- The paper introduces a framework that exactly decomposes classifier loss into aleatoric (irreducible) and epistemic (reducible) components using normalizing flows.
- It reveals that epistemic error decays by a power law with dataset size, showing continued learning progress even after total loss plateaus.
- It demonstrates that training with oracle soft labels and epistemic-based sample selection outperforms traditional hard-label supervision and random strategies.
Exact Oracle-World Posteriors: A Framework for Decomposing Neural Network Error
Framework Overview and Methodology
This paper introduces a rigorous framework for evaluating the limits of supervised learning using class-conditional normalizing flows trained on realistic image datasets (AFHQ, ImageNet) to serve as synthetic-data oracles. These flows generate data where the true posterior p(y∣x) is computable in closed form. This enables decomposition of the cross-entropy loss of any model into its aleatoric and epistemic components—a feat generally impossible with real-world datasets.
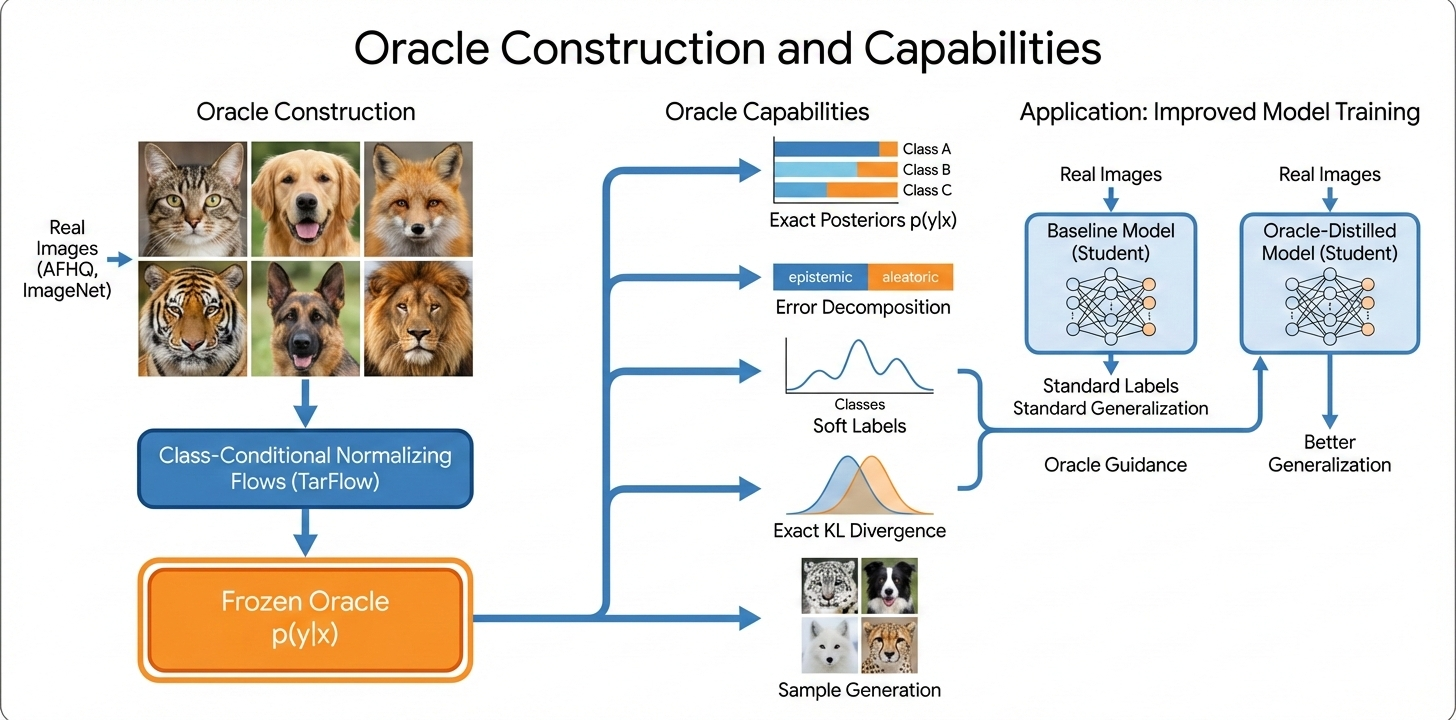
Figure 1: Normalizing flows enable exact posterior computation on realistic images and decompose classifier error into aleatoric (irreducible) and epistemic (reducible) parts, enabling new diagnostics and training regimes.
Architectures such as TarFlow are utilized to fit data distributions separately for each class, after which posteriors are tractably available via Bayes’ rule. The authors establish the validity of these oracles through extensive validation: generated samples demonstrate high coverage, diversity, and distinctiveness (with low memorization rates), and classifiers trained on oracle samples approach the Bayes error (99.77% on AFHQ).
Scaling Laws and the Loss Decomposition
The core contribution is the ability to exactly partition the observed loss into its aleatoric and epistemic terms. The aleatoric term is irreducible, reflecting intrinsic ambiguity in the data, while the epistemic term quantifies learnable but as-yet-unlearned structure. Standard benchmarks measure only aggregate loss, masking this distinction.
Experiments reveal that epistemic error consistently follows a power-law decay with respect to dataset size, even beyond points where total loss plateaus. Notably, different model families display distinct scaling exponents and convergence behaviors.
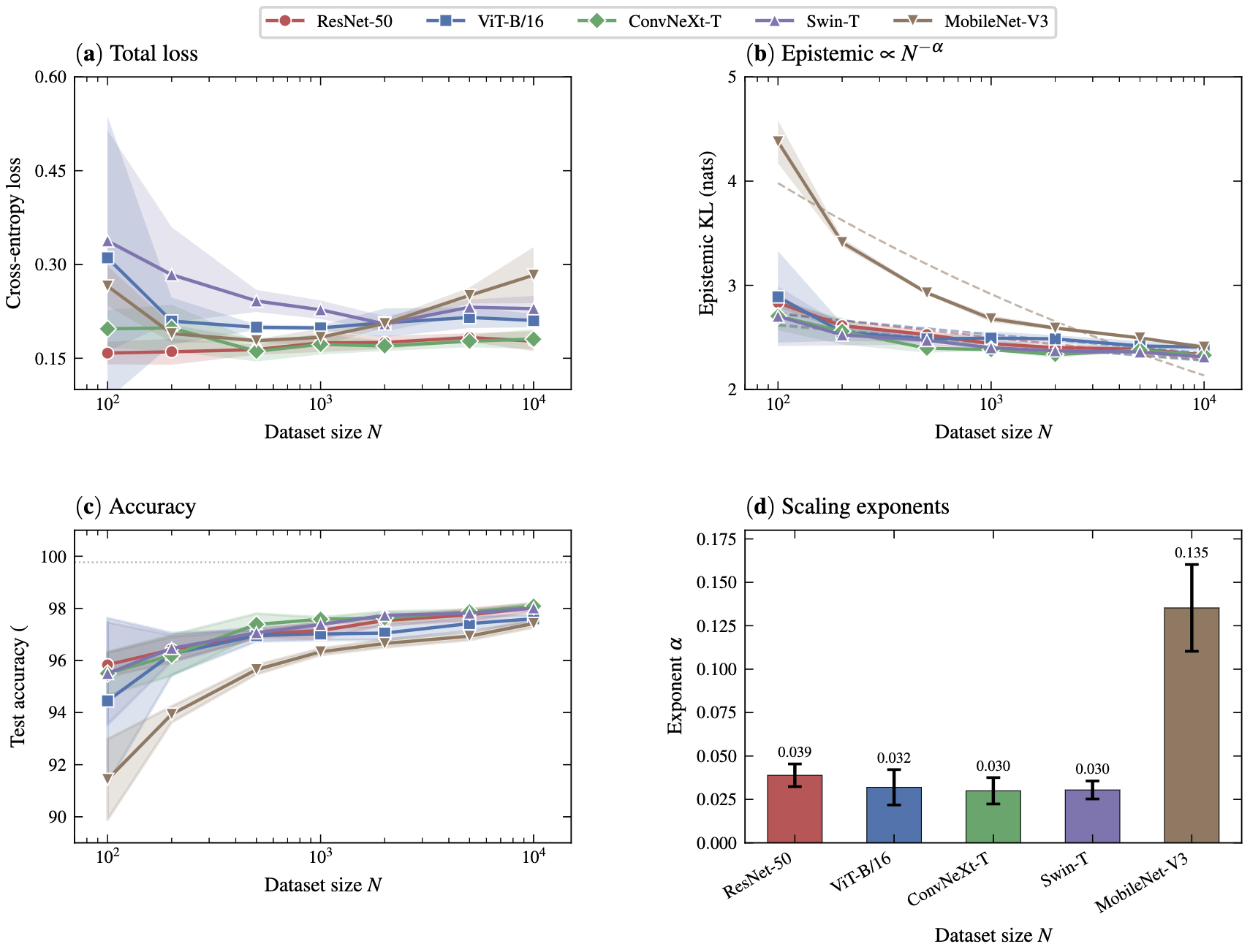
Figure 2: Epistemic error (KL divergence to the oracle) follows a power law in dataset size, even as total loss saturates.
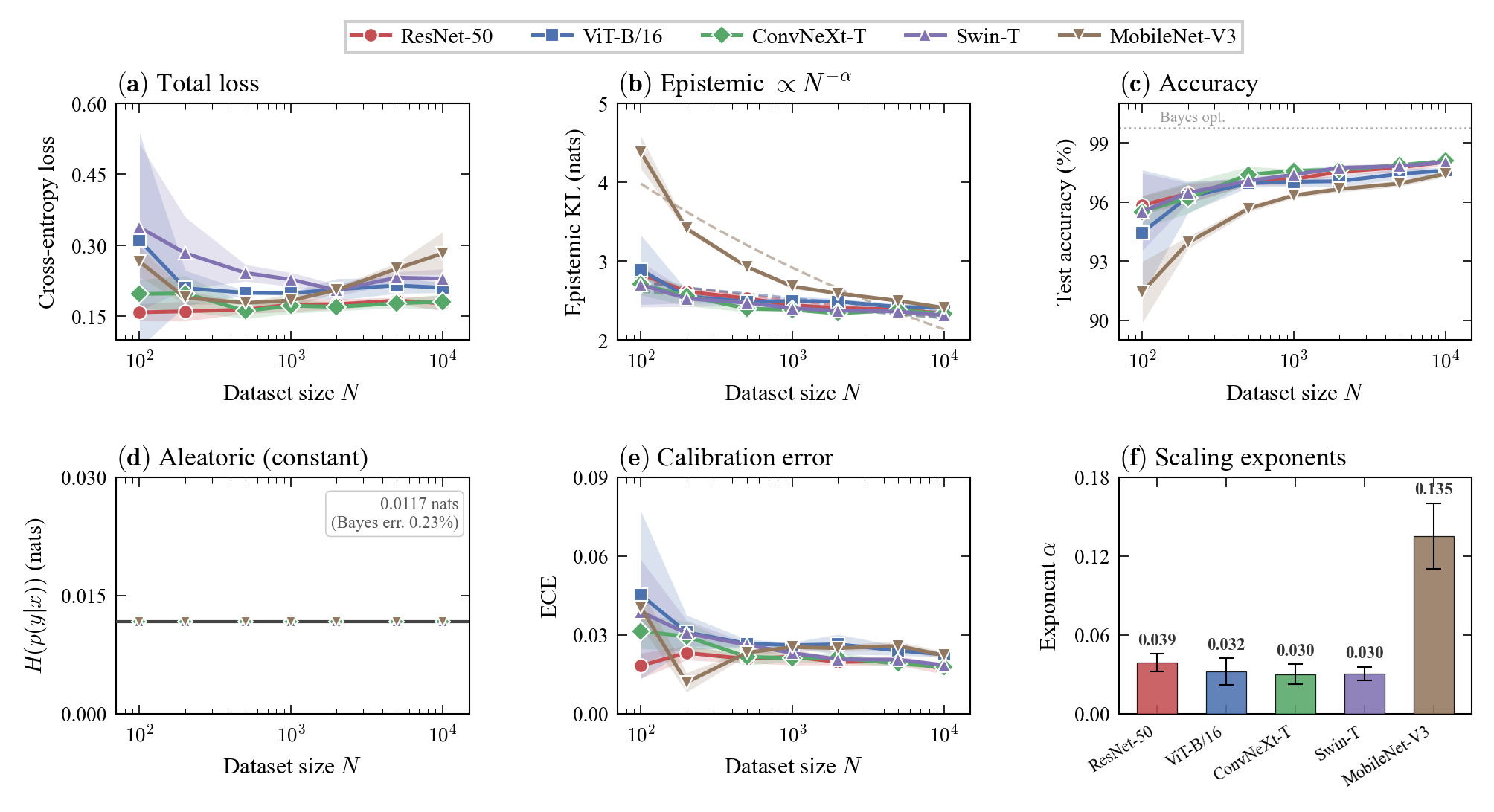
Figure 3: Full scaling results on AFHQ indicate persistent power-law decay in epistemic uncertainty across architectures, quantifying learning progress even after loss saturation.
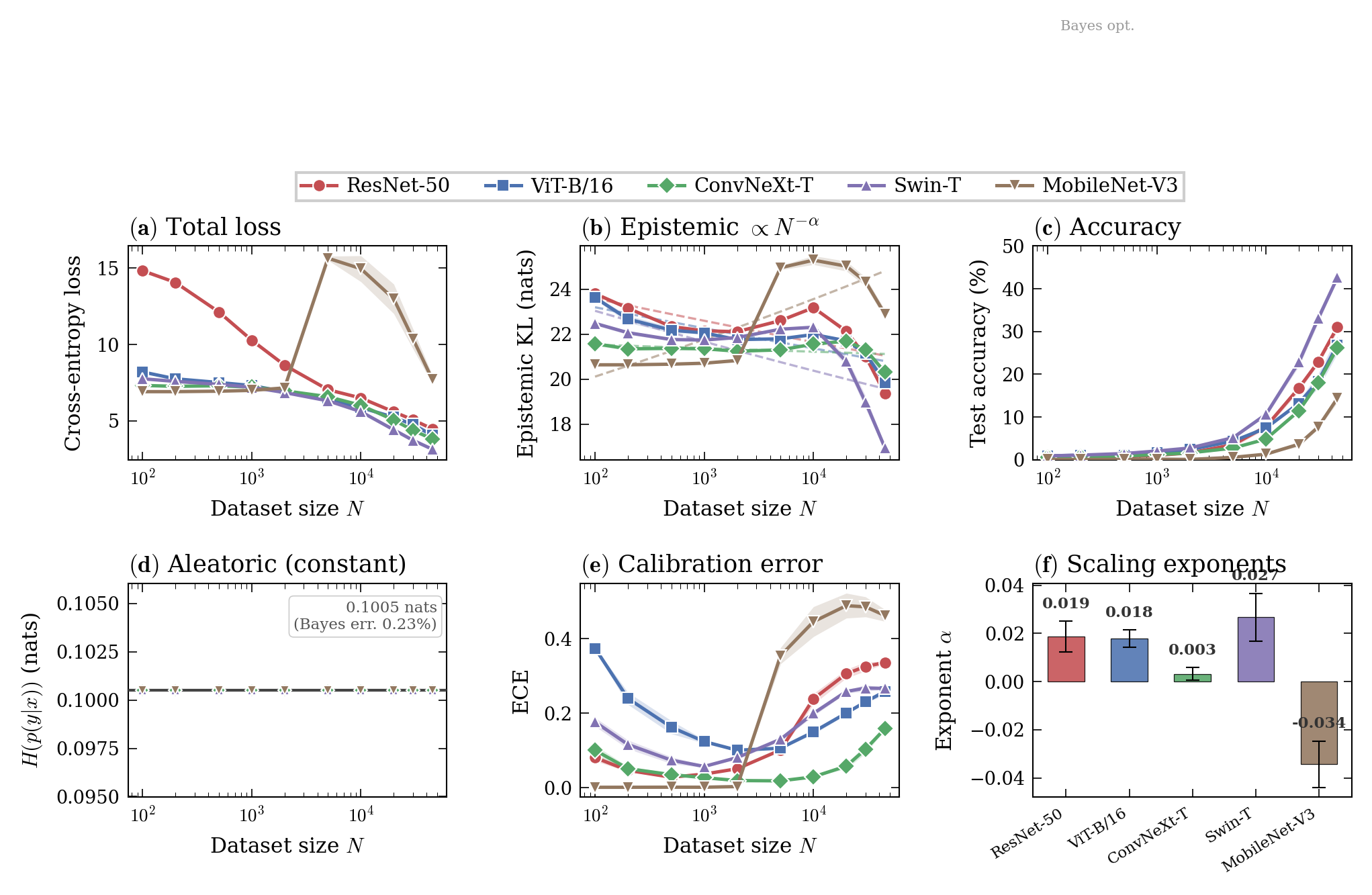
Figure 4: Scaling laws extend to ImageNet-64’s 1000-class setting; MobileNet exhibits a mid-range anomaly but resumes power-law scaling at larger scales.
Comparison of architectures unveils that convolutional models (e.g., ResNets) maintain clean scaling, substantially reducing epistemic uncertainty, whereas transformer-based models (ViT) typically stall without pretraining, showing limited epistemic gains in low-data regimes.
Soft Label Supervision
Training classifiers with the oracle’s exact posterior distributions (“soft labels”) yields superior performance compared to hard-label (argmax) training and achieves improved calibration. This demonstrates that under full posterior access, there exists additional exploitable structure that canonical classification regimes do not capture.
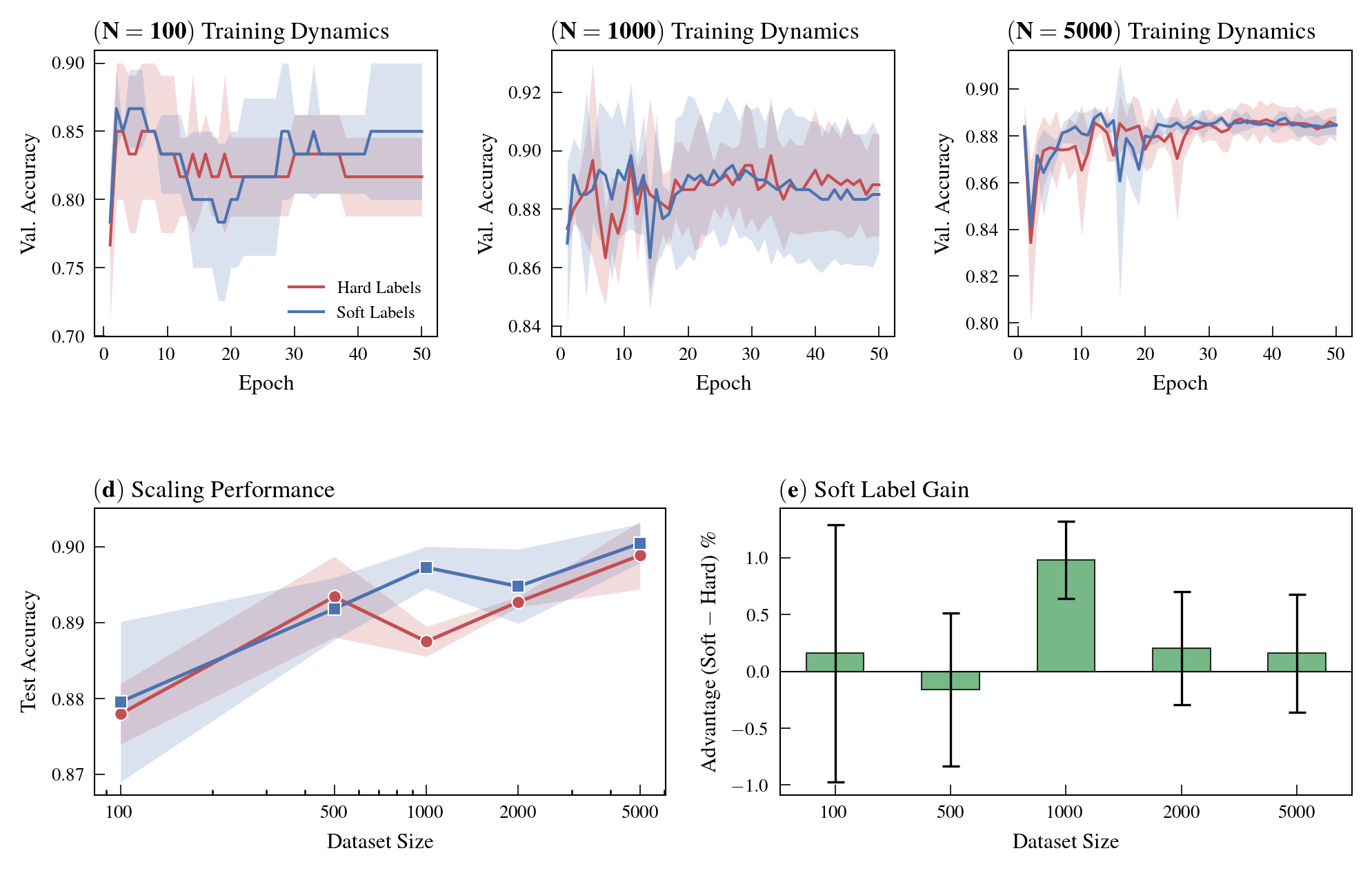
Figure 5: Training with exact soft labels consistently outperforms hard-label supervision across dataset sizes, improving both accuracy and calibration.
Distribution Shift: Quantitative Insights
The decompositional framework enables for the first time an exact quantification of model degradation under controlled distribution shift, by measuring KL divergence between the baseline and perturbed data distributions. The experiments reveal a critical qualitative result: the type of shift—covariate (feature) vs. prior (class-imbalance)—matters more than the magnitude of shift as measured by KL divergence.
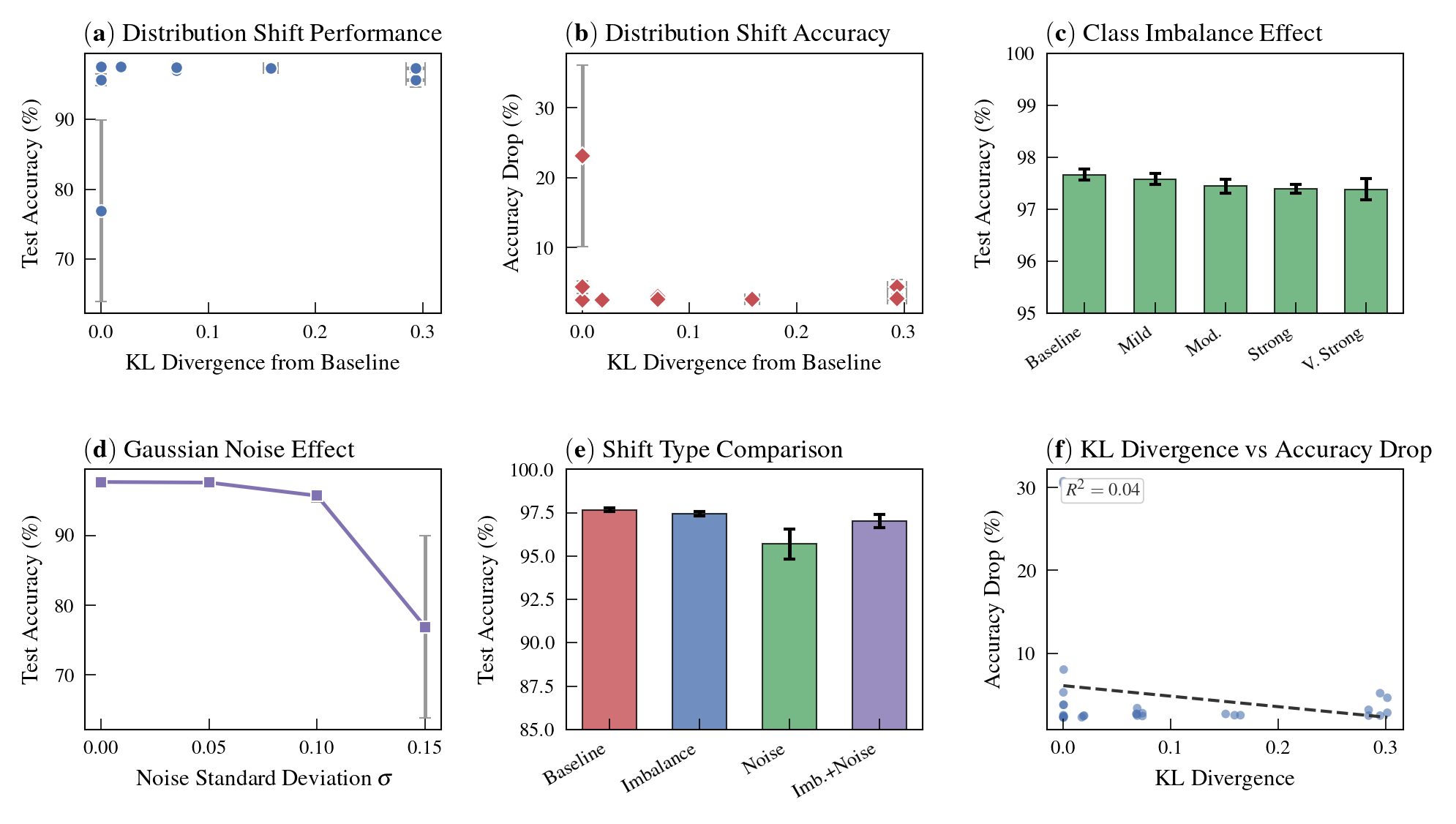
Figure 6: Shifts in KL divergence alone poorly predict task performance—shift type (covariate vs. prior) dominates outcome.
Class imbalance barely affects accuracy even at large KL values, while moderate covariate noise yields catastrophic accuracy drops. This has strong implications for robustness assessments: operational definitions must distinguish where the distribution is shifting.
Active Learning with Ground-Truth Uncertainty
The oracle’s tractable posteriors provide “ground-truth” epistemic uncertainty, enabling separation of truly informative (epistemically uncertain) samples from aleatorically ambiguous ones. Acquisition based on this epistemic score substantially outperforms canonical entropy-based or random sampling strategies.
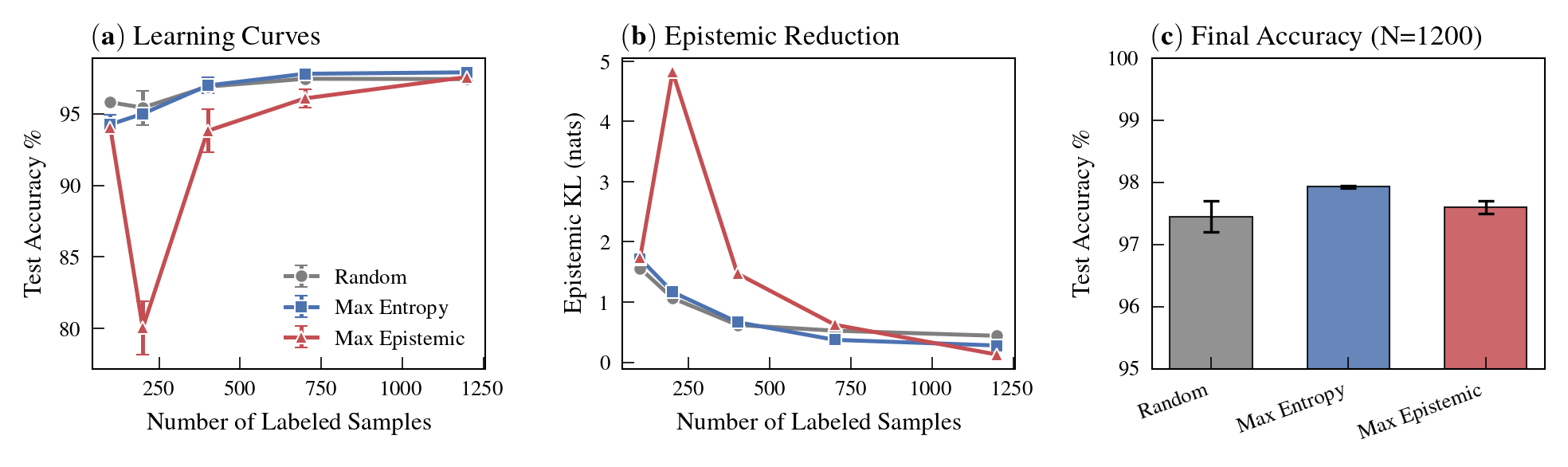
Figure 7: Epistemic-based acquisition drives rapid reduction in model uncertainty, outperforming standard sample selection strategies.
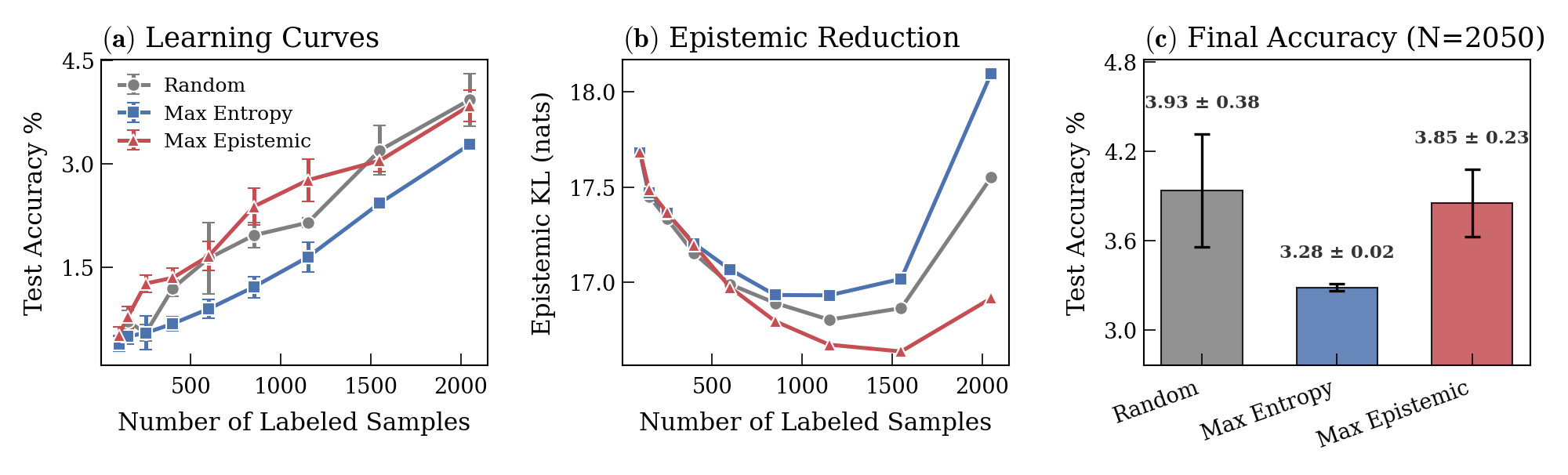
Figure 8: On ImageNet-64, selection by epistemic uncertainty consistently yields superior learning acceleration compared to entropy or random choice.
Empirical and Theoretical Implications
Practical Impact
- Loss curves are misleading: Substantial epistemic progress can continue after total loss plateaus, challenging practices such as early stopping based solely on validation loss.
- Inductive bias matters under data scarcity: Convolutional architectures maintain epistemic gains in low-data regimes, while attention-based models (transformers) require large-scale data or pretraining to approach similar information-theoretic optimality.
- Soft labels enable higher utility: Access to (or approximation of) posteriors for supervision, even beyond teacher distillation settings, improves both accuracy and calibration.
- Robustness evaluations must be nuanced: Mode of distribution shift critically determines performance impact, eroding confidence in defenses or metrics predicated solely on divergence values.
Theoretical Relevance
- Scaling law generalization: By isolating epistemic error, the study demonstrates that power-law learning curves persist even after statistical estimates (total loss) saturate, suggesting new diagnostics for the limits of supervised learning.
- Tight benchmarks for future Bayesian learning: This decomposition with exact posteriors defines a setting to rigorously benchmark and advance Bayesian deep learning, uncertainty quantification, and active learning algorithms.
- Complement, not replace, real data: While grounded in a synthetic “oracle world,” the findings inform and constrain our understanding of neural network learning in naturalistic data, particularly about the role of data uncertainty and information content.
Conclusion
This paper establishes a rigorous, synthetic-but-realistic benchmarking methodology for analyzing supervised learning in neural networks, enabled by normalizing flow-based oracles that provide exact posteriors. The authors demonstrate that epistemic error continues to shrink—following a power law in data scale—well past the flattening of traditional loss curves, and that model architectures exhibit starkly different scaling exponents. Furthermore, the distinction between aleatoric and epistemic uncertainty enables unprecedented disambiguation of learning progress, calibration, and active acquisition efficiency. Quantitative assessment of distribution shift reveals the necessity of measuring not just the magnitude but the structure of domain changes. This framework provides a testbed for principled evaluation and targeted improvement of models and algorithms in settings that approximate, but are not limited by, the constraints of real-world data.