast, but noisy signals that reflect what the brain is processing when you look at pictures.
- Vision models: They took several powerful pre-trained image models (like ResNet and Vision Transformers) that turn pictures into sets of features at different layers. Early layers capture edges and colors; middle layers mix shapes and parts; final layers summarize what the object is.
- Shallow Alignment: Instead of aligning brain signals to the final “summary” layer, they aligned them to a chosen middle layer, where both fine details and meaning are still present. Think of it like matching a detailed sketch (brain signals) to a mid-progress drawing (not just the final label).
- How they trained the match: They used a “contrastive learning” setup—basically a pairing game. For each image and its corresponding brain recording, the system learns to make the matching pair close together and push non-matching pairs farther apart in a shared space. Imagine grouping correct pairs like friends sitting together and separating unrelated pairs.
- Simple “projectors”: They used simple linear layers (like basic filters) to map both brain features and image features into the same space. Keeping these simple helps show that performance gains come from choosing the right layer in the vision model, not from a complicated decoder.
- Testing: They measured how often the system retrieves the correct image from a large set, using “Top-1” (the very first guess) and “Top-5” (correct image appears in the first five guesses). They tested within the same person (intra-subject) and across different people (inter-subject).
Main Findings and Why They Matter
The results were clear and important:
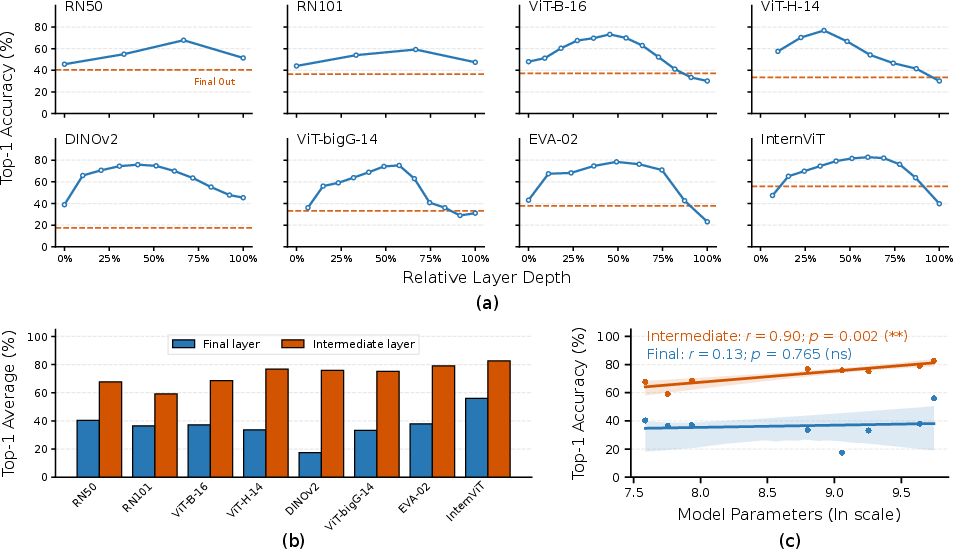
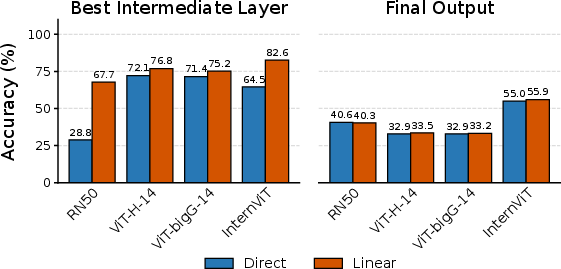
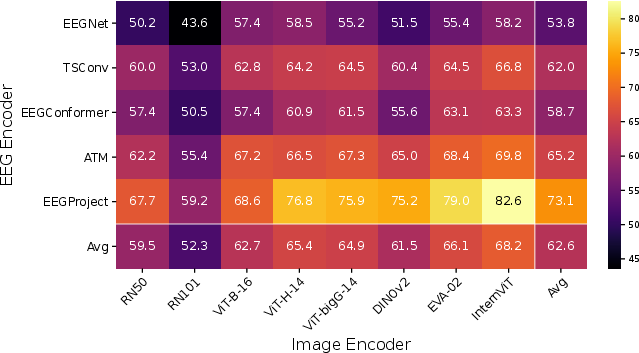
- Big performance boost: Aligning to intermediate layers beat the standard final-layer method by a lot—gains ranged from about 22% to 58% across different vision models. On EEG data, Top-1 accuracy reached around 83% (intra-subject), much higher than previous methods.
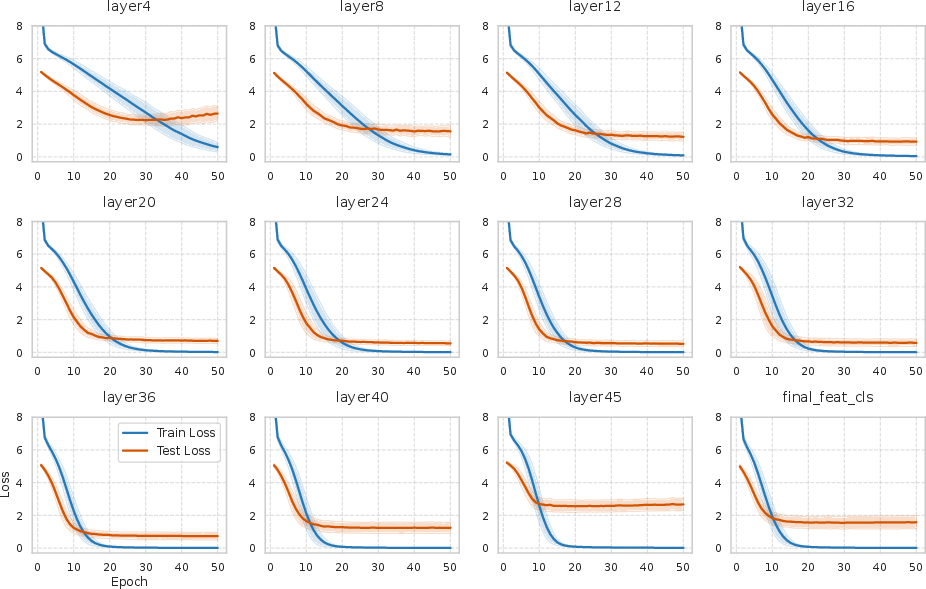
- Best layer is in the middle: Performance across layers followed an “inverted U” shape—starting low, peaking at a middle layer, then dropping at the final layer. That peak is where the mix of detail and meaning best matches the brain’s signals.
- Unlocking scaling: With final-layer alignment, bigger models didn’t help much and sometimes did worse (their final outputs are too abstract). With Shallow Alignment, larger models began to help predictably. In other words, once you pick the right middle layer, bigger models start to improve decoding in a reliable way.
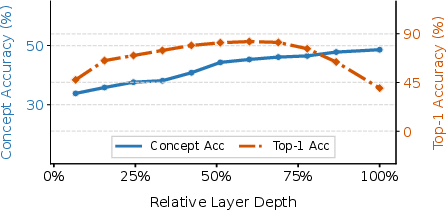
- Semantics vs. details: As models go deeper, “concept accuracy” (getting the category right, like “animal”) goes up, but retrieval accuracy (finding the exact image) peaks in the middle and drops at the end. This shows that the final layer’s strong focus on categories throws away fine details the brain still encodes.
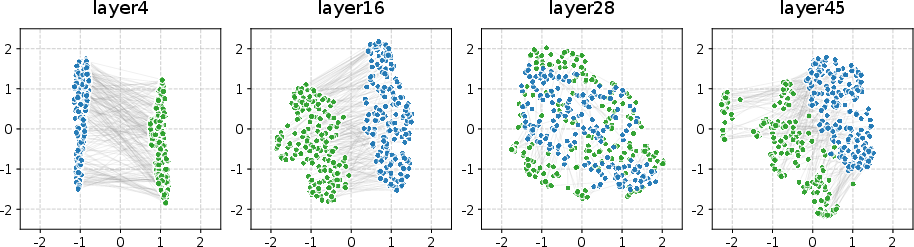
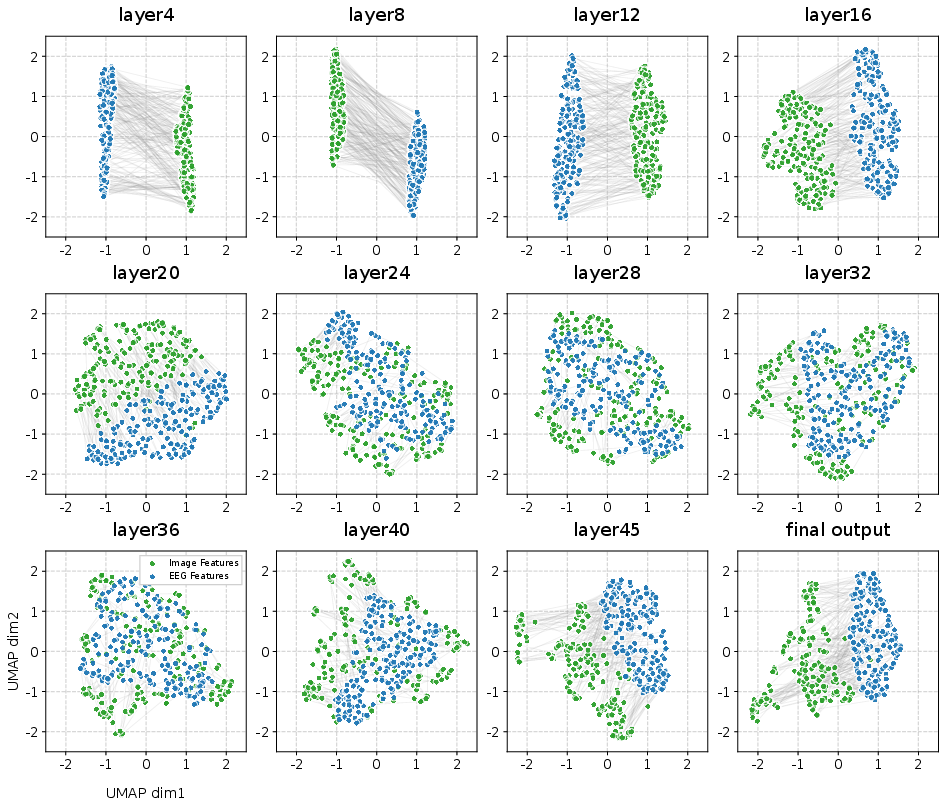
- Visual checks: When they plotted the feature spaces (using a tool called UMAP), the brain and image features overlapped best at the right middle layer, and separated at too-early or too-late layers. Simple linear projectors worked especially well for intermediate layers, but didn’t help much with the final layer (which had “collapsed” to too-abstract features).
- Simple brain encoders win: A lightweight EEG encoder (EEGProject) often worked better than more complex ones. Because EEG/MEG are noisy and data is limited, simpler models avoided overfitting and captured the most useful signals.
Implications and Potential Impact
This work suggests a practical recipe for better brain-computer interfaces that decode what people see:
- Don’t match brain signals to the very last layer of an image model. Choose the right middle layer where both details and semantics are present.
- Doing this lets researchers and engineers benefit from larger, stronger vision models in a predictable way.
- It also supports the idea that human and artificial vision share a layered, hierarchical structure: early detail, mid-level shapes, late semantics.
In the future, the authors want systems that can automatically pick the best layer for each situation and better handle differences between people (since inter-subject performance is still challenging). Overall, Shallow Alignment moves us closer to high-fidelity, non-invasive visual decoding and a deeper understanding of how our brains represent the world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address:
- Adaptive selection of layer depth: The method requires a layer-wise sweep to pick the best intermediate layer ; no learnable or data-driven mechanism (e.g., gating, attention over layers, or bilevel optimization) is proposed to select or combine layers at training/test time.
- Multi-layer fusion vs. single-layer targets: Only a single intermediate layer is used for alignment; the potential benefits of aggregating multiple layers (e.g., hypercolumns, learned mixtures, or skip-attention across layers) to capture multi-scale granularity remain unexplored.
- Temporal–layer correspondences: EEG/MEG have rich temporal dynamics, but the approach aligns a time-collapsed neural embedding to a static image representation; it leaves open how to align time-resolved neural latencies (early vs. late components) with depth-resolved features across layers.
- Frequency-resolved alignment: No analysis of how EEG/MEG frequency bands (e.g., alpha, beta, gamma) differentially align with intermediate vs. deep features; band-specific encoders or multi-band fusion could refine granularity matching.
- Source-space vs. sensor-space alignment: Signals are encoded at the sensor level; whether source localization and cortical parcellation (e.g., V1/V2/IT) could sharpen granularity matching and improve inter-subject generalization is not assessed.
- Inter-subject generalization remains low: Despite large intra-subject gains, inter-subject performance—especially for MEG—is poor; the paper does not propose subject-invariant encoders, hyperalignment/canonical space methods, or domain-adaptive training to reduce between-subject granularity mismatch.
- Trial averaging and real-time viability: The test protocol likely benefits from averaging many repeats (e.g., 80 in THINGS-EEG test); single-trial performance, latency/throughput, and online BCI feasibility are not reported.
- Cross-dataset generalization: Results are limited to THINGS-EEG/MEG; robustness to other datasets, labs, acquisition hardware, electrode montages, and stimulus sets (e.g., scenes, actions, faces, dynamic video) is untested.
- Robustness to neural noise and artifacts: Sensitivity to common EEG/MEG artifacts (EMG, EOG), channel dropout, and SNR variation is not quantified; strategies like artifact-aware training or uncertainty modeling are not evaluated.
- Pooling strategy for intermediate features: The pooling operator Pool(·) over spatial tokens/feature maps is fixed and under-specified; the impact of different pooling schemes (e.g., attention pooling, spatial pyramids, token selection) on granularity preservation is unstudied.
- Dimensionality control and confounds: Intermediate features often have higher dimensionality than final-layer embeddings; the paper does not control for or report matched latent dimensionalities, leaving open whether gains stem from higher feature dimensionality rather than granularity per se.
- Objective choice and negatives: Only a symmetric InfoNCE-style loss with in-batch negatives is used; alternatives (e.g., multi-positive within-concept objectives, supervised contrastive loss, CCA/PLS/DCCA, memory banks, hard-negative mining) may alter granularity alignment but are not compared.
- Projector capacity trade-offs: The study emphasizes linear projectors; it does not systematically explore the capacity/regularization spectrum (e.g., shallow MLPs with strong weight decay, orthogonality constraints, spectral norm bounds) or quantify overfitting risks versus representational sufficiency.
- Quantifying “granularity”: The notion is supported by performance curves, UMAP visuals, and concept accuracy, but no formal, quantitative granularity metric (e.g., intrinsic dimensionality, class-wise dispersion, CKA/CKA-gram alignment, texture/shape bias scores) is introduced to measure and optimize granularity matching.
- Neuroscientific validation: There is no direct mapping between network layers and cortical areas/timings (e.g., RSA/encoding models across time–space), leaving the claimed “shared hierarchical granularity” as an indirect inference from performance rather than grounded neurophysiological evidence.
- Scaling law confounds: “Unlocking scaling laws” is shown on a small set of backbones with different pretraining corpora/objectives; it remains unclear whether the trend holds when controlling for pretraining data, tokenization, patch size, and architecture-specific inductive biases.
- Compute and practicality of layer sweeps: Scanning many layers in very large backbones is computationally heavy; the cost/benefit trade-off and efficient proxies (e.g., learning-to-rank layers, probing heads, or early stopping heuristics) are not discussed.
- Generalization beyond retrieval: The method is evaluated on 200-way image retrieval; whether intermediate-layer alignment improves image reconstruction, generative decoding, captioning, or cross-modal reasoning is not tested.
- Alternative modalities and tasks: Extensions to fMRI/ECoG and to non-object stimuli (scenes, text, auditory, cross-modal tasks) are not studied; it is unclear whether the same granularity principles transfer.
- Augmentations on neural inputs: While vision-side augmentations are discussed in related work, neural-side augmentation (e.g., time-warping, noise injection, mixup across trials) and their effect on granularity alignment are not explored.
- Subject-specific vs. universal optimal depths: The optimal layer depth varies across backbones; it is unknown whether it also varies across individuals, sessions, or attention states, and whether per-subject adaptive depths would help.
- Effect of presentation dynamics: Experiments are in RSVP settings; the impact of stimulus duration, inter-stimulus interval, and masking on the depth at which alignment is optimal is not analyzed.
- Attribute-level contributions: The paper does not dissect which visual attributes (color, orientation, spatial frequency, curvature, part structure) in intermediate features most drive gains; targeted ablations or controlled stimuli could clarify this.
- Hardness and concept effects: Performance is reported at aggregate; how improvements distribute across categories/concepts and whether “hard” categories require deeper/shallower features is not analyzed.
- Baseline parity and hyperparameter fairness: It is unclear whether baselines were tuned to the same extent (e.g., projector dimensions, temperature τ, batch size, optimizer settings), which could confound the size of reported gains.
- Interpretability of learned projections: The linear projector is treated as a black box; analyses of its weight patterns (e.g., which channels/times/frequencies are emphasized) to interpret neural–feature correspondences are absent.
- Layer sampling resolution in ViTs: For ultra-deep Transformers, only ~10 layers are probed; finer-grained sampling might reveal different optima, raising questions about the exact location and stability of the “best” depth.
- Textual alignment baselines: Given CLIP’s dual encoders, aligning EEG/MEG to text embeddings or jointly to image+text could probe whether semantic abstraction in language spaces changes the granularity sweet spot; this is untested.
- Calibration and confidence: No calibration metrics (e.g., conformity scores, uncertainty estimates) are provided for retrieval decisions, leaving reliability under distribution shift unknown.
- Reproducibility and open resources: Detailed preprocessing choices, exact Pool(·) definitions, and code for layer sweeping/selection are deferred to the appendix or unspecified; open benchmarks and standardized protocols for this setting would aid replication.
Practical Applications
Immediate Applications
The following applications can be deployed with current tools and datasets, leveraging the Shallow Alignment strategy (aligning EEG/MEG with intermediate layers of pre-trained vision models) and the empirical gains reported (e.g., up to 82.6% Top-1 on intra-subject THINGS-EEG and 48.0% on intra-subject THINGS-MEG for 200-way retrieval).
- Healthcare (Clinical neuro-assessment): Rapid functional profiling of visual pathways
- Use case: Create a non-invasive test that characterizes a patient’s visual processing by measuring decoding performance across intermediate layers (layer-depth profile) to assess low-, mid-, and high-level visual function.
- Workflow/product: Clinic-ready RSVP task (2–5 minutes), EEG capture, layer-wise decoding report highlighting peak alignment depth and deviations from normative curves; integration with MNE/EEGLAB for reporting.
- Assumptions/dependencies: High-density EEG/MEG or clinical-grade EEG; validated normative baselines; controlled stimulus presentation; regulatory review for diagnostic use; inter-subject variability remains a challenge (inter-subject results are modest).
- Academia (Cognitive and systems neuroscience): More sensitive neural-encoding benchmarks
- Use case: Replace final-layer alignment with intermediate-layer alignment in neural decoding studies to improve retrieval accuracy and sensitivity to mid-level features (contours/texture).
- Workflow/product: Open-source PyTorch module for Shallow Alignment that exposes intermediate hooks for popular backbones (OpenCLIP, DINOv2, ViTs); layer sweep utilities; reproducible leaderboards.
- Assumptions/dependencies: Access to paired neural-stimulus datasets; harmonized preprocessing; compute for large backbones; careful control of RSVP paradigms.
- Software/AI (Model selection and evaluation): Practical layer-selection for multimodal alignment
- Use case: Improve cross-modal retrieval and embedding alignment tasks (e.g., EEG-to-image search in lab settings) by selecting a backbone’s optimal intermediate layer rather than its final embedding.
- Workflow/product: “Layer tuner” utility that performs fast layer sweeps with contrastive loss; exports the best-performing layer index as part of model cards and deployment configs.
- Assumptions/dependencies: Access to pretrained vision encoders; modest neural data for calibration; batch sizes sufficient for stable contrastive training.
- Human–computer interaction (Neuroadaptive experiments): Real-time stimulus selection in lab settings
- Use case: In experimental settings, adapt images shown to participants in real time by monitoring EEG-to-image similarity in an intermediate-layer embedding space (e.g., select stimuli that maximize separability or engagement).
- Workflow/product: Online EEG pipeline that projects signals via a lightweight encoder and linear projector; cosine-similarity feedback loop for adaptive stimulus scheduling.
- Assumptions/dependencies: Low-latency EEG processing; synchronized presentation hardware/software; performance validated in controlled labs; translation to uncontrolled environments is non-trivial.
- Media and UX research (Neuro-evaluation of visual content): Content diagnostics across granularity
- Use case: Evaluate how different design variants affect mid-level versus high-level processing by comparing layer-depth decoding profiles across stimuli.
- Workflow/product: A/B testing toolkit that logs per-layer decoding performance for candidate designs (icons, packaging, UI elements); reports which visual features (texture/contour vs semantics) drive neural alignment.
- Assumptions/dependencies: Participant recruitment and consent; institutional ethics approvals; repeatable stimulus protocols; privacy-preserving pipelines.
- Tooling (Open-source): Lightweight EEG encoders paired with large vision backbones
- Use case: Provide a plug-and-play library with the paper’s recommended simple EEG encoder and linear projector, enabling robust performance under low SNR and small datasets.
- Workflow/product: PyTorch package with EEGProject, linear semantic projector, contrastive training loops, and pretrained configs for common backbones (ResNet-50/101, ViT-B/H, DINOv2).
- Assumptions/dependencies: Standard EEG preprocessing pipelines; access to pretrained vision backbones; documented training recipes.
Long-Term Applications
These applications require further advances (e.g., inter-subject generalization, real-world robustness, regulatory approvals, larger datasets, or adaptive layer selection) before broad deployment.
- Healthcare (Assistive communication for locked-in patients): Semantically constrained visual decoding
- Use case: Combine Shallow Alignment with text/image generative models to enable non-invasive, brain-driven selection or reconstruction of intended objects or scenes (e.g., communication boards, iconographic vocabularies).
- Potential product: EEG-driven communication aid that decodes object categories or retrieves images from a constrained vocabulary to support selection-based communication.
- Assumptions/dependencies: Substantial improvement in inter-subject transfer, continuous calibration, robust real-time pipelines, safety/effectiveness trials, and regulatory approvals.
- Precision diagnostics (Neuro-ophthalmology, neuropsychiatry): Layer-profile biomarkers
- Use case: Use layer-depth decoding curves as digital biomarkers for disorders affecting visual processing (e.g., agnosias, visual neglect, developmental conditions with atypical mid-level processing).
- Potential workflow: Standardized test batteries linking deficits to specific hierarchical stages; longitudinal tracking of recovery or treatment response.
- Assumptions/dependencies: Large normative cohorts, multi-site validation, robust cross-session reproducibility, clear clinical interpretability, and ethics governance.
- AR/VR and adaptive interfaces: Brain-responsive content personalization
- Use case: Decode user’s visual engagement or perceived object-level content to dynamically adjust AR/VR scenes (e.g., emphasizing mid-level features for clarity, reducing visual clutter, aiding training/education).
- Potential product: On-device or edge-assisted EEG module selecting the optimal vision-layer alignment to modulate rendering parameters or recommend scene elements.
- Assumptions/dependencies: Wearable, comfortable EEG hardware; reliable online inference; privacy by design; safety in dynamic content adaptation; validation in ecologically valid tasks.
- Foundation-model design (AI/ML): Neuroscience-aligned training objectives
- Use case: Train or fine-tune vision backbones to preserve mid-level structure beneficial for neural alignment (countering excessive semantic collapse), improving robustness and interpretability in industrial applications (e.g., medical imaging triage, quality control).
- Potential tools: Regularizers or multi-task heads that optimize for both classification and mid-level feature preservation; model cards that include “neuro-alignment profiles.”
- Assumptions/dependencies: Access to neural datasets for co-validation; compute for large-scale training; industry acceptance of neuroscientifically motivated objectives.
- Cross-modal generalization (Beyond vision): Extending Shallow Alignment to audio/language
- Use case: Align neural signals with intermediate representations in speech or LLMs for decoding perceived words/phonemes or concepts (e.g., non-invasive speech prostheses).
- Potential product: EEG/MEG-to-speech concept retrieval for constrained vocabularies; neuro-driven caption selection in AAC devices.
- Assumptions/dependencies: High-quality neural-audio/text paired datasets; model adaptations for temporal alignment; improved SNR and artifact mitigation.
- Subject-agnostic neural decoders: Robust inter-subject generalization
- Use case: Develop adaptive layer-selection and domain adaptation methods (e.g., learnable gating for layer choice; meta-learning; style normalization) to reduce between-subject “granularity mismatch,” enabling plug-and-play decoders.
- Potential workflow: Calibration-light onboarding with a few minutes of data; automatic layer and projector tuning for new users.
- Assumptions/dependencies: New algorithms for subject-invariant representation learning; large, diverse training cohorts; continuous monitoring for drift.
- Privacy and governance (Policy and standards): Neurodata protection and disclosure norms
- Use case: Establish standards for secure storage, consent, processing transparency, and model-card disclosures (e.g., which intermediate layers are used, data retention policies).
- Potential outcome: Sector-specific guidance for healthcare, research, and consumer neurotech; certification schemes for neuro-aligned AI systems.
- Assumptions/dependencies: Regulatory alignment across jurisdictions; stakeholder engagement (patients, IRBs, industry); privacy-preserving learning (federated/differential privacy).
- Real-world neuro-sensing ecosystems: Edge deployment and hardware co-design
- Use case: Integrate optimized intermediate-layer alignment into edge-capable devices (wearable EEG headsets) for continuous or on-demand decoding in daily life contexts (navigation aids, training feedback).
- Potential product: Low-power embedded modules with preselected intermediate layers, fast linear projection, and event-driven decoding.
- Assumptions/dependencies: Advances in wearable EEG comfort and signal quality; battery and compute constraints; robustness to motion artifacts; stringent privacy safeguards.
Glossary
- AdamW optimizer: A variant of Adam that decouples weight decay from the gradient update to improve generalization. "using the AdamW optimizer,"
- attention pooling: An attention-based aggregation method that pools spatial features into a global representation. "For ResNet models, the final feature is obtained by attention pooling of the last convolutional layer."
- bidirectional formulation: A training setup that enforces consistency in both neural-to-visual and visual-to-neural directions. "This bidirectional formulation enforces consistent alignment across modalities and is used as the primary training objective"
- brain–computer interface (BCI): A field focused on direct communication or interaction between brain activity and computational systems. "Neural visual decoding is a central problem in brainâcomputer interface research,"
- CLS token embedding: The special classification token’s representation in a Vision Transformer that summarizes the image at the final layer. "For Transformer-based models, the final feature corresponds to the CLS token embedding from the last layer."
- Cognitive Prior Augmentation: A data augmentation strategy that simulates perceptual variability using cognitively inspired transforms. "NeuroBridge leverages Cognitive Prior Augmentation to simulate perceptual variability via image transformations, including Gaussian blur, Gaussian noise, mosaic effects, and low-resolution downsampling."
- contrastive learning: A representation learning paradigm that brings matched pairs closer and pushes mismatched pairs apart in embedding space. "aligning neural signals to visual representations via contrastive learning on the final-layer embeddings of these models"
- contrastive loss: The objective function used in contrastive learning to optimize pairwise similarity and dissimilarity. "The contrastive loss is defined as"
- cosine similarity: A metric that measures the cosine of the angle between two vectors to quantify their similarity. "where denotes cosine similarity,"
- Depth--Capacity Paradox: The phenomenon where deeper, more abstract layers hinder alignment despite larger model capacity. "We resolve a Depth--Capacity Paradox, where increased semantic abstraction in deeper layers hinders effective alignment."
- DINOv2: A self-supervised vision backbone producing robust, general-purpose visual features. "For example, DINOv2 achieves a Top-1 accuracy of only 17.5\% when aligned at its final layer,"
- EEG (electroencephalography): A non-invasive recording of electrical brain activity via scalp electrodes. "particularly studies based on electroencephalography (EEG) and magnetoencephalography (MEG),"
- EEG encoder: A neural network that maps raw EEG signals to a latent embedding space for alignment. "utilizes a tailored EEG encoder named Adaptive Thinking Mapper (ATM) to align EEG signals with CLIP embeddings."
- EEGNet: A compact convolutional neural network architecture designed for EEG signal classification and analysis. "despite its high capacity, the widely used EEGNet averages only 53.8\% accuracy,"
- EEGProject: A lightweight EEG encoding architecture used to produce neural embeddings for alignment. "We utilize EEGProject as the neural encoder"
- EVA-02: A large-scale visual representation model used as a backbone for feature extraction. "including DINOv2, EVA-02, and InternViT."
- granularity mismatch: A misalignment between the level of abstraction in neural signals and the visual model’s representation. "However, existing approaches overlook a fundamental granularity mismatch between human and machine vision,"
- Granularity Balance: The property of intermediate layers to retain structural detail while maintaining semantic discriminability. "intermediate layers maintain a Granularity Balance: they possess sufficient semantic density to distinguish concepts while retaining the high intrinsic dimensionality and structural redundancy."
- inductive bias: The assumptions embedded in a model that guide learning toward certain types of representations. "The inductive bias of contemporary vision models aims to maximize semantic invariance,"
- InternViT: A large-scale Vision Transformer backbone used for high-capacity visual feature extraction. "InternViT peaks at around 60\%."
- intrinsic dimensionality: The effective number of degrees of freedom underlying a data manifold or representation. "reduces its intrinsic dimensionality"
- leave-one-subject-out (LOSO): An evaluation protocol where one subject is held out for testing and the rest are used for training. "Inter-subject: leave-one-subject-out (LOSO)"
- linear projection: A learnable linear mapping that projects features into a shared latent space. "introducing a learnable linear projector yields only marginal performance improvements."
- Linear Semantic Projector: The module that applies linear mappings to neural and visual features to align them semantically. "Linear Semantic Projector"
- magnetoencephalography (MEG): A non-invasive technique measuring magnetic fields produced by neural activity. "contains magnetoencephalography (MEG) recordings from 4 participants"
- manifold structure: The geometric arrangement of embeddings in a lower-dimensional space reflecting data relationships. "induce a manifold structure whose granularity is more consistent with neural signals,"
- Neural Collapse: A training-phase phenomenon where within-class variability vanishes and class means become maximally separated. "As networks deepen, they undergo Neural Collapse"
- Neural-MCRL: A multimodal contrastive learning framework for EEG-based visual decoding. "Baseline approaches such as NICE, ATM, and Neural-MCRL"
- OpenCLIP: An open-source implementation and set of weights for contrastive language-image pretraining (CLIP). "all using pretrained weights provided by OpenCLIP"
- Rapid Serial Visual Presentation (RSVP): A paradigm where images are shown rapidly in sequence to elicit time-resolved neural responses. "collected under a Rapid Serial Visual Presentation (RSVP) paradigm"
- ResNet-101: A deep residual network architecture used as a vision backbone. "Specifically, we include ResNet-50 and ResNet-101~\cite{he2016deep},"
- ResNet-50: A residual network with 50 layers used for visual feature extraction. "Specifically, we include ResNet-50 and ResNet-101~\cite{he2016deep},"
- scaling law: A predictable relationship where performance improves with model capacity or data scale. "Notably, our approach effectively unlocks the scaling law in neural visual decoding,"
- semantic collapse: The loss of fine-grained structural details due to excessive abstraction in final-layer features. "these representations have undergone severe semantic collapse"
- semantic invariance: The property of representations that maintain object identity while ignoring low-level variations. "deep vision models emphasize semantic invariance by suppressing local texture information,"
- signal-to-noise ratio (SNR): A measure comparing the level of the desired signal to background noise. "leading to substantially reduced signal-to-noise ratios"
- symmetric contrastive objective: A contrastive loss computed in both image-to-EEG and EEG-to-image directions. "We employ a symmetric contrastive objective"
- temperature hyperparameter: A scalar that controls the softness of the softmax in contrastive objectives. " is a temperature hyperparameter,"
- THINGS-EEG: A large-scale EEG dataset of object concepts and images used for decoding benchmarks. "Overall accuracy (\%) of 200-way zero-shot retrieval on THINGS-EEG"
- THINGS-MEG: A large-scale MEG dataset of object concepts and images used for decoding benchmarks. "Overall accuracy (\%) of 200-way zero-shot retrieval on THINGS-MEG"
- UMAP: A nonlinear dimensionality reduction technique for visualizing high-dimensional embeddings. "We employ UMAP~\cite{mcinnes2018umap} to visualize the geometric distributions of the projected neural embeddings and visual embeddings on the test set."
- Uncertainty-Aware Blur Prior (UBP): A method that applies blur based on sample uncertainty to better align human and machine vision. "proposing an Uncertainty-Aware Blur Prior (UBP) that improves alignment by dynamically adjusting the blur radius based on sample uncertainty."
- Vision backbone: The core visual encoder architecture used to extract features at various depths. "diverse vision backbones."
- Vision Transformer (ViT): A transformer-based architecture for image recognition using patch tokens and a CLS token. "Vision Transformer models of increasing capacity, including ViT-B/16~\cite{dosovitskiy2021image}, ViT-H/14~\cite{zhai2022scaling}, and ViT-bigG/14~\cite{cherti2023reproducible},"
- zero-shot retrieval: Matching queries to targets without training on the exact target classes or images. "Overall accuracy (\%) of 200-way zero-shot retrieval on THINGS-EEG"
Collections
Sign up for free to add this paper to one or more collections.