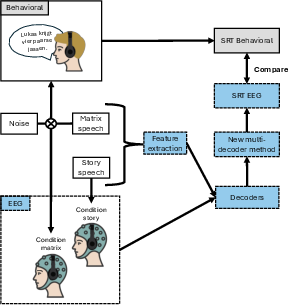
- The paper introduces a multi-decoder neural tracking framework that integrates EEG-based acoustic features with support vector regression to predict speech reception thresholds with sub-decibel precision.
- It employs 648 unique decoder configurations and ERF-adjusted NT vectors to robustly capture and integrate neural signals across varying SNR conditions.
- The study demonstrates clinical potential by reducing EEG data requirements while maintaining reliable subject-specific and subject-independent prediction accuracy.
Multi-Decoder Neural Tracking for Objective Prediction of Speech Intelligibility
Background and Motivation
Accurate assessment of speech intelligibility is essential in both research and clinical audiology settings, underpinning diagnoses, hearing aid evaluations, and interventions. Traditional behavioral measurement of speech reception threshold (SRT)—the signal-to-noise ratio (SNR) at which 50% of presented speech can be accurately repeated—is robust but requires subject participation, limiting its applicability in populations such as children or patients with disorders of consciousness (DOC). EEG-based predictive methods have emerged as objective alternatives, yet prior implementations fall short of the precision and reliability of behavioral test-retest benchmarks, often failing to reach sub-decibel accuracy or requiring extensive tuning and feature selection per subject.
This paper introduces a multi-decoder neural tracking (NT) framework designed to overcome parameter selection constraints, maximize exploitation of acoustic and neural features, and deliver robust SRT prediction through high-dimensional EEG data integration and support vector regression (SVR), with a focus on clinical practicality (2602.03624).
Experimental Paradigm
The study recruited 39 participants with normal-hearing thresholds. Each underwent three main experimental tasks:
Speech feature extraction centered on broadband envelope and acoustic onsets, processed using auditory-inspired filter banks and rectification/derivation techniques. EEG data preprocessing included artifact rejection, bandpass filtering (delta, theta, broadband), and normalization across subjects and tasks.
Multi-Decoder Neural Tracking Framework
Decoder Configurations
A decoder (linear backward model, ridge regression) learns to reconstruct select speech features from multichannel EEG. Key innovations include:
- Parameter diversity: 648 unique decoder configurations varying in stimulus (story/matrix), feature (envelope/onset), frequency band (theta, delta, broadband), lag window (up to 500 ms), and decoder type (subject-specific [SS] vs. subject-independent [SI]).
- Combinatorial model approach: Each configuration yields NT values for seven SNR conditions, leading to thousands of decoders per subject.
Subject-independent decoders used leave-one-subject-out cross-validation; SS decoders used leave-one-matrix-sentence-out within subjects. All decoders were evaluated on matrix EEG data.
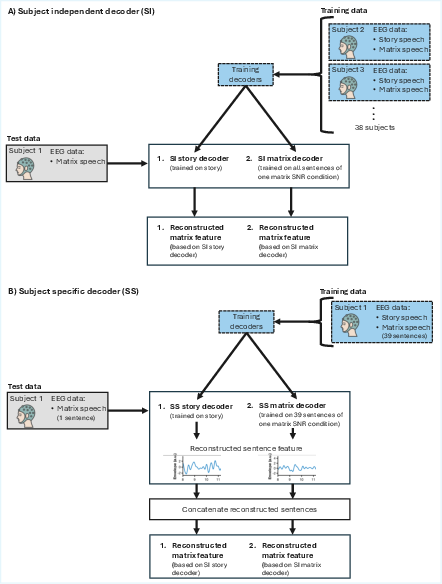
Figure 2: Schema of SI and SS decoders with their training/testing regimes across EEG datasets.
Feature Vector Construction
For each SNR condition per decoder configuration, NT values are computed. SNR-wise baseline subtraction (using NT at −12.5 dB SNR) yields adjusted NT values for five SNRs per configuration. These concatenate into a single high-dimensional NT feature vector per subject.
These vectors undergo the error function (ERF) transformation, globally parameterized across configurations to provide psychometric-like nonlinearity while avoiding subject-specific curve fitting.
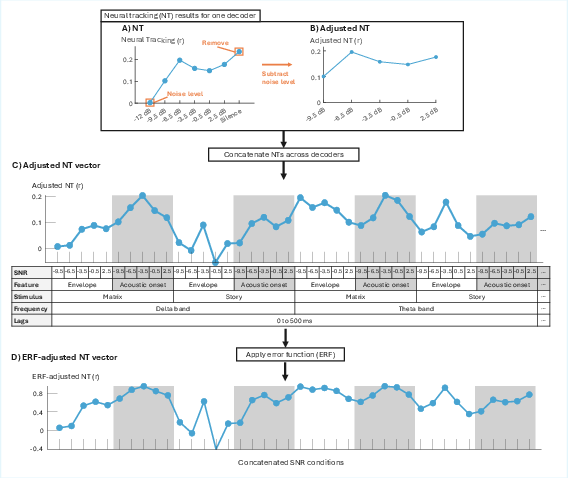
Figure 3: Process of generating ERF-adjusted NT vectors across all decoder configurations, illustrating baseline subtraction and transformation.
SRT Prediction Model and Evaluation
A linear SVR model, regularized via ridge penalty and optimized using L-BFGS, maps the ERF-adjusted NT vector to individual behavioral SRT. Nested leave-one-out CV enables unbiased hyperparameter optimization and robust generalization estimates.
Performance metrics include Pearson correlation and NRMSE between predicted and behavioral SRTs. Statistical significance is assessed via a robust null distribution of Fisher Z-transformed random correlations.
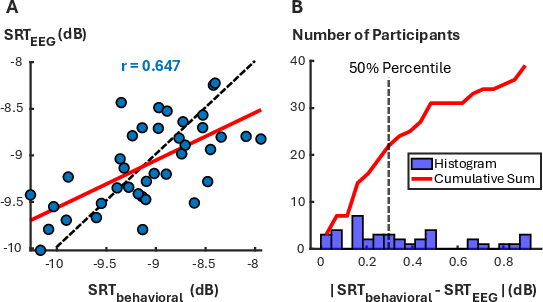
Figure 4: (A) Scatterplot of behavioral vs. predicted SRTs with regression fit, (B) distribution of absolute prediction errors.
Parameter Importance via SHAP Analysis
SHAP (Shapley additive explanations) analysis quantifies the attribution of each decoder parameter/component to SVR prediction. Dominant contributors included:
- Theta and delta frequency bands
- Early integration lags
- Subject-specific decoders
- Story task features
This suggests that low-frequency neural dynamics and individualized modeling are critical for capturing intelligibility-linked brain responses.

Figure 5: SHAP value distribution for feature groups and decoder types, demonstrating relative parameter contribution.
Data Reduction and Clinical Efficiency
Systematic reduction of EEG recording duration confirms:
- Matrix sentence reduction: Directly and adversely impacts prediction accuracy, highlighting the criticality of sufficient stimulus diversity for SS decoders.
- Story duration reduction: Down to 3 minutes without accuracy loss, supporting efficient protocol adaptation.
Combined SI and SS decoders consistently outperform approaches relying on either in isolation.
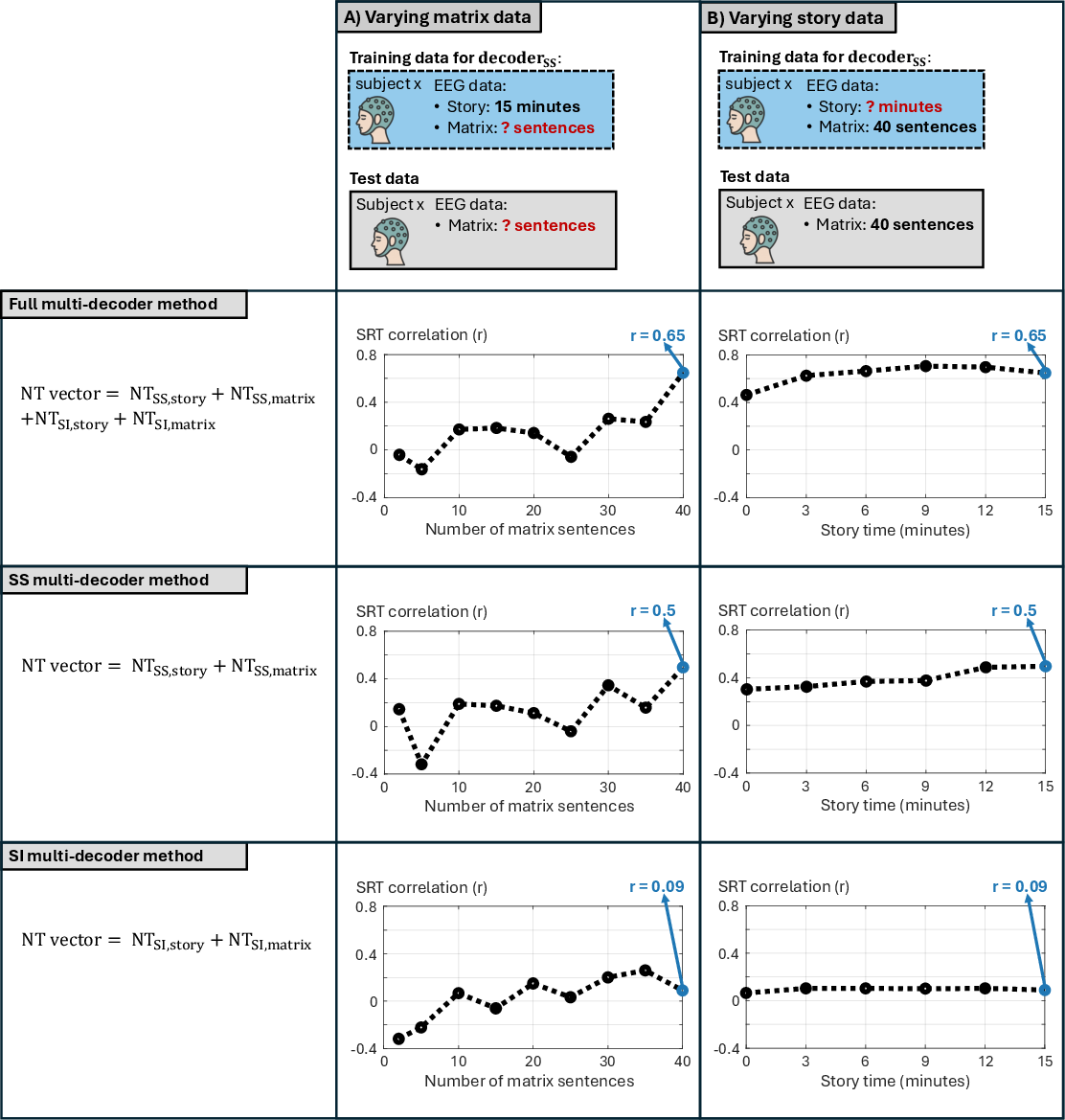
Figure 6: Impact of reducing EEG data (matrix sentence number and story duration) on prediction error for different decoder integration strategies.
Comparative Benchmarking
Despite not yielding the highest raw correlation in literature, the multi-decoder method achieves lowest NRMSE, indicating superior normalized accuracy across lower-variability SRT datasets. Distinct from prior work, this method avoids failure on individual subjects and removes the necessity for post-hoc curve fitting, enhancing both reliability and scalability.
Implications and Future Directions
Practically, this framework is positioned for clinical translation, notably in populations unable to participate in behavioral measurements, such as patients with DOC or pediatric cohorts. The protocol reduces EEG burden to approximately 15 minutes while maintaining sub-decibel precision, advancing usability. Theoretically, the paradigm demonstrates the value of comprehensive parameter integration and individualized neural decoding for objective auditory function assessment.
Future work should:
- Validate in populations with hearing loss and older adults to establish robustness in diverse clinical scenarios.
- Explore exclusive use of continuous audiobook stimuli at multiple SNRs for further ecological gains.
- Refine multi-decoder strategies and feature selection via interpretable machine learning methodologies.
Conclusion
The multi-decoder neural tracking method with ERF-adjusted NT vectors and SVR modeling reliably predicts speech intelligibility with sub-decibel accuracy and minimal data requirements. Parameter attribution underscores the primacy of low-frequency neural tracking and subject-specific modeling. This approach represents an advance toward robust, objective EEG-based intelligibility estimates suitable for populations where behavioral testing is impractical, and should be further examined in broader clinical populations.
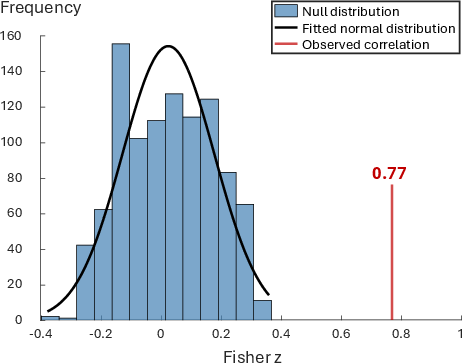
Figure 7: Null distribution for correlation benchmarking, demonstrating that observed SRT prediction correlation is statistically non-chance.