- The paper presents a novel quantization framework that compresses KV-cache memory by up to 7× with minimal quality degradation.
- It employs semantic-aware smoothing and progressive residual quantization to reduce quantization error in autoregressive video diffusion models.
- Experimental results demonstrate near-lossless performance over 700+ frames and enable large-scale video models to run on commodity GPUs.
Quant VideoGen: Training-Free 2-Bit KV-Cache Quantization for Autoregressive Long Video Generation
Introduction and Context
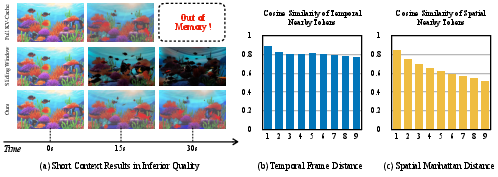
Autoregressive video diffusion models (AR-VDMs) have emerged as the preferred paradigm for long-horizon visual synthesis, enabling incremental and interactive video generation. However, the scalability and practical deployment of these models are fundamentally bottlenecked by the memory cost of the KV-cache, which grows linearly with temporal context. This work identifies the KV-cache as not only a systems bottleneck but also an algorithmic constraint—limiting both attainable context length and thus degrading long-term visual consistency in identity and motion.
This paper introduces Quant VideoGen (QVG), a training-free, video-specific KV-cache quantization framework that achieves aggressive memory savings (up to 7× compression) with only minimal effects on generation quality and system throughput. The central insights are: (1) KV-cache activations in video models exhibit highly non-uniform numeric statistics and strong spatiotemporal redundancy, which render LLM-oriented quantization methods sub-optimal, and (2) a principled clustering and residual quantization scheme can dramatically regularize these activations for quantization.

Figure 1: QVG establishes a new quality-memory Pareto frontier, reducing KV-cache memory by up to 7× while achieving high PSNR on challenging benchmarks.
Semantic-Aware Smoothing
QVG’s primary technical contribution is Semantic-Aware Smoothing of the KV-cache. Standard low-bit quantization performs poorly in video VDMs due to highly dynamic activation ranges both inter-token and inter-channel, exacerbated by diverse scene semantics and rapid K/V cache growth. To address this, QVG partitions KV-cache tokens into semantically coherent groups—using k-means clustering on the latent representations—then subtracts each group’s centroid, operating along the temporal axis of the KV-cache. This yields residual matrices with lower and more homogeneous magnitudes, which are much more amenable to quantization.
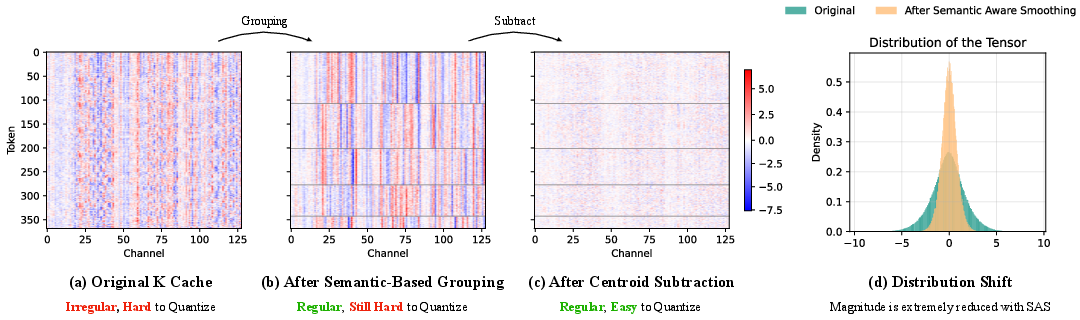
Figure 2: Semantic-Aware Smoothing regularizes the KV-cache: (a)-(c) show grouping and centroid subtraction; (d) depicts reduction in amplitude, facilitating quantization.
Empirical analysis shows that Semantic-Aware Smoothing reduces quantization error for keys by 6.9× and for values by 2.6×. This substantial error reduction is critical to achieving sub-2 bitwidth quantization without destructive quality loss, a result not attainable by straightforward application of methods from LLMs or speech models.
Progressive Residual Quantization
To further minimize quantization error, the framework deploys Progressive Residual Quantization. It applies multiple sequential semantic-aware smoothing and quantization stages to the residual matrix, each capturing finer-grain structure missed by previous stages—a concept inspired by multi-layer streaming codecs. This coarse-to-fine quantization scheme enables a tunable trade-off between memory usage and quality, with the first stage contributing the majority of mean-squared error reduction, and subsequent stages providing diminishing yet non-negligible returns.
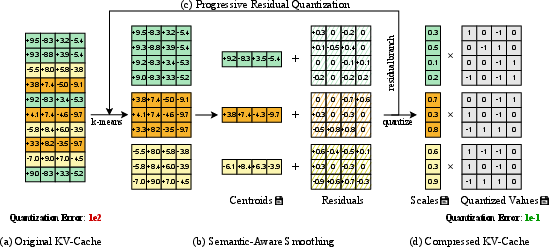
Figure 3: QVG pipeline: (a) Raw, highly irregular distribution; (b)-(c) Semantic grouping and iterative smoothing; (d) final output is well regularized and low-error.
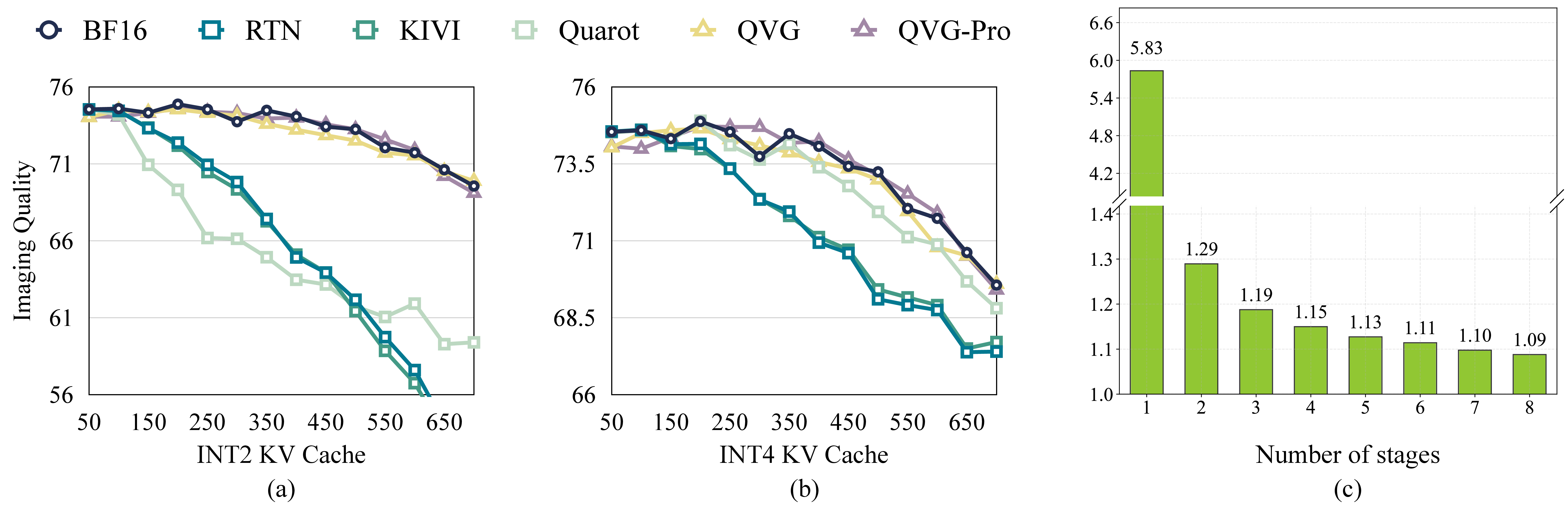
Figure 4: (a)-(b) Long-horizon imaging quality using Self-Forcing: QVG variants remain near-lossless over hundreds of frames, while baselines degrade; (c) Most error drop occurs in stage 1 of progressive quantization.
Experimental Evaluation
Extensive experiments are conducted on modern, large-scale AR-VDMs including LongCat-Video-13B, HY-WorldPlay-8B, and Self-Forcing-Wan-1.3B, targeting 480p long video generation and using MovieGen and VBench suites. QVG outperforms SOTA LLM-inspired alternatives (e.g., RTN, KIVI, QuaRot) on both raw fidelity (PSNR, SSIM, LPIPS) and perceptual/video-specific metrics (e.g., background/subject consistency, image/aesthetic quality).
Key results:
System-Algorithm Co-design and Practical Implications
QVG is implemented with CUDA/Triton kernels, employing chunk-wise streaming compression and fused dequantization, ensuring system efficiency in both latency and throughput. The centroid caching scheme further reduces runtime clustering overheads. Memory usage is predominantly allocated to the quantized values, with negligible cost for assignment vectors and centroids.
The practical upshot is that QVG enables deployment of AR-VDMs on commodity hardware and extends feasible generation horizons, addressing both research and application-level demands in video synthesis, interactive world modeling, and live-control generation scenarios.
Theoretical and Future Directions
QVG’s methodology departs from LLM-centric quantization research by specifically leveraging video’s intrinsic spatiotemporal redundancy, which increases generalization potential to other high-dimensional structured generative tasks (e.g., 3D, trajectory synthesis). Extension directions include adaptive group sizing, hybrid quantization with model weights, and application to transformer architectures beyond AR-VDMs. Further advances may employ learning-based codebooks or even multiscale hierarchical grouping driven by self-supervision.
Conclusion
Quant VideoGen provides a scalable, training-free solution for tackling the KV-cache memory bottleneck in autoregressive video diffusion. By fusing semantic token grouping with progressive residual quantization, QVG delivers high-fidelity, near-lossless long video generation with up to 7× memory savings and modest compute overhead. This framework unlocks long-horizon AR-VDMs for both research and deployment, and establishes new design principles for resource-efficient generative modeling systems.
(2602.02958)