- The paper establishes that full-batch GD with a truncated quadratic activation attains the information-theoretic limit, outperforming one-pass SGD.
- It employs power-method dynamics and a two-phase process, achieving weak recovery in O(log d) steps and exact recovery afterwards.
- The findings imply that minor activation modifications and data reuse can decisively close the statistical gap in nonlinear feature learning.
Sample Complexity Separation in Single-Index Learning: Full-Batch Gradient Descent vs. One-Pass SGD
The study systematically investigates whether full-batch gradient descent (GD), which repeatedly reuses the entire training dataset, can surpass one-pass stochastic gradient descent (SGD) in terms of sample complexity for nonlinear models—specifically, single-index models with quadratic activations. The results rigorously establish a provable separation in statistical efficiency, with full-batch GD achieving learning at the information-theoretic limit under minimal algorithmic modification, thereby contradicting the sample complexity lower bound intrinsic to one-pass SGD in the same regime.
Problem Setting and Theoretical Motivation
The setting is the d-dimensional single-index model: each i.i.d. data sample is xi∼N(0,Id) with label yi=σ(⟨xi,θ⋆⟩), where θ⋆ is an unknown signal direction and σ is the activation (quadratic or truncated quadratic). The objective is to estimate θ⋆ via empirical risk minimization, leveraging either full-batch gradient methods or one-pass SGD.
Classically, for deep linear regression, reusing data via multiple passes has demonstrable improvements in sample complexity. However, for single-index models with nonlinearity (and, in particular, for quadratic σ), it has been established that one-pass SGD requires n≳dlogd samples for weak recovery, consistent with a computational-statistical gap due to the information exponent of the link function. Spectral estimators, in contrast, reach the information-theoretic limit of n≳d for recovery, raising the open question of whether full-batch GD can inherit this optimal sample efficiency for nonlinear feature learning models.
Negative Results: Full-Batch Gradient Flow at Quadratic Activation
The first principal result is a negative statement: minimizing the correlation loss over the sphere using full-batch gradient flow with unbounded quadratic activation (σ(z)=z2) does not improve sample complexity compared to online SGD. The analysis, rooted in random matrix theory, shows that unless n≫dlogd, the principal eigenvector obtained by the full-batch power method is asymptotically uncorrelated with the signal, and no weak recovery is achieved.
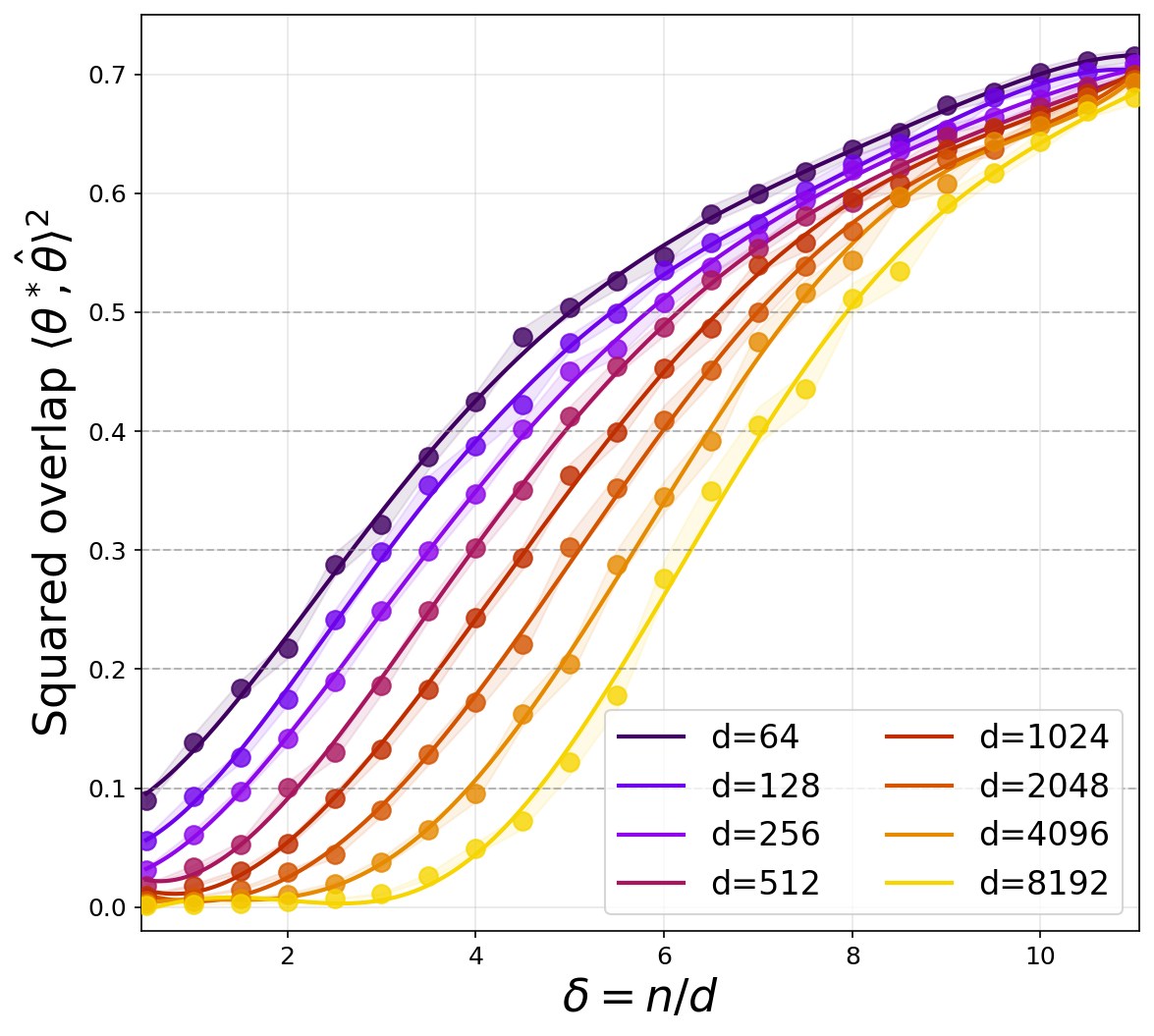
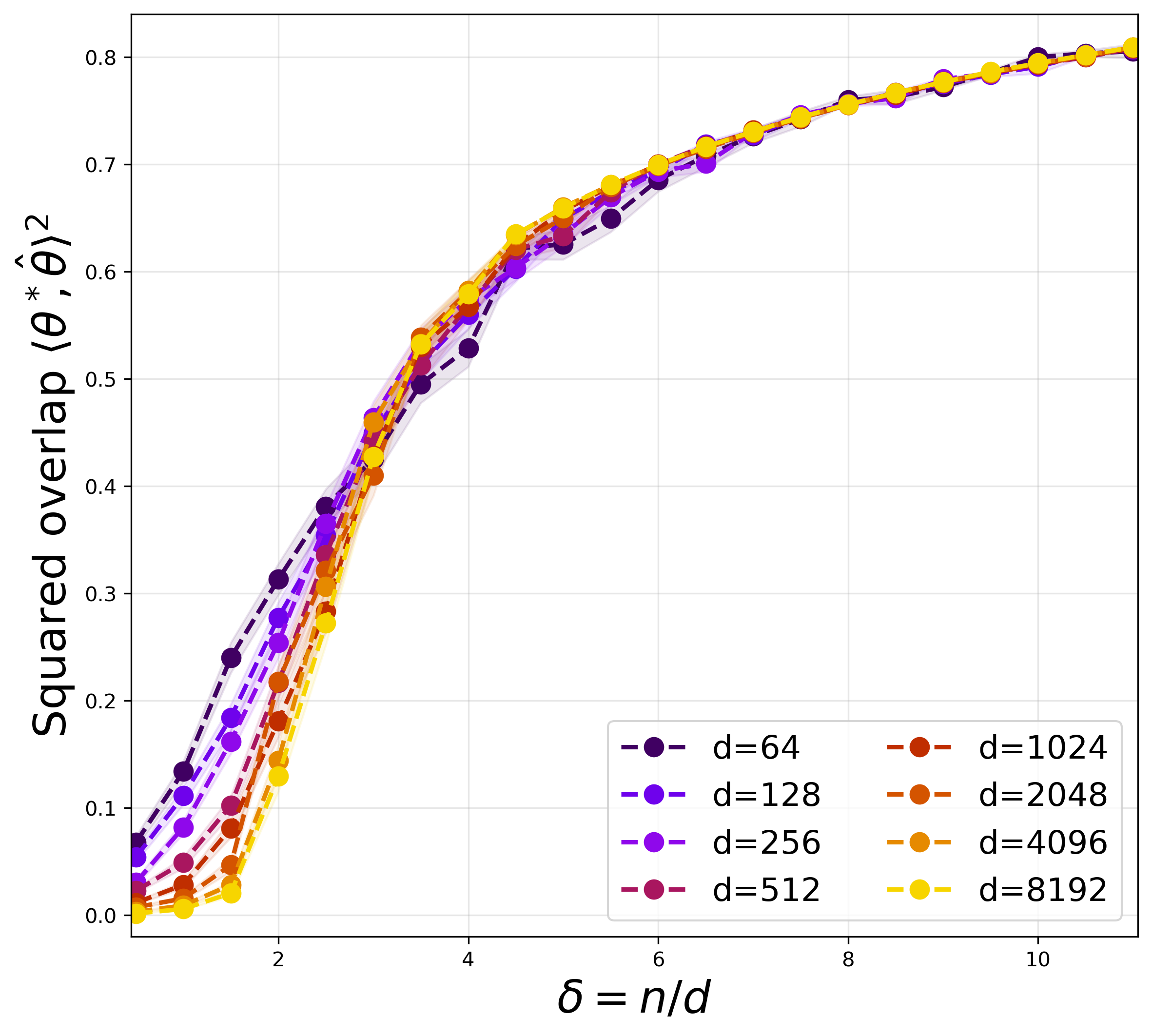
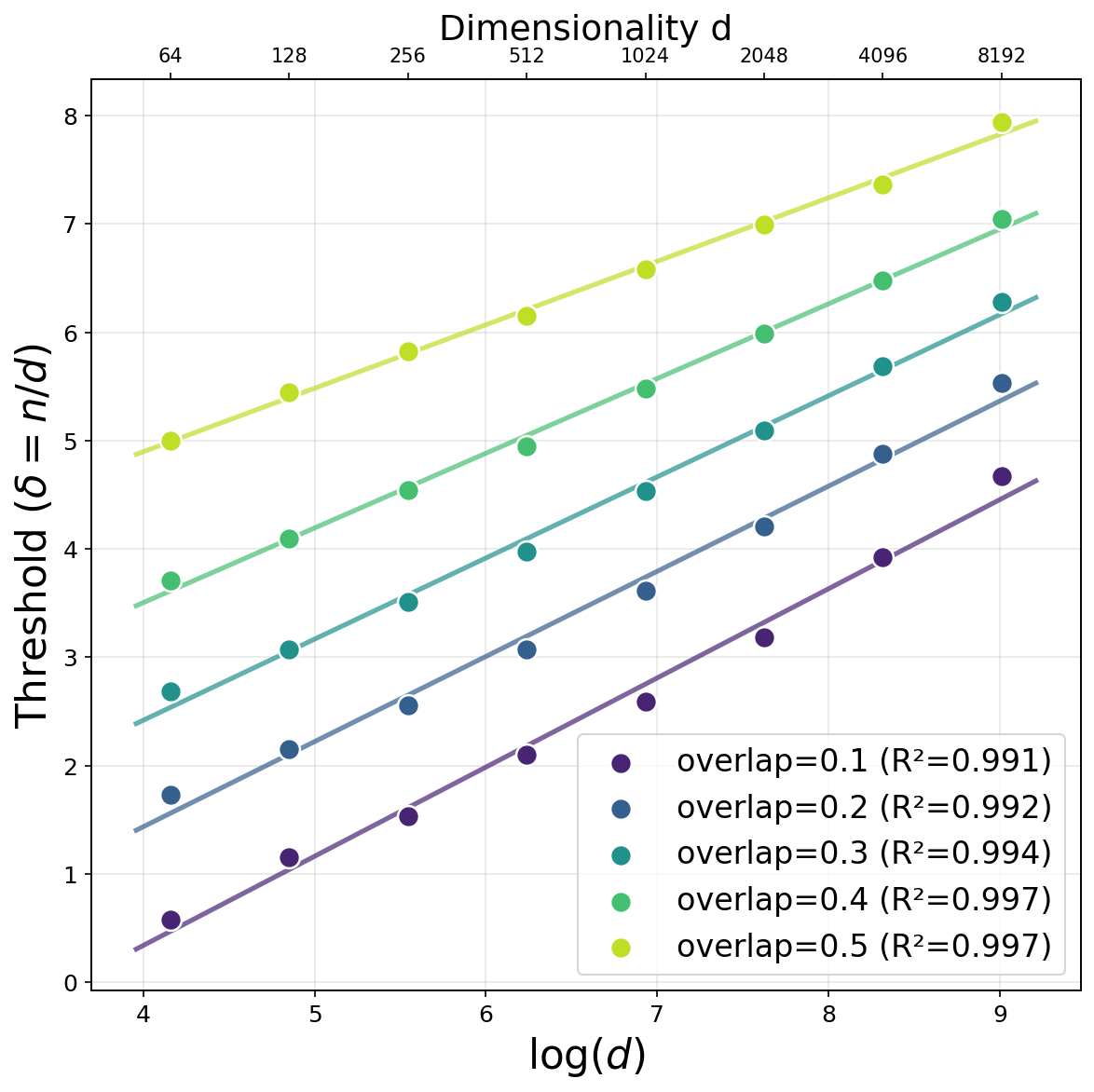
Figure 1: Overlap as a function of δ=n/d for unbounded quadratic activation, demonstrating that the recovery threshold increases with d, in precise agreement with the predicted n/d≃logd scaling.
This aligns with the spectral properties of random matrices defined by quadratic nonlinearities without truncation, where the absence of a BBP transition precludes informative eigenstructure in high dimensions under sample constraints. Hence, under the quadratic map, the logd gap from the information-theoretic lower bound persists for standard full-batch methods, just as for one-pass SGD.
A minimal, theoretically motivated modification—truncating the quadratic activation—completely alters the landscape. With σ(z) defined as a smooth or hard truncation of z2, the power-method–like dynamics implemented by full-batch gradient flow now operate on a matrix ensemble whose principal eigenvector retains alignment with θ⋆ even at n≃d.
The authors establish that, for truncated activations, full-batch spherical gradient flow achieves weak recovery with high probability as soon as n≳d, provided M (the truncation threshold) is chosen reasonably. The proof leverages a uniform BBP-type transition for the time-dependent matrices along the optimization trajectory and a uniform VC concentration argument for indicator processes induced by the truncation.
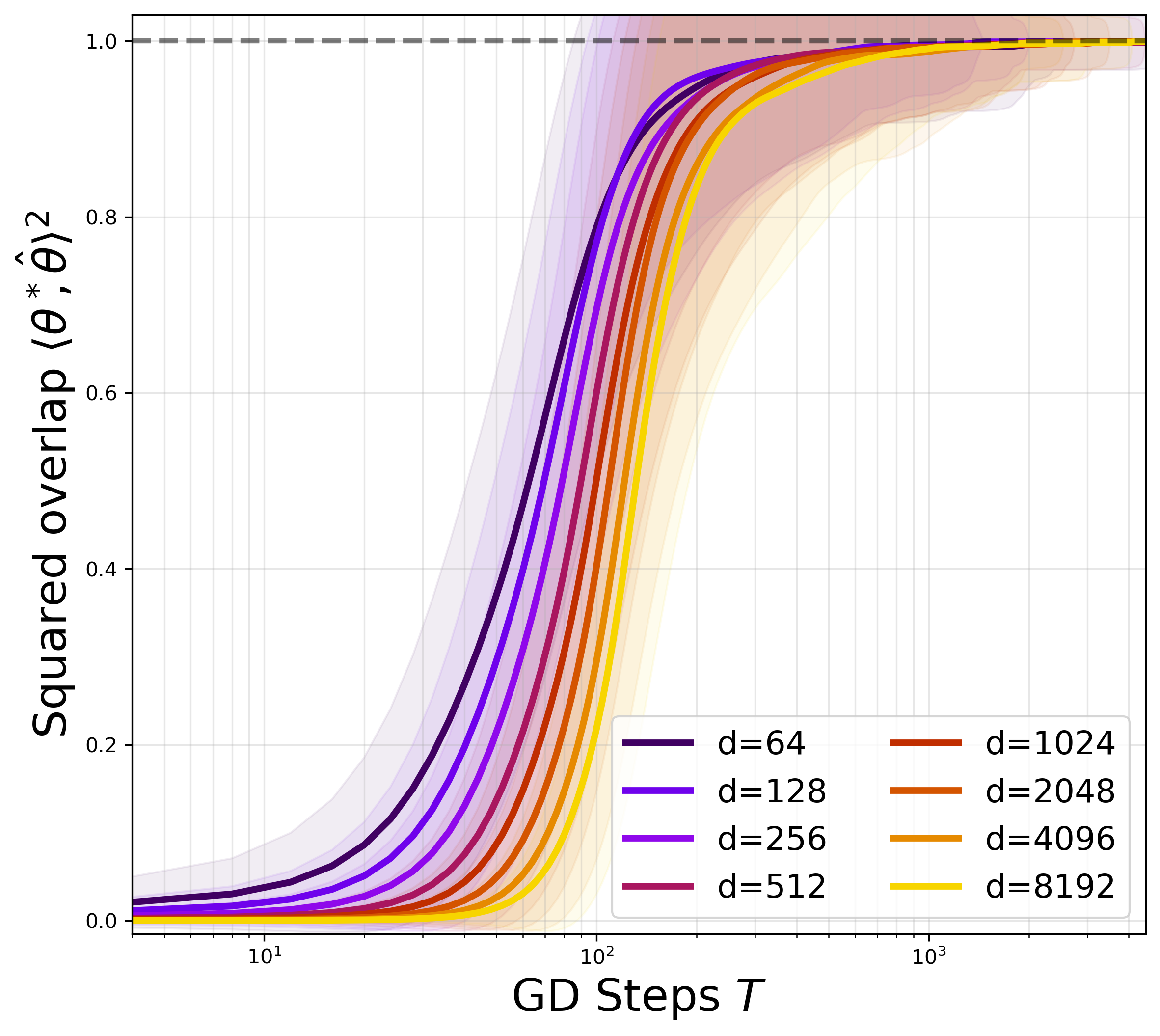
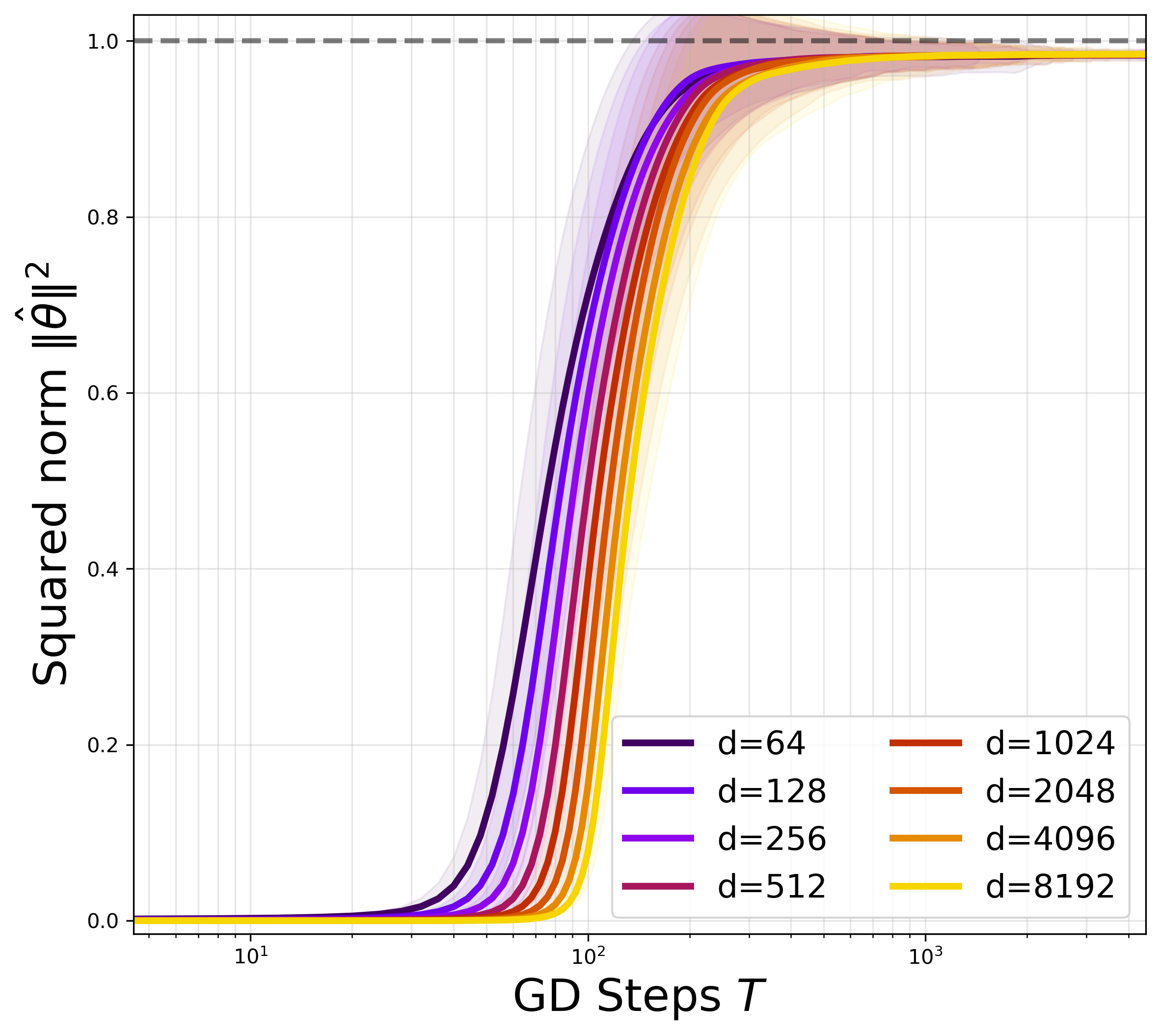
Figure 2: Convergence of the direction (overlap growth vs. number of GD steps) with truncated quadratic activation, indicating that both overlap and recovery threshold become independent of d for fixed δ=n/d.
The implications are significant: full-batch gradient dynamics can close the statistical-computational gap intrinsic to one-pass SGD in this class, by simply bounding the activation. This provides the first rigorous sample complexity separation in a non-convex, nonlinear feature learning problem, showing that algorithmic data reuse indeed yields a provable statistical gain.
Strong Recovery and Iteration Complexity: Squared Loss and Small Initialization
To move beyond landscape analysis and quantify iteration complexity and strong recovery, the work next studies full-batch gradient descent on the squared loss with truncated activation, starting from small (sphere-scale) initialization. The analysis reveals a two-phase dynamics:
- Search Phase: The angle between the iterate and θ⋆ decreases to a small constant and parameter norm grows geometrically, both within O(logd) steps, as the early-stage dynamics are well-approximated by the corresponding power method.
- Refinement Phase: Once within a constant angle and norm band, local strong convexity enables geometric error decay, leading to exact recovery at an exponential rate in the number of steps.
The iteration complexity to reach strong recovery is T≳logd, matching population-level scaling and contrasting with the prohibitive guarantees for online SGD in the same regime.
Implications, Extensions, and Future Directions
The findings have salient theoretical and methodological implications:
- Algorithmic Principle: Full-batch data reuse can enable learning at the information-theoretic limit in non-convex models, when coupled with minimal preprocessing (truncation).
- Landscape and Trajectory Analysis: Uniform random matrix and VC theory arguments allow tight non-asymptotic control necessary for establishing global convergence rates in high-dimensional regimes.
- Scaling Laws: The results motivate precise computation of phase transition constants and connection with dynamical mean-field theory for multistep learning algorithms.
- Model Generality: The design principles extend to other link functions with higher information exponent and to multi-index models, potentially broadening the class of learning problems where full-batch GD outperforms online variants.
For practical AI systems, these results highlight how seemingly minor modifications in model class or optimization protocol (e.g., bounded nonlinearities and data reuse) can decisively close or widen computational-statistical gaps.
Conclusion
This work rigorously demonstrates that, for single-index models with quadratic activation, full-batch gradient descent can, with a simple truncation, bridge the logarithmic sample size gap separating one-pass SGD from information-theoretic limits. This result is established by uniting random matrix theory, VC arguments, and dynamical analysis to prove both weak and strong recovery with linear-in-d sample size and logarithmic iteration complexity. The insights garnered here pave the way for deeper understanding of the precise conditions dictating the statistical superiority of multi-pass algorithms in nonlinear learning regimes.