Parallel Stochastic Gradient-Based Planning for World Models
Abstract: World models simulate environment dynamics from raw sensory inputs like video. However, using them for planning can be challenging due to the vast and unstructured search space. We propose a robust and highly parallelizable planner that leverages the differentiability of the learned world model for efficient optimization, solving long-horizon control tasks from visual input. Our method treats states as optimization variables ("virtual states") with soft dynamics constraints, enabling parallel computation and easier optimization. To facilitate exploration and avoid local optima, we introduce stochasticity into the states. To mitigate sensitive gradients through high-dimensional vision-based world models, we modify the gradient structure to descend towards valid plans while only requiring action-input gradients. Our planner, which we call GRASP (Gradient RelAxed Stochastic Planner), can be viewed as a stochastic version of a non-condensed or collocation-based optimal controller. We provide theoretical justification and experiments on video-based world models, where our resulting planner outperforms existing planning algorithms like the cross-entropy method (CEM) and vanilla gradient-based optimization (GD) on long-horizon experiments, both in success rate and time to convergence.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Parallel Stochastic Gradient-Based Planning for World Models”
Overview
This paper is about helping computers and robots plan actions by imagining the future. The authors use “world models,” which are computer programs that learn to predict what happens next from videos or images. Planning with these models is hard, especially for long tasks, because there are many possible action sequences to try. The paper introduces a new planning method called GRASP (Gradient RelAxed Stochastic Planner) that makes planning faster, more reliable, and easier to run in parallel (many parts at the same time), especially for long, complex tasks.
Key objectives and questions
The paper sets out to answer a few clear questions:
- How can we use world models to plan better for long tasks without getting stuck in bad solutions?
- Can we use gradient-based methods (which follow the slope of the “error” to improve) in a way that stays stable and avoids nasty surprises in high-dimensional vision models?
- Will a new approach (GRASP) be faster and more successful than popular planners like CEM (which samples random action sequences) or plain gradient descent (GD)?
- Can we run planning steps in parallel to save time?
Methods and approach (in everyday language)
First, some quick definitions:
- World model: Think of it like a simulator in the robot’s head. It predicts the next state (what the world looks like) given the current state and an action.
- Planning horizon: How many steps into the future we plan (like planning 50 moves ahead).
- Gradient: A direction that tells you how to change something (like actions) to get closer to your goal, based on how the error changes.
Now, what GRASP does:
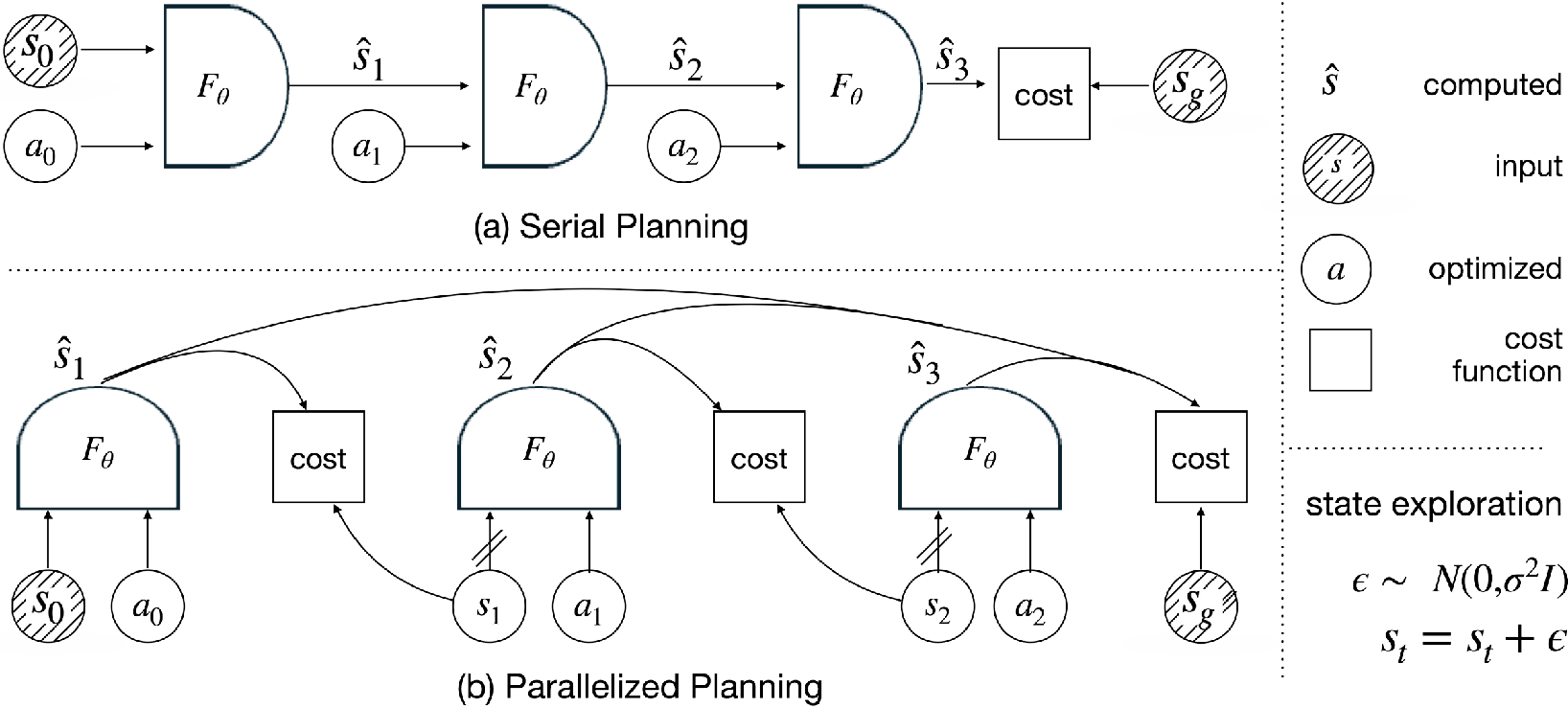
- Virtual waypoints (states) instead of only rolling forward:
- Usual planning “rolls out” the model step by step from start to end, which can be slow and unstable.
- GRASP treats the states at each step as “virtual waypoints” that you can adjust directly, almost like placing useful checkpoints along a route.
- This lets the planner compare pairs of states and actions and compute things in parallel, saving time.
- Soft rules for dynamics:
- Instead of forcing every step to exactly match the world model’s rules, GRASP uses a “soft” penalty that encourages states and actions to behave like the model predicts, while still allowing flexibility. This makes optimization easier.
- Add helpful randomness to escape traps:
- Many planning problems have “local minima,” like dead-ends where a greedy strategy would fail.
- GRASP adds small random nudges to the virtual states during optimization. This is like trying slightly different routes to avoid getting stuck in a bad path.
- Use gradients only through actions (not states):
- In high-dimensional vision models, tiny changes to the state input can cause weird, unrealistic jumps (like “teleporting” in the model) because the model’s “state gradients” can be unreliable.
- GRASP “stops” gradients through the state inputs and only uses gradients through actions. This keeps the planner’s guidance realistic: it learns which actions move you toward the goal, rather than trying to exploit fragile state directions.
- Goal shaping at every step:
- GRASP gives each step a hint by asking the model’s “next prediction” to move toward the goal, not just the final state. This spreads useful signals across the whole plan.
- Occasional full-rollout sync:
- Every so often, GRASP briefly runs standard gradient descent through the full rollout (from start to finish) to fine-tune the plan. Think of it as tightening all the bolts after exploring different paths.
Put together, these steps make GRASP a planner that:
- Works in parallel,
- Uses randomness to avoid bad traps,
- Avoids unreliable gradients through visual states,
- And still uses gradients smartly through actions to get better plans.
Main findings and why they matter
The authors test GRASP on several visual planning tasks, including:
- PointMaze and WallSingle (like navigating a maze or around walls),
- Push-T (moving and pushing objects in a tricky “T” shaped area).
Here are the key results:
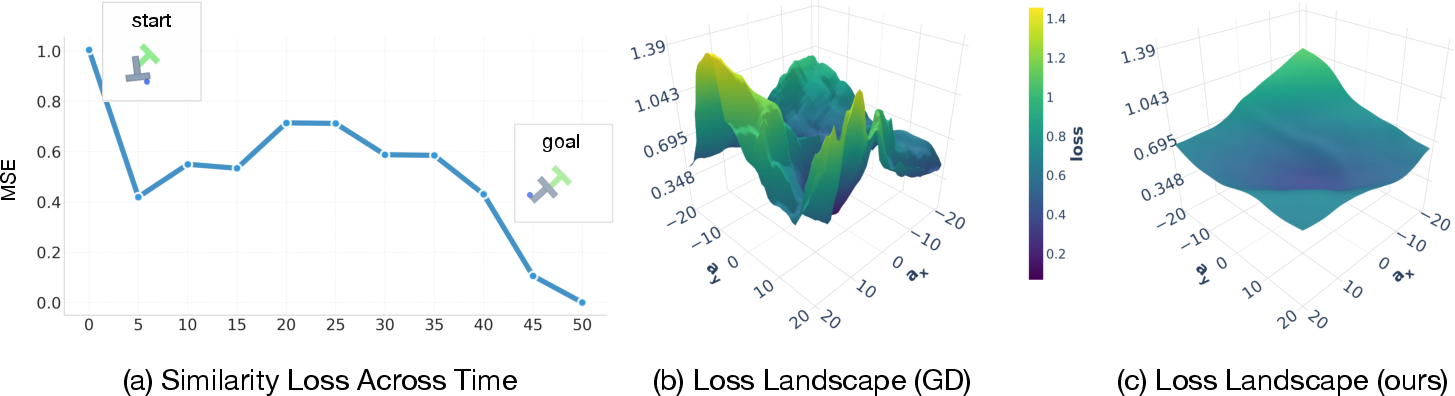
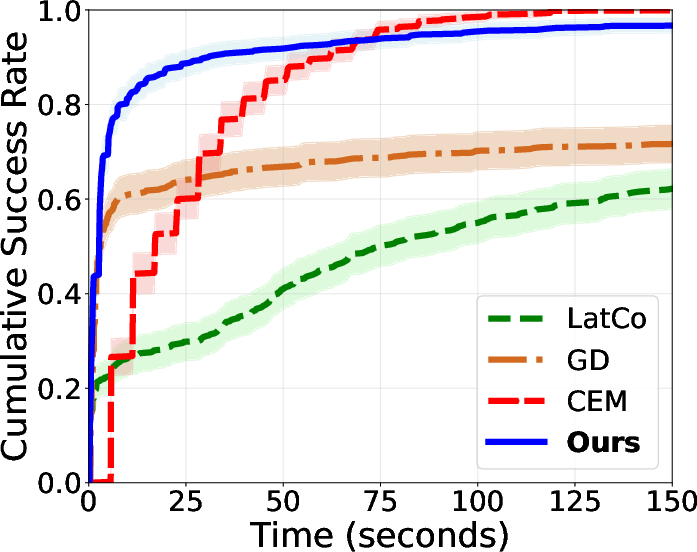
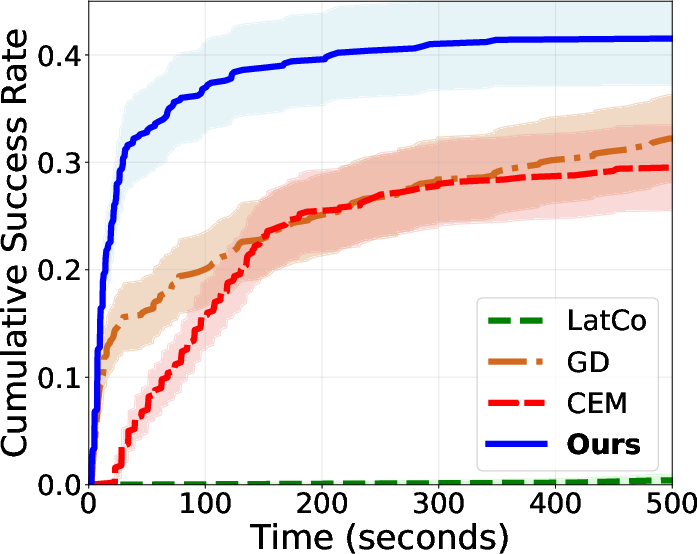
- For long tasks (big planning horizons), GRASP succeeds more often than CEM (sampling-based) and standard GD (gradient-based).
- It finds solutions faster (lower wall-clock time), often less than half the compute time vs. CEM.
- It avoids greedy failures where you’d wrongly try to go straight to the goal even when you need to go away from it first.
- In short tasks, GRASP performs similarly to strong baselines but still tends to be fast.
- Ablation tests (turning features on/off) show that the three key ideas—state gradient stopping, added noise, and periodic sync—are important for GRASP’s success.
Why this matters:
- Planning from video is hard because the “state space” (what the world looks like) is huge and messy. GRASP’s approach makes this planning more reliable and scalable, especially when you need to plan far ahead.
Implications and impact
GRASP can make robots and AI agents better at planning in visually rich worlds, such as:
- Navigating complex environments,
- Manipulating objects with arms,
- Testing strategies in simulated medical procedures,
- Practicing safely in virtual worlds before acting in the real one.
Because GRASP is highly parallelizable and uses smarter gradients, it can scale to longer, more complicated tasks while staying efficient. The method also suggests a broader lesson: when working with visual world models, it’s better to trust action gradients (how actions change the future) than state gradients (tiny pixel-space changes), which can be fragile.
Limitations and future work:
- For short, easy tasks, GRASP’s advantage is smaller.
- If world models become smoother and more robust, GRASP might be simplified further and become even faster.
- Hybrid planners that mix GRASP with other methods (like CEM) could push performance even higher.
Overall, GRASP is a practical step toward reliable, long-horizon planning in complex visual environments, showing that careful use of gradients, randomness, and parallel computation can make a big difference.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights what remains missing, uncertain, or unexplored in the paper and can guide future research:
- External validity: Plans are evaluated only under the learned world model, not in the ground-truth simulator or real environment. It remains unknown how GRASP’s plans perform under true dynamics (sim-to-real transfer, closed-loop execution, robustness to model error).
- Robustness to model error and uncertainty: The planner assumes a deterministic world model and does not account for epistemic/aleatoric uncertainty. How to incorporate uncertainty estimates (e.g., ensembles, Bayesian models) and robust objectives to prevent unsafe or brittle plans under model misspecification?
- Dynamic feasibility guarantees: The method enforces dynamics via soft penalties and periodic rollout sync, but provides no guarantees that the final action sequence produces a dynamics-consistent trajectory. What conditions or schedules (penalty weights, sync frequency) ensure feasibility and how can violations be measured and reduced?
- Convergence theory: The paper provides informal arguments and mentions a theoretical model, but lacks formal convergence guarantees for the combined “noisy state + action-only gradients + periodic sync” dynamics. Under what assumptions does GRASP converge, and to what (local/global) optima?
- Effect of stop-gradient on states: Detaching state-input gradients mitigates adversarial directions, but may discard useful curvature. When do action-only gradients suffice, and in which systems (e.g., underactuated/contact-rich) does this degrade performance? Can we characterize tasks where stop-grad harms optimization?
- Off-manifold exploration: State noise can push “virtual states” off the data manifold, potentially degrading model predictions. How often and how far do states drift off-manifold, and can manifold-aware regularizers or learned priors (e.g., diffusion, autoencoder constraints) mitigate this?
- Hyperparameter sensitivity and auto-tuning: Performance depends on noise level (σ), goal shaping weight (γ), learning rates (ηa, ηs), sync frequency (Ksync), and sync steps (Jsync). What are principled schedules (e.g., annealing, adaptive control) to tune these automatically across tasks and horizons?
- Scalability to high-dimensional control: Experiments use low-dimensional actions; it is unclear how GRASP scales to high-DoF robots (e.g., 7–28 DoF), complex contact dynamics, or multi-agent systems. Provide empirical scaling laws (time/memory) and failure modes at larger dimensions.
- Compatibility with stochastic world models: Many video world models predict distributions. How to extend GRASP to stochastic dynamics (e.g., optimize expected cost, risk-sensitive objectives, reparameterization tricks), and how does noise interact with model stochasticity?
- Breadth of baselines: Comparisons exclude widely used planners such as MPPI, iLQR/DDP with learned linearizations, and modern population-based methods (e.g., CMA-ES variants). Including these would clarify GRASP’s advantages in conditioning, speed, and success across regimes.
- Real-time MPC integration: GRASP is demonstrated in open-loop planning. How does it perform in receding-horizon MPC with closed-loop feedback, latency constraints, and partial observability? What are end-to-end wall-clock budgets on embedded hardware?
- Constraint handling: The planner optimizes goal-reaching without explicit hard constraints (state, action, safety). How to incorporate barrier functions, chance constraints, or safety filters (e.g., control barrier functions) while retaining parallelism and robustness?
- Latent-space metric calibration: The objectives use latent L2 distances to the goal, whose alignment with task semantics may be poor. How sensitive is GRASP to the choice of latent metric, and can perceptual or contrastive metrics improve plan quality?
- Generality across world model architectures: Tested with DINO-wm; it is unknown how GRASP performs with other models (e.g., diffusion-based, transformer latent dynamics, Dreamer-like models). Provide cross-model evaluations and identify model properties (smoothness, Lipschitzness) that make GRASP succeed.
- Sensitivity to world model quality: There is no study of performance vs. model accuracy. How does GRASP degrade under weaker models, and can it adaptively detect and compensate for poor predictions (e.g., trust-region updates, uncertainty-weighted losses)?
- Initialization strategies: States are initialized via noisy linear interpolation and actions at zero. How do alternative initializations (heuristics, CEM warm starts, learned priors) affect convergence speed and success, especially at long horizons?
- Sync-step brittleness: The periodic full-rollout gradient step reintroduces state-input gradient issues the method seeks to avoid. Quantify when and how much this harms optimization, and develop safer refinement steps (e.g., trust regions, gradient clipping, second-order damping).
- Parallelization and resource profiling: Claims of parallelism need detailed analysis of GPU utilization, memory footprint, and batch size scaling. Provide throughput comparisons vs. CEM/GD across hardware and horizons, including the cost of periodic sync passes.
- Plan quality metrics: Evaluation focuses on success rate and time to convergence. Add measures of path optimality (length, energy/smoothness), dynamics violations, and safety to understand trade-offs introduced by relaxed constraints and noise.
- Action bounds and physical limits: The planner does not explicitly enforce bounds or torque limits. How to incorporate action constraints to prevent unrealistic or unsafe commands under learned dynamics?
- Horizon limits: Results extend to H≈80 in Push-T; long-horizon behavior beyond this remains unexplored. What failure modes appear at very long horizons, and can curriculum schedules or multi-segment planning help?
- Noise design: The paper uses isotropic Gaussian noise on states. Investigate adaptive or anisotropic noise (e.g., preconditioned by local curvature, learned diffusion schedules) and its impact on escaping local minima without leaving the manifold.
- Goal types and task diversity: Tasks use fixed goal states/regions. How does GRASP handle moving goals, sparse rewards, multi-objective costs, or temporally extended specifications (e.g., LTL constraints)?
- Reproducibility and variance: While success rates and CIs are reported, variability across seeds and runs under different noise realizations is not analyzed. Provide variance analyses and robustness tests for reproducibility.
- Formalization of the “informal theorem”: The paper asserts that losses with dynamics-feasible minimizers must depend on state gradients. A precise statement, assumptions, and proof (and possible exceptions or relaxations) would strengthen the theoretical foundation.
- End-to-end co-training: The method suggests smoother state geometry would reduce stabilization needs. Explore joint training of the world model with GRASP-in-the-loop (e.g., adversarial training, representation regularization) to directly optimize for planning amenability.
Practical Applications
Summary
The paper introduces GRASP (Gradient RelAxed Stochastic Planner), a gradient-based planner for learned world models—especially visual/latent video models. GRASP lifts planning by optimizing over “virtual states” with soft dynamics constraints, cuts gradients through state inputs (uses action-only gradients), injects Langevin-style noise for exploration, and periodically synchronizes with short full-rollout gradient steps. This produces a parallelizable, stable, and faster long-horizon planner that outperforms common baselines like CEM and vanilla GD in success rate and convergence time on visual world-model benchmarks.
Below are practical applications that derive from these findings, grouped by timeline and connected to relevant sectors, potential tools/products/workflows, and feasibility assumptions.
Immediate Applications
These applications can be prototyped or deployed now where differentiable world models (or differentiable surrogates) are available.
- Robotics: long-horizon planning with learned visual models
- Use cases
- Warehouse AMRs and mobile manipulators: non-greedy navigation among obstacles; long-sequence pick-and-place planning in visually rich scenes.
- Drone filming/inspection in structured spaces: plan obstacle-aware camera trajectories with fewer sampling rollouts.
- Lab and pilot deployments where a world model is already trained (e.g., for specific factories, labs, or demo floors).
- Sector: robotics, logistics, industrial automation
- Tools/products/workflows
- GRASP-MPC: a receding-horizon controller that runs GRASP in a loop with re-planning and model predictive control.
- PyTorch/JAX module for time-parallel virtual-state optimization with GPU-batched inference.
- A “planner plugin” for existing world-model stacks (e.g., DINO-wm, Dreamer-like pipelines).
- Assumptions/dependencies
- A trained differentiable world/surrogate model with usable action gradients; reasonable model fidelity in the target domain.
- Latent encoder/decoder for visual inputs and goals.
- Real-time GPU/TPU/accelerator availability and latency budgets compatible with GRASP steps and periodic sync updates.
- Safety fallbacks required for real robots (model error may cause unsafe plans).
- Digital twins and simulation “what-if” search
- Use cases
- Rapid what-if testing and long-horizon sequence search for factory cells, AMR traffic patterns, or process lines within a learned model of the environment.
- Automated scenario generation that explores edge cases via state noise, complementing coverage-based simulation tests.
- Sector: manufacturing, operations research, simulation platforms
- Tools/products/workflows
- Integration with digital twin platforms (e.g., Omniverse) using learned surrogates for fast differentiable rollouts.
- Batch parallel “stress-test” harness: GRASP explores non-greedy solutions and obstacle-heavy layouts by injecting state noise.
- Assumptions/dependencies
- Availability of sufficiently accurate learned surrogates or differentiable simulators; sim-to-real gap acknowledged.
- Compute capacity for running many parallel GRASP instances.
- Game AI and interactive simulation agents
- Use cases
- Bots that perform long-horizon objectives (quest completion, stealth routing, item sequencing) with fewer heuristic hand-tunes.
- Automated level/QA testing: plan hard-to-find sequences that expose gameplay bugs (via stochastic state exploration).
- Sector: gaming, simulation, entertainment
- Tools/products/workflows
- Unity/Unreal integration layers that wrap an in-engine learned model or differentiable surrogate and call GRASP for planning.
- Batch agents for level testing and metrics dashboards (success vs. horizon, convergence time).
- Assumptions/dependencies
- Differentiable or learned-in-engine dynamics model; access to action gradients or surrogate models that approximate them.
- Tolerance for planning compute in the loop or offline precomputation.
- Research and education tooling for world-model planning
- Use cases
- Benchmarking: compare CEM, GD, LatCo, and GRASP on long-horizon tasks to study gradient brittleness and loss landscapes.
- Curriculum design: teaching lifted planning (virtual states), state-gradient detaching, and stochastic exploration.
- Sector: academia, corporate research
- Tools/products/workflows
- Reproducible baselines, ablation suites, and notebooks for D4RL/DM control with GRASP.
- Visualization utilities for plan trajectories and loss landscapes.
- Assumptions/dependencies
- Access to standard benchmarks and pretrained world models; moderate compute for parallel runs.
- Safety evaluation in simulation
- Use cases
- Pre-certification testing of robot policies inside a trusted sandbox: GRASP explores long-horizon failure modes that greedy planners may miss.
- Counterfactual analysis: “How could a policy fail under rare sequences?” using state noise to traverse basins.
- Sector: policy/compliance for robotics and AI systems
- Tools/products/workflows
- Scenario libraries with GRASP-based exploration policies to probe edge cases; audit trails of long-horizon trajectories.
- Assumptions/dependencies
- A world model with fidelity for the safety metric of interest; human oversight and sanity checks for model bias.
Long-Term Applications
These require additional research, scaling, or maturing of world models and system integration.
- Autonomous driving/planning modules with learned visual world models
- Use cases
- Non-greedy long-horizon maneuvers (e.g., complex merges, multi-block routing in dense urban scenes) using action-gradient planning.
- Sector: transportation, automotive
- Tools/products/workflows
- GRASP as a long-horizon optimizer within a hierarchical planner; fused with rule-based safety envelopes or reachable-set monitors.
- Assumptions/dependencies
- Highly reliable, distributionally robust visual world models; strict verification, uncertainty calibration, and fail-safe layers.
- Real-time deterministic latency and certification for safety-critical systems.
- Surgical robotics and procedural planning from video models
- Use cases
- Long-sequence planning for fine, non-greedy maneuvers (e.g., suture paths) in simulated training or preoperative planning.
- Sector: healthcare, surgical robotics, medical simulation
- Tools/products/workflows
- GRASP-informed preoperative rehearsal planners; “what-if” procedural simulators with stochastic exploration to expose potential complications.
- Assumptions/dependencies
- Extremely high-fidelity world models (tissue dynamics, tool-tissue interactions) and regulatory-grade validation.
- Generalist home/service robots that plan complex tasks from vision
- Use cases
- Long multi-step routines (e.g., tidying a room with obstacles, preparing a sequence of actions across different rooms) where greedy steps fail.
- Sector: consumer robotics, smart home
- Tools/products/workflows
- GRASP-MPC integrated with perception stacks and skill libraries; on-device accelerators or edge compute support for time-parallel planning.
- Assumptions/dependencies
- Robust, continually updated home environment world models; reliable closed-loop control and recovery from model errors.
- Multi-robot coordination and trajectory optimization
- Use cases
- Coordinated long-horizon plans with collision constraints in shared spaces (factories, warehouses, swarms).
- Sector: robotics, logistics, defense
- Tools/products/workflows
- GPU-accelerated GRASP variants that jointly optimize virtual states for multiple agents with inter-agent constraints.
- Assumptions/dependencies
- Learned multi-agent world models or differentiable surrogates that capture interactions; scalable constraint handling and safety guarantees.
- Process, energy, and building control with differentiable surrogates
- Use cases
- Long-horizon control (HVAC schedules, microgrid dispatch, industrial processes) where non-visual differentiable surrogates exist.
- Sector: energy, industrial control
- Tools/products/workflows
- GRASP adapted to surrogate models (not necessarily visual) and integrated into EMS/BMS; parallelized planning windows for seasonal or daily schedules.
- Assumptions/dependencies
- High-quality differentiable surrogates with calibrated gradients; forecasting pipelines for exogenous variables; safety constraints/guards.
- Regulatory testbeds and standards for long-horizon planning
- Use cases
- Standardized, reproducible long-horizon scenario batteries using GRASP to probe planning algorithms in safety-critical domains.
- Sector: policy, standards bodies, certification ecosystems
- Tools/products/workflows
- Open benchmarks, reference implementations, and conformance tests pairing world models with GRASP and baselines (CEM/GD).
- Assumptions/dependencies
- Community consensus on model fidelity thresholds; governance for simulator and model biases; infrastructure for shared test computing.
Cross-Cutting Implementation Notes
- Deployment pattern
- Receding-Horizon Control (GRASP-MPC): run GRASP over a horizon T, execute first k actions, re-estimate state, and re-plan; mitigates model error accumulation.
- Batch parallelism: leverage the time-parallel “virtual state” evaluations on GPUs/TPUs; vectorize multiple candidate plans for robustness.
- Integration with existing stacks
- Pair with learned visual world models (e.g., DINO-wm) or non-visual differentiable surrogates; maintain action gradient paths while detaching state gradients.
- Periodic short full-rollout synchronization to refine plans; tune noise scale and sync frequency for the task.
- Key dependencies and risks
- World model fidelity and coverage are primary determinants of plan validity; out-of-distribution states remain a risk.
- Real-time constraints: although GRASP reduces wall-clock time vs. CEM in benchmarks, embedded deployments may still require hardware acceleration.
- Safety: pair GRASP plans with constraint checks, uncertainty estimates, and rule-based overrides in safety-critical contexts.
Glossary
- Action-input gradients: Gradients computed with respect to the action variables (not the state inputs) when differentiating through a model. "while only requiring action-input gradients."
- Backpropagation through time: The technique of computing gradients through sequential models across time steps, often unstable over long horizons. "akin to backpropagation through time~\citep{werbos2002backpropagation}"
- Collocation (direct collocation): An optimal control method that optimizes state and control trajectories simultaneously by enforcing dynamics at selected collocation points. "direct collocation~\citep{von1993numerical}"
- Cross-Entropy Method (CEM): A stochastic, population-based optimization algorithm often used for planning without gradients. "Cross-Entropy Method (CEM~\cite{rubinstein2004cross})"
- D4RL: A benchmark dataset suite for offline reinforcement learning tasks. "problems in D4RL~\citep{fu2020d4rl}"
- Diffeomorphic transforms: Smooth, invertible transformations used to reparameterize sampling distributions in planning. "parallelized sampling via diffeomorphic transforms"
- DINO-wm: A framework for training video-based world models leveraging DINO-style representations. "DINO-wm framework~\citep{zhou2024dino}"
- Direct collocation: See “Collocation.” "direct collocation~\citep{von1993numerical}"
- Euler discretization: A numerical method that discretizes continuous-time dynamics using a first-order update. "whose Euler discretization takes the following form:"
- Goal shaping: Adding auxiliary goal-related loss terms during optimization to provide denser guidance toward the target. "Dense goal shaping on one-step predictions."
- Gradient vector field: A vector field representing the direction of steepest descent of a scalar function; optimization following true gradients moves along this field. "do not follow a true gradient vector field"
- Jacobian: The matrix of first-order partial derivatives describing local sensitivity of a model’s outputs to its inputs. "brittle or poorly calibrated Jacobians."
- Langevin dynamics: A stochastic optimization/sampling process that augments gradient steps with noise to explore the landscape. "overdamped Langevin dynamics~\citep{gelfand1991recursive}"
- LatCo: A lifted latent-space planning baseline that jointly optimizes intermediate latent states and actions. "LatCo~\citep{rybkin2021model}"
- Latent space: A learned, low-dimensional representation of high-dimensional observations used for modeling dynamics. "states are typically represented in a learned latent space"
- Lipschitz constants: Bounds on how rapidly a function can change; large constants indicate high sensitivity and potential adversarial brittleness. "high Lipschitz constants"
- Model Predictive Control (MPC): An optimal control approach that solves a finite-horizon optimization at each step using a system model. "Non-condensed QP formulations in MPC~\citep{jerez2011condensed}"
- Multiple shooting: An optimal control technique that breaks a long-horizon problem into shorter segments with continuity constraints to improve conditioning. "multiple shooting and direct collocation~\citep{von1993numerical}"
- Non-condensed: A formulation that keeps state variables explicit (rather than eliminating them) to improve numerical properties in optimal control. "a non-condensed or collocation-based optimal controller."
- Open-loop planning: Planning an entire sequence of actions without feedback corrections during execution. "Open-loop planning results on long range Push-T."
- Quadratic program (QP): An optimization problem with a quadratic objective and linear constraints, common in control. "Non-condensed QP formulations in MPC~\citep{jerez2011condensed}"
- Rollout: Sequentially applying a dynamics model over time to simulate future states from actions. "backpropagating through the full rollout"
- Shooting methods: Trajectory optimization methods that plan by sampling or optimizing action sequences and rolling out the dynamics forward. "shooting methods which plan by iteratively rolling out trajectories"
- Stop-gradient (gradient detaching): Treating a variable as a constant during backpropagation to block gradient flow through it. "We denote by a stop-gradient copy of "
- Synchronization (full-rollout synchronization): Periodically refining actions with full backpropagation through the entire rollout to align stochastic updates with true objectives. "Full-rollout synchronization"
- Wald confidence interval: A statistical interval estimate based on asymptotic normality of estimators. "Wald 95\% confidence intervals."
- World model: A learned dynamics model that predicts future states given current states and actions, enabling planning via simulation. "World models simulate environment dynamics from raw sensory inputs like video."
- Zero-order optimization: Optimization methods that do not use gradient information, relying on sampled function evaluations instead. "0\textsuperscript{th}-order optimization methods"
Collections
Sign up for free to add this paper to one or more collections.