Discovering Hidden Gems in Model Repositories
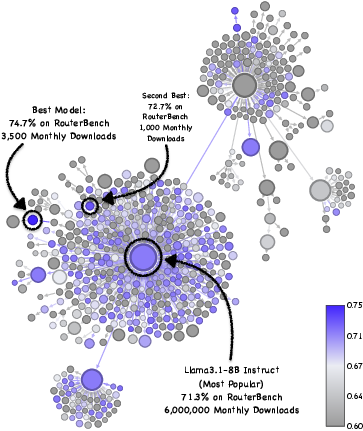
Abstract: Public repositories host millions of fine-tuned models, yet community usage remains disproportionately concentrated on a small number of foundation checkpoints. We investigate whether this concentration reflects efficient market selection or if superior models are systematically overlooked. Through an extensive evaluation of over 2,000 models, we show the prevalence of "hidden gems", unpopular fine-tunes that significantly outperform their popular counterparts. Notably, within the Llama-3.1-8B family, we find rarely downloaded checkpoints that improve math performance from 83.2% to 96.0% without increasing inference costs. However, discovering these models through exhaustive evaluation of every uploaded model is computationally infeasible. We therefore formulate model discovery as a Multi-Armed Bandit problem and accelerate the Sequential Halving search algorithm by using shared query sets and aggressive elimination schedules. Our method retrieves top models with as few as 50 queries per candidate, accelerating discovery by over 50x.
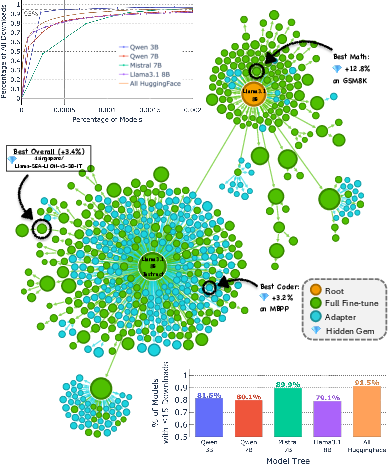
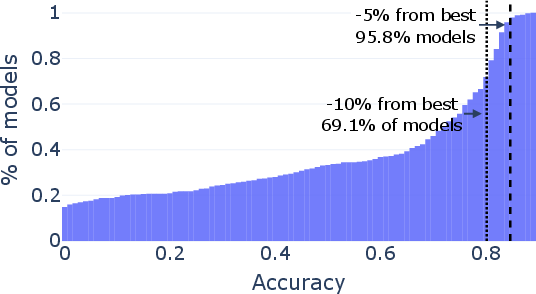
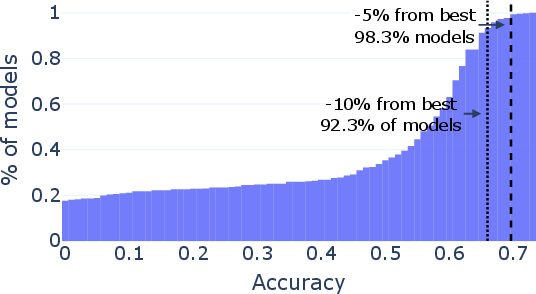
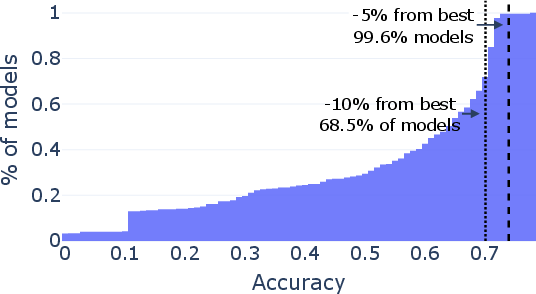
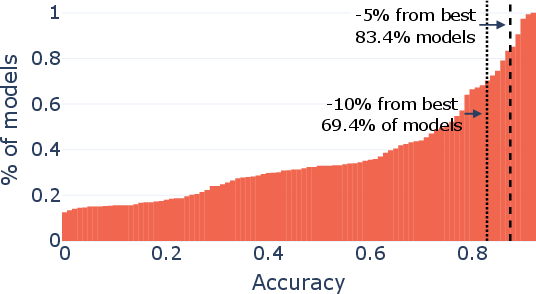
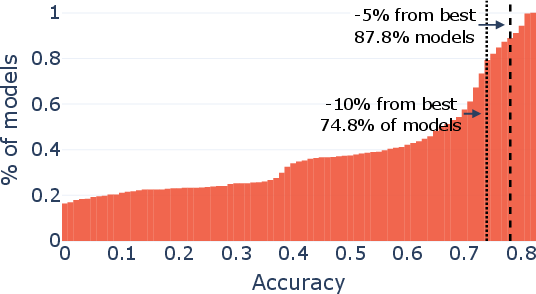
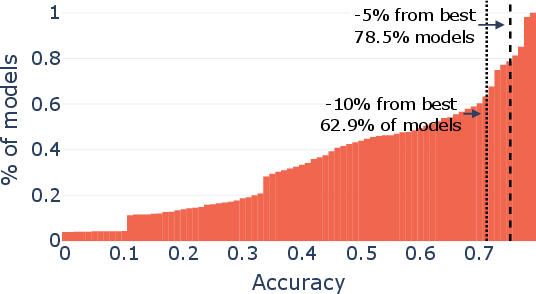
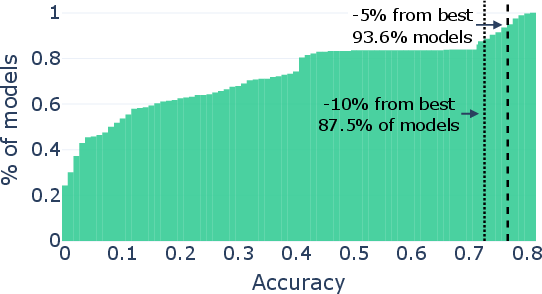
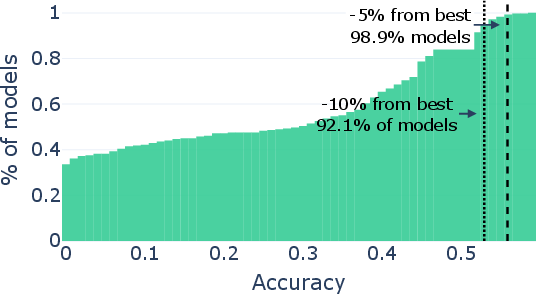
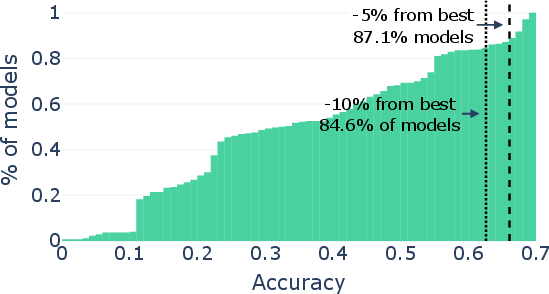
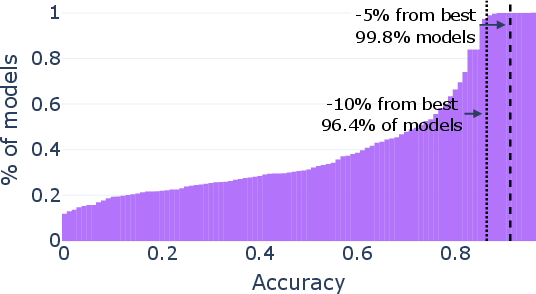
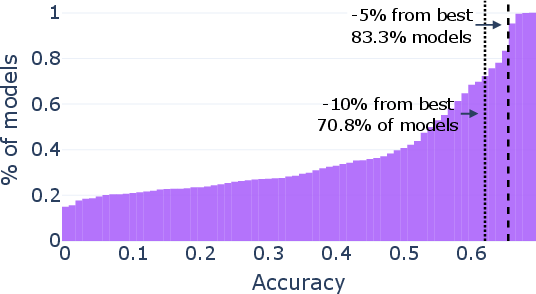
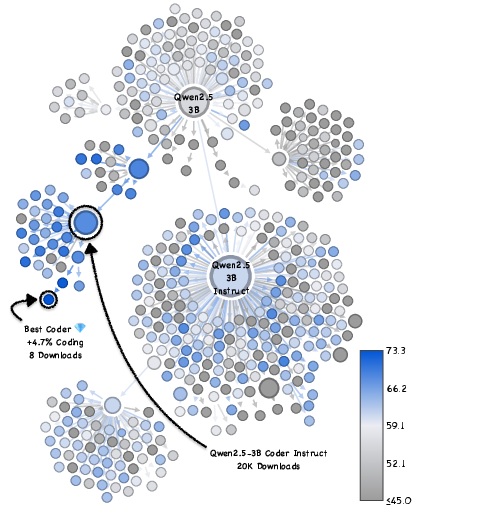
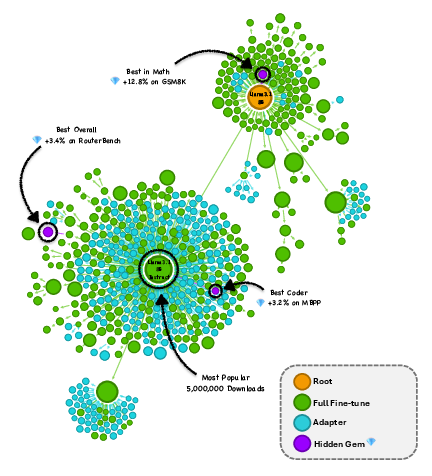
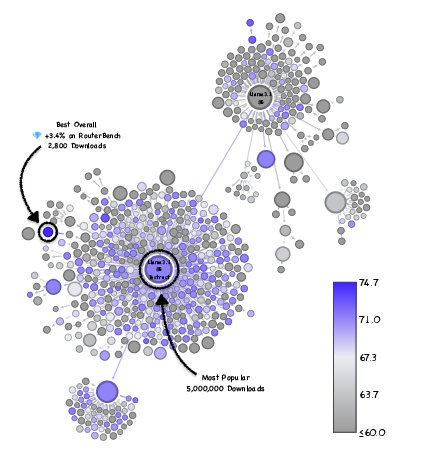
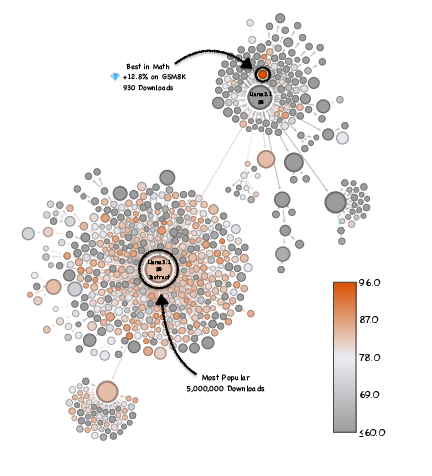
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A Simple Summary of “Discovering Hidden Gems in Model Repositories”
1) What is this paper about?
This paper looks at giant online libraries of AI models (like Hugging Face) where people can download and use different versions of LLMs. Even though there are millions of models, most people pick the same few “famous” ones. The authors ask: are those popular models really the best, or are better models being ignored?
2) What questions did the researchers ask?
- Are the most-downloaded models actually the top performers?
- If not, can we find the best models efficiently without testing every single one (which would take forever and cost a lot)?
3) How did they study it? (Methods in everyday language)
Think of the model library like a huge music app. Most people play the top hits, but there might be amazing songs hidden deeper in the catalog. The researchers:
- Tested over 2,000 models from several “families” (called model trees). A model tree is like a family tree: all the models come from the same “parent” and are slightly adjusted (fine-tuned) for different skills.
- Gave models a mix of tests (like school exams) that check different skills:
- General knowledge and understanding
- Logic and reasoning
- Coding
- Math word problems
- They bundled many tests together (similar to a combined report card) so each model got a fair, broad evaluation.
- Kept the “price per test” the same by comparing models from the same family, so differences came from ability, not from size or cost.
But testing every model on every question is too expensive. So they used a smart search strategy:
- Multi-Armed Bandit (MAB): Imagine a room full of slot machines, each machine pays out differently. Your job is to find the best machine without playing all of them too many times. Here, each “machine” is a model; each “pull” is asking it a question; a “reward” is getting the answer right.
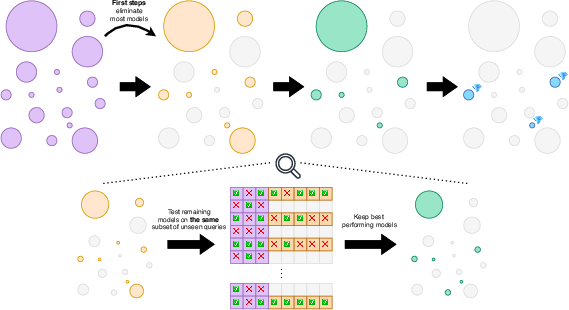
- Best Arm Identification with Sequential Halving:
- Like a tournament: in round 1, every model gets a small, equal set of questions. The worst half are dropped.
- In the next rounds, the remaining models get more questions, and you keep eliminating the bottom half until a winner remains.
- Two tricks made this faster and fairer:
- Correlated sampling: everyone answers the same exact questions in each round, like a standardized quiz. That way, one model doesn’t get easy questions while another gets hard ones.
- Aggressive early elimination: quickly cut out obviously weak or broken models so you spend most of your time comparing the good ones.
This approach lets them find top models using as few as about 50 questions per model—much faster and cheaper than testing everything.
4) What did they find, and why does it matter?
They found many “hidden gems”: lesser-known models that beat the popular ones—even by a lot—without costing more to run.
Here are a few key takeaways:
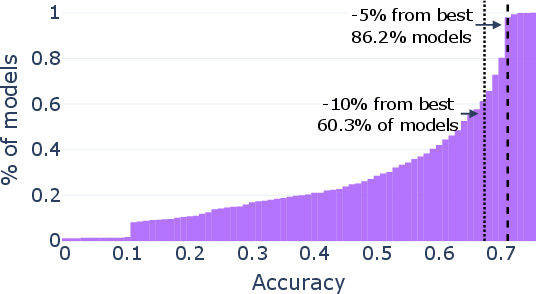
- Popularity ≠ performance. A tiny fraction of models get most downloads, but some rarely-downloaded models score higher on tough tests.
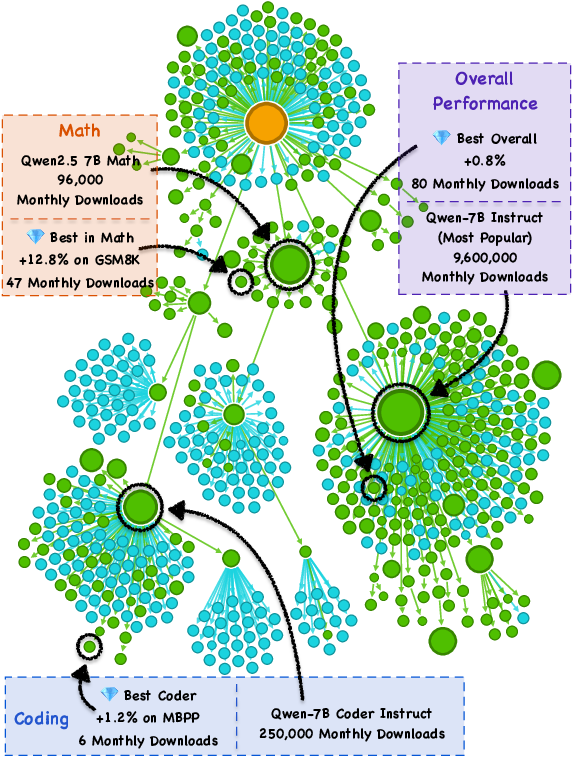
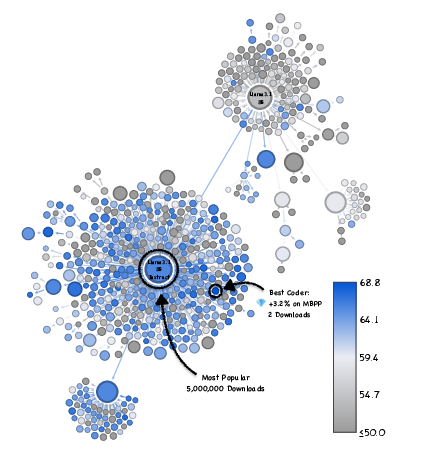
- Big example: within the Llama-3.1-8B family, they found rarely-downloaded versions that boosted math accuracy from about 83% to 96%—with the same compute cost.
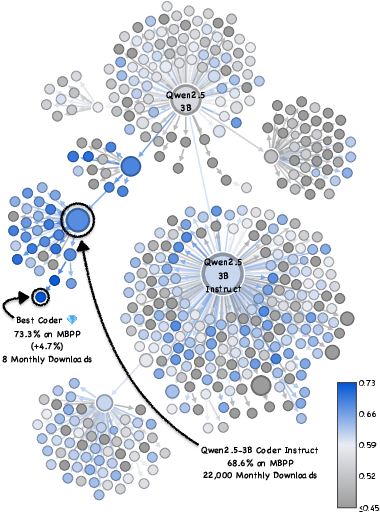
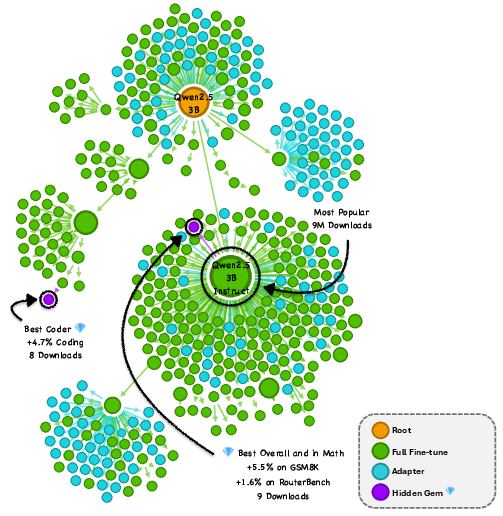
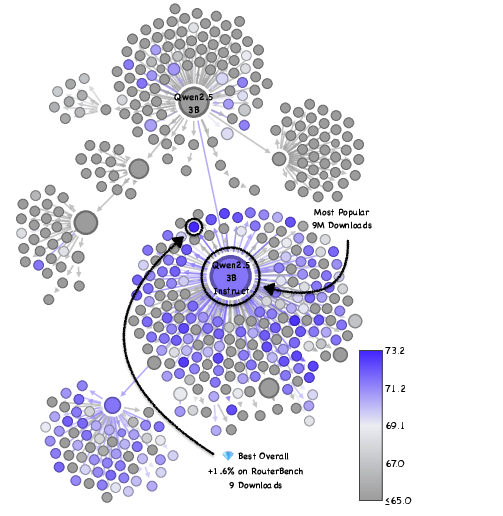
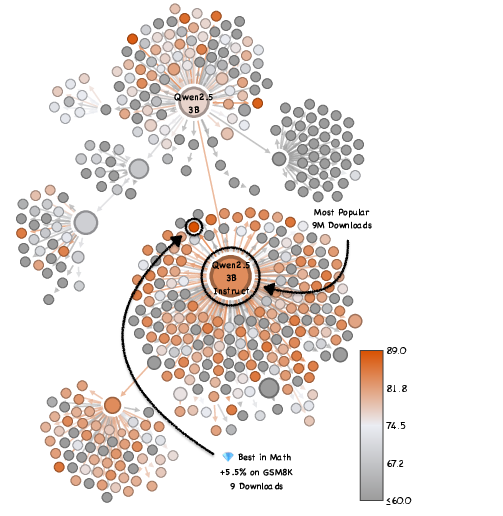
- This wasn’t a one-off. They saw similar hidden gems in other model families (like Qwen and Mistral), across several skills (coding, math, general knowledge).
- Why are they missed? Most “model cards” (the documentation pages) don’t clearly show strengths on specific tasks, so users can’t tell which model is great for, say, math or coding. Also, good models are not conveniently clustered in obvious places in the family tree—so simple “pick the most popular” or “closest to the root” strategies often fail.
Their search method worked well:
- With about 50 questions per model, their approach found top-3 models while using over 50× less testing than a full exhaustive evaluation.
- On average, it picked models that performed about 4.5% better than the popular baselines.
5) What could this change in the real world?
- Better results for everyone: Teams and developers could get stronger models for their specific tasks (like math help, coding assistance, or reasoning) without extra cost.
- Time and money saved: Instead of testing thousands of models, people can use this fast method to find great options quickly.
- Fairer visibility: Lesser-known but excellent models could finally get used more, not just the famous ones.
- Smarter model hubs: Repositories could add tools like this to help users discover top models for their needs, even when documentation is incomplete.
In short: there really are hidden gems in big model libraries, and the paper shows a fast, practical way to find them—so we don’t have to settle for the most popular choice when a better one is just a smart search away.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to be actionable for future research.
- External validity across the broader ecosystem: The study evaluates ~2,000 models from four LLM families (Qwen-3B/7B, Mistral-7B, Llama-3.1-8B). It remains unknown whether “hidden gems” exist to the same extent across other sizes (e.g., ≥70B), modalities (vision, speech, diffusion), architectures (Mixture-of-Experts, transformers with long-context extensions), and non-LLM domains.
- Popularity proxy fidelity: Download counts are used to define “Popular Consensus,” but may not reflect true usage (e.g., mirrors, CI pulls, caching, bots, time-window effects). Rigorous auditing and alternative usage signals (e.g., API call telemetry, space forks, citation/reference counts) are needed to validate the popularity-performance relationship.
- Stability and temporality of “gems”: The paper does not analyze whether identified gems persist over time (as downloads and new uploads change). Longitudinal tracking is needed to assess gem stability, discovery latency, and churn.
- Representativeness of evaluation data: RouterBench_s is a 2,500-query subsample; the sampling scheme, coverage, and per-task weighting are not validated for rank preservation. How small can a query set be while maintaining reliable rankings across diverse tasks?
- Statistical significance and uncertainty: The paper reports accuracy differences without confidence intervals or significance tests. Methods to quantify uncertainty (e.g., bootstrapping, Bayesian credible intervals) and to robustly decide dominance under tight budgets are missing.
- Reward modeling limitations: Best-Arm Identification uses binary correctness, while many tasks warrant partial credit or continuous metrics (e.g., BLEU, Rouge, code coverage, reasoning chains). How do non-binary rewards change algorithm choice, variance, and elimination schedules?
- Sensitivity to inference settings: Prompt formatting, decoding parameters (temperature, top-p), stop sequences, and tool availability can materially change rankings. The paper does not report sensitivity analyses or robustness to standardized vs. vendor-specific inference pipelines.
- Contamination and benchmark gaming: No checks for benchmark leakage or targeted fine-tuning on the evaluation queries are reported. Mechanisms for contamination detection, adversarial robustness, and query privacy in discovery pipelines are needed.
- Generalization beyond evaluated tasks: “Overall” performance is based on RouterBench aggregation; users often have domain-specific objectives (e.g., legal, biomedical, multilingual). How to customize discovery to user-specific task mixtures and apply multi-objective optimization (accuracy, latency, safety)?
- Safety, reliability, and ethics: The selection focuses on accuracy; toxicity, jailbreak susceptibility, harmful content, calibration, and fairness are not evaluated. A practical discovery system must incorporate safety/risk metrics and licensing constraints.
- Equality of inference cost assumptions: Comparing within model trees is intended to equalize inference cost, but quantization, KV-caching behavior, context windows, tokenizer differences, and memory footprint are not measured. A principled, empirical cost model (latency, memory, throughput) is missing.
- Cross-tree and cross-architecture search: Discovery is confined within “Model Trees.” Many uploads lack clear lineage or mix adaptations (LoRA merges, adapters). Methods to do cross-tree discovery, lineage recovery, and deduplication at scale are not addressed.
- Prevalence characterization: The paper shows existence of gems but does not quantify their prevalence distributions (e.g., per tree, per task, per parameter size) nor identify systematic correlates (training recipe, dataset, adapter type) that predict gem likelihood.
- Query selection integration: Authors note their method can be paired with query selection techniques, but do not explore adaptive or task-aware query selection. How to design minimal, high-coverage query sets that retain ranking fidelity under correlated sampling?
- Theoretical guarantees for modifications: Correlated sampling and aggressive elimination to a fixed pool (e.g., 100) are domain-specific changes to Sequential Halving. Formal analysis of sample complexity, failure modes under heterogeneous task difficulty, and optimal elimination schedules is missing.
- Scalability to millions of models: Even with 50 queries per candidate, evaluating millions of checkpoints is expensive. How to combine bandit-based discovery with prefiltering (e.g., weight-space embeddings, lineage heuristics, metadata quality filters) to reduce K efficiently?
- Handling broken or misconfigured models: The paper mentions many uploads are “low-quality or broken” without formal criteria. Automatic detection, triaging, and normalization of incompatible tokenizers, missing files, or misaligned generation settings are needed.
- Hyperparameter fairness across baselines: Comparative baselines (UCB variants, TTTS, Successive Rejects, BayesElim, SH) may be sensitive to hyperparameters and priors. A standardized tuning protocol or regret-based fairness analysis is needed to ensure apples-to-apples comparisons.
- Aggregation choices in RouterBench: Task weights and aggregation strategy are not justified. Investigate alternative aggregation schemes and task-specific discovery (e.g., math-only, coding-only) with principled weighting based on user requirements.
- Ensemble and routing opportunities: The method identifies a single best model, but mixture-of-experts routing or model soups can exceed single-model performance. Explore discovery methods that select sets of complementary models and evaluate router performance vs. single best.
- Multilingual and domain specialization: Most evaluated tasks are English-focused and general-purpose. Assess gem presence and discovery efficacy in multilingual, domain-specialized corpora (legal, medical, financial), and low-resource languages.
- Extreme low-budget regimes: Budgets of N∈{10,50} queries per model are tested; the limits of discovery for N<10 (e.g., 1–5 queries) are unexplored. Characterize rank reliability and necessary conditions for success in ultra-low-budget scenarios.
- Robustness to near-duplicates and merges: Many hub models are minor variants, merges, or quantized clones. Deduplication, provenance verification, and “equivalence class” handling are not studied, potentially inflating K and skewing rankings.
- Impact of licensing and governance: Discovery ignores licensing terms, usage restrictions, and governance signals that affect deployability. Integrate license compliance and trust metadata into discovery and ranking.
- Intervention design for documentation gaps: The paper notes that ~90% of gems lacked relevant performance documentation but does not propose mechanisms to improve it. Explore automated documentation generation, verification, and incentives to surface true capabilities.
- Causal drivers of popularity vs. performance: The centralization of downloads is described but not causally analyzed. Identify platform UX, social proof, search ranking, and organizational constraints that drive popularity; test interventions to reduce information asymmetry.
- Practical deployment pipelines: Transitioning from discovery to production (monitoring drift, safety guardrails, routing, rollback) is not addressed. Define end-to-end operational workflows for adopting discovered gems.
- Reproducibility and openness: Beyond a project page, the paper does not detail full code, evaluation prompts, and model lists. Open-sourcing pipelines, seeds, and query sets is needed for independent verification and extension.
Practical Applications
Overview
This paper shows that public model hubs (e.g., Hugging Face) systematically overlook “hidden gems”: little-used fine-tunes that outperform popular base models at the same inference cost. It provides a practical discovery method—an accelerated, budgeted Sequential Halving approach with correlated sampling and aggressive early elimination—that finds top models with as few as 50 queries per candidate (over 50× faster than exhaustive evaluation). Below are concrete applications that leverage these findings and methods.
Immediate Applications
- Bold replacement of default base models with discovered fine-tunes (software, enterprise AI, education, finance, customer support)
- Swap widely used base LLMs with discovered gems to obtain large accuracy gains at identical inference cost (e.g., Llama-3.1-8B math from 83.2% to 96.0%).
- Potential tools/workflows: “GemFinder” CLI/service; CI/CD gate that periodically scans model trees and auto-suggests replacements.
- Dependencies/assumptions: Representative task-specific evaluation prompts; model licensing compatibility; reproducible inference settings; on-premise or API access to candidates.
- Rapid model evaluation pipelines for MLOps (software, platform engineering)
- Integrate the bandit-based search (correlated sampling + aggressive elimination) into model onboarding pipelines to select the best candidate per use case under fixed budgets.
- Potential tools/workflows: MLOps step that runs N=10–50 queries per model, auto-prunes, and registers winners into a model registry.
- Dependencies/assumptions: Access to model trees; deterministic evaluation configs; small but reliable evaluation sets.
- Internal leaderboards without exhaustive testing (academia, startups, labs)
- Build “micro-leaderboards” that rank large pools of candidates with only tens of queries each, avoiding costly full-benchmark sweeps.
- Potential tools/workflows: TinyBenchmarks + correlated sampling; scheduled retrials as repos update.
- Dependencies/assumptions: Carefully curated small query sets; attention to overfitting and variance control.
- Smarter multi-LLM routing via expert selection (software, tooling)
- Use the method to select top specialists (math, coding, reasoning) within a model family as router experts.
- Potential tools/workflows: Router training that starts from a gem set; periodic re-discovery as new fine-tunes appear.
- Dependencies/assumptions: Stable skill-specific evaluation prompts; routing logic integration; monitoring to avoid regressions.
- Cost savings in model procurement and vendor evaluation (finance, healthcare, legal, enterprise IT)
- Replace manual or full-benchmark proof-of-concept evaluations with fixed-budget bandit search to lower time and compute costs.
- Potential tools/workflows: Procurement checklist that mandates a “market scan” against candidate fine-tunes; audit logs of evaluation runs.
- Dependencies/assumptions: Secure evaluation sandbox; data privacy compliance; clear acceptance thresholds.
- Repository-side recommendations and ranking signals (platforms, marketplaces)
- Hubs can run continuous budgeted discovery to surface “hidden gems” on model pages and search results.
- Potential tools/workflows: “Gem badge” and “Top-in-tree for task X” signals; model tree-aware recommendations.
- Dependencies/assumptions: Platform compute budget; fair scheduling; deduplication of near-identical fine-tunes.
- Developer productivity tools that auto-pick better assistants (software, daily life)
- VSCode/JetBrains extensions or CLI that take a few representative prompts, scan a model tree, and configure the best local or API-based assistant.
- Potential tools/workflows: One-click “Find my best coder/math tutor” using N=50 queries per candidate.
- Dependencies/assumptions: API rate limits; local GPU or hosted inference; cached evaluations for speed.
- Upgrade domain chatbots and RAG systems without higher serving cost (customer support, e-commerce, internal knowledge bases)
- Use discovered gems that outperform popular instruct models but keep the same latency and hardware footprint.
- Potential tools/workflows: Upgrade pipeline that A/B tests a small evaluated shortlist in production.
- Dependencies/assumptions: Domain-aligned evaluation prompts; guardrails and monitoring for safety and drift.
- Energy and cost-efficient benchmarking (energy, sustainability, research ops)
- Cut evaluation energy consumption by >50× during model selection; reallocate compute to later-stage validation only for finalists.
- Potential tools/workflows: Green AI reporting that includes “evaluation energy per candidate” metrics.
- Dependencies/assumptions: Accurate logging of energy/compute; acceptance of probabilistic ranking under small budgets.
- Safety- and risk-aware model selection (responsible AI, governance)
- Extend the search framework with additional “reward” definitions (e.g., hallucination rates, toxicity) to select safer gems under fixed budgets.
- Potential tools/workflows: Multi-objective evaluation where correctness, safety, and license constraints filter candidates.
- Dependencies/assumptions: Availability of compact safety test suites; consistent safety inference configs; policy-aligned thresholds.
Long-Term Applications
- Platform-level discovery services embedded in model hubs (platforms, marketplaces)
- Always-on “Discovery-as-a-Service” that continuously scans incoming uploads to surface tree-level top performers per task.
- Potential tools/workflows: Public gem indices; time-series “best of month” lists per domain.
- Dependencies/assumptions: Sustained compute; governance for equitable exposure; mitigation of gaming/overfitting.
- Standardized model tree metadata and lineage tracking (policy, ecosystem infrastructure)
- Formalize Model Tree identifiers and provenance fields so discovery runs are scoped correctly and comparable across forks/derivatives.
- Potential tools/workflows: Schema updates to model cards; lineage APIs; third-party lineage attestations.
- Dependencies/assumptions: Community adoption; platform support; consistent inheritance conventions.
- Continuous enterprise “model catalog” curation (enterprise AI, IT asset management)
- Autonomous jobs that scan new uploads weekly, update internal catalogs, and recommend safe, superior swaps for production tasks.
- Potential tools/workflows: Scheduled crawlers; governance reviews; shadow deployments with telemetry.
- Dependencies/assumptions: Legal review of licenses; data privacy controls; change management processes.
- Dynamic routing and ensembles of fine-tunes (software, research)
- Build mixtures of fine-tunes discovered via bandit search; optionally merge compatible weights for single-pass ensembles.
- Potential tools/workflows: Ensemble builders; ties-merging/model-soup pipelines seeded by gems.
- Dependencies/assumptions: Compatibility between fine-tunes; careful evaluation of interference; serving complexity budget.
- Cross-modal extension to vision, speech, and diffusion (media, robotics, creative tools)
- Apply correlated sampling + aggressive elimination to find best LoRAs/adapters/checkpoints for generation and perception tasks.
- Potential tools/workflows: Adapter discovery for diffusion (e.g., style/content adapters); best-policy selection for robotics planners.
- Dependencies/assumptions: Task-appropriate micro-benchmarks; unified inference interfaces; domain-specific reward definitions.
- Regulatory guidance for model selection due diligence (policy, compliance)
- Encourage/require fixed-budget, structured discovery rather than defaulting to popularity for safety-critical deployments.
- Potential tools/workflows: Audit-ready logs of search, candidate sets, and selection criteria; benchmarks transparency.
- Dependencies/assumptions: Sector-specific standards (e.g., healthcare, finance); third-party verification.
- Evaluation-as-a-Service and “gem indices” markets (software, ecosystem)
- Offer hosted discovery with curated prompt sets per vertical, producing paid shortlists and periodic updates.
- Potential tools/workflows: Vertical-specific indices (coding, math, legal); alerts on new outperformers.
- Dependencies/assumptions: Trust in provider’s methodology; data coverage; SLAs for latency and privacy.
- On-device/edge auto-discovery for specialized hardware (mobile, robotics, IoT)
- Local discovery among small fine-tunes compatible with device constraints to maximize quality within strict latency/memory budgets.
- Potential tools/workflows: Embedded “model fitter” that runs tiny discovery on-device during setup.
- Dependencies/assumptions: Efficient on-device inference; energy constraints; small but representative local prompts.
- Hybrid weight-space and query-space screening (research, tooling)
- Pre-filter candidates using weight-based predictors or lineage priors, then run bandit discovery on a small shortlist.
- Potential tools/workflows: Weight-space embeddings + BAI; meta-learned priors by model family.
- Dependencies/assumptions: Availability of robust weight-space models; access to weights (not just APIs).
- Education and community challenges around “gem hunting” (academia, community)
- Competitions/courses where teams design tiny benchmarks and discovery strategies to uncover gems in different trees.
- Potential tools/workflows: Public leaderboards for discovery efficiency; open datasets of query sets and outcomes.
- Dependencies/assumptions: Community compute grants; fair rules against overfitting; reproducibility infrastructure.
- Safety- and domain-optimized governance catalogs (healthcare, legal, public sector)
- Long-lived catalogs of vetted gems with domain-specific safety, bias, and compliance tags; updated via continuous discovery.
- Potential tools/workflows: Sectoral registries (e.g., “clinical summarization gems”); integration into procurement portals.
- Dependencies/assumptions: Expert curation; regulatory review cycles; robust, representative test batteries.
These applications hinge on a few cross-cutting assumptions: access to comprehensive candidate sets within model trees; small but representative, non-leaky evaluation prompts; consistent, reproducible inference configurations (temperature, decoding); license and security vetting; and governance that balances rapid discovery with safety and fairness.
Glossary
- Aggressive Elimination Schedule: An early, high-pruning evaluation policy that removes many weak candidates in the first round to reallocate budget to promising ones. "Aggressive Elimination Schedule."
- Bayesian Elimination (BayesElim): A best-arm identification method that prunes candidates based on the posterior probability that they are optimal. "TTTS \citep{russo2016simple}, which uses top-two Thompson sampling, and Bayesian Elimination \citep{atsidakou2022bayesian}, which prunes based on posterior probabilities."
- Best-Arm Identification (BAI): A bandit objective focused on identifying the single best option (arm) under a fixed evaluation budget. "We frame this as a Fixed-Budget Best-Arm Identification \citep{audibert2010best} problem"
- Correlated Sampling: A variance-reduction technique where all surviving models are evaluated on the exact same queries to produce more reliable comparisons. "To mitigate this, we employ Correlated Sampling."
- Foundation checkpoints: Official base model checkpoints that serve as widely used baselines in public repositories. "Public repositories host millions of fine-tuned models, yet community usage remains disproportionately concentrated on a small number of foundation checkpoints."
- Hidden Gems: Unpopular fine-tuned models that significantly outperform the widely used, popular models within the same family. "We search for hidden gems by evaluating over $2,000$ models."
- Instruction fine-tuning: Specializing a base model to follow instructions by training on instruction–response data. "such as the official Qwen or Llama checkpoints or to its official instruction fine-tuning."
- Model cards: Standardized documentation pages that describe a model’s intended use, training data, and performance. "as model cards \citep{model_cards} are frequently incomplete or missing entirely"
- Model Tree: A lineage structure grouping fine-tuned models that share a common ancestor checkpoint. "the foundation model at the root of the Model Tree \citep{Horwitz_2025_CVPR}"
- Multi-Armed Bandit (MAB): A framework for sequential decision-making under uncertainty; here used for pure exploration to find the best model. "Concretely, we formulate model discovery as a Multi-Armed Bandit (MAB) problem"
- Pure exploration: A bandit setting where the goal is to learn the best option after exploration, rather than to maximize immediate cumulative rewards. "Unlike standard MAB, where an agent maximizes total reward during learning, our goal is pure exploration."
- RouterBench: An aggregate benchmark that combines diverse tasks (e.g., coding, reasoning) to assess general model quality. "we use RouterBench \citep{hu2024routerbench}, which aggregates diverse benchmarks including MBPP, Winograd, MMLU, ARC-Challenge, and GSM8K"
- Sequential Halving (SH): An elimination-based algorithm that allocates small budgets to all candidates, ranks them, and repeatedly halves the pool. "accelerate the Sequential Halving search algorithm by using shared query sets and aggressive elimination schedules."
- Simple regret: The performance gap between the selected model and the true best model after the evaluation budget is spent. "We aim to minimize the simple regret (gap between the chosen model and the best one) after the fixed budget is exhausted."
- Successive Rejects: An elimination algorithm for best-arm identification that removes the worst candidate in stages as more samples are collected. "Successive Rejects \citep{audibert2010best} and Sequential Halving \citep{karnin2013almost} iteratively eliminate the worst models."
- Top-two Thompson Sampling (TTTS): A Bayesian bandit strategy that alternates sampling between the two most promising candidates according to posterior probabilities. "TTTS \citep{russo2016simple}, which uses top-two Thompson sampling,"
- UCB (Upper Confidence Bound): A family of bandit algorithms that select options using optimistic estimates derived from confidence intervals. "UCB \citep{auer2002finite}, UCB-E \citep{audibert2010best}, and UCB-StdDev greedily sample based on upper confidence bounds."
- UCB-E: A UCB-style variant designed for exploration-focused settings like fixed-budget best-arm identification. "UCB \citep{auer2002finite}, UCB-E \citep{audibert2010best}, and UCB-StdDev greedily sample based on upper confidence bounds."
- UCB-StdDev: A UCB variant that incorporates empirical standard deviation to refine confidence bounds during selection. "UCB \citep{auer2002finite}, UCB-E \citep{audibert2010best}, and UCB-StdDev greedily sample based on upper confidence bounds."
Collections
Sign up for free to add this paper to one or more collections.