Joint Learning of Hierarchical Neural Options and Abstract World Model
Abstract: Building agents that can perform new skills by composing existing skills is a long-standing goal of AI agent research. Towards this end, we investigate how to efficiently acquire a sequence of skills, formalized as hierarchical neural options. However, existing model-free hierarchical reinforcement algorithms need a lot of data. We propose a novel method, which we call AgentOWL (Option and World model Learning Agent), that jointly learns -- in a sample efficient way -- an abstract world model (abstracting across both states and time) and a set of hierarchical neural options. We show, on a subset of Object-Centric Atari games, that our method can learn more skills using much less data than baseline methods.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Joint Learning of Hierarchical Neural Options and Abstract World Model — Explained for Teens
Overview: What is this paper about?
This paper introduces AgentOWL, an AI that learns new skills quickly by reusing old ones and by “imagining” how the world will change before it tries things for real. The skills are organized like a toolbox with simple tools at the bottom and more complex tools built from them at the top. The “world model” is like the AI’s mental map of what happens when it uses a skill. Together, these let the AI plan better and learn faster, especially in tricky video games that need long, smart action sequences.
Goals and Questions: What did the researchers want to find out?
The paper focuses on a few key questions:
- How can an AI learn a lot of skills in sequence, each harder than the last, without needing tons of trial-and-error?
- Can the AI build complex skills from simpler ones (like Lego pieces), and use a mental model to plan before acting?
- Will this approach help in hard games (like certain Atari games) where random guessing does not work?
- Which parts of the method are truly necessary for the AI to succeed?
Methods: How does AgentOWL work?
Think of AgentOWL as a careful gamer:
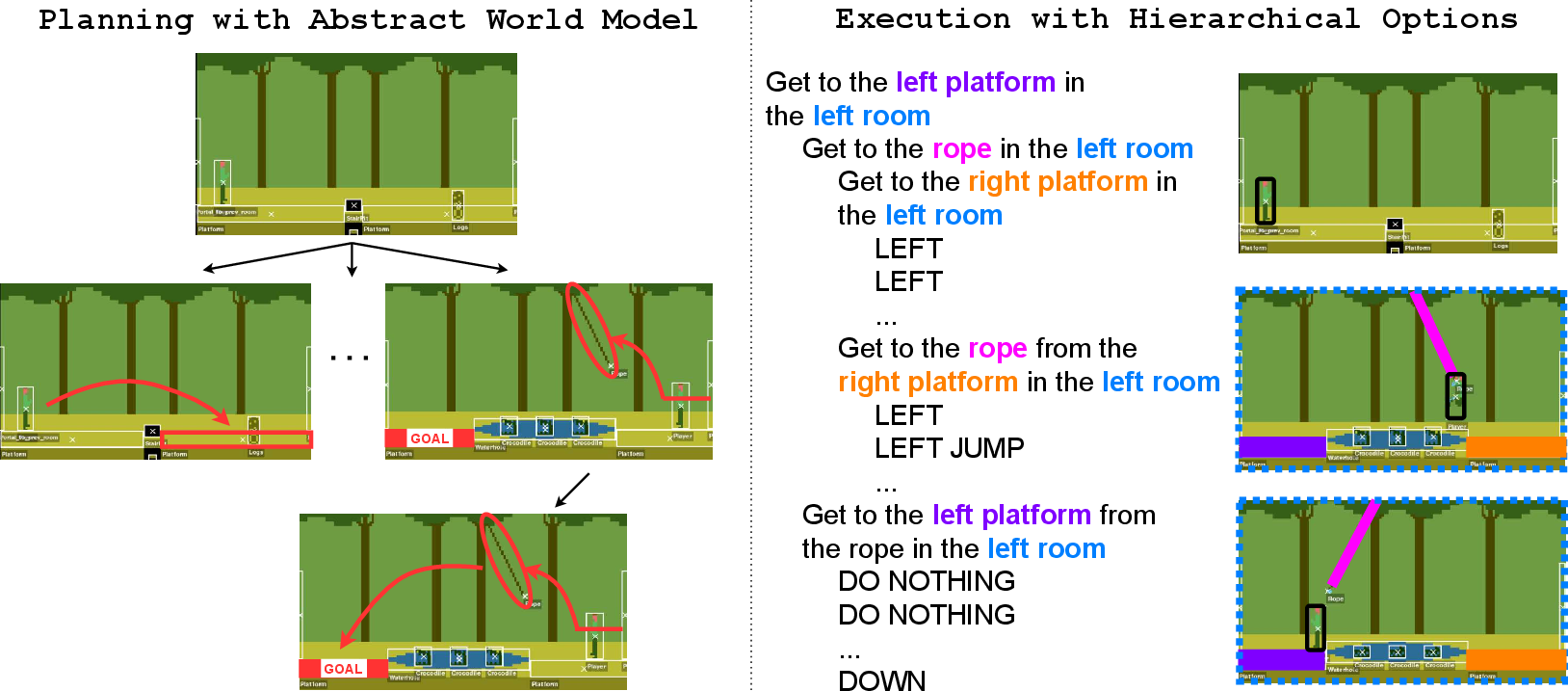
- Hierarchical skills (called “options”):
- An “option” is a skill with a goal and a policy (how to act).
- High-level options can call lower-level options or basic actions.
- Example: “Get the key” might call “climb ladder,” “jump gap,” and “avoid enemy.”
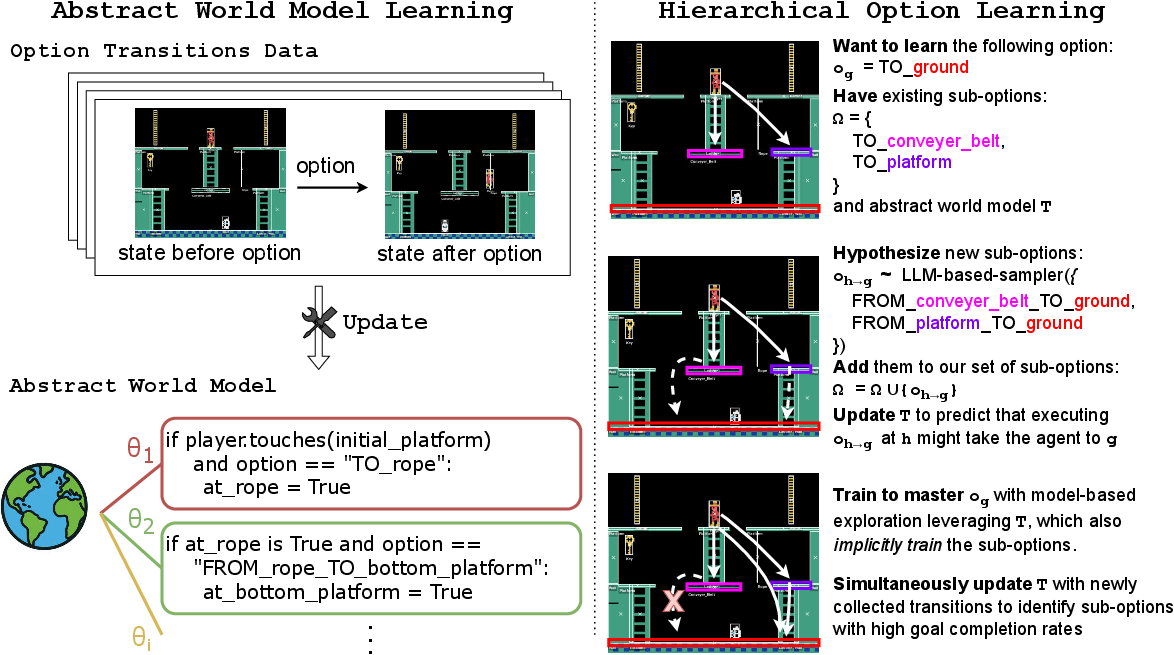
- Abstract world model (the AI’s mental map):
- Instead of predicting every tiny change after each button press, the AI predicts what will be true after finishing a skill.
- This is called “temporal abstraction” (looking ahead by whole skills, not single steps) and “state abstraction” (tracking important facts, like “Is the key picked up?”).
- The model is built using a “product of experts” idea: many small rule-like programs each explain one part of the world (like “ladders let you go up”). Their advice is combined to make a full prediction.
- These small programs are generated with help from a LLM—think of it as code-writing assistants that suggest simple rules.
- A “frame axiom” belief keeps learning stable: most skills only change a few things, not everything. This prevents the model from overreacting.
- Planning and exploration with the world model:
- The AI learns a “planning policy” inside its world model (cheap and fast), and uses it as smart exploration in the real game.
- Over time, it relies less on the model and more on its own learned real-world policy (a safe way to avoid mistakes if the model isn’t perfect).
- Hypothesizing helpful sub-skills using LLMs:
- If the AI struggles with a new goal, it asks the LLM to suggest a useful precondition (a stepping-stone goal).
- Example: To “fill the cup,” first “pick up the cup.”
- The AI adds this new sub-option to its toolbox and updates the world model to include it.
- Stable training for stacked skills:
- Training high-level skills can get messy if the lower ones keep changing.
- To keep things stable, the AI ignores training data that uses “unstable” sub-options (not yet reliable or insufficiently trained), until they become solid.
In short: the AI builds a mental map using tiny rule programs, plans with that map, proposes new helpful mini-goals when needed, and trains skills from bottom to top without wobbling.
Results: What did the AI actually achieve?
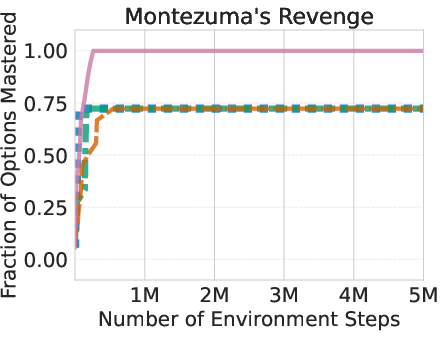
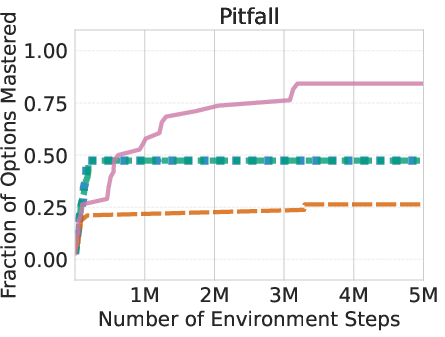
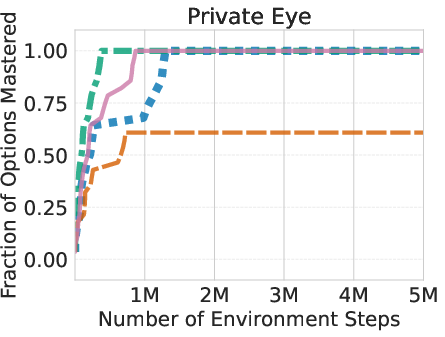
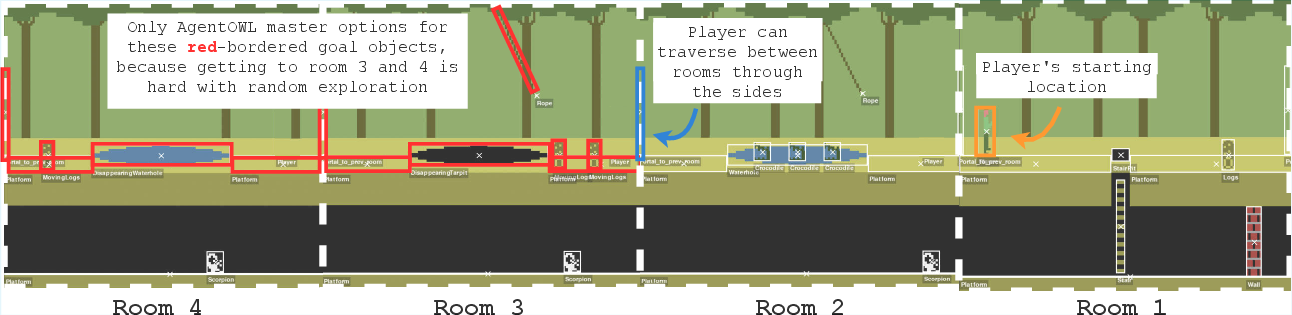
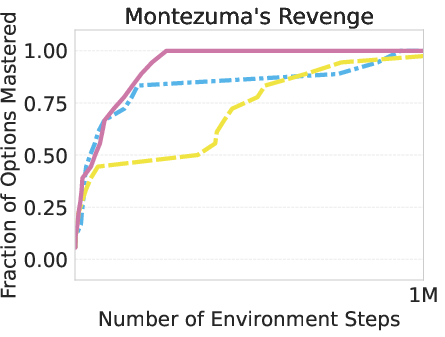
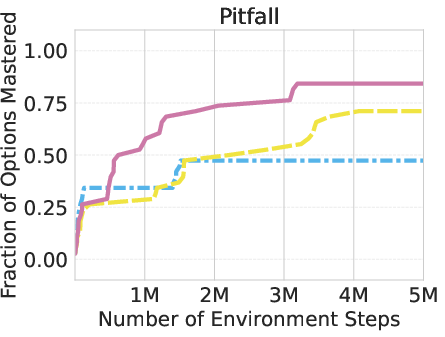
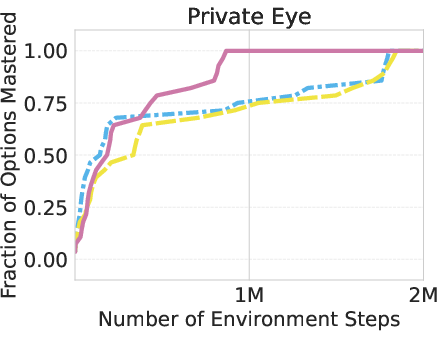
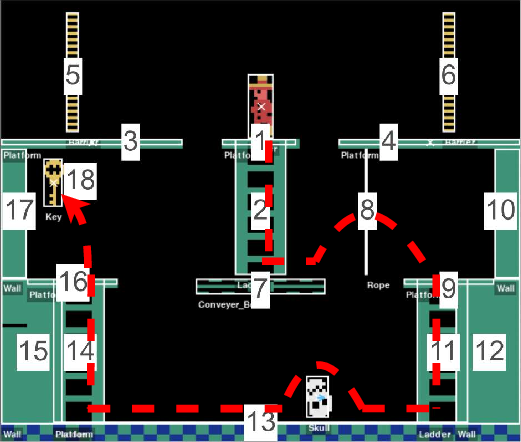
The researchers tested AgentOWL on three hard Object-Centric Atari games: Montezuma’s Revenge, Pitfall, and Private Eye. These games are famous for requiring careful exploration and long plans.
Main findings:
- AgentOWL mastered more skills with fewer game steps than strong baselines (like Rainbow DQN, goal-conditioned DQN, and hierarchical DQN without a world model).
- It handled hard goals better by planning with higher-level skills. Short, abstract plans made it easy to find the right path without trying millions of random moves.
- Ablation tests (removing parts of the system) showed:
- Without LLM-based sub-goal proposals, learning slowed and plateaued lower.
- Without stable training rules, high-level learning became less reliable.
- Zero-shot adaptation:
- After giving AgentOWL a single new “navigation” option (to get from a new starting point back to the original one), it could immediately solve old goals from the new start—without extra training.
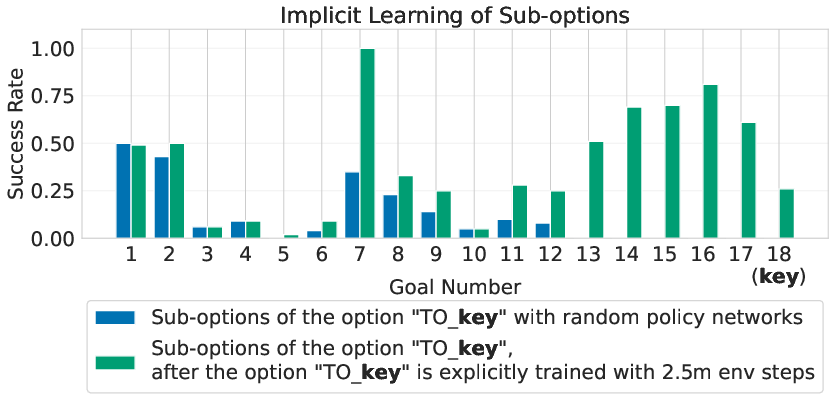
- Implicit learning:
- While training a high-level goal (like “get key”), the AI automatically improved the sub-options that are relevant to that goal (like “climb ladder”), even if those sub-options weren’t directly rewarded. It essentially learned the right route and leveled up the steps along that route.
Why it matters: What could this change?
AgentOWL demonstrates a powerful idea: to learn efficiently, an AI should both plan and reuse skills. This approach:
- Cuts down on trial-and-error by “thinking ahead” with a world model.
- Builds skills that stack, helping tackle complex tasks (like multi-step game puzzles, robotics chores, or planning in new environments).
- Shows that combining symbolic rule-like models with neural learning can be very data-efficient.
Looking ahead:
- Automating the curriculum (the order of goals) would make the system even easier to use.
- Scaling to hundreds or thousands of goals will need faster ways to pick relevant skills (affordances).
- Moving from symbolic inputs (objects, positions) to raw pixels is a big next step—bridging to vision-heavy worlds while keeping planning power.
In simple terms: AgentOWL is a smarter, thriftier learner. It plans with its brain (world model), practices with its hands (policies), and builds new tricks from old ones—so it can solve tough problems with less guesswork.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper that future researchers could act on.
- Lack of formal guarantees: no error bounds or convergence analysis for planning with the abstract world model plus weighting function, especially under compounding model error across multi-option plans.
- Weighting function approximation: sampling full states from abstract states via KDE is heuristic; scalability, coverage, and out-of-distribution behavior in large/high-dimensional or continuous state spaces are unstudied.
- Independence assumption in PoE-World: the factorized next-state model ignores feature dependencies; methods to capture tractable cross-feature interactions (e.g., structured factors) are missing and their impact is unknown.
- Frame axiom prior sensitivity: the MAP prior choices (means/variances) are hand-set; no ablation of how prior misspecification affects learning, planning performance, or sample efficiency.
- Uncertainty handling: the system does not quantify or propagate model uncertainty into planning/exploration; risk-aware planning and uncertainty-guided data collection are unaddressed.
- Abstract predicate set: the state abstraction equals the vector of goal predicates; discovering additional useful abstract features or reducing irrelevant ones (automatic abstraction selection) is not explored.
- Preconditions expressivity: sub-option preconditions are restricted to a single predicate equality; richer logical/relational preconditions (conjunctions/disjunctions, spatial relations, object interactions) and how to learn them are open.
- LLM dependence for subgoal proposal: robustness to LLM model choice, prompt design, and failure modes is not analyzed; alternatives that do not rely on LLMs (e.g., information-theoretic or affordance-based proposals) are absent.
- Hypothetical option models: adding an LLM-proposed option and its “hypothetical” model lacks validation—how accurate are these models before data, how to calibrate/repair them online, and how to decide when to discard them?
- pi_wm learning strategy: world-model policy is learned via DQN; comparisons to explicit planning (e.g., tree search, MPC) or hybrid plan-and-learn approaches inside the abstract model are missing.
- Online planning at execution: the system uses the world model to pre-train pi_wm but not to perform decision-time planning; whether online lookahead improves robustness to model errors is untested.
- Hierarchical DQN stability: the threshold-based stabilization heuristic lacks theoretical grounding; sensitivity analyses and automated scheduling/criteria for replay inclusion/exclusion are not provided.
- Replay design: each option has its own buffer; the tradeoff vs a shared/prioritized replay (with off-policy corrections and option labels) for data efficiency is not studied.
- No weight sharing across options: compute scales linearly with the number of options; exploring shared backbones, adapters, or meta-learning for rapid option acquisition is an open design space.
- Curriculum dependence: goals must be provided and ordered by difficulty; automatic curriculum/goal sequencing, goal discovery, and detecting prerequisite subgoals are unaddressed.
- Scalability to many goals/options: the approach assumes <100 goals; mechanisms to prune/merge options, exploit affordances, or index/search in large option libraries are needed and untested.
- Depth of hierarchies: empirical scaling to deeper hierarchies and very long abstract plans remains unquantified; risks of non-stationarity and interference with many levels are not analyzed.
- Option termination design: termination equals goal satisfaction; learning or adapting termination sets (interrupts, multi-terminal options, time/duration models) is not explored.
- Duration modeling: the abstract model does not model option durations explicitly; using semi-Markov models with duration/cost predictions for time-sensitive planning is open.
- Symbolic input assumption: the method relies on object-centric symbolic state; integrating perception (pixels-to-symbols), learning abstractions from raw inputs, and robustness to parser errors are open challenges.
- Partial observability: extensions to POMDPs (belief-state abstract models, memory in options) are not developed despite related literature cited.
- Generalization and transfer: beyond a single zero-shot test, systematic evaluation across rooms, levels, or task variations (without injecting a new “navigate” option) is lacking.
- Robustness to dynamics shift: how the learned abstract model and options adapt to stochasticity or environment changes (e.g., object spawn changes) is untested.
- Benchmark coverage: evaluation is limited to a few rooms in three OCAtari games with “touch-object” goals; broader domains (continuous control, robotics, procedurally generated tasks, relational/temporal goals) are absent.
- Baseline breadth: comparisons exclude strong model-based agents (e.g., Dreamer, MBPO/MBOP) and hierarchical RL baselines (e.g., HIRO, HAC, option-critic variants with models); fairness and compute/data budgets are unclear.
- Compute vs data tradeoffs: the paper targets sample efficiency but does not report wall-clock compute, LLM call overhead, or energy; regimes where compute becomes the bottleneck are not characterized.
- Selection of when to hypothesize new sub-options: the current rule (stability/no-good options) is ad hoc; Bayesian decision criteria or information-gain triggers for proposing/refining options are unexplored.
- Data coverage for KDE weighting: reliance on previously seen transitions risks bias; active data collection to fill abstract-state coverage gaps and principled retrieval indices are missing.
- Continual/online learning: as the option library and predicate set grow, the abstract model faces a changing state/action space; strategies for stable continual world-model and policy updates are open.
- Option library management: mechanisms for pruning, merging, or compressing redundant or low-utility options (and their models) to control memory and planning cost are unstudied.
- Evaluation metrics: focus on “fraction of options mastered” with a fixed success threshold; additional metrics (cumulative return, plan length, model calibration, planning latency) would give a fuller picture.
- Reproducibility: prompts, LLM outputs, and expert code generation details (and their variance across runs) are not fully characterized; standardizing seeds and reporting variability would improve reliability.
Practical Applications
Overview
Based on the paper “Joint Learning of Hierarchical Neural Options and Abstract World Model (AgentOWL),” the practical value comes from three innovations:
- A sample-efficient abstract world model (PoE-World) that mixes symbolic code “experts” with non-parametric components to predict the outcomes of temporally extended skills (options).
- A hierarchical option-learning pipeline that composes previously learned skills to master harder goals, using model-based exploration for targeted, low-waste data collection.
- An LLM-assisted mechanism to hypothesize useful sub-goals (preconditions) that shorten abstract plans and stabilize hierarchical training.
Below are actionable applications grouped by deployment horizon. Each item identifies sectors, concrete use cases, potential tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
These can be prototyped/deployed now in environments with symbolic or easily extracted state and clear goal predicates, modest goal counts, and access to logs/simulators.
- Software automation (RPA/enterprise workflows)
- Use case: Learning and composing enterprise task “options” (e.g., “log in,” “extract invoice,” “post to ERP”) from process logs to automate long workflows (e.g., expense processing, onboarding).
- Tools/workflows:
- “Option Library for RPA” that mines and maintains reusable skills.
- “Abstract Workflow Modeler” using PoE-World to simulate option effects before execution.
- Integration hooks for UiPath/Automation Anywhere, BPM tools, and event logs.
- Assumptions/dependencies:
- Symbolic state and action traces (GUI events, API calls) are available.
- Clear goal predicates (e.g., “invoice posted”) and modest number of goals (<100).
- Governance around LLM use for sub-goal suggestions; data privacy/compliance.
- DevOps/SRE (runbook automation)
- Use case: Compose hierarchical remediations (e.g., “roll back deployment,” “purge cache,” “rotate keys”) and simulate outcomes prior to live execution.
- Tools/workflows:
- “Abstract Runbook Modeler” that learns option effects from incident/resolution logs.
- “Hierarchical Planner for On-Call” that suggests and evaluates minimal abstract plans.
- Integration with ticketing (Jira), observability (Prometheus), and orchestration (Kubernetes).
- Assumptions/dependencies:
- High-fidelity, symbolic telemetry and action logs.
- Sandboxed staging environment for testing model-based plans.
- Clear roll-back and safety checks to mitigate model errors.
- Game AI and QA automation
- Use case: Train NPCs/test bots with hierarchical behaviors (e.g., “navigate to checkpoint,” “unlock door,” “escort”) that generalize across levels; fast exploration for coverage.
- Tools/workflows:
- “AgentOWL QA Bot” integrated with engine introspection (Unity/Unreal) to build object-centric state.
- Skill libraries for reusable level mechanics (jump, key-door sequences).
- Assumptions/dependencies:
- Engine APIs expose symbolic object states or can be instrumented.
- Abundant simulation for fast data collection; goals can be enumerated.
- Industrial robotics (simulation and structured cells)
- Use case: Compose pick-place-inspect-pack options in tightly controlled cells; plan across multiple steps to reduce trial runs and wear.
- Tools/workflows:
- “Skill Composer for ROS2” where options are robot macros; PoE-World models abstract effects (e.g., “object grasped,” “bin occupied”).
- Digital twin integration for model-based exploration.
- Assumptions/dependencies:
- Reliable symbolic state from perception/PLC (object present, pose known).
- Small to moderate goal sets and a curated curriculum.
- Initial deployment in simulation or guarded cells; human-in-the-loop safety.
- Cross-application LLM agents (productivity assistants)
- Use case: Multi-app workflows (e.g., “collect client feedback → summarize → update CRM → schedule call”), with options as app-specific skills and an abstract model for safe lookahead.
- Tools/workflows:
- “Hierarchical Planner for Agent Frameworks” (LangChain, AutoGen) that composes skills and uses PoE-World to simulate side-effects (e.g., “event created,” “record updated”).
- Assumptions/dependencies:
- Stable app APIs and observable symbolic states.
- Guardrails for LLM sub-goal generation; review of side-effect predictions.
- Building/energy management (testbeds and pilots)
- Use case: Compose control options (“pre-cool zone,” “shift schedule,” “set-point bump”) to reach comfort/efficiency targets; test abstract plans before applying.
- Tools/workflows:
- “Abstract Control Sandbox” linked to BMS/EMS for plan rehearsal and what-if analysis.
- Assumptions/dependencies:
- Safe test environments; symbolic telemetry; clear goals and constraints.
- Oversight for safety, compliance, and occupant comfort.
- Finance back-office operations
- Use case: Automate reconciliation, exception handling, and multi-step approvals via reusable options trained from audit-compliant logs.
- Tools/workflows:
- “Option Chains for Reconciliation” with verifiable abstract models of ledger states.
- Assumptions/dependencies:
- Access to redacted/non-PII logs or privacy-preserving pipelines.
- Strict auditability; human approval for high-stakes actions.
- Research and education (academia)
- Use case: Benchmarking hierarchical RL, teaching modules on skill composition and model-based RL, and rapid prototyping of neurosymbolic agents.
- Tools/workflows:
- Open-source “AgentOWL Toolkit” combining PoE-World, hierarchical DQN, and LLM sub-goal prompts.
- Assumptions/dependencies:
- Availability of object-centric/symbolic environments; reproducibility datasets.
Long-Term Applications
These require advances in perception-to-symbolic abstraction, safety, scaling beyond hundreds of goals, continuous online learning, or stringent assurance.
- Home/Service robotics (general-purpose)
- Use case: Multi-step household tasks (e.g., “make coffee,” “set table,” “tidy room”) by composing learned skills; adapt to novel layouts zero-shot.
- Tools/products:
- “Household Skill Library” with abstract world model bridging perception and symbolic predicates.
- Assumptions/dependencies:
- Robust perception that yields reliable symbolic state; safe manipulation.
- Automated curriculum and affordance-aware option selection at scale.
- Clinical workflows and surgical robotics
- Use case: Plan multi-step clinical processes (orders, documentation) or assistive robotic subtasks; simulate workflow outcomes before execution.
- Tools/products:
- “Abstract Clinical Planner” integrated with EMR; safety-checked plan rehearsal.
- Assumptions/dependencies:
- Regulatory approval; robust validation; strong interpretability.
- Privacy-preserving data and certified LLM components.
- Autonomous vehicles and fleets (high-level planning)
- Use case: Compose higher-level driving options (merge/overtake/exit) with abstract model to reason about mission-level goals.
- Tools/products:
- “Hierarchical Mission Planner” layered above low-level control and perception.
- Assumptions/dependencies:
- Verified perception-to-symbol mapping; stringent safety and liability frameworks.
- Open-world digital assistants with lifelong learning
- Use case: Continuous acquisition of new options/goals from user interactions; online abstract world modeling with expanding state/action spaces.
- Tools/products:
- “Lifelong Skill Orchestrator” with option affordances and curriculum generation baked in.
- Assumptions/dependencies:
- Stable mechanisms for preventing catastrophic forgetting; scalable reasoning over large skill sets; privacy-by-design.
- Industrial process control at plant scale
- Use case: Hierarchical planning for multi-unit processes (e.g., chemical plants) with sample-efficient abstract models learned from limited runs.
- Tools/products:
- “Abstract Plant Modeler” for option-level control and what-if plan analysis.
- Assumptions/dependencies:
- High-confidence modeling; safety interlocks; integration with SCADA/DCS.
- Disaster response and field robotics
- Use case: Compose navigation, assessment, and manipulation options in dynamic, partially observable environments.
- Tools/products:
- “Mission Option Composer” integrating robust symbolic state estimation and uncertainty-aware planning.
- Assumptions/dependencies:
- Reliable object-centric perception under stress; robust partial observability handling; safety.
- Personalized education and tutoring
- Use case: Compose pedagogical options (prerequisite skills, hints, sub-goals) to build individualized learning paths; reason over abstract models of student knowledge.
- Tools/products:
- “Curriculum Explorer + Knowledge Tracer” driven by abstract state of mastery.
- Assumptions/dependencies:
- Validated student-model abstractions; ethical oversight; content alignment.
- Laboratory automation and scientific discovery
- Use case: Compose experimental protocol options and simulate outcomes; accelerate hypothesis testing with minimal wet-lab trials.
- Tools/products:
- “Protocol Skill Composer” and “Abstract Reaction Modeler.”
- Assumptions/dependencies:
- High-quality lab records; safe model-based execution; domain-specific priors.
- Smart grid and large-scale energy systems
- Use case: Hierarchical control options for demand response, storage dispatch, and network reconfiguration; simulate grid-level effects.
- Tools/products:
- “Hierarchical Grid Planner” with abstract models of regional states.
- Assumptions/dependencies:
- Regulatory acceptance; robust simulation fidelity; cyber-physical security.
- Cybersecurity operations (SOC)
- Use case: Compose playbooks (isolate host, revoke credentials, patch deployment); simulate abstract network effects of actions before execution.
- Tools/products:
- “Abstract Playbook Planner” integrated with SIEM/SOAR.
- Assumptions/dependencies:
- Accurate symbolic network state; strong risk assessment layers; incident response governance.
Cross-Cutting Assumptions and Dependencies
- Symbolic state availability: AgentOWL relies on object-centric/symbolic states and well-defined goal predicates. In pixels-only settings, a dependable perception-to-symbol pipeline is required.
- Goal sequencing and scope: Current method assumes an ordered curriculum and a relatively small set of goals (<100). Automated curriculum learning and affordance filtering are open problems.
- Data and logging: Sufficient option transition data (from logs/simulators) is needed to fit PoE-World experts and the weighting function.
- LLM reliance: Sub-goal/precondition generation and expert code synthesis depend on access to strong LLMs and safe prompting, with privacy and security controls.
- Model accuracy vs safety: The weighting function is an approximation; abstract models may mispredict. Safety interlocks, sandboxing, and human-in-the-loop review are recommended for high-stakes domains.
- Compute vs data trade-off: The approach reduces environment interaction by leaning more on computation (planning/RL in the abstract model). Ensure compute budgets align with deployment constraints.
- Stability of hierarchies: Training stability benefits from the proposed thresholds; non-stationarity grows with depth/scale, motivating additional safeguards (e.g., option freezing, affordance gating).
These applications leverage AgentOWL’s central advantage: composing reusable skills with a data-efficient abstract world model to plan “in the now,” enabling targeted exploration, faster mastery of complex tasks, and flexible recomposition in new scenarios.
Glossary
- Abstract world model: A model that predicts the effects of options at an abstract feature level and at option termination times, enabling temporal and state abstraction. "We use PoE-World to learn an abstract world model."
- Affordances (option affordances): Constraints indicating which options are applicable in a given state. "Incorporating option affordances \cite{khetarpal2020can, khetarpal2021temporally} to reduce the number of applicable options could be a fruitful direction."
- Call-and-return paradigm: In hierarchical RL, an option runs until termination before control returns to the caller. "We follow the call-and-return paradigm \cite{sutton1999between}; an option executes until its goal is satisfied, or it timeouts."
- Curriculum learning: Training strategies that order tasks from easier to harder to improve learning efficiency. "In the future, we hope to use ideas from curriculum learning \cite{bengio2009curriculum} to automate this."
- Deep Q-learning (DQN): A neural-network-based algorithm that learns action-value functions for discrete control. "Concretely, we run RL (specifically, deep Q-learning (DQN)) in the abstract world model"
- Frame axiom prior: A prior that biases learning so that actions/options are assumed to change only a small set of features unless evidence suggests otherwise. "we impose a ``frame axiom prior'' on the abstract world model"
- Goal-conditioned MDP: An MDP where the reward and sometimes dynamics are conditioned on a specified goal. "An environment can be described as a goal-conditioned MDP ."
- Hierarchical DQN: A DQN variant whose action space includes invoking previously learned sub-options. "Hierarchical DQN is DQN whose policy has an action space that includes previously learned sub-options."
- Hierarchical neural options: Neural policies organized as options that can call sub-options to form multi-level skill hierarchies. "an abstract world model (abstracting across both states and time) and a set of hierarchical neural options."
- Kernel density estimator: A non-parametric method to estimate a probability density from samples. "We heuristically predict from using a kernel density estimator that samples full states given an abstract state :"
- LLM code synthesis: Using LLMs to generate programmatic components (experts) of the world model. "Specifically, each expert is generated using LLM code synthesis, and the weight for each expert (denoted ) is learned"
- Maximum a posteriori estimation (MAP): Parameter estimation that maximizes the posterior probability, incorporating a prior. "turning weight optimization into a maximum a posteriori estimation (MAP) instead of MLE."
- Maximum likelihood estimation (MLE): Parameter estimation that maximizes the likelihood of observed data. "hence we can perform maximum likelihood estimation (MLE) of the weights through gradient descent."
- Model-based reinforcement learning: RL methods that learn and exploit a model of the environment for planning. "we instead turn to model-based reinforcement learning~\cite{kaelbling1996reinforcement, moerland2023model}."
- Model-free hierarchical reinforcement algorithms: Hierarchical RL methods that learn directly from experience without an explicit model. "existing model-free hierarchical reinforcement algorithms need a lot of data."
- Non-parametric distributions: Distributions characterized by the data rather than a fixed set of parameters. "a novel world model whose representation combines symbolic code with non-parametric distributions,"
- Non-stationary environment: An environment whose effective dynamics change over time (e.g., due to updates of sub-policies), destabilizing learning. "each higher-level option faces a non-stationary environment: Training lower level options changes the transition dynamics as seen by higher level options~\cite{nachum2018data}."
- Object-centric Atari (OCAtari): An Atari environment augmentation that parses each frame into objects and their attributes. "On object-centric Atari (OCAtari) \cite{delfosse2023ocatari}, PoE-World takes only a few minutes of gameplay to assemble a working world model."
- Off-policy reinforcement learning: Methods that learn a target policy from data collected by a (possibly different) behavior policy. "a standard off-policy RL algorithm commonly used in discrete action settings."
- One-step trap: The difficulty of planning far ahead when models predict only immediate next states, limiting long-horizon reasoning. "overcoming the ``one-step trap'' \cite{sutton2025oak, asadi2019combating}"
- Option (reinforcement learning): A temporally extended action comprising a policy and a termination/goal condition. "An option is a learned skill."
- Options framework: A formalism extending MDPs with temporally extended actions (options). "We formalize this compositional skill learning using the options framework \cite{sutton1999between}:"
- Partition function: The normalization constant required to turn unnormalized scores into a proper probability distribution. "this makes it tractable to compute the partition function, , and hence we can perform"
- PDDL: Planning Domain Definition Language, a standard formal language for specifying planning problems. "This ``frame prior'' is commonly used in the planning community, as it is employed, in a much stronger form, in PDDL \cite{mcdermott20001998}."
- PoE-World: A product-of-experts world modeling framework that learns structured dynamics from little data. "PoE-World, a framework for learning structured world models from little data."
- Product-of-experts: A probabilistic modeling approach that multiplies expert distributions to form a sharper combined model. "World models are represented using a product-of-experts, where each expert is a short symbolic program."
- Replay buffer: A memory that stores past transitions for sample-efficient, off-policy learning. "executing the policy to collect data in the replay buffer and optimizing the policy using samples from the replay buffer."
- Semi-MDP: A generalization of MDPs allowing variable-duration actions (e.g., options). "Adding options to the action space of an MDP forms a Semi-MDP \cite{puterman1994mdp}."
- State abstraction: A mapping from full states to a reduced representation that retains task-relevant information while omitting irrelevant/unpredictable details. "we consider state abstractions, which are functions of the state that elide unpredictable or irrelevant features that would be hard to predict"
- Temporal abstraction: Representing and planning over multi-step actions or events at coarser time scales. "This implements temporal abstraction and state abstraction, because rather than predicting the immediate next state, we instead predict only its abstract features, and only at the time that the current option terminates."
- Weight sharing: Sharing neural parameters across multiple policies or tasks to improve data efficiency. "Goal-conditioned DQN is DQN with weight sharing between the policies of the options."
- Weighting function: A function used to sample or weight full states consistent with an abstract state for multi-step prediction/planning. "this approximation is common in the hierarchical decision-making literature, where is called a weighting function~\cite{bertsekas1995, li2006towards}."
Collections
Sign up for free to add this paper to one or more collections.