Routing the Lottery: Adaptive Subnetworks for Heterogeneous Data
Abstract: In pruning, the Lottery Ticket Hypothesis posits that large networks contain sparse subnetworks, or winning tickets, that can be trained in isolation to match the performance of their dense counterparts. However, most existing approaches assume a single universal winning ticket shared across all inputs, ignoring the inherent heterogeneity of real-world data. In this work, we propose Routing the Lottery (RTL), an adaptive pruning framework that discovers multiple specialized subnetworks, called adaptive tickets, each tailored to a class, semantic cluster, or environmental condition. Across diverse datasets and tasks, RTL consistently outperforms single- and multi-model baselines in balanced accuracy and recall, while using up to 10 times fewer parameters than independent models and exhibiting semantically aligned. Furthermore, we identify subnetwork collapse, a performance drop under aggressive pruning, and introduce a subnetwork similarity score that enables label-free diagnosis of oversparsification. Overall, our results recast pruning as a mechanism for aligning model structure with data heterogeneity, paving the way toward more modular and context-aware deep learning.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
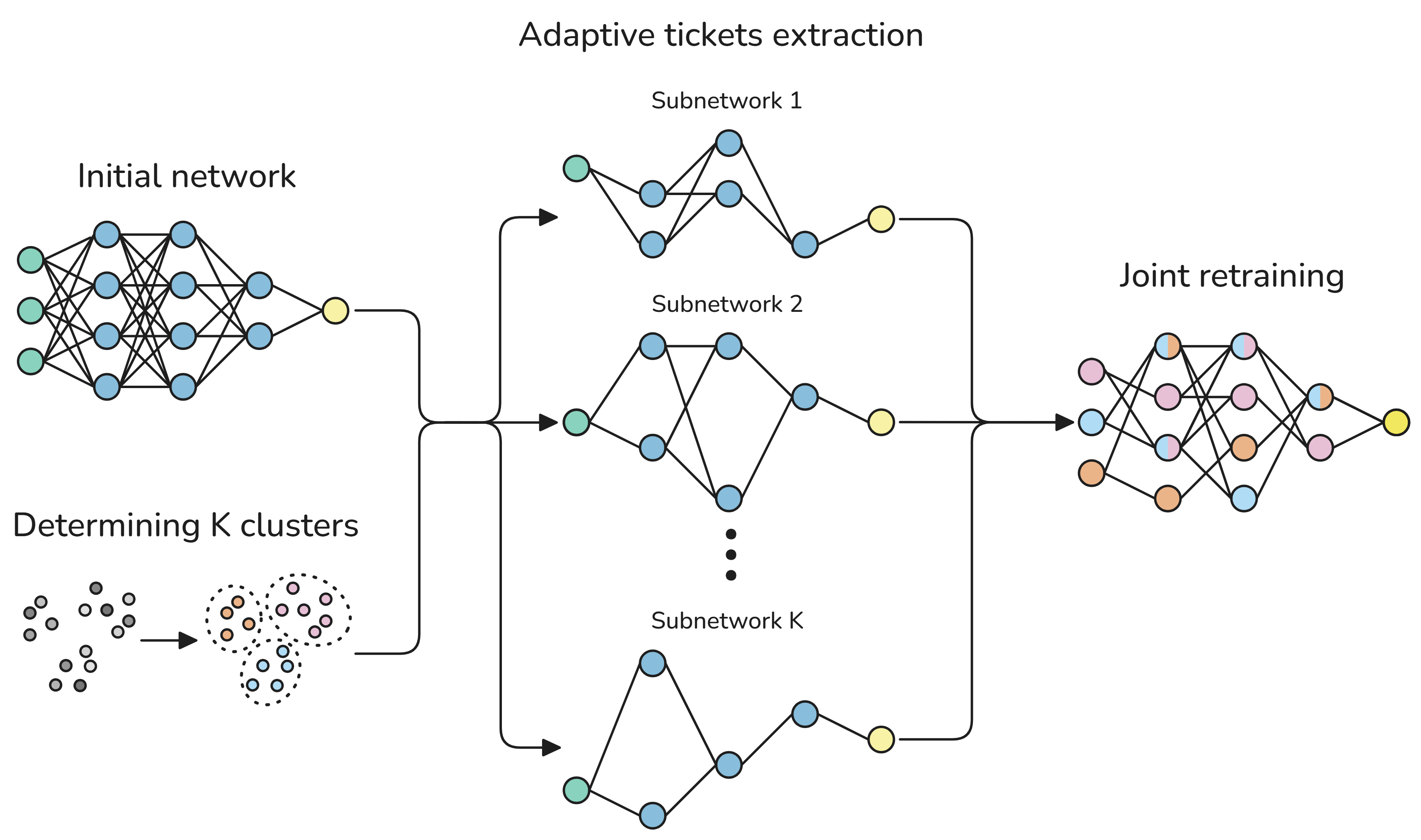
This paper introduces a way to make big neural networks smaller and smarter by trimming them in a thoughtful way. Instead of forcing one tiny version of a model to handle every kind of input, the authors create several small, specialized “paths” inside the same model. Each path is tuned to a specific type of data (like a class of images or a noisy environment). They call this approach Routing the Lottery (RTL).
What questions are the authors trying to answer?
The paper focuses on three simple questions:
- Can one big model contain multiple small, specialized versions (subnetworks) that work better for different kinds of inputs?
- Is it possible to find these specialized subnetworks just by “pruning” (removing unneeded connections) without building extra complicated systems?
- How do we know when we’ve pruned too much and started hurting the model’s performance?
How did they do it?
Think of a neural network like a huge city of roads and intersections. Pruning is like shutting down roads that aren’t useful so traffic can move faster. The “Lottery Ticket Hypothesis” says there are hidden, smaller road networks (winning tickets) inside the big city that can do the job just as well if you find and train them.
The authors extend this idea:
- Instead of finding one universal “winning ticket” for all traffic, they find several “adaptive tickets,” each designed for a different neighborhood (type of data).
Here’s their approach, explained in everyday terms:
- Split the data into meaningful groups: For example, by class (cats vs. trucks in CIFAR-10), by broad theme (clusters in CIFAR-100), by regions inside a single image (for image reconstruction), or by environment (indoor vs. outdoor noise for speech).
- For each group, lightly train the model and then prune (remove) the smallest, least helpful connections. This creates a mask, which is basically a map of which connections stay on and which turn off.
- Reset the remaining connections back to their starting values and repeat until each group’s subnetwork is nicely “trimmed.”
- Joint retraining: Train all these subnetworks together inside the same shared model. When updating the model, only the connections that belong to a given subnetwork get changed (like editing just one city’s district without messing up others). This keeps the subnetworks from interfering with each other.
Key terms explained simply:
- Pruning: Removing weak or unnecessary connections to make the model smaller and faster.
- Mask: A switchboard that says which connections are on (1) and off (0) for a subnetwork.
- Sparsity: How many connections have been removed. Higher sparsity means fewer active connections.
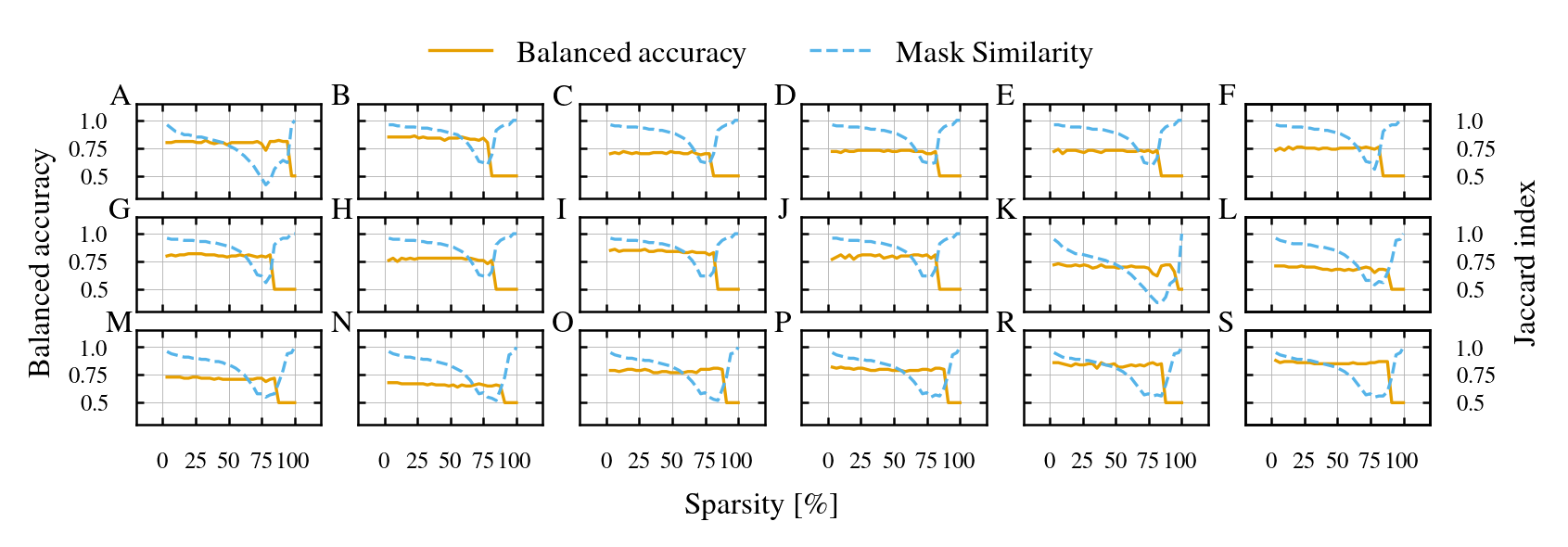
- Subnetwork collapse: When pruning goes too far, different specialized paths start looking the same and performance drops.
- Mask similarity: A measure of how much two subnetworks share the same connections. High similarity means they’re not very different.
What did they find and why is it important?
Across different tasks, RTL performed better or as well as traditional pruning methods, often with far fewer parameters than training many separate models. Here’s a simple summary:
- CIFAR-10 (image classification with 10 classes): Subnetworks specialized per class had higher balanced accuracy and recall than one-size-fits-all pruning, while using much fewer parameters than training a separate model for each class.
- CIFAR-100 (100 classes grouped into 8 clusters): Even with imperfect groupings, adaptive subnetworks still beat single-mask methods and were much more efficient than many independent models.
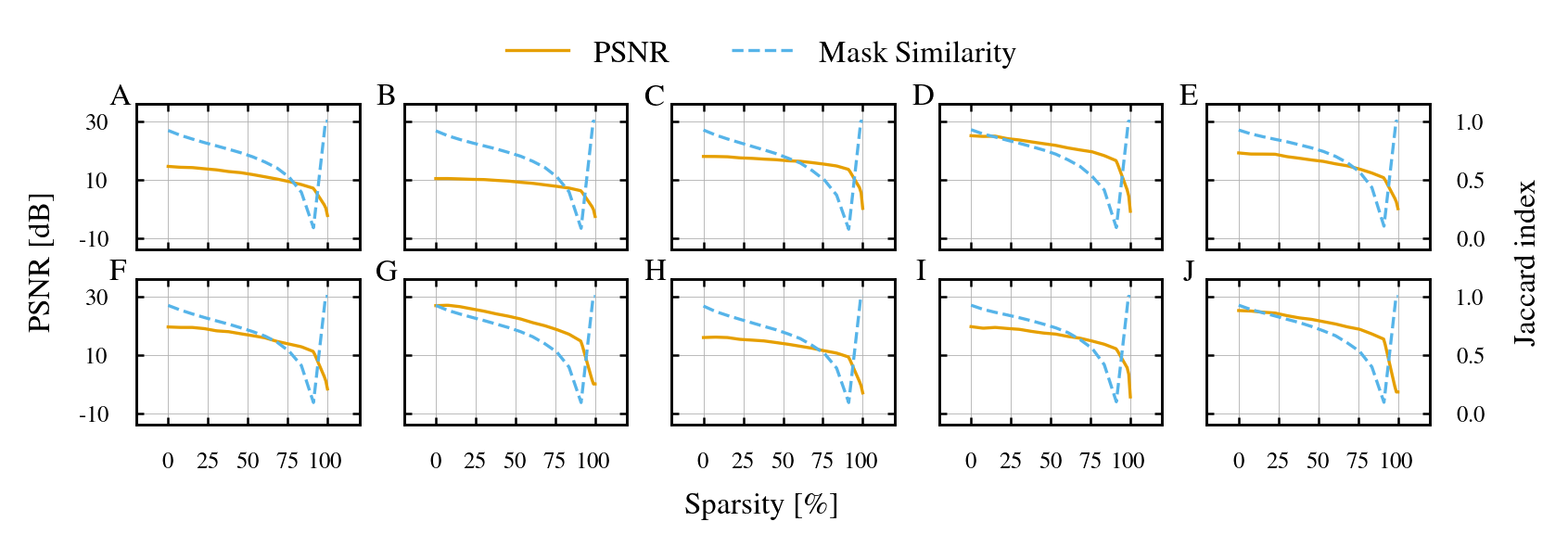
- Implicit Neural Representations (INRs) for images: Specializing per semantic region (like sky vs. building) improved reconstruction quality (higher PSNR) compared to using a single pruned network for the whole image.
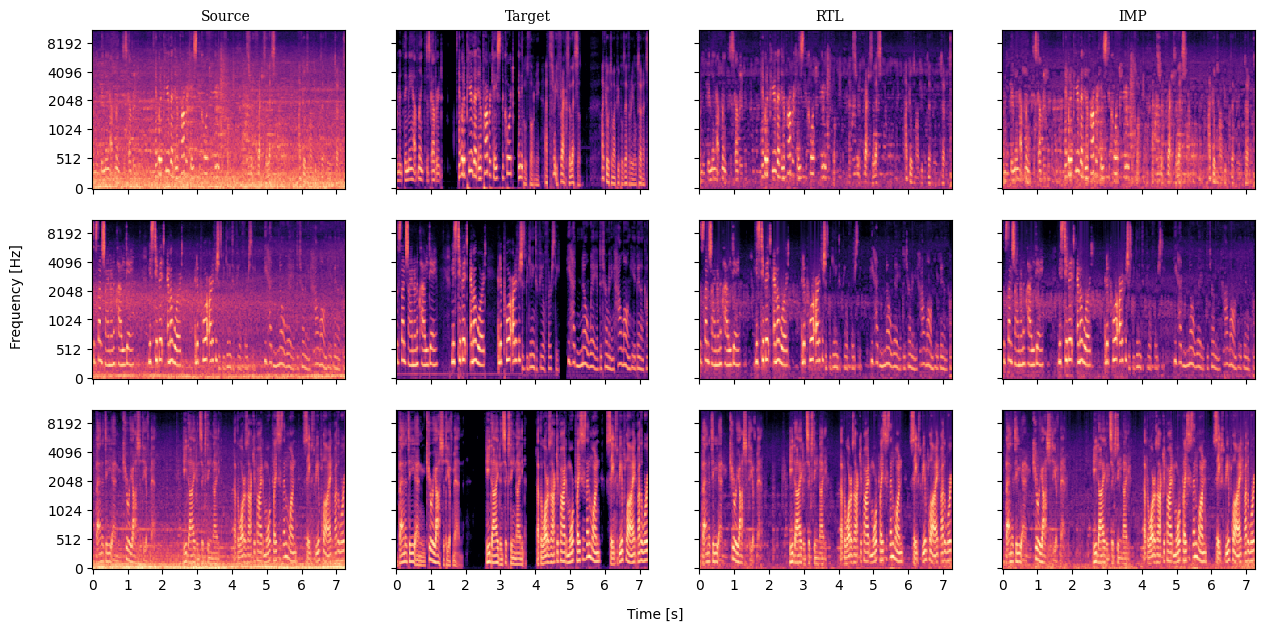
- Speech enhancement (denoising in different environments): Subnetworks specialized for indoor, outdoor, and transportation noises improved the clarity of speech (higher SI-SNRi) more than single or multiple separate models.
They also discovered:
- Subnetwork collapse: If you prune too aggressively, different specialized paths become too similar, and performance drops sharply. A simple “mask similarity” score gives a warning sign—even without labels—that you’re pruning too much.
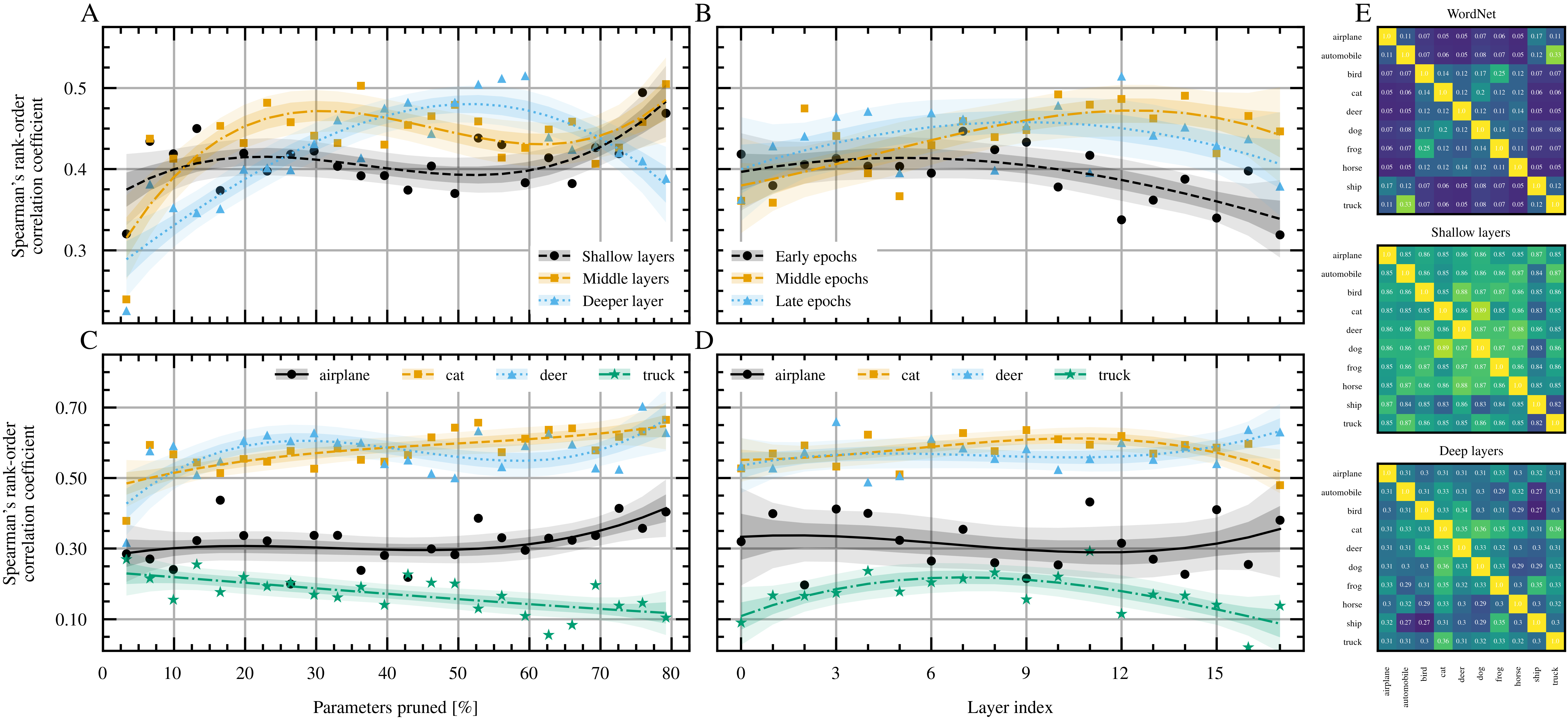
- Semantic alignment: Subnetworks naturally reflect real-world relationships. For example, animal classes end up sharing more structure with each other than with vehicle classes, especially in deeper layers, which suggests pruning can uncover meaningful patterns.
Why this matters:
- Better performance with fewer parameters means models can run faster and fit on devices with limited memory (like phones or edge sensors).
- Specialization makes models more understandable and flexible: they use the right “path” for the right context.
- A simple early warning for over-pruning helps avoid damaging your model during compression.
What’s the bigger impact?
RTL shows that pruning isn’t just about making models smaller—it can also make them smarter by aligning the model’s structure with the natural variety in the data. This leads to:
- More modular, context-aware systems that pick the best path for the job (class, cluster, environment).
- Efficient deployment in real-world settings (e.g., better speech enhancement on devices with limited compute).
- Clearer, more interpretable models where different parts have specific roles.
In short, instead of squeezing everything through one narrow doorway, RTL builds several smaller, well-chosen doorways—each tailored to what’s coming through—so the whole system runs smoother, faster, and more reliably.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Inference-time routing without ground-truth context: The method assumes access to true class/cluster/environment labels for routing; a practical, lightweight router (learned or heuristic) and its training/evaluation under misrouting are not developed.
- Robustness to routing errors and ambiguity: The impact of noisy, delayed, or uncertain routing (e.g., ambiguous inputs, multi-modal scenes) on accuracy and collapse risk is unquantified; error-tolerant routing or soft/blended mask activation is unexplored.
- Automatic discovery and selection of K: How to choose the number of subnetworks K and when to merge/split clusters is not addressed; no data-driven criterion (e.g., performance vs. mask-similarity trade-off) is provided.
- Sensitivity to partition quality: Dependence on the partition (class labels, text-based clusters, segmentation masks) is unstudied; systematic experiments varying cluster granularity, noise, and modality-driven vs. text-driven groupings are needed.
- Fully unsupervised specialization: RTL is “partition-agnostic” but relies on provided partitions; a self-supervised or jointly learned partitioning mechanism (e.g., clustering in representation space) is not explored.
- Realistic classification pipeline: For classification, predictions require combining K subnetworks when labels are unknown; decision rules, calibration, score aggregation, or gating-based selection are not designed or evaluated, especially to improve low precision.
- Precision–recall calibration: RTL’s reduced precision is noted but not remedied; concrete methods (thresholding, calibration, selective prediction) and their effect on balanced accuracy/recall are not demonstrated.
- Overlap control during extraction: Masks are extracted independently from θ0 with no explicit mechanism to limit overlap or encourage diversity; regularizers/constraints to manage overlap and their effect on performance and collapse are not studied.
- Gradient interference in overlapping regions: Joint retraining can still interfere where masks overlap; quantification and mitigation (e.g., orthogonal gradient projection, alternating updates, conflict-aware optimizers) are not investigated.
- Integrating collapse detection into training: The proposed mask-similarity signal is not turned into a practical stopping/early-warning rule (e.g., per-layer thresholds, moving averages, cross-validated cutoffs) nor assessed across tasks for reliability.
- Choice of similarity metric: Only Jaccard/IoU on binary masks is used; alternatives (e.g., Fisher overlap, path overlap by layer, cosine similarity of active weight vectors, influence functions) may offer better collapse detection but are untested.
- Per-layer sparsity allocation: Global magnitude pruning can starve critical layers; adaptive per-layer sparsity schedules tuned per-subnetwork (or jointly) are not explored.
- Alternative pruning criteria: The effect of different criteria (gradient- or Hessian-based, saliency, entropy, sensitivity) on specialization quality and collapse thresholds is unexamined.
- Compute and wall-clock cost: Algorithm 1 scales with K and iterative pruning rounds; training-time/energy cost vs. IMP and dynamic sparse training is not reported, and parallelization or more efficient schedules are not proposed.
- Memory and storage overhead: The storage footprint of K binary masks (and routing metadata) is not counted in parameter budgets; mask compression (bit-packing, run-length, structured factorization) and memory–latency trade-offs are unreported.
- Deployment speedups on hardware: Unstructured sparsity often yields limited real-time gains; actual latency/throughput/energy on CPUs/GPUs/NPUs and hardware-aware RTL (structured/channel pruning) are not evaluated.
- Scalability to large models: Experiments are on small backbones; viability for ResNets/ViTs, speech Transformers, and LLMs (including per-domain tickets) and associated scaling laws (K vs. overlap vs. accuracy) remain open.
- Comparison to conditional computation baselines: Empirical head-to-head with MoE/Switch/conditional convs under matched FLOPs/params/latency budgets is missing, as are hybrid designs (small router + RTL masks).
- Generalization and OOD robustness: Behavior of specialized subnetworks under domain shift, novel classes, new environments, or mixed/noisy contexts is unassessed; detection/abstention or fallback “universal” masks are not explored.
- Continual/incremental specialization: Adding new classes/clusters/environments without full re-pruning/retraining, expanding masks, and avoiding interference/forgetting is not addressed.
- Multi-label or overlapping regimes: Inputs that belong to multiple contexts (e.g., multi-object scenes, mixed acoustics) are not supported; combining multiple masks per input (union/intersection/soft gating) is an open design question.
- Training stability and variance: Sensitivity to random seeds, hyperparameters (T, p, s, η), and mask initialization/rewinding choices lacks analysis; confidence intervals and statistical significance are not reported.
- Interaction with class imbalance: The batch-repetition balancing step may overfit small subsets; principled reweighting, augmentation, or regularization for imbalanced or long-tail distributions is not investigated.
- Joint vs. sequential mask extraction: Co-extracting masks with explicit diversity or complementarity objectives (rather than independent IMP-style passes) may improve specialization; this joint optimization is unexplored.
- Layerwise semantic alignment: While semantic-mask correlations are shown, causal tests (e.g., enforcing alignment via regularizers) and their effect on accuracy/collapse are not studied; robustness of alignment across datasets is unclear.
- INR and speech routing practicality: INR relies on semantic segmentation masks and speech uses scene labels; when such metadata is unavailable, how to obtain it (joint segmentation/router) and at what cost remains open.
- Accounting conventions: Reported “parameters” appear to exclude mask storage and router costs; a standardized accounting (weights + masks + router) and end-to-end memory/compute budgeting would clarify practical efficiency.
- Safety, bias, and fairness: Per-subgroup specialization can encode or amplify biases; subgroup-wise performance audits, calibration, and fairness constraints for specialized subnetworks are not examined.
Practical Applications
Overview
The paper introduces Routing the Lottery (RTL), an adaptive pruning framework that discovers multiple specialized subnetworks (“adaptive tickets”) within a single shared backbone, each tailored to a class, cluster, or environment. Masks are learned per subset and routed with simple context signals (e.g., class label, scene type), yielding higher balanced accuracy/recall and better SI-SNRi than single-mask or multi-model baselines, with up to 10× fewer parameters than independent models. The authors also introduce a subnetwork similarity score to diagnose oversparsification without labels (early-warning for “subnetwork collapse”). Below are practical applications and workflows enabled by these findings.
Immediate Applications
The following applications can be deployed with current tooling and moderate integration effort.
- On-device noise suppression with environment-aware subnetworks
- Sectors: healthcare, consumer electronics, automotive, enterprise communications
- What to build:
- Smartphone/earbud/vehicle microphone pipelines that route audio frames to indoor/outdoor/vehicle-specific masks for denoising (as validated by RTL’s SI-SNRi gains).
- Video-conferencing SDKs offering ambient-aware noise suppression without shipping multiple models.
- Benefits: higher SI-SNRi than single-mask or multi-model baselines under the same budget; fewer parameters than per-environment models; improved battery life and latency on edge devices.
- Assumptions/dependencies: availability of a lightweight environment tag (e.g., device sensor metadata, geolocation, vehicle CAN bus, or a tiny scene classifier); hardware/runtime support for unstructured sparsity may vary; ensure safe fallbacks if routing is uncertain.
- Scene-aware image pipelines on mobile devices
- Sectors: mobile imaging, media, AR
- What to build:
- Camera “scene modes” routed to specialized masks for low light, HDR, portrait, or motion scenes to enhance denoise/deblur without swapping models.
- On-device image reconstruction in codecs or INRs with region-specific masks to improve quality at high sparsity (paper shows PSNR gains in INR).
- Benefits: better visual quality under tight compute/memory budgets; energy efficiency; easy integration with existing scene detectors.
- Assumptions/dependencies: simple scene detection available; runtime must support fast mask switching; unstructured-sparsity speedups depend on hardware.
- Context-aware perception for embedded/robotic systems
- Sectors: robotics, drones, industrial IoT, automotive ADAS
- What to build:
- Single backbone with specialized masks for indoor/outdoor, day/night, or weather conditions to maintain detection/segmentation performance on low-power SOCs.
- Route via existing state estimators (time-of-day, IMU/GPS, weather APIs) rather than training a heavy router.
- Benefits: robust perception across environments without model proliferation; fits within strict compute budgets.
- Assumptions/dependencies: reliable context sensors; careful treatment of mask overlap to prevent “subnetwork collapse” at high sparsity.
- MLOps: pruning workflows with multiple masks and collapse monitoring
- Sectors: software/ML infrastructure, cloud/edge platforms
- What to build:
- Extend pruning toolchains (PyTorch, TensorFlow) to:
- Extract per-cluster masks via RTL’s iterative magnitude pruning loop.
- Implement joint retraining with masked gradient updates.
- Expose a “subnetwork similarity” metric (e.g., Jaccard index) in training dashboards as a label-free early-warning signal for oversparsification.
- CI/CD checks that halt pruning or adjust sparsity when similarity spikes.
- Benefits: modularity and parameter sharing across contexts; higher accuracy/recall at comparable sparsity; safer pruning via automated diagnostics.
- Assumptions/dependencies: need dataset partitions (labels or offline clustering); compute budget for per-cluster pruning cycles; memory overhead for storing multiple masks; team familiarity with unstructured pruning trade-offs.
- Personal audio and hearing assistive devices
- Sectors: healthcare, consumer electronics
- What to build:
- Hearing aids and wearables with environment-specific masks for background noise profiles; on-device routing using simple rules (e.g., spectral statistics, microphone array cues).
- Benefits: better intelligibility; low latency and power consumption; privacy by keeping processing on-device.
- Assumptions/dependencies: stringent validation in medical contexts; robust failover to a general-purpose mask if context detection is uncertain.
- Enterprise and industrial monitoring with context-aware anomaly detection
- Sectors: manufacturing/energy, security, operations
- What to build:
- Single backbone with masks per asset type, operating regime, or facility; route via known metadata.
- Benefits: improved recall of rare anomalies with compact models; reduced need for many specialized models.
- Assumptions/dependencies: high-quality metadata; retraining when regimes change; calibration to manage RTL’s recall-heavy tendency.
- Academic research on modularity and interpretability
- Sectors: academia
- What to build:
- Studies on semantic alignment and modularity using mask similarity across datasets; reproducible benchmarks extending CIFAR and ADE20K experiments.
- Benefits: interpretable structure-function analysis without auxiliary routers; accessible to standard compute budgets.
- Assumptions/dependencies: availability of labeled or clusterable datasets; careful choice of sparsity to avoid subnetwork collapse.
Long-Term Applications
These applications require additional research, scaling, or engineering (e.g., hardware/software co-design, large-scale validation, or automation).
- Domain-specialized LLMs via masked experts
- Sectors: software, enterprise IT, education, finance, healthcare
- What to build:
- Extend RTL to transformer-based LLMs with domain masks (legal, medical, coding) within a shared backbone; route by task metadata or a small router.
- Benefits: parameter-efficient domain specialization without full MoE overhead; reduced serving costs; better domain recall.
- Assumptions/dependencies: hardware acceleration for unstructured sparsity in transformers; scalable mask extraction and joint retraining; strong routing confidence for safety-critical domains.
- Federated learning with per-client/per-site masks
- Sectors: healthcare, finance, edge IoT
- What to build:
- Federated workflows where clients learn local masks (device/site specialization) and share masked updates to a common backbone.
- Benefits: personalization and heterogeneity handling; bandwidth savings; privacy preservation.
- Assumptions/dependencies: aggregation protocols for masked parameters; stability against drift; fairness and compliance considerations.
- Regulatory and sustainability policy: “green AI” and safety guidelines
- Sectors: policy/governance
- What to build:
- Procurement and compliance frameworks recognizing adaptive pruning as a means to meet energy/carbon targets.
- Safety guidelines requiring collapse monitoring (mask similarity thresholds) for compressed models in regulated sectors.
- Benefits: standardized energy reporting; fail-safes during model compression; improved public trust.
- Assumptions/dependencies: accepted metrics for unstructured sparsity speedups; auditing tools; sector-specific validation protocols.
- AutoML pipelines for automatic data partitioning and mask discovery
- Sectors: ML platforms, enterprise software
- What to build:
- Automated clustering of heterogeneous datasets; hyperparameter search for number of masks, sparsity, overlap constraints; co-optimization with quantization/distillation.
- Benefits: turnkey context-aware compression without manual partitioning; improved performance under tight budgets.
- Assumptions/dependencies: robust unsupervised clustering; avoiding overfitting to spurious clusters; compute overhead of the search phase.
- Hardware/runtime support for fast mask routing and unstructured sparsity
- Sectors: semiconductors, systems software
- What to build:
- Compilers and runtimes that cache multiple masked variants, accelerate mask-aware kernels, or convert masks to structured patterns for better throughput.
- Benefits: predictable latency gains; lower energy; broader adoption of RTL-style models.
- Assumptions/dependencies: vendor support; trade-offs between unstructured vs. structured sparsity; dynamic mask switching overhead.
- Safety-critical ensembles with context-aware failover
- Sectors: automotive, aerospace, healthcare
- What to build:
- Ensembles of specialized masks with monitors that detect misrouting, trigger a general-purpose mask, or calibrate predictions.
- Benefits: maintain high recall while enforcing safety; reduce worst-case errors in out-of-distribution contexts.
- Assumptions/dependencies: formal verification and monitoring; rigorous certification; conservative sparsity settings to prevent collapse.
- Content-aware graphics and neural rendering
- Sectors: gaming, AR/VR, media
- What to build:
- Region- or asset-specific masks for neural textures, super-resolution, or denoising (building on INR results), routed by scene graph semantics.
- Benefits: higher visual fidelity at lower compute; efficient on-device rendering.
- Assumptions/dependencies: integration with real-time engines; stable routing under rapid scene changes; GPU support for masked inference.
- Fairness- and privacy-aware model partitioning
- Sectors: public sector, finance, HR tech
- What to build:
- Mask discovery that constrains or audits specialization to avoid proxy alignment with protected attributes; privacy-preserving clustering.
- Benefits: reduced risk of disparate impact; transparent specialization.
- Assumptions/dependencies: bias detection and mitigation pipelines; governance for mask audits; additional constraints may reduce compression gains.
- Cross-task modular backbones in multi-task learning
- Sectors: robotics, autonomous systems, enterprise AI
- What to build:
- Single backbone with task-specific masks (e.g., detection, segmentation, depth) and light routing; share low-level features; specialize at deeper layers (aligned with paper’s semantic-depth findings).
- Benefits: parameter sharing across tasks; improved recall per task; simplified deployment.
- Assumptions/dependencies: joint training stability; task interference management; scheduling and mask overlap control.
- Libraries and marketplaces for reusable subnetworks
- Sectors: software ecosystems
- What to build:
- Catalogs of vetted adaptive masks for standard backbones (e.g., ResNet, UNet) across common contexts; plug-and-play routing modules.
- Benefits: faster adoption; community benchmarking; interoperability.
- Assumptions/dependencies: versioning, licensing, and security for mask artifacts; standardized export formats and APIs.
Notes on Feasibility and Dependencies (cross-cutting)
- Context signals: Immediate deployments assume access to reliable context labels (class, environment) or inexpensive proxies (metadata, lightweight classifiers). Lacking this, a small router may be required, adding complexity and latency.
- Hardware: Real-world latency gains from unstructured pruning depend on hardware support; structured approximations or kernel-level optimizations may be necessary for speedups.
- Training budget: Mask extraction requires per-subset pruning cycles and joint retraining; still lighter than training many standalone models but needs planning.
- Stability: Monitor subnetwork similarity to avoid “collapse”; stop pruning or adjust sparsity when similarity spikes.
- Integration with other compression: Combine with quantization/distillation carefully; validate interactions, especially at high sparsity.
- Safety and fairness: In regulated or sensitive domains, ensure robust fallbacks, calibration (RTL tends to favor recall), and audits to avoid unintended specialization aligned with protected attributes.
These applications translate RTL’s key innovations—adaptive, context-aware sparsity; shared backbones with per-context masks; and collapse diagnostics—into concrete tools, products, and deployment workflows across sectors.
Glossary
- Adaptive pruning: A pruning approach that tailors sparsity patterns to different data subsets rather than using a single global mask. "we propose Routing the Lottery (RTL), an adaptive pruning framework that discovers multiple specialized subnetworks"
- Adaptive tickets: Specialized sparse subnetworks discovered for particular classes, clusters, or conditions. "multiple specialized subnetworks, called adaptive tickets, each tailored to a class, semantic cluster, or environmental condition."
- Balanced accuracy: A performance metric averaging recall across classes, mitigating class imbalance effects. "RTL consistently outperforms single- and multi-model baselines in balanced accuracy and recall"
- Catastrophic forgetting: Degradation of previously learned knowledge when training on new data; here, avoided by masking gradients per subnetwork. "preventing interference between subnetworks and avoiding both catastrophic forgetting and collapse."
- Cluster-aware pruning: Pruning strategy that specializes subnetworks to data clusters rather than individual classes. "Cluster-aware pruning on CIFAR-100"
- Context-aware inference: Inference that uses contextual information (e.g., labels or environment) to select appropriate subnetworks. "employing a mask-based routing to enable context-aware inference."
- Context-based routing: Selecting which subnetwork to use based on contextual signals like labels or environments. "selects them via simple context-based routing (e.g., label or environment)"
- Coordinate-based neural network: A model that maps continuous coordinates (e.g., pixel positions) directly to signal values. "mapping continuous pixel coordinates to RGB values using a coordinate-based neural network."
- Dynamic sparse training: Methods that modify sparsity patterns online by pruning and regrowing connections during training. "Dynamic sparse training methods relax the fixed-mask assumption by evolving sparsity patterns during training."
- Entropy-based pruning: Pruning guided by entropy measures of activations or filters to remove less informative parameters. "proposed entropy-based approaches to guide pruning."
- Hadamard product: Element-wise multiplication of tensors used to apply binary masks to parameters. "where denotes the Hadamard product."
- Heterogeneous data: Data with diverse distributions or regimes that benefit from specialized models or subnetworks. "ignoring the inherent heterogeneity of real-world data."
- Implicit Neural Representations (INRs): Neural networks that represent signals by mapping coordinates to values without explicit discretization. "(iii) implicit neural representations (INRs) with within-image semantic specialization"
- Iterative Magnitude Pruning (IMP): An algorithm that repeatedly trains and prunes low-magnitude weights, often with weight or learning-rate rewinding. "Iterative Magnitude Pruning (IMP) emerged as a practical algorithm for identifying winning tickets"
- Jaccard similarity (IoU): Intersection-over-Union measure quantifying overlap between two masks or sets. "average Jaccard similarity (IoU) to all other subnetworks."
- Joint retraining: A phase where multiple subnetworks are retrained together on their respective subsets while sharing the same parameter tensor and masks. "we perform a lightweight joint retraining phase to refine subnetwork performance and reinforce specialization."
- Learning rate rewinding: Resetting the learning rate schedule (or optimizer state) during pruning/fine-tuning to improve training stability or performance. "learning rate rewinding \cite{Renda2020}"
- Lottery Ticket Hypothesis (LTH): The hypothesis that large networks contain sparse “winning tickets” that can train to match dense-model performance. "the Lottery Ticket Hypothesis posits that large networks contain sparse subnetworks, or winning tickets, that can be trained in isolation to match the performance of their dense counterparts."
- Mask-based routing: Selecting subnetworks by applying learned binary masks rather than using separate routing networks. "maintaining a single compact backbone and employing a mask-based routing to enable context-aware inference."
- Mixture-of-Experts (MoE): Conditional computation architectures that route inputs to expert subnetworks via learned gating. "offering a lightweight and interpretable alternative to Mixture-of-Experts (MoE) architectures"
- Network sharpness: A property of the loss landscape related to curvature that influences robustness and pruning limits. "identifying two key factors that determine the pruning ratio limit, i.e., weight magnitude and network sharpness"
- Optimal Brain Damage: A classical sensitivity-based pruning method that removes parameters based on their estimated impact on loss. "sensitivity-based methods like Optimal Brain Damage \cite{LeCun1989}"
- Optimal Brain Surgeon: A second-order pruning method using Hessian information to remove parameters with minimal loss increase. "Optimal Brain Surgeon \cite{Hassibi1993}"
- Oversparsification: Pruning too aggressively, causing performance degradation or collapse of specialization. "introduce a subnetwork similarity score that enables label-free diagnosis of oversparsification."
- Peak Signal-to-Noise Ratio (PSNR): A reconstruction-quality metric used to evaluate image fidelity. "Reconstruction quality is evaluated using peak signal-to-noise ratio (PSNR)"
- Scale-Invariant Signal-to-Noise Ratio Improvement (SI-SNRi): A metric for speech enhancement measuring improvement in scale-invariant SNR. "achieve higher SI-SNRi than universal or independent baselines."
- Semantic alignment: The correspondence between learned subnetwork structures and semantic relationships in data. "Subnetwork collapse and semantic alignment"
- Semantic clustering: Grouping classes into clusters based on semantic similarity (e.g., text embeddings) to define specialization subsets. "group the 100 classes into 8 coarse semantic clusters using an unsupervised text-based clustering procedure."
- Semantic segmentation: Partitioning an image into regions labeled with semantic categories. "Semantic segmentation masks define region-level classes"
- Sensitivity-based regularization: A regularization technique that penalizes neuron sensitivity to encourage structured sparsity. "introduced sensitivity-based regularization of neurons to learn structured sparse topologies"
- Subnetwork collapse: A failure mode where pruned subnetworks become overly overlapping, causing a sharp performance drop. "we identify subnetwork collapse, a performance drop under aggressive pruning"
- Subnetwork similarity score: A measure of similarity between subnetworks (e.g., their masks) used to diagnose specialization and collapse. "introduce a subnetwork similarity score that enables label-free diagnosis of oversparsification."
- Unstructured pruning: Removing individual weights without enforcing removal of whole filters, channels, or layers. "unstructured pruning removes non-relevant weights without imposing structural constraints, i.e., without removing entire layers."
- Variational dropout: A Bayesian dropout method that can induce sparsity by learning dropout rates per weight. "extended variational dropout in order to sparsify deep neural networks"
- WordNet path similarity: A semantic similarity metric based on shortest-path distances in the WordNet graph. "WordNet path similarity (top) and RTL mask similarity matrices for shallow (middle) and deep (bottom) layers."
Collections
Sign up for free to add this paper to one or more collections.