- The paper introduces a regularization-free sequential growth method that uses information geometry to optimally activate graph edges.
- It employs fully-corrective coordinate descent to build sparse Gaussian graphical models while minimizing false detections.
- Numerical experiments on synthetic and real data validate its competitive performance against methods like Glasso.
The paper "Information-geometry-driven graph sequential growth" (2601.22106) investigates novel regularization-free approaches for Gaussian graphical inference by adopting a sequential growth strategy driven by information geometry. The method builds initially edgeless graphs via a coordinate descent process, employing fully-corrective descents that align with information-optimal growth patterns. This paper proposes efficient numerical strategies to approximate such descents, demonstrating the capability of the procedures to extract sparse graphical models while minimizing false detections.
Methodology
The paper introduces an innovative approach to Gaussian graphical model estimation, utilizing coordinate descent in information geometry. The essential idea is to develop graphs sequentially, activating edges systematically based on their information-geometric relevance. The authors provide a rigorous characterization of fully-corrective descents, which correspond to optimal information growth criteria, and propose computational techniques to approximate these optimal descents without the need for regularization parameters.
Using classical matrix operations, the authors investigate the Gaussian graphical loss and derive relations crucial for the coordinate descent process. Importantly, the paper distinguishes between diagonal and off-diagonal updates during the graph growth process, introducing precise terminologies for edge activation and the formation of graphical models.
Numerical Experiments
The efficacy of these new graph-recovery strategies is validated through extensive numerical experiments. The authors explore synthetic data scenarios and a real-world case involving gene-network inference using the Riboflavin dataset.
The experiments showcase:
- Precision and reliability: Graphs generated via the proposed growth strategy exhibit substantial precision in recovering true edge patterns, particularly in sparse regimes.
- Comparison with existing methods: Sequential growth approaches are compared with methods like Glasso, demonstrating competitive performance, especially in extracting sparse models without introducing excessive false positives.
- Subsampling and stability selection: Subsampling techniques are employed to explore edge activation ranks, contributing to informed graph structure detection.
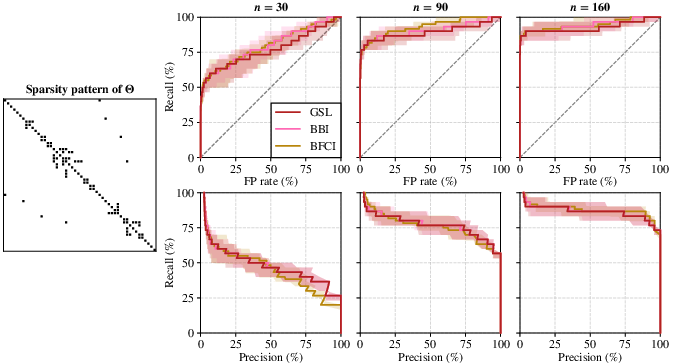
Figure 1: ROC curves and precision-recall curves for sequential growths with GSL, BBI, and BFCI selection rules, indicating their median accuracies and interdecile ranges.
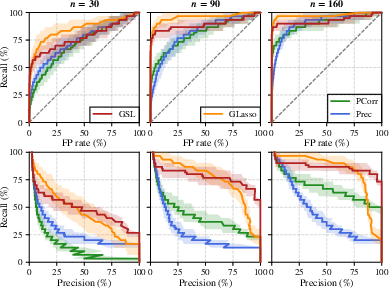
Figure 2: ROC curves and precision-recall curves comparing GSL, Glasso, Prec, and Pcorr methods, affirming GSL's superior early-stage graph-recovery performance.
Theoretical Implications
The paper contributes methodologically by bridging classical probability, statistics, and convex optimization within the graphical inference paradigm. This integration enhances the theoretical foundation of sequential growth strategies, underscoring their diagnostic capabilities in graphical model estimation.
While not delving deeply into parameter learning applications, the authors hint at potential for further research into constrained environments and total positivity settings, which could expand the applicability of these techniques.
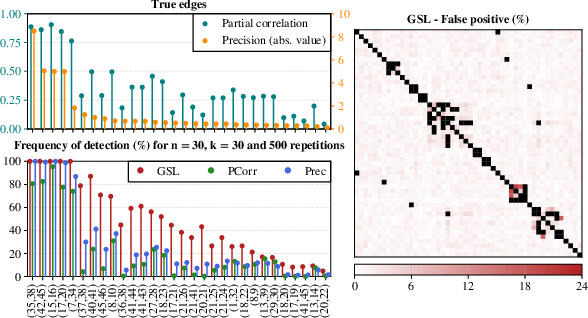
Figure 3: True partial correlations and precisions visualized, showcasing detection frequency and false-positive distribution under GSL growth.
Conclusion
This research paper puts forward promising information-geometry-driven methods for structured graph formation in Gaussian inference without regularization. It adeptly balances theoretical insight with practical utility, advocating for the adoption of sequential-growth-based processes in analyzing complex datasets. The results, illustrated through comprehensive experiments, suggest robust performance and versatility, forecasting future developments in high-dimensional statistical modeling and diagnostics. As such, these methods hold potential for advancing parameter learning and refining stability selection frameworks in statistical analysis.