- The paper introduces Speech-to-Spatial, an end-to-end system that transforms ambiguous verbal instructions into spatially-grounded AR guidance, enhancing task efficiency.
- It employs a multi-stage pipeline with LLM-based parsing and an object-centric relational graph to resolve diverse linguistic reference patterns.
- Empirical results demonstrate significant reductions in task completion times and cognitive workload, with summary overlays outperforming conventional audio-only guidance.
Speech-to-Spatial: From Verbal Instructions to Spatially-Grounded AR Guidance
Introduction and Motivation
Speech-driven remote assistance is widely adopted in scenarios where direct visual or embodied collaboration is infeasible. However, spoken instructions are often inherently ambiguous due to under-specified referential expressions. Traditional systems mitigate this ambiguity through manual visual annotations, gestures, or gaze cues—strategies that introduce operational overhead or demand specialized hardware. "From Speech-to-Spatial: Grounding Utterances on A Live Shared View with Augmented Reality" (2602.03059) proposes Speech-to-Spatial, an end-to-end framework that seamlessly converts verbal remote-assistance instructions into spatially-grounded AR guidance, aiming to resolve referent ambiguity solely based on speech.
The approach is motivated by a formative study revealing four dominant linguistic reference patterns in remote instructions: Direct Feature, Relational, Memory-based, and Chained referencing. Speech-to-Spatial operationalizes these patterns by parsing utterances, constructing an object-centric relational graph, and generating persistent AR visual indicators that clarify the intended referent and associated actions in real time.
Framework Architecture and Technical Pipeline
The system architecture centers around a multi-stage pipeline: speech transcription, linguistic attribute extraction, referential graph construction, semantic reasoning, and AR visualization. Speech input is parsed by LLMs into a structured format, segmenting target objects, anchors, features, relational language, and temporal cues (Figure 1). The framework builds a relational graph mapping objects, spatial relationships, and interaction history, encoding multi-dimensional attributes—space, time, intent, and action—per object (Figure 2).
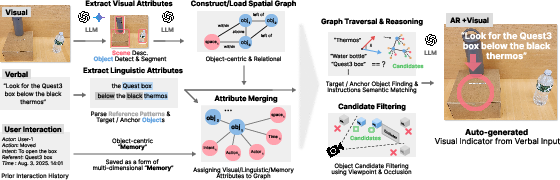
Figure 3: End-to-end pipeline: Speech input is parsed, attributes are extracted, a relational graph built, and AR indicators rendered for referent grounding.
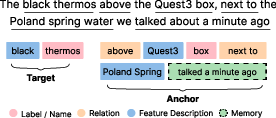
Figure 1: Attribute parsing: Verbal instructions are structured for downstream reasoning via LLM extraction.
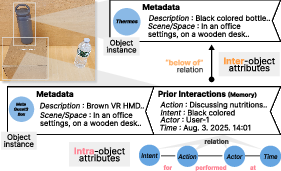
Figure 2: Object-centric relational graph: Each object maintains a node linked with intra- and inter-object attributes supporting referential disambiguation.
The reasoning backend, leveraging semantic similarity and LLM-based compositional inference, handles variable and chained expression resolution. Viewpoint-aware candidate filtering and occlusion culling optimize candidate selection, while prior interaction traces are retained per object to support memory-based references.
Visual indicators (e.g., directional arrows, concise instructional overlays) are anchored in AR directly above resolved objects, providing actionable guidance that persists until task completion. Summarization modules distill lengthy utterances into concise directives, minimizing cognitive overhead.
A controlled user study with 18 participants compared the Speech-to-Spatial system—with both full and summarized transcription overlays—to a conventional audio-only baseline. Participants performed locate and move tasks requiring disambiguation of target cubes among distractors under different guidance modalities.
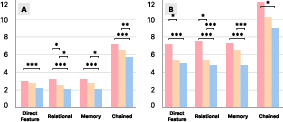
Key quantitative findings include:
Qualitative feedback underscored the preference for concise visual directives, with 79% of participants rating summary mode highly, citing reduced memory burden and streamlined actionability.
Use Cases and Applications
Speech-to-Spatial is demonstrated in three real-world collaborative AR scenarios:
Discussion, Limitations, and Future Directions
Speech-to-Spatial demonstrates robust improvements in instruction clarity, efficiency, and user satisfaction under speech-only constraints, but several technical limitations remain:
- Language coverage: Current graph representation primarily supports object-centered referencing; broader integration of view-centered and environment-centered frames requires advanced multimodal fusion and geometric reasoning.
- Reasoning complexity: Chained and ordinal references ("second to the right of" or nested constructs) expose limitations in multi-hop and global relationship inference.
- Visual guidance design: The impact of overlay modality (2D/3D, icons/arrows) and display fidelity on usability warrants further investigation.
- Real-world robustness: Assumptions of spatial coordinate synchronization and reliable object localization must be relaxed for scalable deployment in unconstrained environments.
- User agency: Balance between concise summarization and semantic completeness needs refinement to accommodate user preferences and task complexity.
Future work should extend system capabilities to support multi-turn interactions, adaptive modality switching, and deeper graph-based spatial reasoning, as well as more comprehensive user studies in authentic remote assistance workflows.
Conclusion
Speech-to-Spatial introduces a speech-driven referent disambiguation framework operationalizing linguistic reference patterns via an object-centric relational graph for grounding utterances in AR environments. Its empirical validation demonstrates measurable gains in task efficiency, comprehension, and cognitive load reduction over conventional verbal guidance. The system provides a practical bridge from ambiguous speech to visually explainable, actionable AR assistance, with potential implications for next-generation multimodal AI agents in collaborative and assistive contexts.
Figure 3: End-to-end pipeline of Speech-to-Spatial translating speech instructions into persistent AR indicators for spatial grounding.