- The paper proposes a context-conditioned value model ($V_0$) that reframes value estimation as a conditional inference task, enabling zero-shot policy capability assessment.
- It integrates a semantic perception backbone, Residual Query Adapter, and TabPFN-based inference to decouple critics from policy updates, improving stability.
- Empirical results demonstrate sustained performance and efficient resource allocation, outperforming traditional actor-critic methods in RLHF.
V0: A Generalist Value Model for Any Policy at State Zero
Motivation and Problem Statement
Efficient and robust value estimation is central to Reinforcement Learning from Human/Verifiable Feedback (RLHF/RLVR) in LLMs. Classical Actor-Critic methods such as PPO maintain a parameterized value model tightly coupled to policy parameters, leading to pronounced computational and stability burdens due to the necessity of tracking rapid non-stationary policy shifts. Value-free approaches, notably Group Relative Policy Optimization (GRPO), circumvent coupled critics but instead require excessive sampling to preserve reward signal variance, notably increasing sample complexity and inefficiency.
V0 redefines this paradigm by reframing value estimation as a conditional inference task over a context explicitly summarizing policy capability, rather than as an implicit function of evolving model parameters. Specifically, V0 predicts the expected performance for arbitrary policies and prompts at state zero—the initial interaction before action—using a context of historical instruction-performance pairs as an in-context capability profile. This decouples value estimation from policy updates, enabling zero-shot capability assessment without on-the-fly parameter tuning.
The high-level distinctions in training paradigms—traditional, tightly coupled Actor-Critic versus the explicit, context-driven V0—are depicted below.
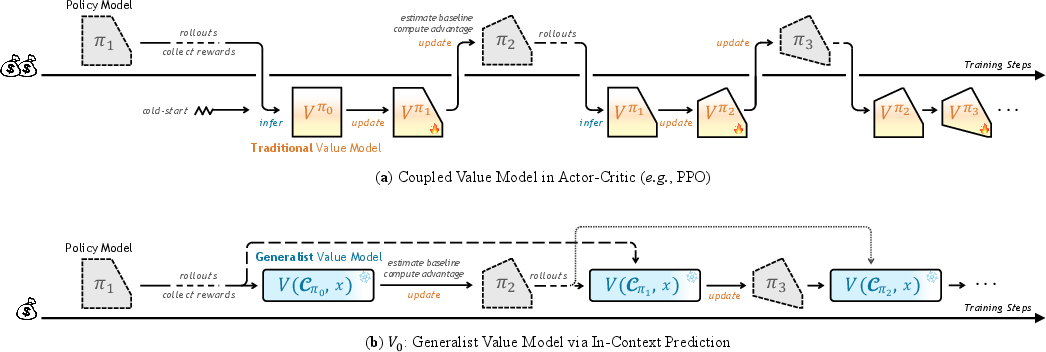
Figure 1: Traditional value models require synchronous coupling to the policy, while V0 queries policy capability through explicit historical context via a single, context-conditioned forward pass.
V0 Model Architecture
V0 constitutes a hybrid framework integrating high-dimensional semantic understanding with statistical reasoning over structured representations. The architecture comprises three interlocking components:
- Semantic-Perception Backbone: A frozen, pre-trained embedding model projects instructions and context into a unified, high-dimensional feature space.
- Residual Query Adapter: To bridge entangled LLM embeddings with the structured tabular reasoning required by downstream Bayesian inference, the Residual Query Adapter introduces learnable static queries and context-dependent dynamic queries, establishing channel-wise semantic disentanglement via multi-head attention.
- TabPFN-based In-Context Head: TabPFN, a transformer-based tabular probabilistic foundation model, serves as the Bayesian inference engine. Given context/query features, it directly computes the posterior predictive distribution for expected policy success on the query.
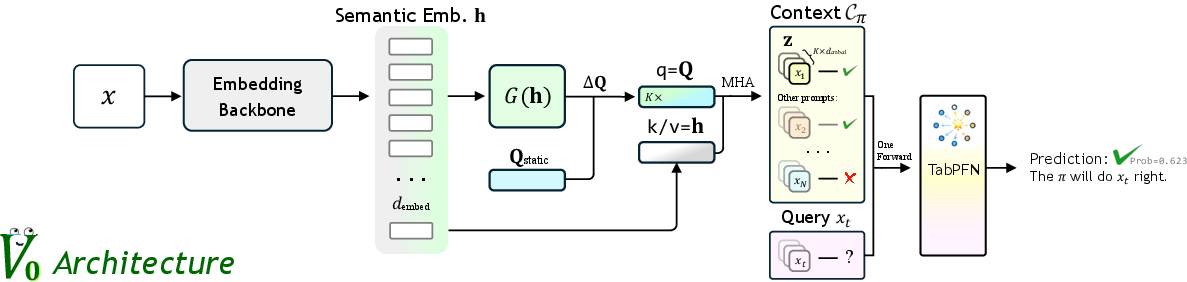
Figure 2: The V0 architecture: semantic encoding via an embedding backbone, projection into structured features by the Residual Query Adapter, followed by TabPFN-based probabilistic inference.
This design enables V0 to perform strong meta-inference about policy capability, rendering predictions agnostic to parameter updates or explicit model details.
A theoretical analysis identifies the risk of shortcut learning: models may trivially exploit context priors (average capability inside the context) instead of genuine instance-wise reasoning, especially when training minimizes standard cross-entropy loss. V0 employs a composite loss balancing a shift-invariant pairwise ranking loss (enforcing query-specific discrimination within context) with a calibration-centric cross-entropy loss. This decomposition explicitly targets conditional mutual information I(Y;X∣C), forcing the model to learn the mapping from query to outcome beyond context-level priors.
The efficacy of these objectives in eliminating context-dependent bias is confirmed by empirical measurement of residual error orthogonality, ensuring that prediction errors are not correlated with policy capabilities or query popularity.
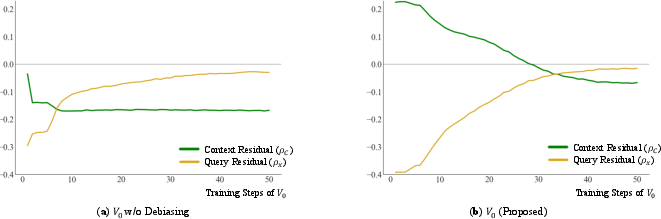
Figure 3: Convergence of residuals for V0 demonstrates effective decoupling from shortcut statistical priors over the training course, in contrast to naive TabPFN tuning.
Stability, Generalization, and Robustness
Comprehensive experimentation shows V0 achieves superior value estimation stability and tracking efficiency throughout the policy training process compared to coupled value models (VM), reward models, and non-parametric kNN baselines. Notably, V0 maintains high AUC on intra-context discrimination from initial to late training stages across a suite of architectures, while coupled VMs exhibit lag and instability.
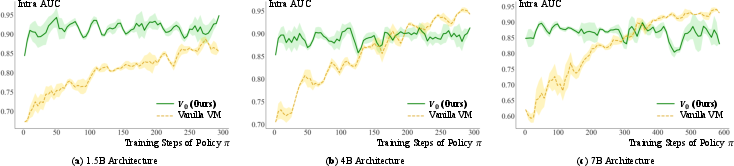
Figure 4: V0 maintains consistently high intra-context AUC throughout policy training, outperforming vanilla value models which exhibit lag and instability.
Zero-shot generalization experiments rigorously exclude test queries from all historical training context. Under these stringent conditions, V0 exhibits robust transfer, retaining strong predictive power and discrimination on unseen prompts and policy checkpoints, whereas traditional value models collapse to random-guessing behavior.
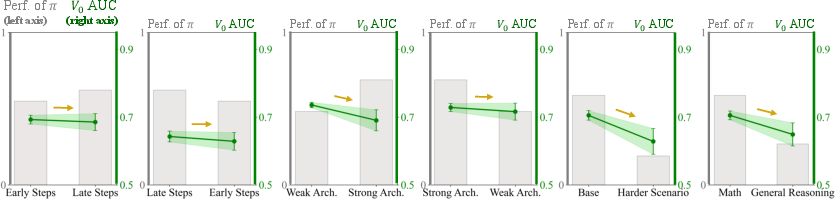
Figure 5: V0 exhibits stable AUC across architectural, temporal, and domain distribution shifts, whereas policy performance fluctuates widely.
Resource Scheduling: Budget Allocation and Inference Routing
Training-Time Budget Allocation
During RL training, optimal sampling budget allocation is critical for maximizing effective gradient signal. V0 enables real-time, sample-level estimation of current policy success probabilities, directly informing a closed-form marginal utility optimization for sampling budget. Empirical evaluation demonstrates that V0-guided allocation leads to faster convergence and higher accuracy across diverse mathematical reasoning benchmarks, notably outperforming both standard GRPO and heuristic, lagged allocation.
Inference-Time Routing
V0 naturally extends to inference-time routing. Within a model fleet, V0 assesses policy suitability and expected cost for a given query, supporting fine-grained optimization along the Pareto frontier of cost and accuracy by rerouting prompts to the least expensive capable model. The inclusion of cost tradeoffs in context enables dynamic adaption to shifting deployment or API pricing constraints, a feature unattainable for parameter-coupled estimation approaches.
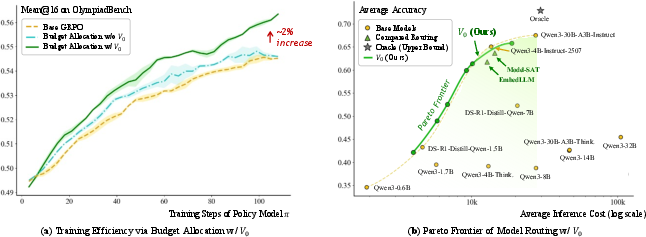
Figure 6: (a) V0-guided dynamic sampling allocation enhances data efficiency and final accuracy; (b) V0 enables cost-accuracy optimal inference routing, outperforming existing methods along the Pareto frontier.
Ablations and Scaling
Ablation studies confirm that V0's superior generalization is due to its context-conditioned design and Residual Query Adapter, with degradation observed when omitting this module or relying exclusively on suboptimally aligned objectives. Increasing context size past a critical threshold markedly improves performance (as shown in extended tables), affirming the benefit of dense capability profiling.
Theoretical and Practical Implications
V0 establishes that policy capability estimation can be executed via in-context capability profiling, decoupling value models from policy parameters and obviating synchronous retraining. Practically, this enables efficient RL, scalable resource allocation, and inference-time flexibility in heterogeneous fleets. Theoretically, it suggests that parameter-based coupling is not intrinsic, and model potential is a function of observed behavior, not solely parameters.
Future work is suggested in extending V0's context-conditional paradigm from state-zero to token-level process supervision, further integrating capability recognition into fine-grained RL and control.
Conclusion
V0 operationalizes generalist value estimation, removing the fundamental bottlenecks of coupling and retraining in RLHF for LLMs. By embedding policy capability directly into context and employing a structured, information-theoretic loss, it demonstrates robust tracking, generalization, and practical utility for both training and deployment. This architectural and methodological shift opens pathways toward context-adaptive, zero-shot capability assessment for continually evolving model fleets.
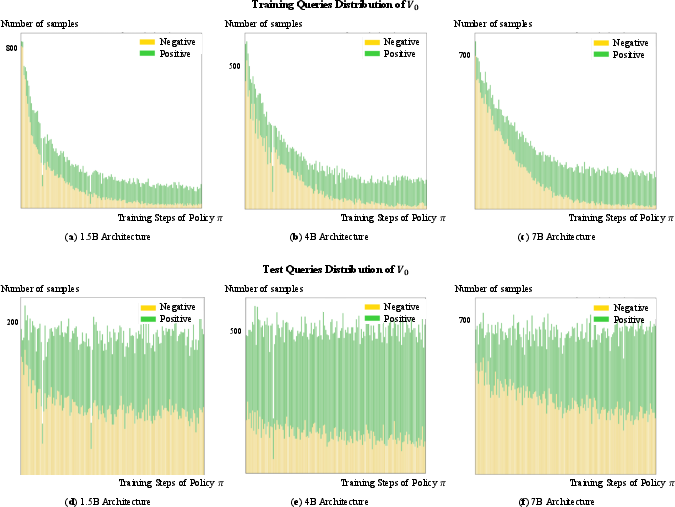
Figure 7: Distribution of positive and negative samples for V0 training and testing across training steps and architectures, highlighting the dynamic landscape that V0 accurately tracks.

