Hierarchical Entity-centric Reinforcement Learning with Factored Subgoal Diffusion
Abstract: We propose a hierarchical entity-centric framework for offline Goal-Conditioned Reinforcement Learning (GCRL) that combines subgoal decomposition with factored structure to solve long-horizon tasks in domains with multiple entities. Achieving long-horizon goals in complex environments remains a core challenge in Reinforcement Learning (RL). Domains with multiple entities are particularly difficult due to their combinatorial complexity. GCRL facilitates generalization across goals and the use of subgoal structure, but struggles with high-dimensional observations and combinatorial state-spaces, especially under sparse reward. We employ a two-level hierarchy composed of a value-based GCRL agent and a factored subgoal-generating conditional diffusion model. The RL agent and subgoal generator are trained independently and composed post hoc through selective subgoal generation based on the value function, making the approach modular and compatible with existing GCRL algorithms. We introduce new variations to benchmark tasks that highlight the challenges of multi-entity domains, and show that our method consistently boosts performance of the underlying RL agent on image-based long-horizon tasks with sparse rewards, achieving over 150% higher success rates on the hardest task in our suite and generalizing to increasing horizons and numbers of entities. Rollout videos are provided at: https://sites.google.com/view/hecrl


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI agents (like robots) to reach complex goals in places with many different things (objects) using only recorded data. The key idea is to break big goals into smaller, easier “mini-goals” that focus on just a few objects at a time. The authors build a two-part system:
- A “doer” that knows how to move toward a given goal.
- A “planner” that suggests helpful mini-goals along the way.
This approach makes it much easier for the agent to succeed in long, multi-step tasks, even when it only gets a reward at the end (sparse rewards) and when it sees the world through images.
Key Objectives
The paper asks:
- How can we help an AI agent reach long, complicated goals by breaking them into simpler steps?
- Can we make these mini-goals focus on just a few objects (like one cube) instead of changing everything at once?
- Can this work with image inputs, where the agent has to understand what’s in a picture without human labels?
- Will this method improve success rates on tough tasks and still work when the number of objects increases?
How It Works (Methods)
Think of the agent like a player in a game, and the system like a team with a coach and a player:
- The player (low-level “doer”): A goal-conditioned reinforcement learning agent. Given a current state and a mini-goal, it decides what action to take next. It also has a “value function,” which is like a map that estimates how close any state is to a goal.
- The coach (high-level “planner”): A special generator called a “diffusion model” that suggests possible mini-goals. A diffusion model is a type of AI that’s good at making realistic samples (it’s similar to how image generators create pictures by removing noise step by step). Here, it proposes mini-goals that are likely to be valid states the agent can reach soon.
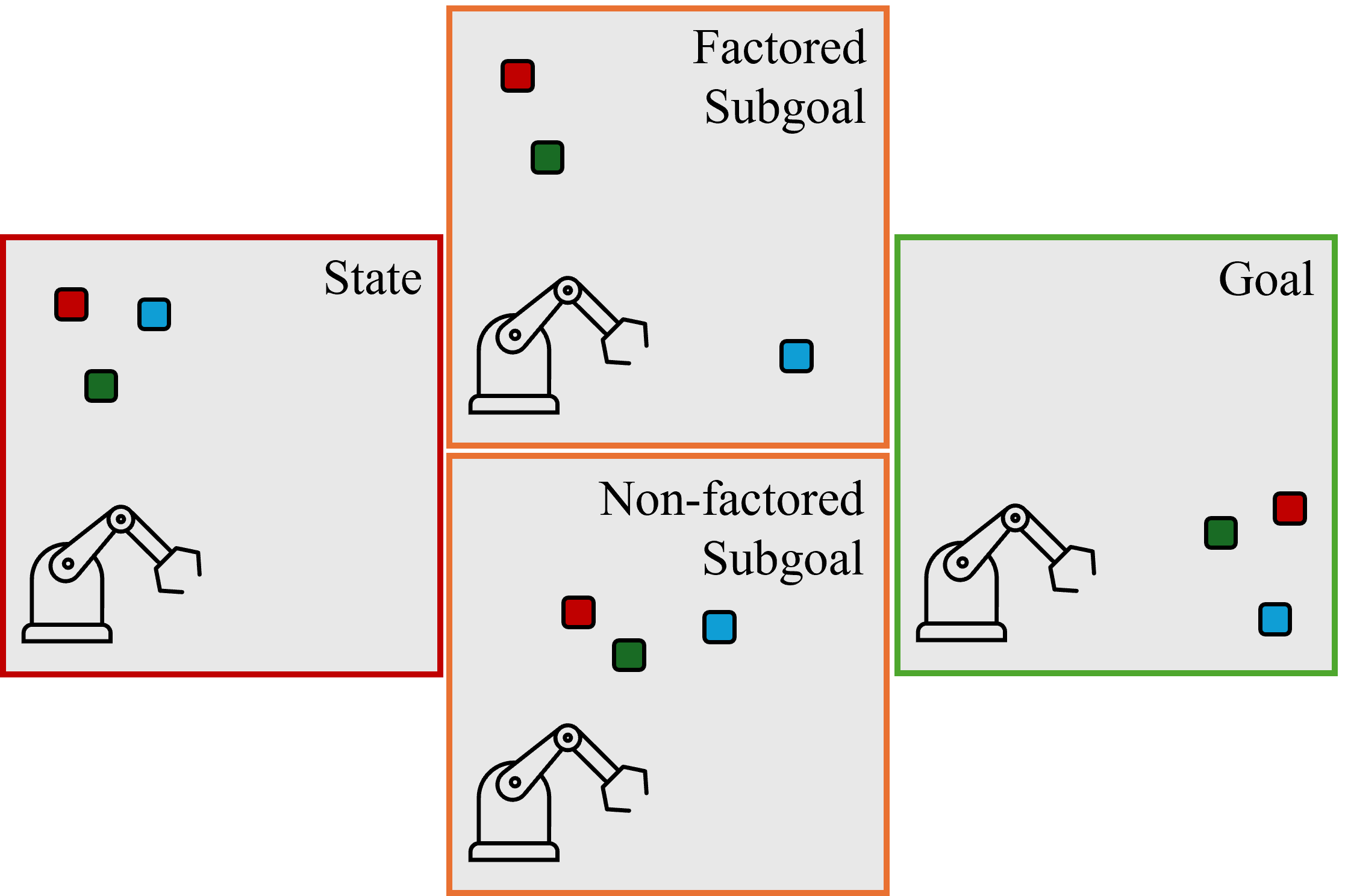
- Entity-centric design: The agent represents the scene as a set of entities (like each cube, drawer, button, etc.). Instead of treating the scene as one big blob, it treats each object separately. This helps it handle many objects without getting overwhelmed and allows it to create mini-goals that change only a few objects at a time.
- Seeing from images: To turn images into these object-like entities, the system uses an unsupervised object-centric vision model (called DLP). It learns to detect and represent the important parts of a scene without human labels.
- Choosing good mini-goals:
- The planner samples several candidate mini-goals from the diffusion model.
- The player’s value map filters out mini-goals that are too hard to reach right now.
- From the remaining candidates, it picks the one that brings the agent closest to the final goal.
- The player follows this mini-goal for a short time, then the process repeats with a new mini-goal.
This setup is modular: the player and planner are trained separately on the same offline dataset, and combined later. It’s flexible and can work with different RL algorithms.
Main Findings
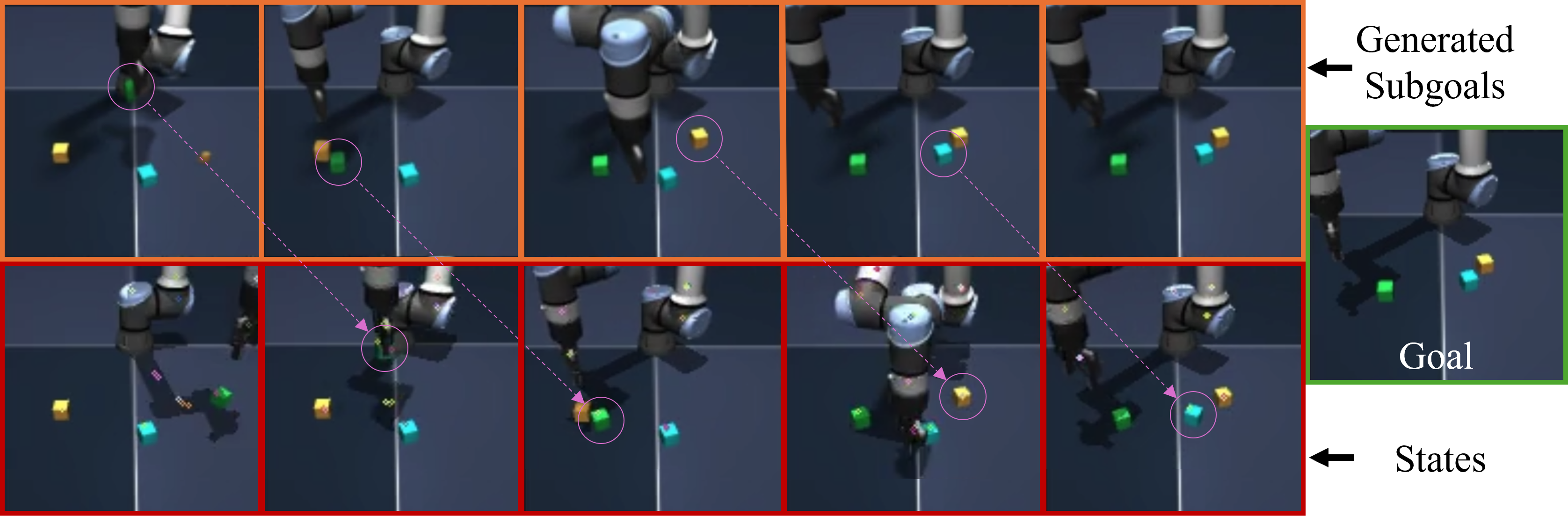
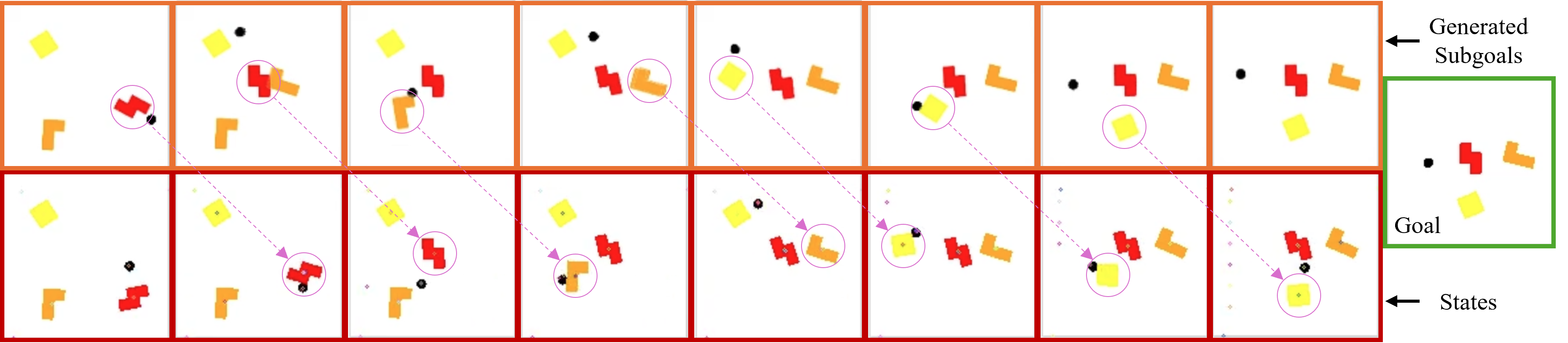
Big performance boosts: Across several challenging tasks (like moving/stacking cubes, pushing Tetris-like blocks, and interacting with drawers and buttons), the method significantly improved success rates compared to strong baselines. On the hardest image-based task (moving 3 cubes), it achieved over 150% higher success than the standard agent without mini-goals.
- Better mini-goals: The diffusion planner often suggests mini-goals that change only one or a few objects at a time. That’s easier for the player to achieve and leads to steady progress.
- Value function helps: Using the value map to filter and select mini-goals matters. Picking random mini-goals or using a simpler deterministic regression model (which tends to “average” different futures) led to worse performance and more confusing mini-goals that change too many objects at once.
- Works with images: By learning object-like representations from images (without labels), the system can plan and act in visually complex scenes.
- Generalization: The method can work reasonably well when the number of objects increases (more cubes), though performance naturally drops as tasks get harder. It still does better than non-hierarchical agents, showing promise for scaling.
Why It’s Important
- Easier long tasks: Breaking big goals into well-chosen, object-focused mini-goals helps the agent handle long, multi-step problems with sparse rewards.
- Handles many objects: Thinking in terms of entities (objects) reduces the complexity of planning, making the method suitable for robotics, multi-robot coordination, and complex video game settings.
- Modular and practical: Because the coach and player are trained separately and combined later, this approach can plug into existing RL systems.
- Image-ready: It doesn’t need hand-labeled data; it can learn to understand scenes from images and use that to plan.
Overall, this research shows a clear path to more reliable and scalable robot and agent behavior in complex environments: think in terms of objects, generate realistic mini-goals, filter them with a “how-close-am-I” map, and solve long tasks step by step.
Knowledge Gaps
Below is a concise, actionable list of unresolved knowledge gaps, limitations, and open questions identified in the paper. Each point highlights what is missing or uncertain and suggests concrete directions for future work.
- Lack of a principled way to set or learn the policy competence radius: the reachability threshold is hand-tuned and may be miscalibrated due to value-function bias; develop adaptive methods to estimate (e.g., via value uncertainty, short-horizon rollouts, or calibration with validation goals).
- Fixed subgoal horizon K: the subgoal Diffuser is trained with a fixed K without automatic selection; investigate data-driven or value-aware procedures to infer K per state/goal or to generate variable-horizon subgoals.
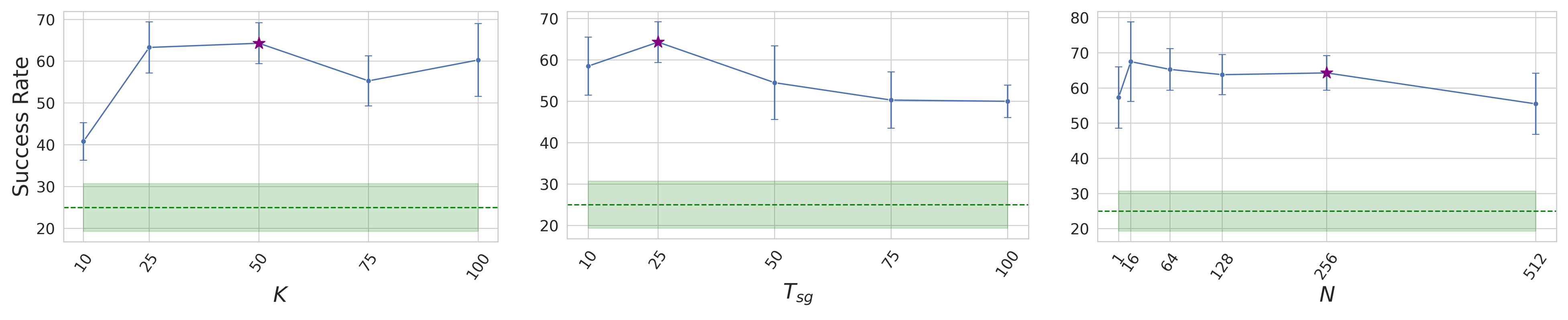
- Sensitivity to hyperparameters not systematically studied: performance dependence on N (subgoal samples), , , number of diffusion steps, and subgoal model capacity remains unclear; provide sensitivity analyses and robust default-setting strategies.
- No guarantees of subgoal feasibility or reachability: subgoals are filtered by a potentially miscalibrated value function with no dynamics-based feasibility check; explore integrating learned dynamics, constraint sets, or reachability predictors to ensure valid, executable subgoals.
- Limited handling of value approximation noise: subgoal selection and “go-to-goal if closer” logic rely on potentially noisy values, risking oscillations or myopic choices; study robust selection mechanisms (e.g., value ensembles, uncertainty-aware tie-breaking, or consistency checks across timesteps).
- Distribution shift in subgoal space: the Diffuser is trained on behavior data but used to propose subgoals that may be out-of-distribution for the low-level policy; investigate OOD detection for subgoals, confidence-aware filtering, or joint training/fine-tuning of value and subgoal models to align supports.
- Absence of guided diffusion: subgoal generation uses unguided sampling plus ex-post filtering; compare against value- or reward-guided diffusion (e.g., classifier-free guidance, Q-guidance, energy-based guidance) to reduce sample waste and improve subgoal optimality.
- Computational latency and real-time viability: although using ~10 diffusion steps, runtime with N candidates per decision (and multi-view encoders) is not reported; profile and optimize latency, and study performance–latency trade-offs for deployment on physical robots.
- Entity duplication and validity issues in image-based subgoals: qualitative results show duplicated or inconsistent entities with DLP-based latents; design deduplication constraints, slot-consistency losses, or set-matching objectives to enforce coherent subgoal sets.
- Reliance on an unsupervised object-centric encoder: performance hinges on DLPv2 quality; examine robustness to occlusions, clutter, partial observability, varying lighting, and domain shift, and compare alternative object-centric methods or co-training strategies with RL.
- Multi-view perception and fusion left underexplored: the approach uses multiple views in some tasks but does not analyze calibration, fusion strategies, or robustness to missing views; study multi-view alignment, 3D consistency, and cross-view data association for subgoal generation.
- Assumption of (approximate) independent controllability: factored subgoals implicitly assume limited cross-entity coupling; analyze failure cases where manipulating one entity disturbs others and incorporate models or constraints to account for coupled dynamics.
- Limited evaluation on stochastic dynamics or sensor noise: current tasks appear largely deterministic; test robustness under stochastic transitions, sensor noise, and actuation uncertainty.
- No formal guarantees or theoretical analysis: convergence, bounded suboptimality, or monotonic progress under value approximation error are not established; develop theoretical conditions and performance bounds for subgoal MPC with learned values.
- Fixed subgoal rollout horizon T_sg: the agent does not adapt when a subgoal is reached early or is unreachable late; explore event-driven subgoal termination criteria (e.g., achieved-subgoal detectors) and adaptive policies.
- Goal specification realism: tasks use goal states (images/states) with sparse indicator rewards; extend to more realistic goal modalities (language, relational goals, partial goals) and to shaped or multi-objective rewards.
- Limited baseline coverage: compare against additional hierarchical/planning baselines (e.g., guided diffusion planners, tree search in subgoal space, world-model MPC) to contextualize gains beyond HIQL/IQL and EC-Diffuser.
- Quantitative subgoal-quality metrics missing for image domains: sparsity and validity are assessed qualitatively; devise quantitative metrics (e.g., entity-change counts via latent matching, consistency scores, or reconstruction-based plausibility) to track subgoal quality at scale.
- Data quality and coverage effects not characterized: study how dataset size, behavior optimality, and goal coverage influence subgoal diversity/quality and downstream performance; include ablations across data regimes.
- Scaling laws with number of entities/horizon not established: while zero-shot generalization is shown up to 6 objects, performance degrades; investigate curriculum strategies, modular training, or progressive scaling, and report scaling curves and failure modes.
- Integration with online fine-tuning: the method is offline; explore offline-to-online adaptation (e.g., conservative exploration in subgoal space, iterative refinement of value/subgoal models) to improve robustness and scaling.
- Calibration of value as a distance metric: the approach relies on as a discounted distance; assess calibration quality, asymmetry effects, and alternative learned distance metrics for reachability filtering and subgoal ranking.
- Generality across underlying GCRL algorithms: claims of modularity are not empirically validated beyond IQL-based variants; test with other value-based GCRL methods (e.g., CQL/TD3-BC goal-conditioned, distributional critics) to confirm compatibility and benefits.
- Safety and constraint handling: while the framework “is compatible with other constraints,” no safety-critical or constraint-satisfaction experiments are provided; add constraint-aware subgoal generation and evaluate under hard safety requirements.
Practical Applications
Immediate Applications
The following use cases can be implemented today by leveraging the paper’s modular HECRL stack (value-based goal-conditioned RL + entity-factored subgoal diffusion) and available datasets/simulators, with realistic engineering effort.
- Robotics (manufacturing/warehousing) — Multi-object manipulation sequences (bin-picking, kitting, sorting, depalletizing)
- What: Use entity-factored subgoals to sequence long-horizon tasks that touch a subset of parts at a time (e.g., pick/place multiple items into kits), improving reliability under sparse rewards.
- Tools/Workflow:
- Collect offline logs (teleoperation, scripted policies) for target tasks.
- Train object-centric encoder (e.g., DLPv2) for image-based scenes or use state-factor APIs if available.
- Train value-based GCRL policy (e.g., IQL/HIQL variants) and independent subgoal Diffuser on the same dataset.
- Deploy the subgoal sampler with value-based reachability filtering; execute T_sg steps per subgoal via existing low-level controllers.
- Assumptions/Dependencies:
- Sufficient offline coverage of relevant object interactions.
- Reliable object-centric perception in deployment domain.
- Safety wrapper for execution (e.g., collision checks), since value-based filtering does not enforce constraints.
- Robotics (lab/assistive) — Drawer/door/button manipulation and multi-object scene reconfiguration
- What: Achieve scene goals (open/close, press, move single objects) with factored subgoals that isolate the next entity to manipulate.
- Tools/Workflow:
- Adopt the paper’s Scene-like tasks to lab robots; integrate multi-view cameras and DLPv2.
- Use the HECRL subgoal generator to choose minimal-change subgoals conditioned on a goal image.
- Assumptions/Dependencies:
- Stable perception for articulated objects.
- Well-tuned reachability threshold for the value function.
- Game AI (simulation/video games) — Long-horizon, multi-entity behaviors from play logs
- What: Learn NPC policies from offline gameplay by generating subgoals focused on subsets of entities (e.g., collect resource A before engaging B).
- Tools/Workflow:
- Pretrain object-centric representations from gameplay frames.
- Train value-based GCRL on play logs; train subgoal Diffuser on short-horizon future states.
- Integrate subgoal selection at inference for more coherent long-horizon strategies.
- Assumptions/Dependencies:
- Access to large, diverse offline play logs.
- Entity-centric perception (e.g., in-game state APIs or object-centric vision).
- RPA/GUI Automation (enterprise software) — Multi-step UI workflows with entity-centric UI parsing
- What: Treat UI elements as entities; propose subgoals that modify a subset of on-screen elements (e.g., fill a form section, then submit).
- Tools/Workflow:
- Use screen-object detectors/segmenters (e.g., DETR/SAM-derived) to build an entity-state.
- Train offline from annotated UI interaction logs; deploy subgoal Diffuser to propose minimal UI changes per step.
- Assumptions/Dependencies:
- Robust UI entity extraction across themes/resolutions.
- Offline logs include representative tasks and failure modes.
- Visual MPC augmentation (robotics research) — Value-guided state-space planning with diffusion
- What: Replace action-sequence optimization with value-filtered, diffusion-sampled subgoals in image or state space.
- Tools/Workflow:
- Plug the subgoal Diffuser + value function into existing MPC loops; adjust thresholds to match policy competence radius.
- Assumptions/Dependencies:
- Low-latency inference (entity-centric diffusion with ~10 steps is feasible on commodity GPUs).
- Calibrated value function on the operating distribution.
- Academic research/education — Benchmarks and modular baselines for hierarchical RL
- What: Use HECRL to study hierarchy, compositionality, and multi-entity structure in long-horizon tasks.
- Tools/Workflow:
- Adopt released code/datasets; replicate PPP-Cube/Scene/Push-Tetris; vary entity counts to test generalization.
- Assumptions/Dependencies:
- Access to simulation and compute for representation pretraining and RL.
- Smart home orchestration — Multi-device routines with factored subgoals (no vision needed)
- What: Devices (lights, blinds, HVAC, appliances) as entities; subgoal generator sequences minimal device changes toward a target scene (e.g., “movie mode”).
- Tools/Workflow:
- Use discrete/factored device states with a value-based GCRL policy trained on historical routines; subgoal Diffuser proposes next device subset to actuate.
- Assumptions/Dependencies:
- Consistent device APIs and logs; predictable actuation latencies.
- Basic constraint checks (e.g., power limits, user presence).
Long-Term Applications
These use cases require further research, scaling, or integration work (e.g., stronger perception, safety, regulatory approval, or online adaptation).
- Autonomous driving — Entity-factored subgoal planning for interactive scenarios
- What: Generate reachable, high-value subgoals that focus on relevant agents (e.g., yield to a specific vehicle, lane changes) under sparse/rare outcomes.
- Potential Products/Workflows:
- Offline learning from fleet logs; entity-centric perception stacks feeding HECRL planner that proposes semantic subgoals to a certified low-level controller.
- Assumptions/Dependencies:
- Strong scene understanding and tracking; rigorous safety constraints and verification.
- Regulatory approval; extensive edge-case coverage.
- Multi-robot coordination (warehouses, hospitals, construction) — Task allocation via factored subgoals
- What: Assign subgoals that modify disjoint subsets of entities (items/locations) to different robots to reduce interference and improve throughput.
- Potential Products/Workflows:
- Central HECRL planner sampling subgoals; robots execute locally with value-based reachability checks and collision constraints.
- Assumptions/Dependencies:
- Scalable multi-robot value estimation; reliable inter-robot communication.
- Constraint-aware subgoal filtering (safety, traffic rules).
- Household general-purpose robots — Long-horizon multi-object tasks in unstructured homes
- What: Tidy-up, load dishwasher, laundry sorting with subgoals that isolate specific objects or appliances per step.
- Potential Products/Workflows:
- Learning from human demonstrations/teleop; robust unsupervised object-centric perception in-the-wild; HECRL as a high-level planner on top of skill libraries.
- Assumptions/Dependencies:
- Robust generalization in open-world perception; dexterous low-level skills.
- Safety/reliability in close human interaction.
- Healthcare robotics — Surgical or clinical assistance with instrument/asset coordination
- What: Subgoal planning over instruments or supplies (entities) to achieve complex protocols with minimal changes per step.
- Potential Products/Workflows:
- Train from procedure logs and simulations; integrate with supervisory control and clinical constraints.
- Assumptions/Dependencies:
- Extremely high safety and interpretability; domain-specific perception.
- Regulatory certification and liability frameworks.
- Energy systems (microgrids/buildings) — Factored control over distributed assets
- What: Treat assets (batteries, HVAC zones, PV inverters) as entities; propose reachable subgoals (setpoint changes) for subsets to approach cost/comfort goals.
- Potential Products/Workflows:
- Offline learning from operational logs; HECRL planner outputs sequenced setpoint targets with constraint-aware filters.
- Assumptions/Dependencies:
- Accurate and timely state estimation; safety and reliability constraints.
- Non-stationary demand and market dynamics require adaptation.
- Finance — Portfolio rebalancing as entity-centric subgoal planning
- What: Assets as entities; propose partial rebalances (sparse changes) toward long-horizon risk/return goals learned from offline market data.
- Potential Products/Workflows:
- HECRL generating candidate target weights with reachability measured by transaction cost/market impact-aware value functions.
- Assumptions/Dependencies:
- Non-stationarity and causality challenges; compliance and risk limits.
- Need for robust evaluation and human-in-the-loop oversight.
- Policy and governance — Standards for safe offline RL with generative high-level planners
- What: Define dataset-sharing, auditing, and validation protocols for diffusion-driven subgoal planners and value-based reachability checks.
- Potential Products/Workflows:
- Benchmarks and test suites for multi-entity tasks; certification processes for hierarchical planners.
- Assumptions/Dependencies:
- Cross-industry collaboration; clear incident reporting and red-teaming practices.
- Tooling ecosystem — Commercial HECRL components
- What: Packaged modules for:
- Object-centric encoders (DLPv2-like) with domain adapters.
- Subgoal Diffuser service (fast inference, ~10 steps) with APIs for ROS and game engines.
- Value-based reachability filters with tunable thresholds and safety plugins.
- Assumptions/Dependencies:
- Vendor-agnostic interfaces; latency targets; model update pipelines for dataset drift.
Notes on feasibility across applications:
- The approach’s success hinges on (1) a competent value function with a non-negligible policy competence radius; (2) quality of object-centric representations for image-based domains; (3) adequate offline dataset coverage of entity-level transitions; (4) integration of constraint/safety-aware subgoal filtering in safety-critical deployments; (5) compute/latency budgets for diffusion inference (mitigated by the entity-centric design and short denoising schedules).
Glossary
- Advantage-Weighted Regression (AWR): An offline RL regression objective that weights updates by estimated advantages to bias learning toward higher-return actions. "the use of diffusion by training a deterministic Transformer-based subgoal generator with an Advantage-Weighted Regression (AWR,~\citep{peng2019advantage}) objective as in HIQL."
- Behavioral cloning: A supervised learning approach that learns a policy by imitating actions from a dataset of behavior. "EC-Diffuser~\citep{qi2025ecdiffuser}: an entity-centric diffusion-based behavioral cloning method."
- Chamfer distance: A metric for comparing two point sets (or unordered sets), often used to align predicted and target sets by measuring nearest-neighbor distances. "We adjust the standard regression loss to a loss based on the Chamfer distance (see App.~\ref{apdx:impl} for details)."
- Combinatorial state-space: A state space whose size grows combinatorially with the number of entities or factors, making learning and planning more difficult. "offline GCRL methods (including HIQL) continue to struggle with combinatorial state-spaces and image observations."
- Compositional generalization: The ability to generalize to new combinations of known components or entities by leveraging factorized structure. "and facilitate compositional generalization~\citep{lin2023survey}."
- Conditional diffusion model: A diffusion generative model that conditions on inputs (e.g., current state and goal) to sample structured outputs (e.g., subgoals). "a factored subgoal-generating conditional diffusion model."
- Deep Latent Particles (DLP): An unsupervised object-centric representation that models scenes as sets of latent particles corresponding to entities. "Deep Latent Particles (DLP,~\cite{daniel2022unsupervised}) representation."
- Diffuser: A diffusion-based planner that models distributions over states or trajectories to guide decision-making. "diffusion planners (also referred to as diffusers)~\citep{janner2022diffuser, ajay2023is, lu2025what} which model distributions of state or state-action trajectories."
- Diffusion models: Generative models that learn to reverse a noise-adding process to synthesize complex, multi-modal data. "Diffusion models~\citep{sohl2015deep, ho2020denoising} learn to generate data by reversing a process that gradually adds noise to clean samples, training a neural network to perform step by step denoising."
- Entity Interaction Transformer (EIT): A Transformer architecture tailored to model interactions among entity embeddings in an entity-centric RL agent. "integrating the Entity Interaction Transformer (EIT) architecture with IQL."
- Entity-centric diffusion: A diffusion approach operating over sets of entities, biasing generation toward selectively copying or sparsely modifying entity tokens. "We show that the bias induced by entity-centric diffusion encourages entity-factored subgoals, which simplifies the subtask for the RL policy."
- Entity-centric RL: An RL paradigm that represents states as sets of entities, exploiting factorization to simplify learning in multi-entity domains. "Entity-centric RL considers environments which can be described as a collection of entities i.e., ."
- Entity-factored subgoals: Subgoals that alter only a sparse subset of entities relative to the current state, simplifying low-level control. "produce entity-factored subgoals, i.e., subgoals with sparse changes to entities compared to the current state."
- Goal relabeling: A technique (e.g., hindsight experience replay) that treats visited states as goals to improve learning with sparse rewards. "via goal relabeling~\citep{andrychowicz2017hindsight}"
- Goal-Conditioned Reinforcement Learning (GCRL): RL where the policy and value function are conditioned on a goal state, aiming to reach goals from diverse initial states. "Goal-Conditioned RL (GCRL)~\citep{kaelbling1993learning} provides a useful framework for training goal-reaching agents..."
- HIQL: A hierarchical offline GCRL method that extracts a two-level policy from a single goal-conditioned value function. "The resulting algorithm, HIQL, offers a simple instantiation of hierarchy in the offline GCRL setting."
- Hierarchical RL: RL methods that operate across multiple timescales or abstractions by decomposing tasks into subgoals or subpolicies. "Hierarchical RL enables reasoning over multiple timescales and levels of abstraction by exploiting temporal structure within sequential data~\citep{klissarov2025discovering}."
- Implicit Q-Learning (IQL): An offline RL algorithm that learns policies from value estimates without explicit policy improvement via standard Q-learning targets. "IQL: an agent based on IQL~\citep{kostrikov2022offline}."
- Inductive bias: Architectural or modeling assumptions that guide learning toward solutions consistent with domain structure. "the underlying factored structure can be leveraged and incorporated as inductive bias to significantly simplify learning."
- Markov Decision Process (MDP): A formal model of sequential decision-making with states, actions, transitions, and rewards. "GCRL~\citep{kaelbling1993learning} considers a Markov Decision Process ..."
- Model Predictive Control (MPC): A control strategy that optimizes actions over a finite horizon and replans at each step using updated state estimates. "receding horizon control or Model Predictive Control (MPC)"
- Object-centric representations: Learned image encodings that decompose scenes into entities or parts to provide factored state estimates for downstream RL. "It leverages unsupervised object-centric representations and the factored structure in multi-entity environments to produce entity-factored subgoals..."
- Offline RL: Learning policies purely from a fixed dataset of trajectories without additional environment interaction. "Our work focuses on the offline setting, where the agent learns from a fixed dataset of suboptimal state-action trajectories."
- Policy competence radius: The range of states around a given state where value estimates provide a reliable signal to extract the policy. "which we will refer to as the policy competence radius and denote or for simplicity of notation."
- Receding horizon control: A planning approach that repeatedly optimizes over a moving short-term horizon; closely related to MPC. "receding horizon control or Model Predictive Control (MPC)"
- Temporal Difference (TD) learning: A value-learning method that bootstraps estimates via successive time-step differences, potentially compounding errors over long horizons. "Temporal Difference (TD) learning~\citep{sutton1988learning} leads to errors which compound over the timestep horizon."
- Transformer: An attention-based neural architecture well-suited for set- and sequence-structured inputs, used for entity-centric modeling and diffusion denoising. "set-based policy architectures (e.g., Transformers~\citep{vaswani2017attention}) better handle the combinatorial complexity of the state-space..."
- Value function: A mapping that estimates expected discounted return (or distance) given a state and goal, used for reachability and subgoal selection. "a policy and value function "
- Value signal-to-noise ratio: The ratio between meaningful value differences and approximation noise; increases with state-goal distance and limits policy extraction. "\citet{park2023hiql} refer to this as the value signal-to-noise ratio, which grows with the distance between states."
- Vector-Quantized Variational Autoencoder (VQ-VAE): A generative model with discrete latent codes used to learn compact image representations for RL. "latent image-based representations extracted using a pretrained VQ-VAE~\citep{van2017neural}"
Collections
Sign up for free to add this paper to one or more collections.