- The paper introduces a distribution-free, spectrum-adaptive algorithm (PRISM) that dynamically fits polynomial updates to the evolving matrix spectrum using randomized sketching.
- It replaces traditional fixed-coefficient iterations with an adaptive, least-squares polynomial fitting approach, achieving faster convergence and lower error in neural network optimization.
- Empirical results demonstrate performance gains in optimizers like Shampoo and Muon, delivering improved training speeds across both Gaussian and heavy-tailed spectral scenarios.
PRISM: Spectrum-Adaptive, Distribution-Free Acceleration for Matrix Functions in Neural Network Optimization
Introduction
The computation of matrix functions—such as the matrix square root, inverse roots, and polar decomposition—is critical in a diverse set of applications, particularly in preconditioned optimization in deep neural networks. Recent optimizers like Shampoo and Muon rely on fast, stable calculation of these functions, which, in high-dimensional settings, mandates computational strategies that avoid expensive eigendecompositions and instead exploit hardware-optimized matrix multiplications (GEMMs). Traditional Newton-Schulz-style iterations and their recent polynomial-accelerated extensions have offered significant advances, but their dependence on fixed or estimated spectral parameters fundamentally limits adaptivity and universality. "PRISM: Distribution-free Adaptive Computation of Matrix Functions for Accelerating Neural Network Training" (2601.22137) introduces a unified, spectrum-adaptive meta-algorithm leveraging randomized sketching to fit polynomial updates directly to the evolving spectrum, delivering robust, distribution-free acceleration with minimal computational overhead.
Main Contributions
The central contribution of PRISM (Polynomial-fitting and Randomized Iterative Sketching for Matrix functions computation) is the removal of all reliance on a priori spectral information, providing instead a dynamic spectrum-adaptive polynomial acceleration mechanism for iterative computation of a broad suite of matrix functions. At each iteration, PRISM performs a randomized sketch-based, instance-specific polynomial fitting to the current residual matrix. This polynomial is then used in the update, seamlessly incorporating the prevailing spectral profile without direct computation or estimation of the spectrum.
PRISM encompasses and generalizes existing methods, including all Newton-Schulz variants, Chebyshev, and Newton iterations for roots and polar decomposition. Critically, it supports hardware-native GEMM-dominated kernels with negligible additional wall-clock overhead—sketching reduces polynomial fitting to O(n2logn) time per iteration, subdominant compared to the O(n3) matrix multiplications.
Empirical results demonstrate that, when integrated into leading optimizers (Shampoo, Muon), PRISM consistently accelerates training. This is evident both for Marchenko-Pastur (random-matrix-theoretic) and heavy-tailed spectral cases, the latter being particularly relevant for modern large-scale neural network weight and gradient matrices.
Detailed Methodology
PRISM proceeds in two principal phases:
- Part I (Iterative Polynomial Formulation): The matrix function iteration is reformulated so that each update is a polynomial (e.g., Taylor expansion or a fixed-degree rational function) of the current iterate.
- Part II (Adaptive Polynomial Fitting): The polynomial is dynamically refit at each iteration using a least-squares criterion over the empirical spectrum of the residual matrix. This fitting is performed using randomized sketching, so the least-squares objective is efficiently estimated using embedding matrices.
This adaptation obviates any need for predefined or estimated spectral ranges, and the resulting update polynomial is tightly fitted to the actual singular values of the input—even in the face of highly non-uniform or heavy-tailed spectra.
Polynomial Update Optimization
Consider the classical Newton-Schulz update for the matrix sign (or its relatives: square-root and polar decomposition):
Xk+1=Xkfd(Ξk)
where fd is a fixed Taylor polynomial approximation and Ξk is the residual. PRISM replaces fd by a spectrum-adapted polynomial gd(ξ;αk), where only the leading (highest-order) coefficient is re-optimized at each iteration subject to a constrained interval.
This step can be formalized as:
αk∗=argα∈[ℓ,u]mini=1∑n(1−(1−λk,i)gd(λk,i;α)2)2
where {λk,i} are the eigenvalues of the current residual.
Randomized Sketching for Polynomial Fitting
Since eigenvalue computation is still too costly for large n, PRISM leverages randomized sketching: the residual matrix is embedded into a lower-dimensional subspace (using a randomized orthogonal or Gaussian matrix), and the minimization objective is evaluated in this reduced space. This results in highly accurate, rapidly computed polynomial coefficients with theoretical guarantees (Johnson-Lindenstrauss/OSE bounds). For typical target error and confidence, p=O(logn) suffices for the embedding dimension.
Strong Numerical Results
PRISM consistently outperforms fixed-interval and classical variants, demonstrating both robust wall-clock speedups and lower error across a suite of tasks:
- Spectrum Adaptivity: The performance of fixed-coefficient methods degrades when the actual spectral interval mismatches the hardcoded one; PRISM's convergence is invariant to such mismatch and maintains acceleration regardless of the range of singular values (Figure 1).
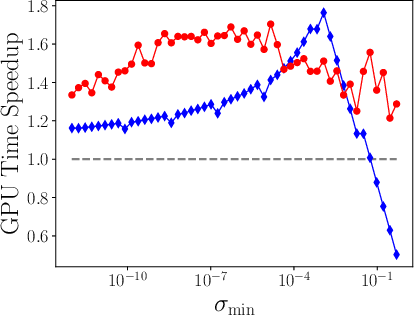
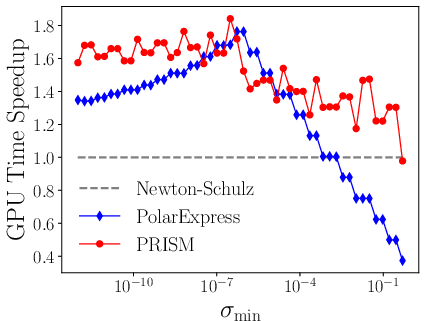
Figure 1: Speedup in GPU time over the classical Newton-Schulz for polar decomposition (left) and square root (right).
- Convergence Improvement via Polynomial Fitting: Spectrum-adapted polynomials provide strictly faster contraction in the residual over vanilla Taylor expansion approximations, especially during the ill-conditioned, early phase of convergence (Figure 2).
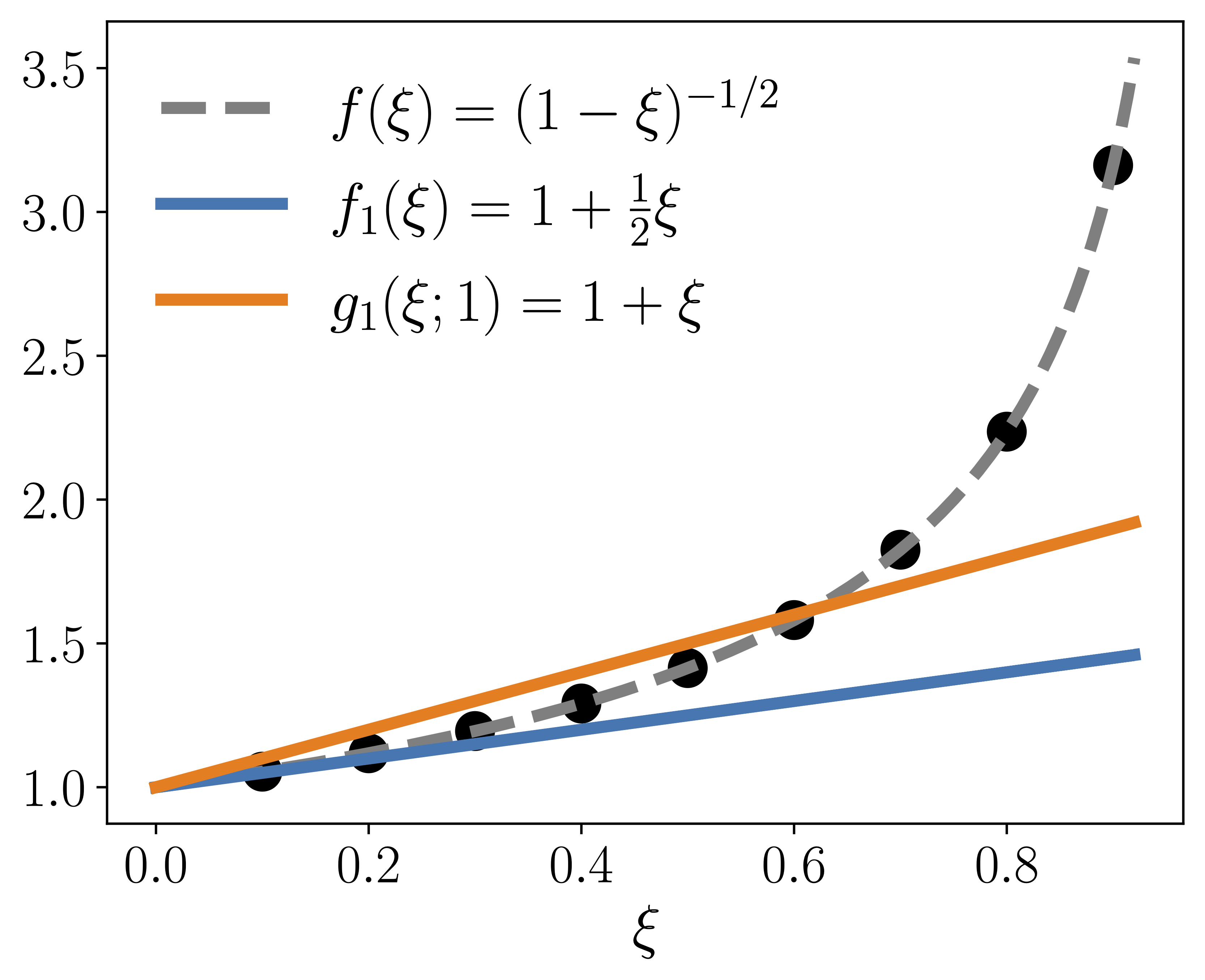
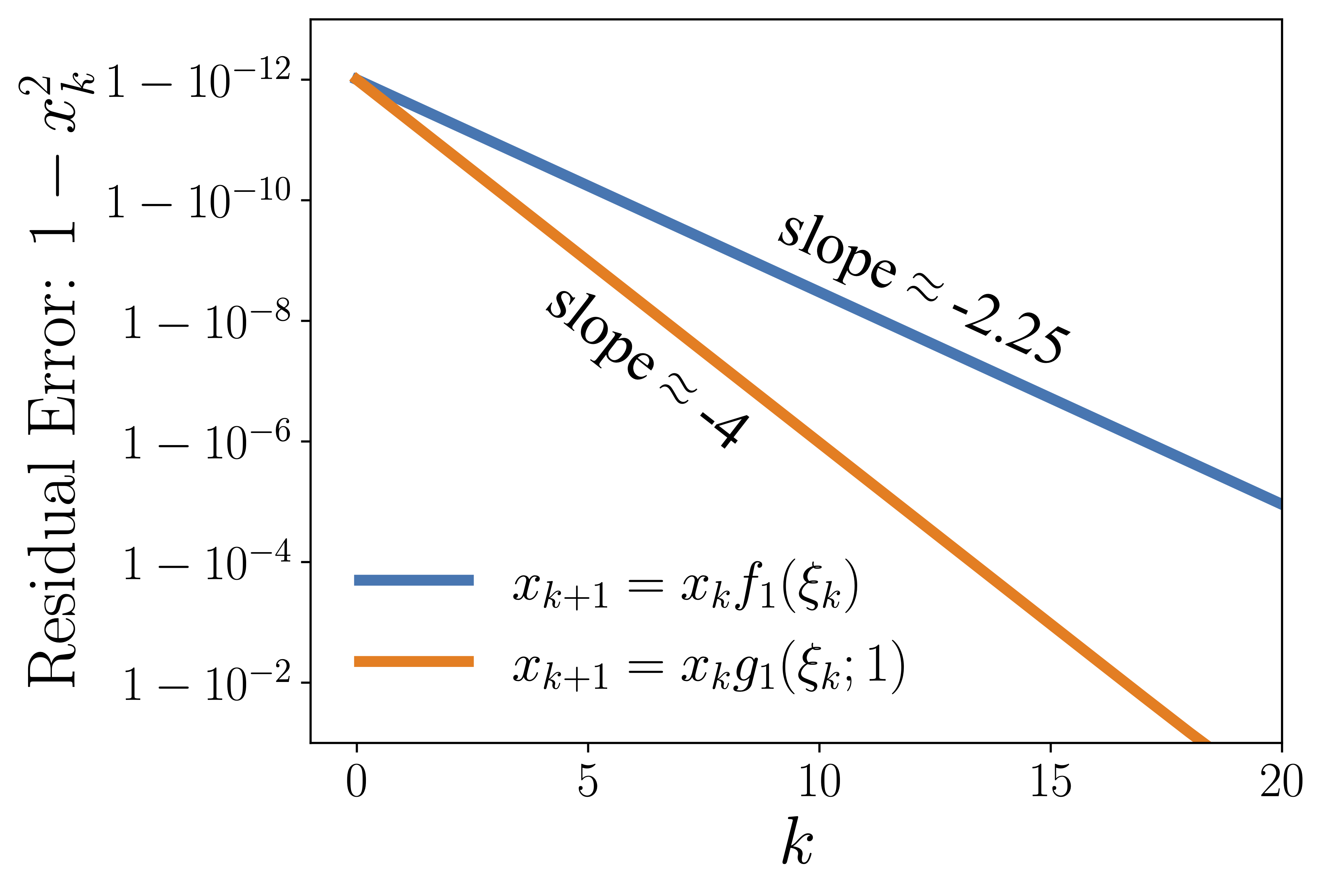
Figure 2: Faster convergence of the residual when using an adaptively fitted polynomial vs. classical Taylor expansion.
- Generalization Beyond Gaussian Spectra: Both in Gaussian (Marchenko-Pastur) random matrices and in heavy-tailed HTMP-generated matrices (which model weight/gradient spectra in large neural networks), PRISM exhibits uniformly faster, more stable convergence in orthogonalization tasks compared to both classical and Chebyshev-accelerated methods (Figures 4, 5).
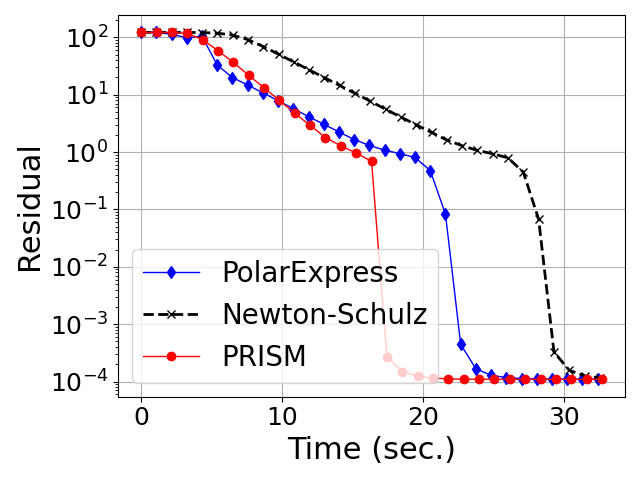
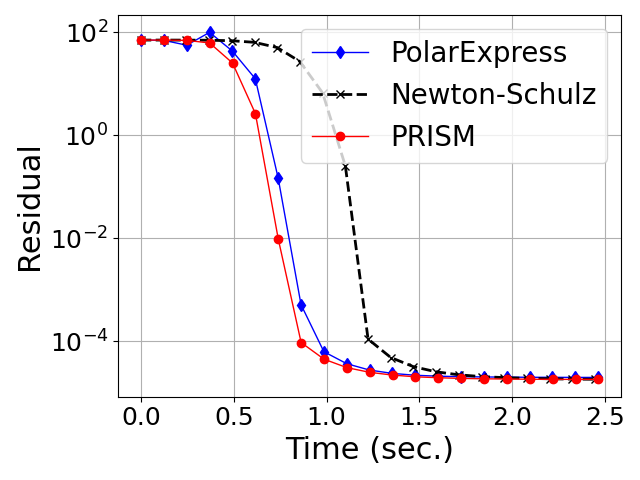
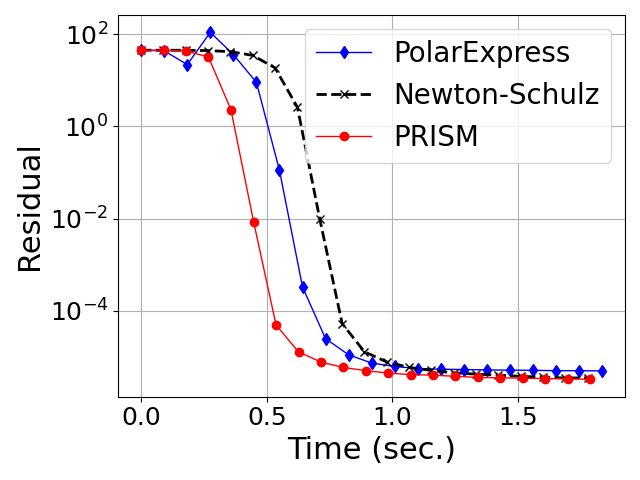
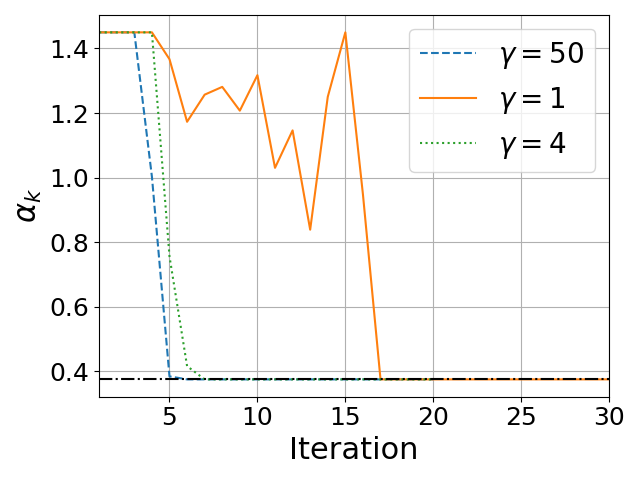
Figure 3: Convergence of degree-5 polynomial methods for orthogonalization on Gaussian random matrices across varying aspect ratios.
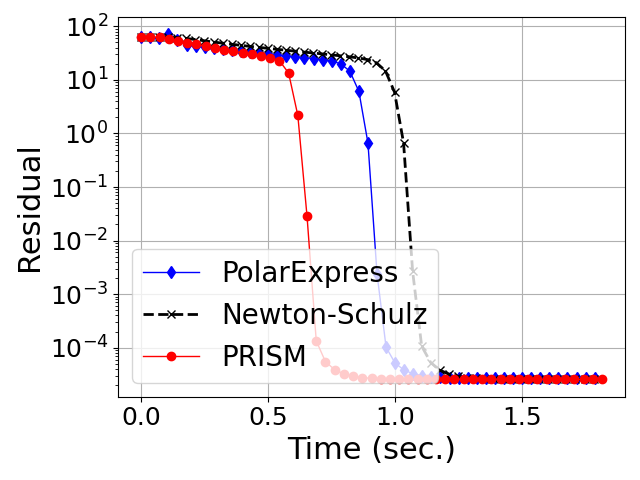
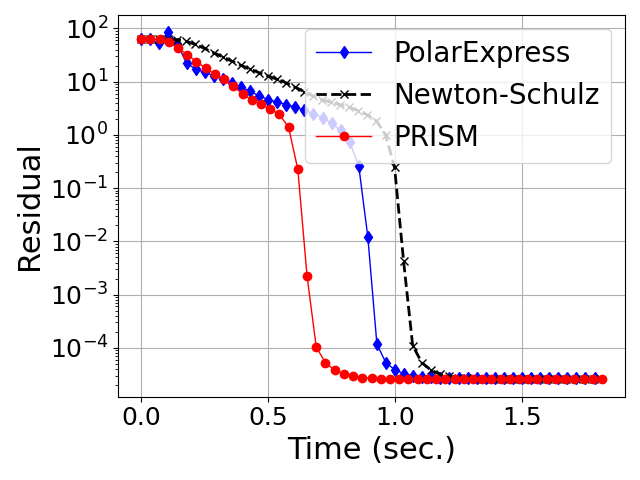
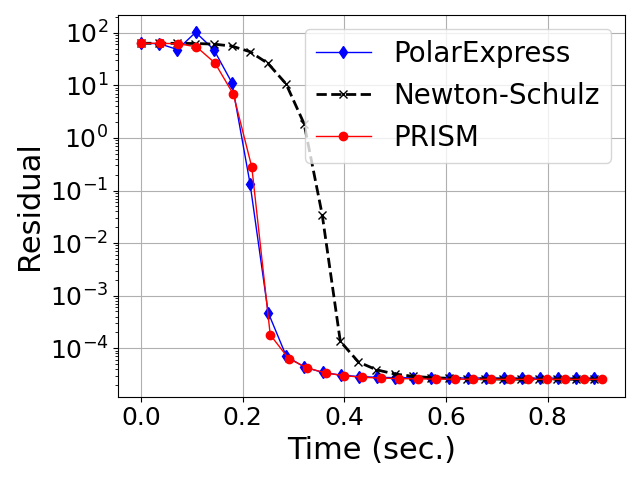
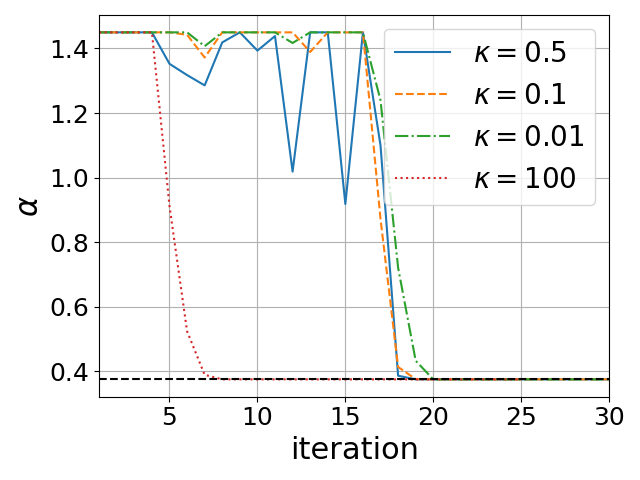
Figure 4: Convergence of degree-5 polynomial methods for orthogonalization on heavy-tailed random matrices (HTMP).
- Accelerated Square Root and Inverse Computation: Analogous empirical wins are seen for computing matrix square/ inverse roots, necessary for constructing preconditioners (Figures 10, 11).
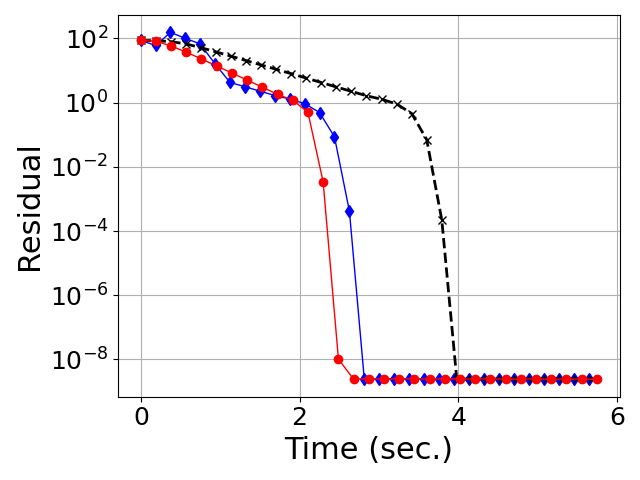
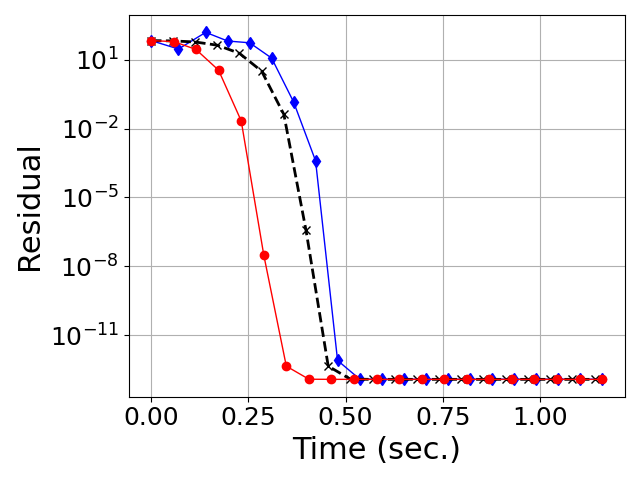
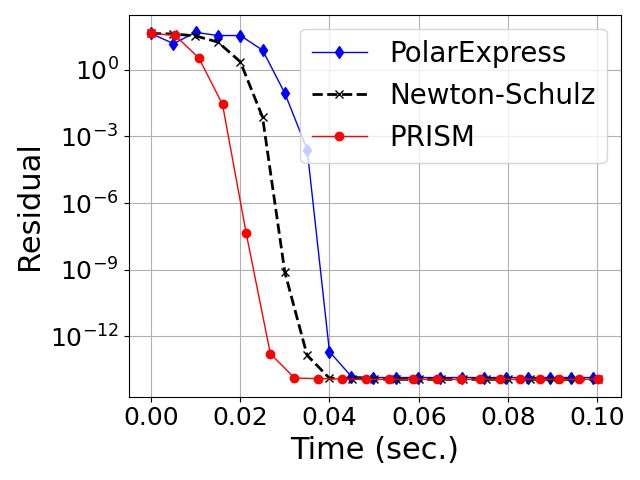
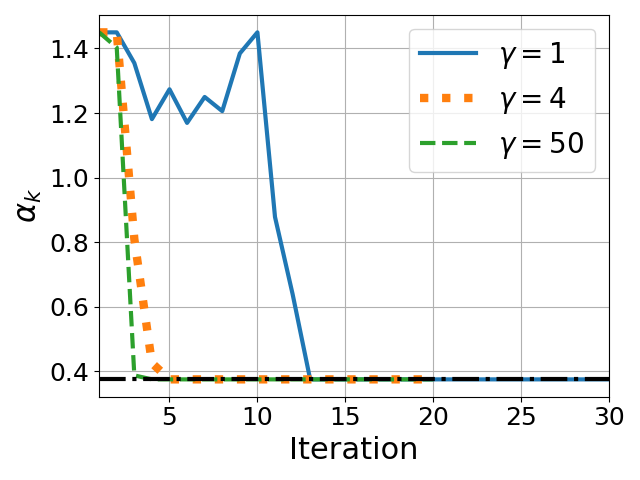
Figure 5: Convergence of degree-5 polynomial methods for computing the square root and inverse square root on Gaussian-Wishart matrices.
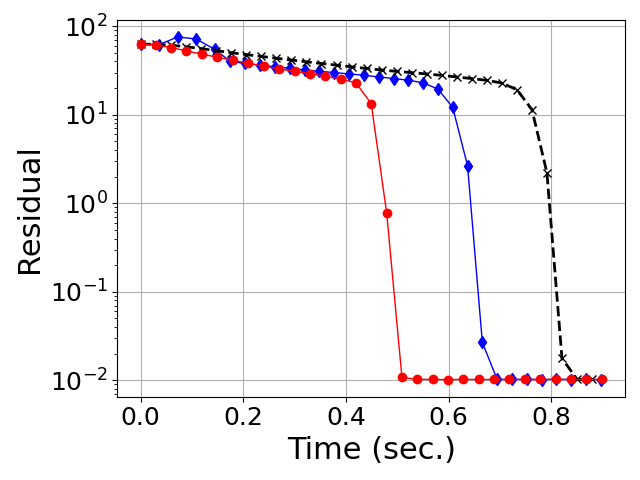
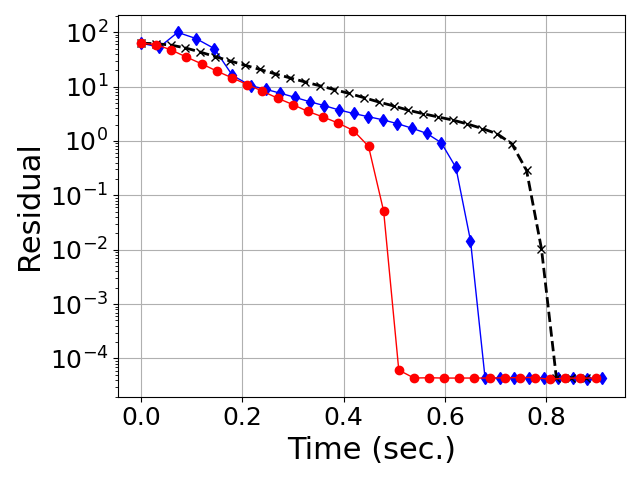
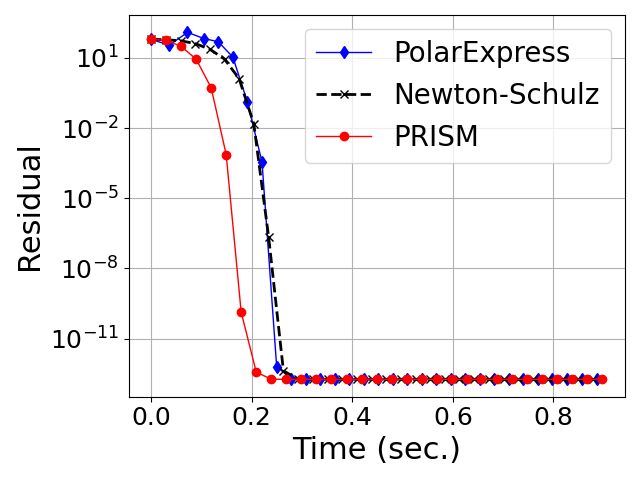
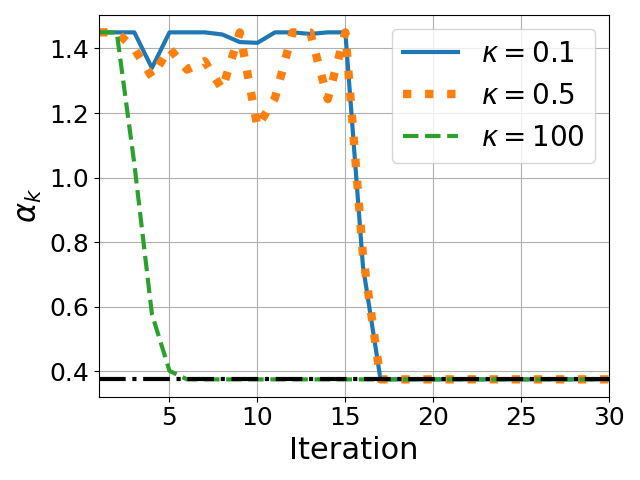
Figure 6: Convergence on heavy-tailed spectra.
- Practical Optimization Impact: Integrating PRISM into Shampoo boosts training speed and accuracy for deep ResNet models (Figure 7), outperforming both eigendecomposition- and fixed-interval-based accelerations.
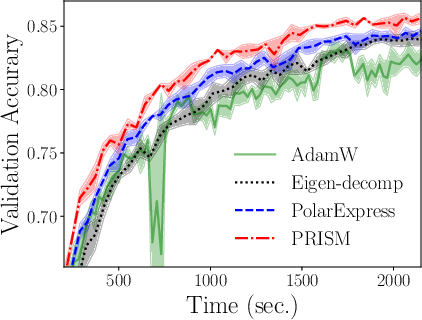
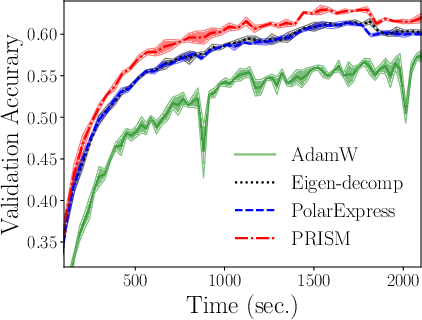
Figure 7: Improvement to the Shampoo optimizer—faster preconditioner update, leading to increased accuracy on CIFAR tasks.
- LLM Training: In Muon-optimized GPT-2 training, PRISM achieves lower training and validation losses compared to PolarExpress and AdamW, with the adaptive degree-5 method realizing the best convergence (Figure 8).
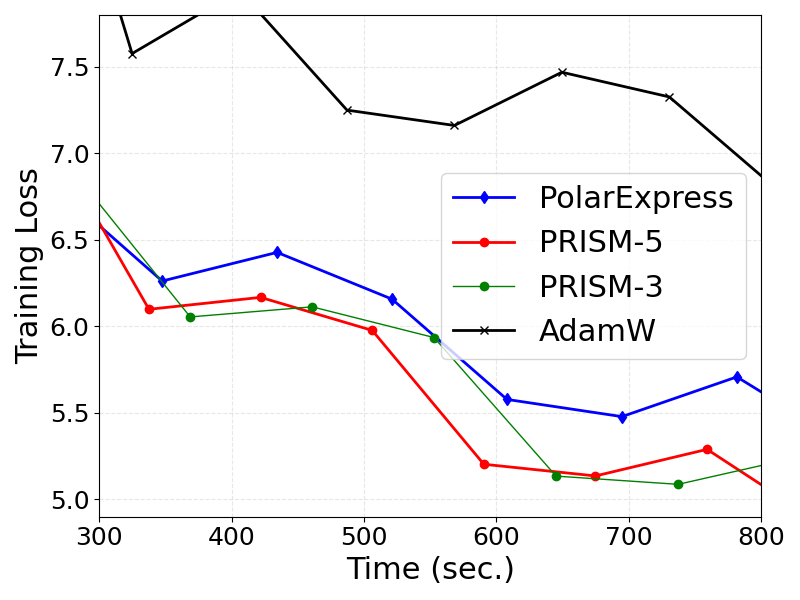
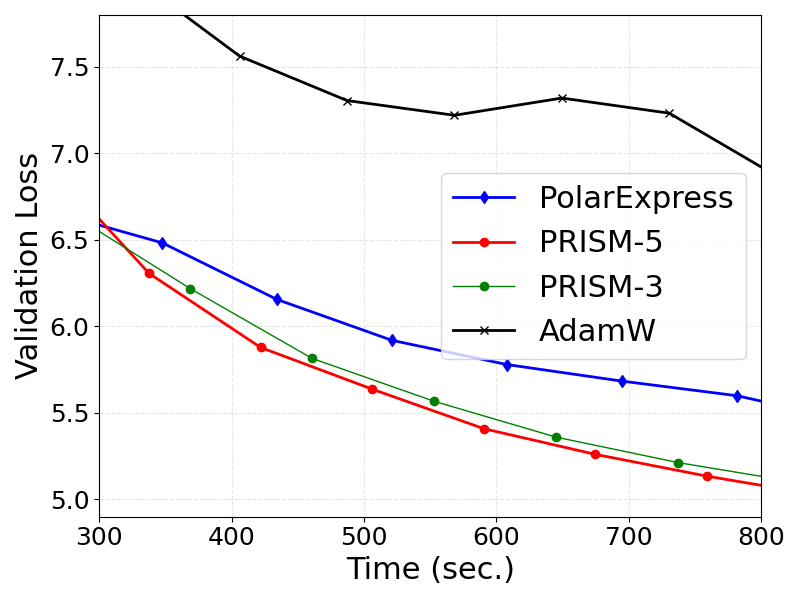
Figure 8: Training and validation losses for GPT-2, showing superior convergence for PRISM-based Muon variants.
Theoretical Guarantees
- Distribution-Free Convergence: PRISM's projected polynomials preserve worst-case quadratic convergence of the classical iterations, even under randomized embedding. Theoretical results bound the error between the actual and projected polynomial update.
- No Hyperparameter Tuning: All algorithmic choices (e.g., polynomial degree, constraint intervals) are universal and independent of singular value distribution.
Implications and Future Directions
PRISM establishes that spectrum-adaptive, randomized-sketching-based polynomial fitting offers a general, distribution-free framework for accelerating matrix function iterations. The primary practical implication is robust, high-performance neural network training that is invariant to changes in initialization, preconditioning, or model-induced spectral structure, without hand-crafted spectral intervals or pathological slowdowns.
Theoretically, this approach opens new avenues for polynomial numerical methods in high-dimensional, hardware-optimized settings, and suggests further integration with stochastic/Monte Carlo search methods for optimal polynomial discovery. Integration with distributed and parallel optimization architectures (e.g., FSDP, DION) is direct, and future directions include extending PRISM to more sophisticated matrix functions, non-symmetric problems, and further optimization for extreme aspect ratios and low precision hardware.
Conclusion
PRISM provides a distribution-free, spectrum-adaptive acceleration framework for GPU-optimized matrix function computation, significantly advancing the practical and theoretical foundations of preconditioned optimization in large-scale deep learning. By making spectral adaptivity as efficient and stable as fixed-coefficient methods—without sacrificing universality—the framework subsumes and generalizes prior polynomial/rational-iteration accelerators, delivering robust gains in both optimizer performance and neural network training outcomes (2601.22137).