- The paper demonstrates that current AI-generated image detectors rely on global VAE artifacts instead of focusing on genuine inpainting manipulations.
- It introduces the INP-X pipeline, which restores unmasked image regions, forcing detectors to target only the localized synthetic content.
- Empirical evaluations reveal a severe drop in detection accuracy under INP-X, highlighting the vulnerability of existing forensic methods.
Overreliance on Global Artifacts in AI-Generated Image Detection: An Analysis of Inpainting Exchange
Introduction
This paper, "AI-Generated Image Detectors Overrely on Global Artifacts: Evidence from Inpainting Exchange" (2602.00192), interrogates the reliability of current deep-learning-based detectors for AI-generated (specifically, inpainted) images. The authors argue and empirically demonstrate that these detectors commonly exploit global artifacts introduced by the image synthesis pipeline—particularly those imposed by Variational Autoencoder (VAE) based generation—rather than identifying genuinely manipulated or inpainted content. This oversight in detector design facilitates trivial shortcut learning, undermining their purported robustness and generalization across diverse image domains and manipulation types.
The study introduces the Inpainting Exchange (INP-X) method, a surgical intervention that replaces unmasked regions of inpainted images with original image content, thereby preserving only the locally inpainted, synthetic content for detection analysis. The paper provides both theoretical underpinning and comprehensive empirical evaluation, including a newly curated 90K-image benchmark, to elucidate and quantify these vulnerabilities in existing detection and localization pipelines.
Theoretical Foundations: VAE-Driven Spectral Bias
The central claim is underpinned by a theoretical analysis showing that the VAE reconstruction mechanism—ubiquitous in latent diffusion models—acts as a global, high-frequency filter over the entire image. VAE encoding-decoding inevitably attenuates stochastic high-frequency components (e.g., sensor noise, PRNU) outside the masked region, even when the semantics are preserved. This induces a distributional shift detectable with high reliability by statistical or frequency-domain forensics, independent of actual content manipulation.
The authors formalize this phenomenon through two primary theoretical results:
- Variance Contraction in VAEs: High-frequency information present in real images, largely irrelevant to semantics but vital for authenticity verification, is suppressed by VAEs due to their information bottleneck.
- Divergence Reduction via Inpainting Exchange: By restoring original pixels outside the mask (INP-X), the global KL-divergence between manipulated and real image distributions is minimized—eliminating the dominant detection signal used by current models and forcing them onto the more challenging task of localized content analysis.
Empirical correlation analysis between VAE loss, inpainting difference maps, and high-frequency components substantiates the theoretical predictions. VAE-induced artifacts and inpainting errors exhibit strong structural and statistical alignment across datasets and models.
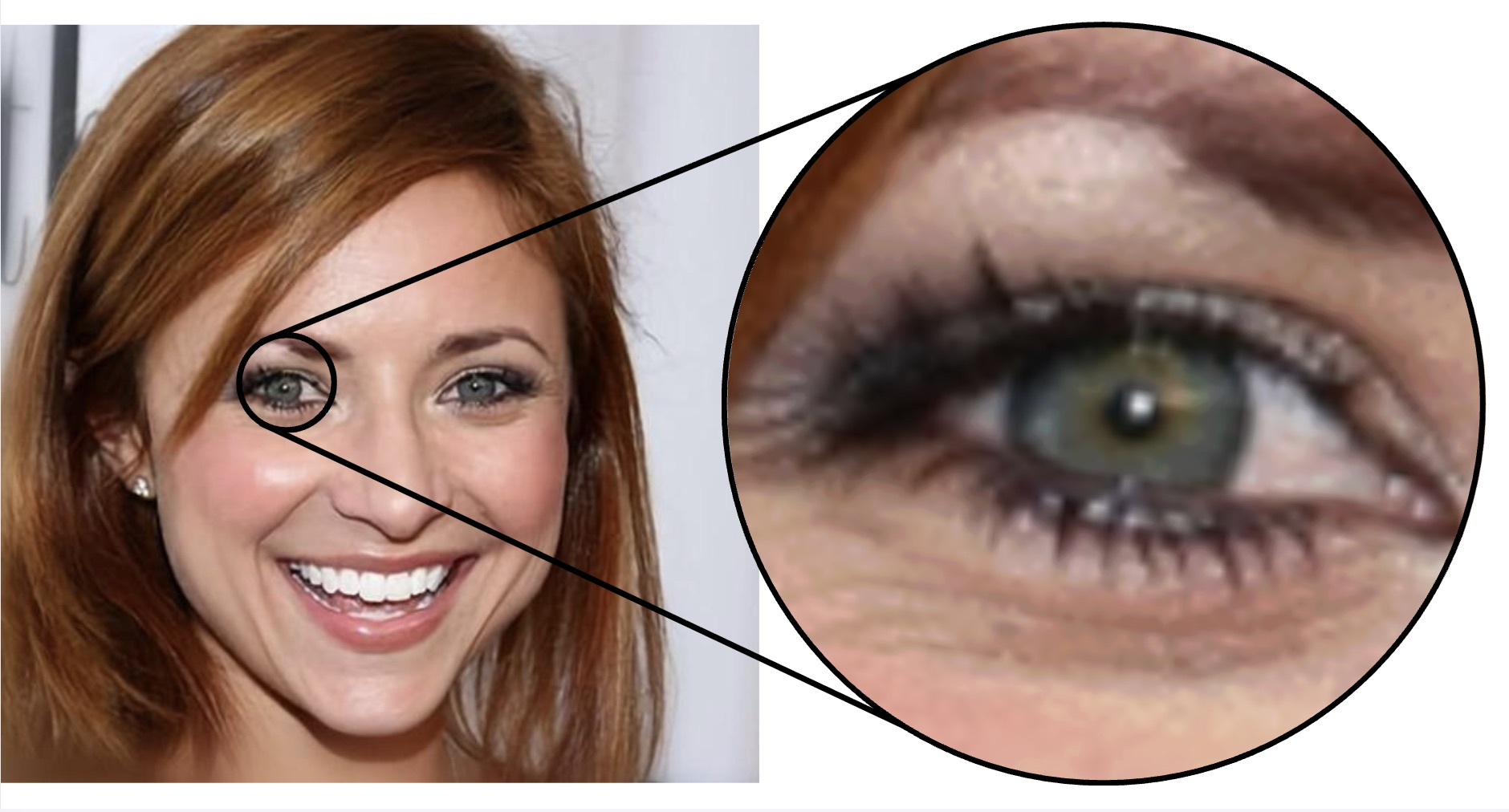
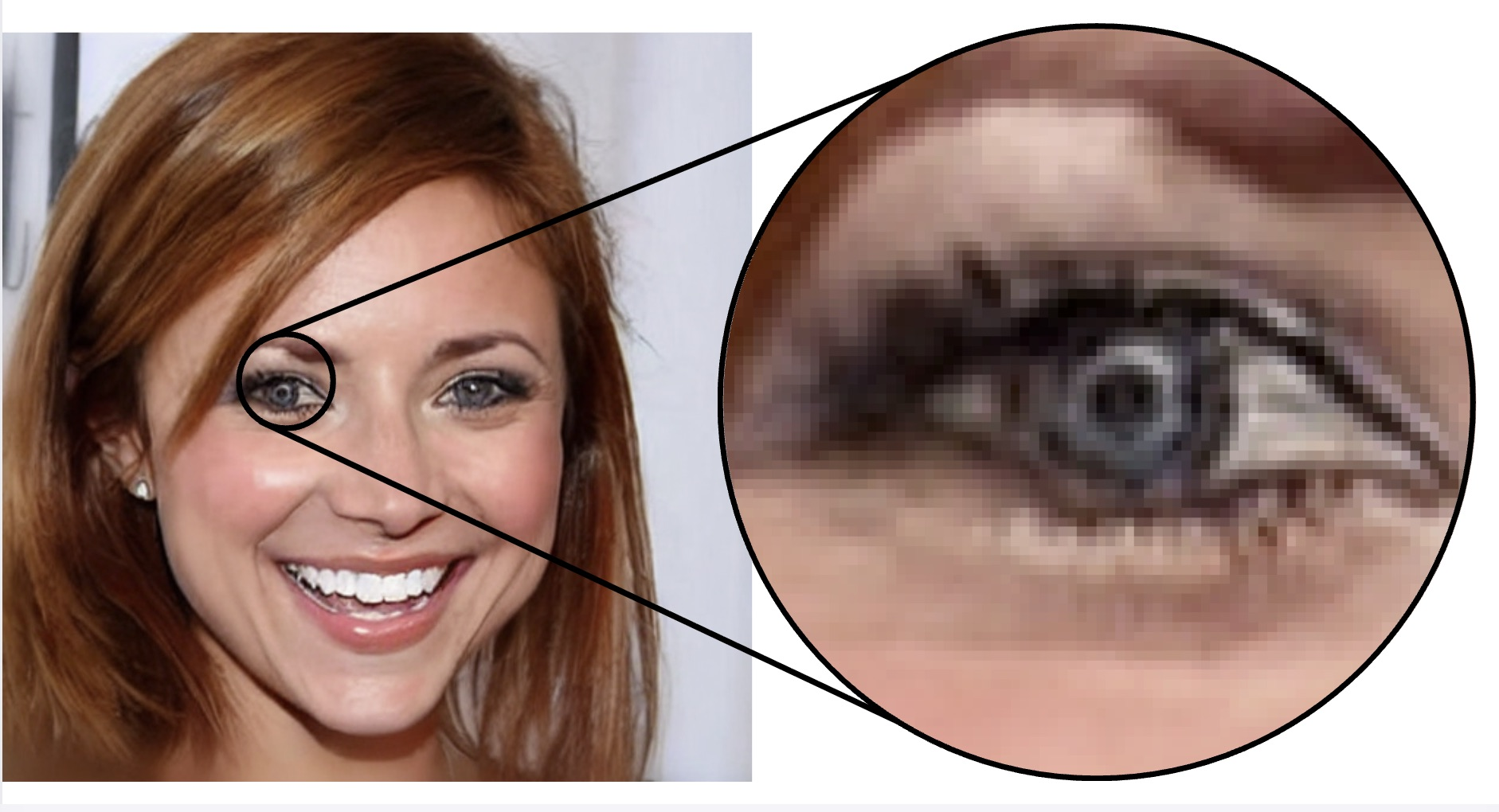
Figure 1: Even localized inpainting results in global pixel changes outside the mask, attributable to the VAE encoder-decoder, which are visually detectable in unmasked regions.

Figure 2: The inpainting error closely mirrors pure VAE reconstruction artifacts, confirming the global nature of the VAE fingerprint, regardless of local inpainting content.
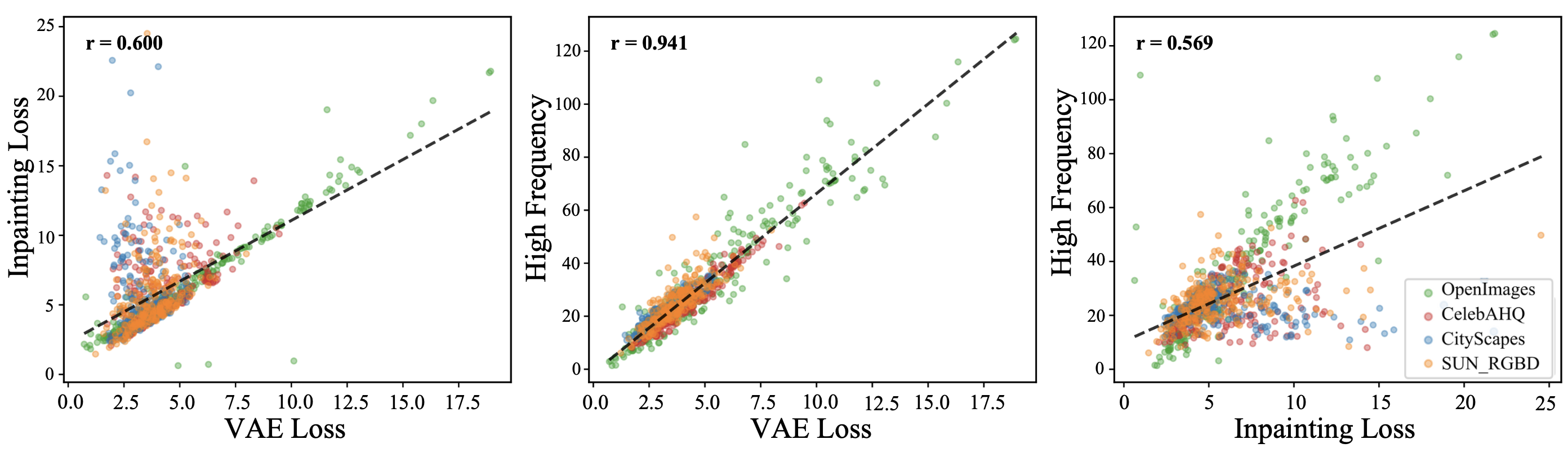
Figure 3: Strong image- and pixel-level correlations between VAE loss and inpainting artifacts quantify the dominant role of VAE-induced global noise in detection.
INP-X: Inpainting Exchange Pipeline
INP-X is designed to probe the detector's reliance on global artifacts by post-processing standard inpainted images: the unmasked pixels are copied from the original image, while only the inpainted (synthetic) mask region is retained. This leaves synthetic content strictly localized, while removing the global VAE fingerprint from the rest of the image.
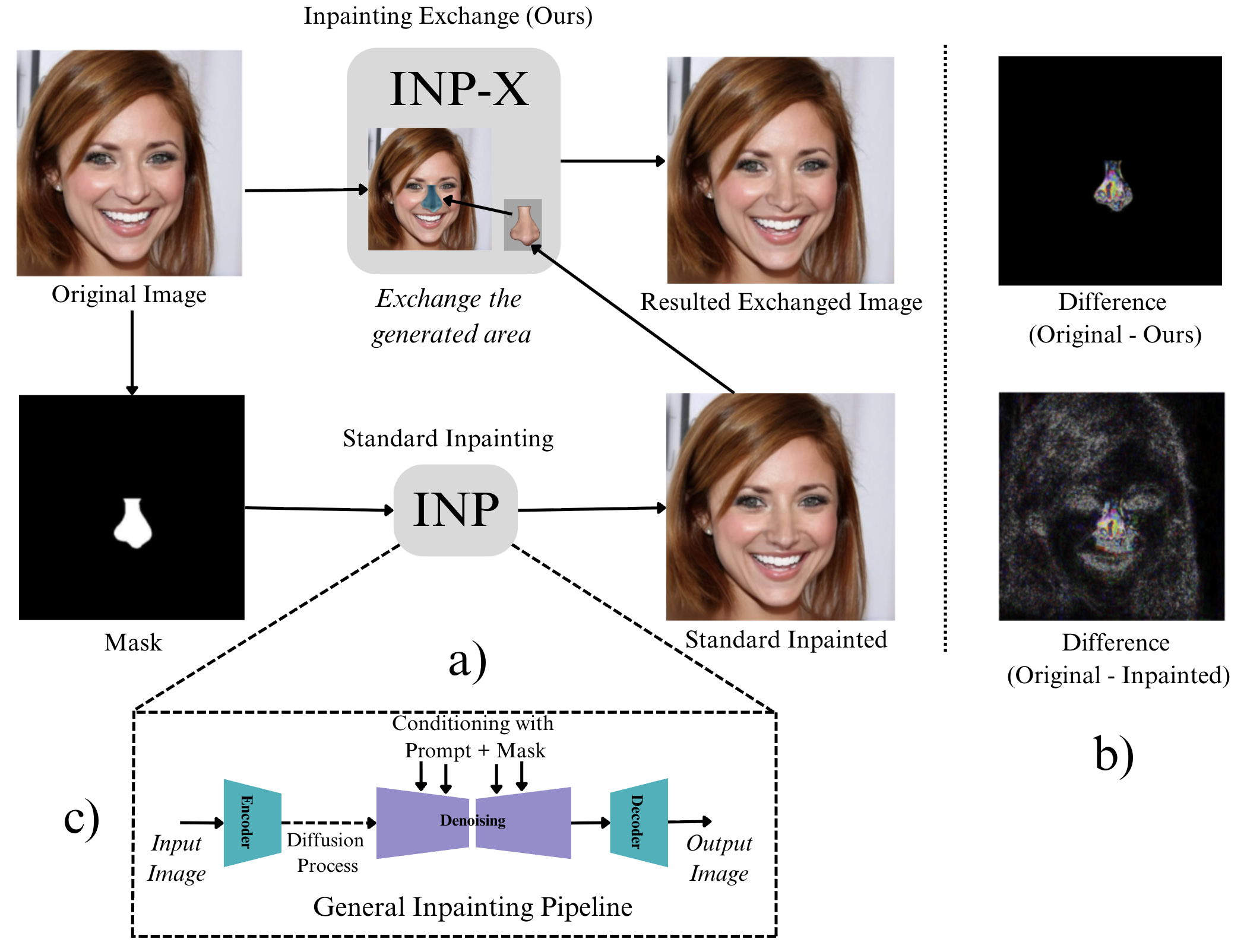
Figure 4: The INP-X pipeline: the unmasked part of an inpainted image is restored with the original, leaving only the synthesized mask region, enabling precise evaluation of detector focus on manipulation.
The contrast between standard inpainting (which alters the entire image via the VAE) and INP-X can be directly visualized in pixel-level difference maps, emphasizing the globality of standard artifacts versus the mask-bounded changes in INP-X.

Figure 5: Standard inpainting introduces image-wide pixel differences; INP-X confines the difference to the mask, isolating synthetic content effects.
Experimental Evaluation
Datasets and Benchmarks
The authors construct an extensive benchmark based on the Semi-Truths paradigm, spanning four datasets (CelebA-HQ, CityScapes, SUN-RGBD, OpenImages), three inpainting models, and 90K total images, incorporating real, standard-inpainted, and INP-X triplets for every source image.
Detector Evaluation
Pretrained detectors—11 open-source models and two commercial APIs (HiveModeration, Sightengine)—are evaluated for accuracy both on standard inpainting and on INP-X images. Under standard conditions, many detectors achieve high accuracy (>90% in several cases), corresponding closely to reported state-of-the-art results on fully synthetic images. However, when tested on INP-X, all detectors experience a severe performance collapse, often to near-chance (e.g., commercial APIs dropping from 91–92% to 55% accuracy). Performance metrics such as recall and F1 demonstrate the detectors are no longer able to reliably flag manipulated images when the global VAE fingerprint is eliminated by INP-X.
Detector Robustness and Localization
Robustness experiments under common corruptions (Gaussian blur, JPEG compression, localized light spots) reveal that detectors maintain high accuracy under these degradations, yet fail to handle INP-X. This underscores the specificity of their vulnerability to distributional shifts caused by restoration of high-frequency statistics in unmasked regions.
Fine-tuning detectors on INP-X images, rather than standard inpainted images, substantially improves their localization and generalization: models are forced to rely on learning local, content-specific artifacts. Yet, even in this setting, the detection task remains hard, with maximal achieved accuracy in the 70–75% range and significant localization improvement (increased mIoU and mAP) compared to standard-inpainting-trained baselines.
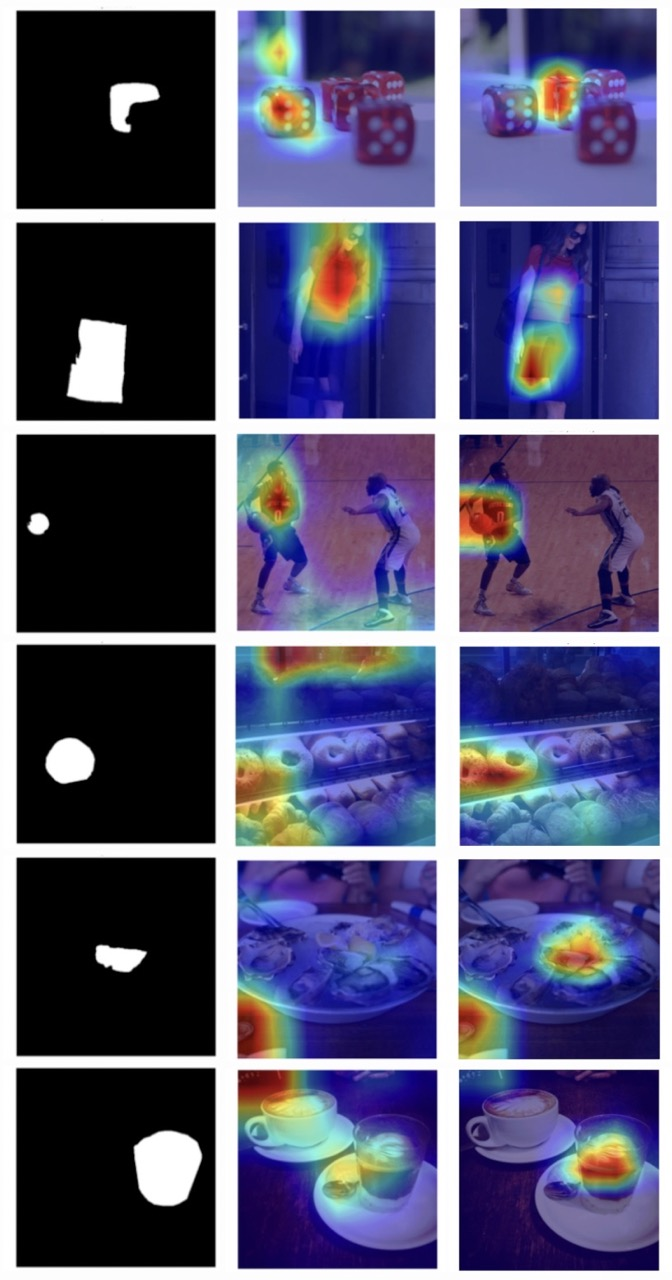
Figure 6: GradCAM visualizations show that standard inpainting detectors attend globally (left), whereas INP-X forces localization to the manipulated mask (right).
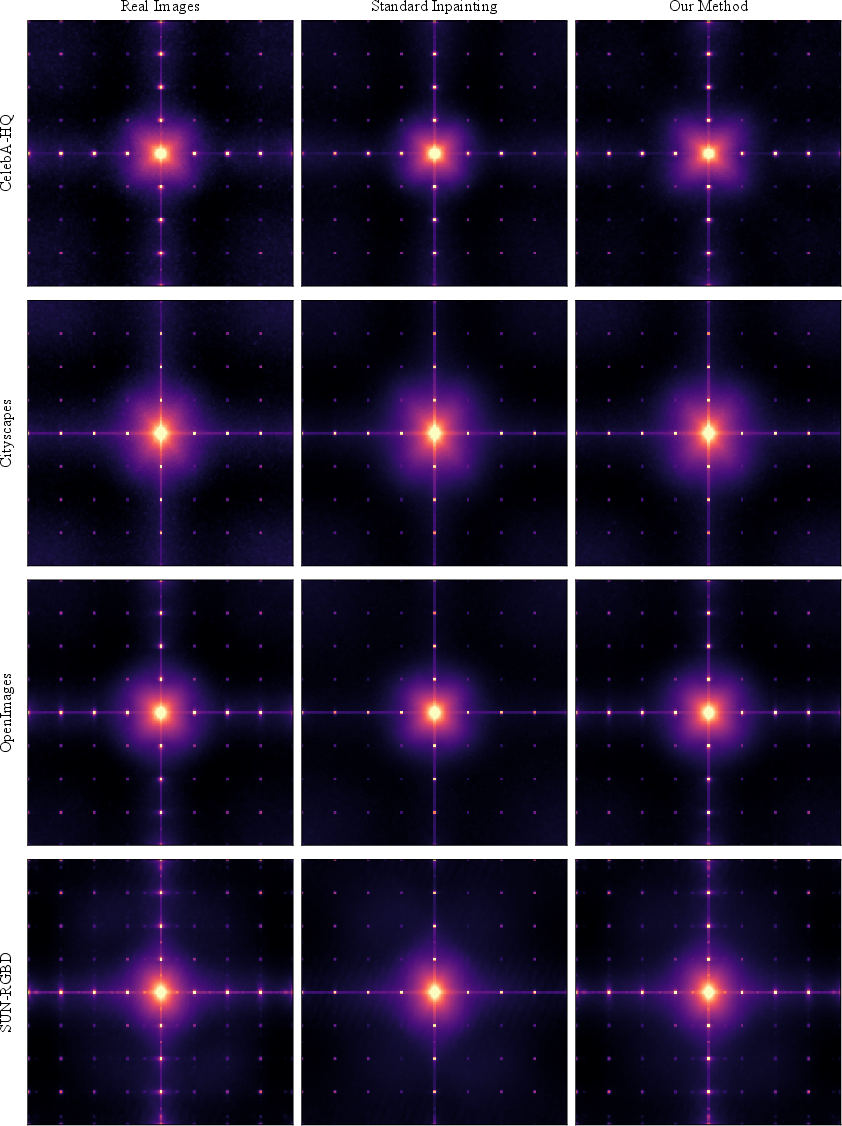
Figure 7: Frequency domain analysis confirms that standard inpainting introduces global spectral artifacts, clearly visible in FFT, which INP-X suppresses.
Spectral and Mask-Size Analysis
A detailed frequency-domain analysis demonstrates that standard inpainting imparts a consistent grid-like artifact in the high-frequency spectrum, serving as a universal and trivial detection cue. INP-X effectively suppresses these signals, as corroborated by spectral MSE metrics across datasets.
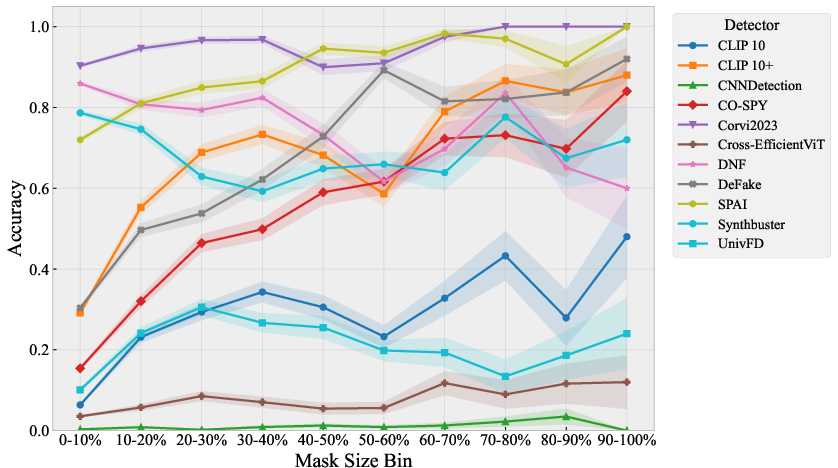
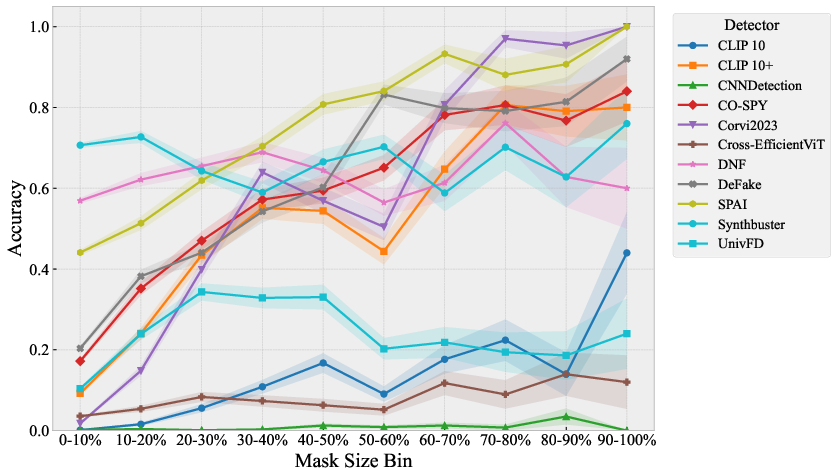
Figure 8: Detection accuracy as a function of mask size—larger masks make INP-X easier to detect, as more generated content is present; smaller masks yield nearly indistinguishable images.
Implications and Discussion
Theoretical Implications: The findings highlight the centrality of artifact overfitting in current detection pipelines—detectors are not fundamentally identifying the semantics or boundaries of manipulations. Instead, they exploit global distributional or spectral anomalies introduced primarily by VAE compression mechanisms. As a result, apparent high accuracy in standard benchmarks largely reflects shortcut learning, not robust artifact detection at the manipulated content level.
Practical Implications: Any future forensic tool or system tasked with manipulation detection, especially for subtle, partial edits like inpainting, must incorporate content-aware, localization-driven mechanisms. Reliance on global high-frequency cues is demonstrably brittle: simple post-processing operations like INP-X (or even blending and restoration strategies) can trivially defeat current state-of-the-art detectors, including commercially deployed APIs.
Broader Impact and Future Directions: The paper underscores the necessity of revising evaluation frameworks for forensic detectors, moving away from “clean” fully synthetic vs. real image benchmarks, and toward more challenging, post-edited, and realistic datasets as released by the authors. Algorithmic advances could include spectral-consistent VAEs, hybrid pixel-latent approaches, and architectures explicitly incorporating spatial localization. Moreover, detection systems must anticipate and adapt to anti-forensic countermeasures based on restoration of background statistics, as the risk of evasion attacks against current models is now concrete.
Conclusion
This work demonstrates—both theoretically and empirically—that current AI-generated image detectors substantially over-rely on global artifacts, particularly those arising from VAE encoding in inpainting pipelines. The proposed INP-X operation exposes this vulnerability: eliminating the global artifact by restoring background pixels drastically reduces detector performance and reveals a fundamental gap in current approaches. Robust detection demands not only content awareness but also a reformulation of training and benchmarking practices to counteract shortcut learning. The released dataset and code set a new standard for the rigorous assessment of image forensic tools and call for new detection paradigms for the coming generation of image synthesis systems.