Self-Supervised Learning from Structural Invariance
Abstract: Joint-embedding self-supervised learning (SSL), the key paradigm for unsupervised representation learning from visual data, learns from invariances between semantically-related data pairs. We study the one-to-many mapping problem in SSL, where each datum may be mapped to multiple valid targets. This arises when data pairs come from naturally occurring generative processes, e.g., successive video frames. We show that existing methods struggle to flexibly capture this conditional uncertainty. As a remedy, we introduce a latent variable to account for this uncertainty and derive a variational lower bound on the mutual information between paired embeddings. Our derivation yields a simple regularization term for standard SSL objectives. The resulting method, which we call AdaSSL, applies to both contrastive and distillation-based SSL objectives, and we empirically show its versatility in causal representation learning, fine-grained image understanding, and world modeling on videos.
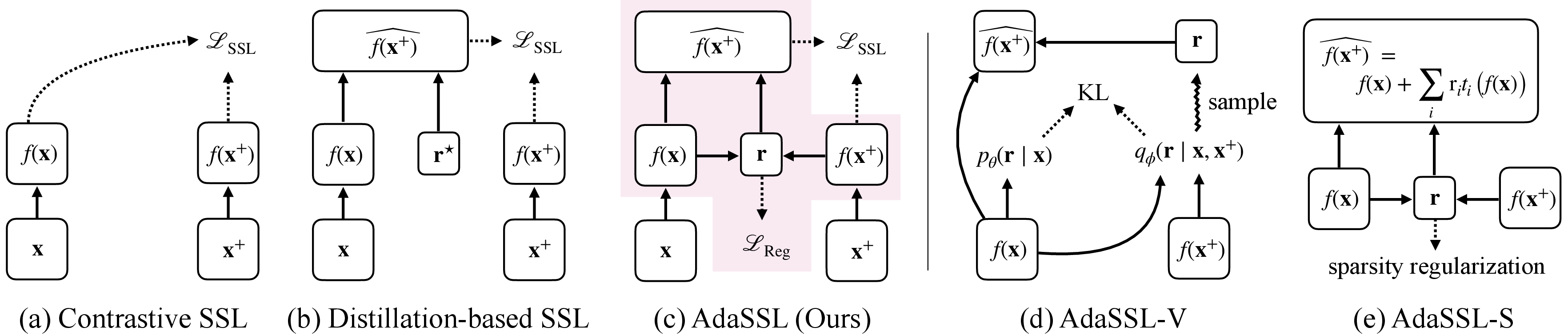


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Self-supervised learning from structural invariance”
Overview
This paper is about teaching computers to understand images and videos without needing labels (like “cat” or “car”). It focuses on a popular approach called self‑supervised learning (SSL), where a model learns by comparing related pairs of data (such as two nearby video frames or two views of the same picture). The authors show that many SSL methods struggle when a single input can lead to many valid outputs (for example, a car can turn left or right next), and they propose a new method, AdaSSL, to handle this uncertainty better.
Key questions the paper asks
- How can an SSL model learn from real, naturally paired data (like video frames) where the future isn’t always predictable, instead of relying on artificial image tweaks like random crops or color changes?
- How can we keep important, fine-grained details in the learned features instead of accidentally throwing them away because they don’t match perfectly across the pair?
- Can we build SSL that adapts to different kinds of uncertainty—sometimes small and simple, sometimes big and complex?
How the method works, in everyday terms
Think of learning from pairs like this:
- Traditional SSL tries to make the two related items (say, two frames from a video) look similar in a special “embedding” space where each item becomes a vector (a list of numbers).
- That works well when differences between the pair are small and predictable (like a slight brightness change).
- But with natural pairs, big changes happen: a person might move behind a wall and reappear somewhere else, or a caption might describe different details depending on the picture.
The authors add a simple idea: a hidden helper variable (call it “zeta”) that explains the differences between the two items in a pair.
- You can think of “zeta” as a note that says what changed: “camera moved right,” “object sped up,” or “time gap was longer.”
- Instead of forcing the model to directly match one item to the other, the model first edits the first item’s embedding using “zeta” to make it closer to the second item’s embedding. This is like adjusting a recipe (“add more salt”) so it tastes like the target dish.
They present two versions:
- AdaSSL-V (Variational): It learns a probability distribution for the helper variable “zeta” given the pair, and uses a standard SSL loss plus a regularizer (a kind of penalty) to keep “zeta” from becoming a shortcut that just copies the answer. This connects to “mutual information,” a measure of how much the two embeddings share, and provides a new lower bound that the model can optimize.
- AdaSSL-S (Sparse): It predicts “zeta” directly and encourages it to be sparse (only a few changes at a time), because in real data usually only a few factors change between frames or images. It uses simple, modular edits like tiny rank‑1 adjustments to the embedding.
Why add “zeta”? Because the paper proves that the noise between embeddings of natural pairs isn’t uniform—its size depends on where you are in the embedding space. Imagine stretching a flat sheet over a ball: some areas stretch more than others, so small changes in the original sheet become different-size changes on the ball. Many SSL methods assume the noise is the same everywhere, which isn’t true, and that can cause them to lose important details. The helper variable lets the model adapt to these changes.
This approach works for both:
- Contrastive SSL (which explicitly pushes positives together and negatives apart).
- Distillation-based SSL (like BYOL), which predicts one embedding from another using a separate “predictor” network.
Main findings and why they matter
Across a set of experiments, AdaSSL consistently learns better, more general features than standard methods.
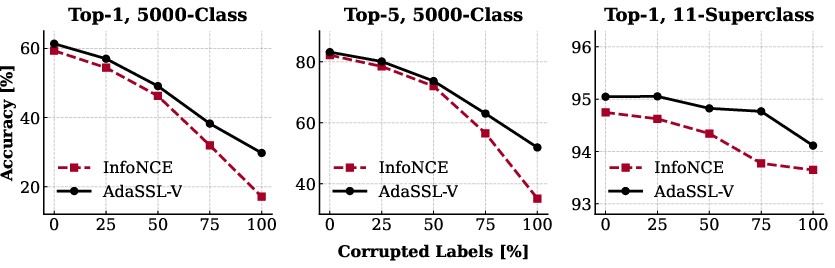
- Numerical (synthetic) data: When the relationship between pairs is complex (different amounts of noise in different places, or even multiple possible futures), standard SSL falters—especially out of distribution (OOD), when the test data looks different from the training data. AdaSSL handles these conditions much better.
- Synthetic 3D images (3DIdent dataset): AdaSSL recovers the true underlying factors that generate the images (like position, light, color) more accurately and more “disentangled” than baselines. In plain terms, it learns features where each number represents a clear, separate property.
- Natural images (CelebA faces): AdaSSL keeps fine details that matter for downstream tasks (like attribute classification) and is more robust to real-world changes than methods that rely only on artificial augmentations.
- Large-scale noisy pairs (iNat-2021): AdaSSL is more resilient when the paired data contains mismatches or noise.
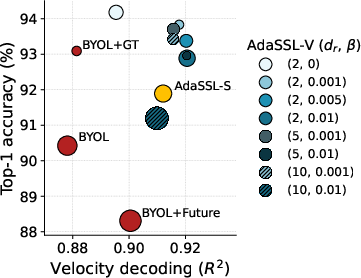
- Videos (Moving-MNIST with randomness): AdaSSL captures uncertain motion (like changes in velocity) without hurting recognition accuracy. In other words, it learns both “what” and “how it moves.”
These results suggest that modeling uncertainty with a helper variable helps SSL learn features that are:
- More detailed and less washed out.
- More robust when the test data differs from training data.
- Better suited for tasks that depend on structured changes over time.
Implications and impact
- More realistic learning: Instead of relying on hand-made image tweaks, AdaSSL learns from naturally occurring pairs like video frames or image–caption pairs, which reflect real-world changes.
- Better generalization: By modeling uncertainty and variation explicitly, models are less likely to throw away useful information and more likely to perform well on new, shifted data.
- Stronger world models: For robotics and autonomous systems, understanding that one state can lead to multiple futures is crucial. AdaSSL’s design fits that reality.
- Flexible foundation: AdaSSL works with different SSL styles (contrastive and distillation) and can be added to existing objectives with a simple regularization term.
- Practical takeaway: If your data involves structured changes—like actions, camera motion, or variable descriptions—AdaSSL helps you capture those changes without losing the core content.
In short, the paper shows that embracing the structure and uncertainty in natural data pairs, instead of flattening it away, leads to richer, more reliable learned representations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, assumptions, and open directions that future work could address to strengthen, generalize, or better understand the proposed AdaSSL framework.
- Theoretical coverage beyond contrastive SSL
- Extend the mutual-information lower bound and guarantees to distillation-based objectives (e.g., BYOL) rather than relying on heuristic applicability.
- Characterize when the AdaSSL objective provably improves relative to standard SSL (tightness conditions, required model class, batch size K).
- Assumptions underlying Proposition 1
- Relax the and full-rank Jacobian assumptions (diffeomorphic , ) to settings where encoders are not locally invertible or smooth (e.g., ReLU networks).
- Quantify how often heteroscedasticity persists when embeddings are not strictly normalized to the unit sphere or when is noisy/stochastic.
- Provide constructive guidance on how heteroscedasticity varies with embedding geometry (e.g., hypersphere vs. Euclidean), including implications for similarity design.
- Latent variable modeling capacity and identifiability
- Replace factorized Gaussian and with richer families (mixtures, flows) to capture multimodal or heavy-tailed uncertainty; assess impact on disentanglement and MI bounds.
- Formalize conditions under which AdaSSL recovers (a subset of) latent factors up to affine transformations—beyond empirical results on 3DIdent.
- Analyze whether the sparse edit assumption (AdaSSL-S) is necessary or sufficient for identifiability in natural data, and how violations affect performance.
- Editing function design and capacity control
- Systematically study the trade-offs between additive, linear, low-rank modular, and MLP edit functions for accuracy vs. disentanglement, with principled model-selection criteria.
- Develop a procedure to select the edit latent dimensionality (e.g., via validation of MI bounds, sparsity constraints, or minimum-description-length).
- Investigate structured edit spaces (e.g., Lie groups, equivariant modules) aligned to known symmetries to improve controllability and generalization.
- Regularization and hyperparameter selection
- Provide a principled method (e.g., PAC-Bayesian, MDL, or variational diagnostics) to set the trade-off parameter instead of manual tuning.
- In AdaSSL-S, augment the sparsity penalty with information-theoretic constraints (e.g., limiting ) to prevent residual shortcutting in non-zero edit dimensions.
- Study the sensitivity of AdaSSL to temperature , batch size , and negative-sampling protocols; quantify how these affect the MI bound and learned uncertainty.
- Negative pairs and InfoNCE mechanics with latent edits
- Analyze the effect of conditioning on when scoring mismatched —does this introduce bias or loosen the InfoNCE bound?
- Explore alternative constructions where negatives also use a compatible latent sample (e.g., ) and compare bounds and empirical behavior.
- Practical availability and quality of “natural” pairs
- Characterize robustness of AdaSSL to noisy or mismatched natural pairings (e.g., temporal breaks, unrelated captions) with controlled corruption levels and failure modes.
- Provide guidance for constructing natural pairs when only weak cues (e.g., temporal proximity, coarse metadata) are available; quantify the gains vs. standard augmentations.
- Scalability and compute considerations
- Measure training/inference overhead from latent-variable components (q/p networks, sampling, Gumbel-Sigmoid) at large scales (e.g., ViT-B/L on web-scale image–text or video datasets).
- Investigate training stability (variance of gradient estimators, reparameterization noise) and propose variance-reduction techniques tailored to AdaSSL.
- Broader benchmarking and downstream tasks
- Evaluate on more realistic video datasets (e.g., Ego4D, Kinetics) with complex multi-agent uncertainty; report both recognition and state estimation metrics.
- Test image–text (CLIP-style) and audio–visual pairings to verify AdaSSL’s benefits under genuinely multimodal, heteroscedastic, and multimodal conditionals.
- Go beyond linear probes to structured tasks (segmentation, detection, 3D pose, policy learning) to assess whether AdaSSL preserves task-relevant uncertainty.
- Measuring and validating information preservation
- Empirically estimate mutual information or bounds during training to verify that AdaSSL increases in practice.
- Diagnose whether gains stem from better conditional modeling vs. increased representational entropy; develop metrics to disentangle these effects.
- Causal interpretation and interventions
- Validate whether learned corresponds to causal influences (e.g., actions, temporal gaps) via interventional studies or synthetic environments with known causal structure.
- Examine risks of learning spurious invariances or confounding (e.g., background changes) and propose causal regularizers or intervention-based curricula.
- Design choices in AdaSSL-S with distillation
- Clarify the “additional care” required when applying AdaSSL-S to BYOL; specify failure modes, recommended predictor architectures, and initialization/temperature schedules.
- Compare predictor designs (shared vs. asymmetric, depth, normalization) and their interactions with sparse edits and EMA targets.
- Prior specification and sampling at inference
- Study how the choice of affects controllable retrieval and editing (e.g., coverage, diversity, fidelity) and propose priors that balance realism with exploration.
- Analyze calibration of the prior (uncertainty estimates) and propose diagnostics/interventions (e.g., temperature scaling, Bayesian model averaging).
- Integration with standard augmentations
- Investigate hybrid training regimes that combine natural pairs with standard augmentations; determine when augmentations help or hurt structural invariance.
- Develop policies that adapt augmentation strength dynamically based on estimated conditional uncertainty (heteroscedasticity) in the data.
- Fairness, privacy, and societal considerations
- Assess whether encoding structural variations from natural pairs introduces demographic biases (e.g., in CelebA) or privacy risks (e.g., re-identification across frames).
- Propose techniques (e.g., fairness-aware regularization, privacy-preserving pairing) to mitigate such risks without degrading representational benefits.
Glossary
- AdaGVAE: A weakly supervised variational autoencoder variant designed to encourage disentangled representations via adaptive group priors. "including β-VAE and AdaGVAE."
- AdaSSL: The paper’s adaptive self-supervised learning framework that introduces a latent variable to better capture conditional uncertainty between positive pairs. "The resulting method, which we call AdaSSL, applies to both contrastive and distillation-based SSL objectives"
- AdaSSL-S: A sparse, modular variant of AdaSSL that predicts a latent edit vector and regularizes its sparsity to model structured changes. "AdaSSL-S(parse) realizes this idea."
- AdaSSL-V: A variational variant of AdaSSL that introduces a variational distribution over the latent variable and yields a tractable mutual-information bound. "We call this variant of our method AdaSSL-V(variational)."
- AnInfoNCE: An anisotropic extension of InfoNCE that learns per-dimension weights to handle direction-dependent noise. "InfoNCE and AnInfoNCE are the contrastive baselines that account for isotropic and anisotropic noise in , respectively."
- anisotropic noise: Noise whose variance differs across directions or dimensions of the embedding space. "learn that has constant, anisotropic noise"
- BYOL: A distillation-based self-supervised learning method that uses an online predictor to match a target encoder updated via an exponential moving average. "We illustrate our findings with BYOL~\citep{grill2020bootstrap}, the backbone of many recent successful distillation-based methods"
- causal representation learning (CRL): A framework aiming to recover latent generative factors of data consistent with an underlying causal model. "From the lens of causal representation learning (CRL)"
- chain rule of mutual information: An identity that decomposes mutual information between variables into conditional and joint components. "Specifically, by the chain rule of MI,"
- contrastive SSL: A family of self-supervised learning methods that bring positive pairs closer and push negatives apart, typically via a contrastive loss. "Contrastive SSL optimizes a lower bound on the mutual information "
- data generating process (DGP): The underlying (often latent) stochastic mechanism that produces observed data. "latent factors of the data generating process~(DGP)."
- DCI disentanglement score: A metric for quantifying disentanglement, completeness, and informativeness of learned representations. "We evaluate (a) disentanglement in the learned embeddings with the DCI disentanglement score"
- diffeomorphic: A smooth, invertible mapping with a smooth inverse between manifolds. "let be diffeomorphic to its image"
- distillation-based SSL: Self-supervised methods that train an online network to predict a target network’s embeddings, often using asymmetry and stop-gradients. "Distillation-based SSL methods are sometimes appealing"
- exponential moving average (EMA): A smoothing technique that updates target network parameters by an exponential average of online parameters. "where is the exponential moving average"
- Gumbel-Sigmoid estimator: A differentiable relaxation used to approximate discrete selections (e.g., L0 penalties) with continuous variables during training. "made differentiable through the Gumbel-Sigmoid estimator"
- heteroscedastic: Having input-dependent (non-constant) conditional variance. "is necessarily heteroscedastic"
- homoscedastic noise: Noise with a constant variance across inputs or conditions. "Here, “constant” refers to isotropic, homoscedastic noise."
- H-InfoNCE: A heteroscedastic extension of InfoNCE that conditions the similarity weighting on the current sample to model input-dependent noise. "we introduce H-InfoNCE, which extend AnInfoNCE to account for heteroscedastic noise"
- identifiability: The property of being recoverable up to permissible transformations (e.g., affine) from observed data. "and (b) the recovery of latent factors, i.e., “empirical” identifiability, up to affine transformations"
- InfoNCE: A contrastive loss that lower-bounds mutual information by comparing similarity of positive pairs to negatives sampled from a batch. "we focus on sample-contrastive methods based on InfoNCE"
- Inverse-Wishart distribution: A distribution over positive-definite matrices, commonly used as a prior for covariance matrices. " is sampled from an Inverse-Wishart distribution"
- JEPA (joint-embedding predictive architectures): Architectures that predict future or masked embeddings using latent variables to capture uncertainty. "joint-embedding predictive architectures~(JEPAs)"
- Kullback–Leibler divergence: A measure of divergence between two probability distributions. "where denotes the Kullback-Leibler divergence"
- latent variable: An unobserved variable introduced to account for hidden structure or uncertainty in observed data. "we introduce a latent variable to account for this uncertainty"
- Lie group transformations: Continuous transformations with group structure (e.g., rotations) used to model structured changes in latent factors. "models the change between latent factors as Lie group transformations"
- mutual information (MI): A measure of statistical dependence that quantifies shared information between random variables. "derive a variational lower bound on the mutual information between paired embeddings."
- unit sphere (hypersphere): The set of unit-norm vectors in a Euclidean space, often used as a normalized embedding space. "Let denote the -dimensional unit sphere."
- out-of-distribution (OOD): Data that differ from the training distribution, often used to assess generalization robustness. "in- and out-of-distribution~(OOD)"
- stop-gradient: An operation preventing gradient flow through a branch of the network during backpropagation. "with a stop-gradient on the target"
- variational distribution: An approximating distribution used to make inference tractable, often parameterized and optimized via variational methods. "We first model with a variational distribution "
- variational lower bound: A tractable lower bound (e.g., ELBO) on an intractable objective derived via variational inference. "derive a variational lower bound on the mutual information between paired embeddings."
- von Mises–Fisher (vMF) distribution: A probability distribution on the hypersphere characterized by a mean direction and concentration parameter. "reduces to von Mises-Fisher (vMF) distributions"
- world modeling: Learning models that capture the dynamics and uncertainties of future states in sequential data like videos. "For example, in world modeling~\citep{ha2018world,ha2018recurrent,hafner2025mastering,assran2025v},"
- factorized Gaussians: A product of independent univariate Gaussian distributions used to simplify modeling of multivariate posteriors or priors. "modeling both as factorized Gaussians."
Practical Applications
Overview
The paper introduces AdaSSL, a family of self-supervised learning (SSL) methods that learn from naturally paired data by explicitly modeling one-to-many mappings and input-dependent (heteroscedastic) uncertainty between paired embeddings. It proposes:
- AdaSSL-V (variational): a latent-variable extension to contrastive and distillation-based SSL with a tractable lower bound on mutual information via InfoNCE and a KL regularizer between a learned posterior and prior over the latent “edit” variable.
- AdaSSL-S (sparse): a deterministic, sparsity-regularized latent edit with modular, low-rank adapters that enact sparse, factor-specific changes in the embedding.
Across numerical, synthetic, image, and video settings, AdaSSL improves disentanglement, fine-grained feature retention, out-of-distribution (OOD) robustness, and world modeling under uncertainty.
Below are practical, real-world applications derived from these findings, methods, and innovations.
Immediate Applications
These can be piloted or deployed with current tooling and data, especially where naturally paired data (e.g., adjacent video frames, multi-view images, product variants, weakly matched captions) are available.
- Fine-grained image understanding and retrieval in consumer media and e-commerce
- Sectors: software, retail/e-commerce, media
- Applications:
- Train AdaSSL-pretrained encoders on product catalogs using natural pairs (e.g., different angles/colors of the same SKU) to improve attribute retrieval, visual search, and variant linking.
- Controllable retrieval by “editing” embeddings along learned latent directions (pose, lighting, hue) to find near-duplicates with specified factor changes.
- Tools/workflows: extend existing InfoNCE/BYOL pipelines with
AdaSSL-VorAdaSSL-Smodules; add an “embedding edit” APIt(f(x), zeta)for search backends. - Assumptions/dependencies: access to reliable natural pairs or weak matches from metadata; robust negative sampling; compute for variational components (if using AdaSSL-V).
- Robust representation pretraining for OOD generalization
- Sectors: software/ML platforms, autonomous systems, cybersecurity (anomaly detection)
- Applications:
- Pretrain foundation encoders on videos/multi-view datasets with AdaSSL to learn heteroscedastic-aware invariances, improving linear probe performance under covariate shift.
- Replace augmentation-heavy recipes with natural-pair pretraining to retain fine-grained features while remaining invariant to structured, real-world changes.
- Tools/workflows: drop-in replacement for the similarity/predictor stage in InfoNCE/BYOL; evaluation harnesses that include OOD linear probes.
- Assumptions/dependencies: availability of naturally paired data; selection of β scaling in regularizer; careful monitoring to avoid shortcut “leakage” where the latent edit encodes the target too directly.
- Video world modeling for downstream tasks (forecasting, tracking, and planning support)
- Sectors: robotics, autonomous driving, sports analytics, industrial monitoring
- Applications:
- Train AdaSSL on successive frames to capture multiple plausible futures (e.g., an agent turning left or right) and decode motion states (velocity/acceleration) without labels.
- Use edited embeddings to probe future-aware features in trackers or planning heuristics.
- Tools/workflows: 3D CNN or ViT encoders with AdaSSL-V; sampling from
p_theta(zeta | x)to stress-test downstream predictors; plug embeddings into standard tracking pipelines. - Assumptions/dependencies: frame-to-frame pairing quality; GPU capacity for variational sampling; downstream planner still needs explicit decision-making logic.
- Label-efficient transfer for specialized domains
- Sectors: healthcare (non-diagnostic pretraining), manufacturing, remote sensing
- Applications:
- Pretrain AdaSSL encoders on unlabeled video/image streams (e.g., machine operations, satellite captures) to cut annotation needs for fine-grained detection/classification.
- Improve OOD resilience where test conditions differ (lighting, angle, device).
- Tools/workflows: domain-specific miner for natural pairs (temporal adjacency, co-registered multi-sensor pairs); linear or shallow probes for downstream tasks.
- Assumptions/dependencies: non-diagnostic use in regulated domains unless clinically validated; domain shift between pretraining and fine-tuning still requires evaluation.
- Causal representation learning (CRL) baselines and benchmarking
- Sectors: academia (ML, vision, causal discovery)
- Applications:
- Use AdaSSL as a strong, reconstruction-free CRL baseline on 3D-rendered or synthetic datasets to study disentanglement and factor recovery under sparse latent transitions.
- Probe the effect of edit function complexity (linear vs. MLP) on disentanglement.
- Tools/workflows: public CRL benchmarks (e.g., 3DIdent); open-source AdaSSL code; DCI metrics; regression-on-latents evaluations.
- Assumptions/dependencies: synthetic data with known factors for validation; appropriate regularization (β, sparsity).
- Heteroscedastic-aware SSL as an engineering pattern
- Sectors: software/ML infrastructure
- Applications:
- Adopt AdaSSL or simpler heteroscedastic baselines (e.g., H-InfoNCE) when switching to normalized embeddings on hyperspheres to avoid mismatch-induced errors.
- Add tests for input-dependent variance in paired embeddings; adjust similarity/predictor to account for it.
- Tools/workflows: internal SSL libraries; CI checks with OOD evaluation and variance diagnostics; ablations for dot-product vs. heteroscedastic similarity.
- Assumptions/dependencies: logging and monitoring of conditional variance proxies (e.g., prediction residuals) during training.
- Privacy-conscious data leverage
- Sectors: policy/compliance, enterprise IT
- Applications:
- Use naturally paired but unlabeled internal content (e.g., consecutive video frames) for pretraining without sharing sensitive labels; keep embeddings in-house.
- Tools/workflows: on-prem AdaSSL training; data governance workflows for pair mining and deletion policies.
- Assumptions/dependencies: internal policies permit unlabeled training; ensure embeddings don’t leak sensitive attributes beyond intended utility.
Long-Term Applications
These need further research, scaling, validation, or cross-disciplinary integration before reliable deployment.
- Multi-future and counterfactual planning in embodied AI
- Sectors: robotics, autonomous vehicles, logistics
- Applications:
- Use AdaSSL’s latent edit variable as a compact handle over environmental or action-conditional modes to plan under uncertainty, enabling robust counterfactual reasoning and risk-aware navigation.
- Tools/workflows: integrate
zetasampling into model-predictive control or diffusion-based planners; couple with policy learning that conditions on edited embeddings. - Assumptions/dependencies: safety validation under distribution shift; calibrated uncertainty; tight integration with control stacks and simulation-to-real transfer.
- Composable, controllable multimodal foundation models
- Sectors: software, media, education
- Applications:
- Train unified encoders on image–text, video–audio, and diagram–caption pairs that preserve fine-grained, factor-specific information while allowing controllable edits in embedding space (e.g., “same scene, different lighting” queries).
- Tools/workflows: multimodal AdaSSL extensions; inference APIs exposing factor knobs inferred from
p_theta(zeta | x); vector databases supporting edited-query search. - Assumptions/dependencies: scalable natural-pair mining across modalities; disentanglement that generalizes beyond training distributions; human-in-the-loop evaluations for controllability.
- Medical video and longitudinal state modeling (decision support, not diagnosis)
- Sectors: healthcare
- Applications:
- Learn patient-state representations from endoscopy, ultrasound, or ICU streams that capture multiple plausible progressions; assist triage or monitoring systems via uncertainty-aware trends.
- Tools/workflows: hospital data pipelines for temporal pairing; uncertainty dashboards to visualize alternative trajectories; strict privacy-preserving training.
- Assumptions/dependencies: clinical validation; bias and safety audits; regulated deployment pathways; domain shift handling (device, site, patient mix).
- Industrial digital twins with uncertainty-aware embeddings
- Sectors: energy, manufacturing, predictive maintenance
- Applications:
- Build digital twins whose internal representations encode plausible, factorized transitions under interventions (load changes, temperature shifts); support scenario analysis and maintenance scheduling.
- Tools/workflows: sensor-video fusion with natural temporal pairing; coupling AdaSSL with simulators for “what-if” analysis; embedding monitors for drift and OOD.
- Assumptions/dependencies: robust synchronization of multimodal streams; faithful mapping between embedding edits and real-world factors; long-horizon validation.
- Finance and econometrics: regime-aware representation learning
- Sectors: finance
- Applications:
- Learn representations from naturally paired market snapshots (e.g., close→open, LOB updates) that reflect heteroscedastic, multimodal transitions; improve downstream models for risk estimation or stress testing.
- Tools/workflows: temporal pair mining under strict compliance; edited-embedding stress scenarios; downstream linear probes for explainability.
- Assumptions/dependencies: data licensing; market microstructure shifts; guardrails to prevent misuse and overfitting to historical idiosyncrasies.
- Policy and standards for SSL evaluation under distribution shift
- Sectors: policy, standards bodies, regulators
- Applications:
- Establish evaluation protocols that include OOD linear probes, heteroscedastic diagnostics, and multi-future metrics for SSL models used in safety-critical settings.
- Tools/workflows: benchmark suites with standardized natural-pair datasets; disclosure templates for training data pairing strategies and uncertainty modeling choices.
- Assumptions/dependencies: consensus on metrics; participation from academia/industry; versioned datasets with governance.
- Edge deployment with controllable, compact adapters
- Sectors: mobile, AR/VR, IoT
- Applications:
- Use AdaSSL-S style low-rank, sparse “edit” adapters for on-device personalization (e.g., camera scene understanding tuned to user environment) without full model retraining.
- Tools/workflows: adapter training pipelines; on-device latent-edit controls for user customization; privacy-preserving fine-tuning.
- Assumptions/dependencies: efficient inference; battery/latency constraints; UX for exposing controllable factors safely.
Cross-Cutting Assumptions and Dependencies
- Data pairing quality: effectiveness depends on naturally paired data that reflect real-world generative changes (temporal adjacency, multi-view, weak labels). Mispaired data can induce shortcuts or spurious invariances.
- Regularization and identifiability: β (KL or sparsity) controls the trade-off between capturing uncertainty and avoiding leakage; too weak leads to shortcuts, too strong hampers utility.
- Edit function design: linear/modular edits favor disentanglement and interpretability; complex MLP edits increase capacity but may entangle factors.
- Geometry mismatch and heteroscedasticity: normalized embeddings on spheres can induce input-dependent variance; using AdaSSL (or at minimum, heteroscedastic-aware similarity) mitigates this.
- Compute and engineering: variational training (AdaSSL-V) adds sampling and KL terms; sparse adapters (AdaSSL-S) add discrete relaxation overhead. Both are compatible with standard PyTorch/JAX pipelines.
- Evaluation: always include OOD probes, multi-future diagnostics, and ablations vs. augmentation-heavy baselines to ensure fine-grained features are retained rather than discarded.
- Safety and compliance: for sensitive domains (healthcare, finance, AV), require domain-specific validation, uncertainty calibration, monitoring for drift, and documentation of pairing strategies and failure modes.
These applications leverage AdaSSL’s core insight: explicitly modeling structured, input-dependent uncertainty in natural pairs leads to richer, more generalizable representations suitable for modern, real-world ML systems.
Collections
Sign up for free to add this paper to one or more collections.