Understanding and Exploiting Weight Update Sparsity for Communication-Efficient Distributed RL
Abstract: Reinforcement learning (RL) is a critical component for post-training LLMs. However, in bandwidth-constrained distributed RL, scalability is often bottlenecked by the synchronization of policy weights from trainers to inference workers, particularly over commodity networks or in decentralized settings. While recent studies suggest that RL updates modify only a small fraction of model parameters, these observations are typically based on coarse checkpoint differences. We present a systematic empirical study of weight-update sparsity at both step-level and multi-step granularities, examining its evolution across training dynamics, off-policy delay, and model scale. We find that update sparsity is consistently high, frequently exceeding 99% across practically relevant settings. Leveraging this structure, we propose PULSE (Patch Updates via Lossless Sparse Encoding), a simple yet highly efficient lossless weight synchronization method that transmits only the indices and values of modified parameters. PULSE is robust to transmission errors and avoids floating-point drift inherent in additive delta schemes. In bandwidth-constrained decentralized environments, our approach achieves over 100x (14 GB to ~108 MB) communication reduction while maintaining bit-identical training dynamics and performance compared to full weight synchronization. By exploiting this structure, PULSE enables decentralized RL training to approach centralized throughput, reducing the bandwidth required for weight synchronization from 20 Gbit/s to 0.2 Gbit/s to maintain high GPU utilization.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Main idea in a nutshell
This paper looks at how to speed up and scale reinforcement learning (RL) training for LLMs when many computers are working together over the internet. The big problem: sending the entire model to many machines over and over is huge and slow. The authors discovered that at each training step, almost none of the model’s numbers actually change, and they built a simple, lossless way—called PULSE—to send only the tiny parts that changed. This cuts network traffic by over 100× without changing how the model learns.
What were the researchers trying to find out?
They asked three simple questions:
- Do only a small number of model weights (think “the model’s knobs”) actually change at each RL step?
- Why does that happen, and when will it keep happening?
- If this is true, can we send only the changed pieces to save a ton of bandwidth, while keeping training exactly the same?
How did they do it? (Explained simply)
Think of an LLM as a giant spreadsheet with billions of numbers (weights). Training is like tweaking those numbers to make the model perform better.
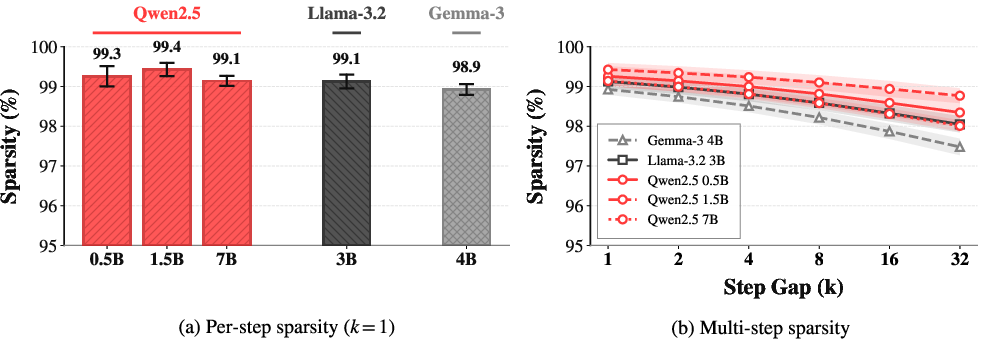
- Measuring “what really changes”: After each training step, they checked which numbers in that spreadsheet were truly different, down to the exact bits. They call this “weight-update sparsity.” If sparsity is 99%, it means only 1% of the numbers changed.
- Why changes are rare: The model’s weights are stored in a format called BF16 (a kind of number with limited precision—like rounding to only a few decimals). If a tweak is too small, it gets rounded away and the saved number doesn’t change. RL uses tiny learning rates (small tweaks), so most changes are too small to show up. Result: few weights actually flip to a new value, even though the “instructions” (gradients) are dense.
- Different conditions they tested:
- Model sizes from 0.5B up to 7B parameters and different model families.
- Single-step and multi-step comparisons (to simulate some delay).
- Different learning rates (small vs. a bit larger).
- “Staleness,” where some machines keep using a slightly older version of the model for a few steps before updating (common in real-world systems).
Analogy: Imagine taking a photo every second of a calm scene. Each new photo looks almost the same—only a few pixels change. Instead of sending the whole photo each time, just send the pixels that changed. That’s the idea.
What did they discover, and why is it important?
Here are the main findings, kept short and clear:
- Very few weights change each step: About 99% of the weights stay exactly the same at every training step across many models and settings.
- It’s not because the “instructions” are sparse: The gradients (the signals that tell how to change) are almost fully dense. The sparsity shows up when saving the new weights because BF16 rounds tiny changes away.
- Learning rate matters: Bigger learning rates make more weights change, so sparsity goes down. But RL usually needs small learning rates to be stable, which naturally keeps sparsity high.
- Delay is okay: Even if machines use a slightly older model for a few steps (staleness), sparsity stays very high (still ≳98% in practical ranges).
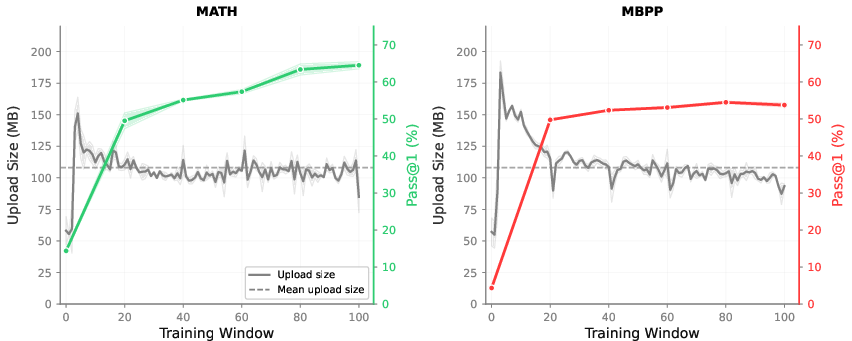
- Huge bandwidth savings: If only 1% of weights change, you can send just those. For a 7B model, that cut the data sent from about 14 GB to roughly 108 MB per update—over 100× smaller—while keeping training outcomes identical.
Why this matters: In real systems, many inference workers need the latest model. Sending 14 GB repeatedly to lots of machines over the public internet is a bottleneck. Cutting this by 100× makes decentralized training practical on normal networks.
What is PULSE, and how does it work?
PULSE stands for “Patch Updates via Lossless Sparse Encoding.” It’s like sending a change log instead of a full copy.
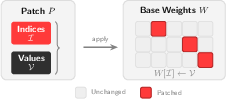
- What it sends: A list of exactly which weights changed (their positions) and their new values.
- What it doesn’t send: It doesn’t send the full model again, and it doesn’t send “add this amount” deltas. It sends the final values, which avoids tiny rounding errors piling up over time.
- How it stays reliable:
- Uses standard compression (like zstd or lz4) to shrink the small patch even more.
- Includes integrity checks (hashes) to make sure receivers reconstruct exactly the same bits.
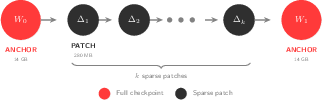
- Organizes updates as short chains: occasional full checkpoints plus many small patches. New or lagging machines can “catch up” by downloading the latest checkpoint and recent patches.
In practice, PULSE turned a requirement of about 20 Gbit/s per machine for high GPU use into about 0.2 Gbit/s—achieving similar throughput to centralized systems but over normal internet links.
So what’s the impact?
- Faster, cheaper, and more accessible RL training: With over 100× less data to send, teams can coordinate training across many machines—even across the world—using ordinary network connections.
- Exactness, not approximation: Because PULSE is lossless and sends final values, the training process stays bit-identical to the full-sync version. No special tuning or error-correction tricks are needed.
- General and robust: The high sparsity held across different model sizes, families, and realistic training setups, including “stale” workers and multi-step gaps.
- Practical proof: They ran PULSE in a live decentralized setting for both math and coding tasks and saw normal learning progress with tiny update sizes.
A quick note on limits and next steps
- They mainly studied one RL method (GRPO) and BF16 precision with Adam-like optimizers. Other methods may behave differently, but past work suggests similar sparsity in RL fine-tuning is common.
- Future work could test longer training runs, more RL variants (like PPO, DPO), and multi-turn dialogues.
Bottom line
Most weights don’t change at each RL step because tiny updates get rounded away by BF16 when learning rates are small. That’s great news for communication: by sending only the changed weights, PULSE slashes bandwidth by over 100× without changing training behavior. This makes distributed RL for LLMs much more practical on everyday networks.
Knowledge Gaps
Unresolved Knowledge Gaps and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research:
- Generalization across RL algorithms: empirically verify update sparsity and PULSE effectiveness for PPO, RLHF, DPO, and variants with explicit KL penalties, beyond GRPO.
- Long-horizon training behavior: study sparsity evolution, compression ratios, and system stability over significantly longer runs (e.g., thousands of steps) and full-scale post-training timelines.
- Multi-turn and tool-augmented RL: measure update sparsity and communication gains for multi-turn conversational RL, tool-use, and agentic tasks with nontrivial environment feedback.
- Optimizer dependence: quantify sparsity under different optimizers (Adafactor, RMSProp, SGD, Lion), derive precise update-absorption thresholds per optimizer, and explore hyperparameter regimes that modulate sparsity.
- Precision format effects: rigorously test BF16 vs FP16 vs FP32 (master weights and pure FP32) and FP8 training; validate claims about sparsity disappearance under pure FP32 and characterize trade-offs in stability/performance.
- Layer- and parameter-type granularity: identify which modules (attention, MLP, layer norm, embeddings, biases) change most/least; exploit structural locality to design finer-grained, higher-ratio patch encodings.
- Hyperparameter sensitivity beyond learning rate: ablate effective batch size, clipping ranges, group size G, temperature/top-p, advantage normalization, reward shaping, and KL penalties to map their impact on gradient magnitudes and update absorption.
- Off-policy delay impact on learning: move beyond sparsity to quantify performance vs staleness k (sample efficiency, stability, final accuracy) and identify safe operational envelopes per task/algorithm.
- Full-sync baseline parity: run matched experiments comparing PULSE vs full checkpoint broadcast to confirm identical training dynamics, final performance, and utilization under controlled bandwidth conditions.
- End-to-end overheads: measure encode/decode CPU time, memory footprint, and patch-apply latency for 7B+ models; assess whether the O(d) diff pass becomes a bottleneck and optimize with streaming or in-place diffing.
- Anchor interval optimization: systematically tune anchor frequency (k) under node churn, network variability, and large fan-out to minimize worst-case recovery time and storage overhead; develop adaptive anchoring policies.
- Multi-trainer/federated scenarios: design and evaluate patch merging, causal ordering, conflict resolution, and versioning (e.g., CRDTs) when multiple learners produce concurrent updates.
- Robustness to transmission faults: characterize behavior under packet loss, partial downloads, bit flips, and corruption; quantify benefits of forward error correction or redundancy beyond SHA-256 verification.
- Cross-hardware reproducibility: validate bit-identical reconstruction across heterogeneous hardware (NVIDIA/AMD/TPU), endianness, and BF16 implementations; define portability constraints and test cases.
- Quantized inference compatibility: study patching when inference uses INT8/FP8 quantization; define workflows for patching dequantized master weights vs quantized tensors and measure performance impacts.
- Security and trust model: specify authentication/authorization for patch publication and retrieval, detect/mitigate poisoning or rollback attacks, and evaluate secure distribution in decentralized settings.
- Scaling to larger models: empirically test sparsity, patch sizes, and throughput for 32B–70B+ models and report broadcast times, relay bottlenecks, and egress costs under public internet constraints.
- Adaptive codec selection: implement online bandwidth probing and dynamic switching between lz4/zstd levels; quantify end-to-end synchronization gains over fixed codec policies.
- Learning capacity under high sparsity: determine whether freezing larger-magnitude weights impedes adaptation; test layer-wise learning rates, weight rescaling, or targeted unfreezing to control which weights can update.
- Parameter-efficient fine-tuning interplay: evaluate PULSE with LoRA/adapters/IA3; compare patch sizes and communication savings relative to full-parameter updates and identify optimal combinations.
- Index mapping across frameworks: formalize and validate index correspondence under FSDP, tensor/pipeline parallelism, parameter sharding, and different inference engines (e.g., vLLM) to prevent mispatching.
- Handling NaNs and special cases: define deterministic rules for bitwise diff and patch application when weights contain NaNs, infinities, or subnormals; test resilience and correctness.
- Relay and fan-out scalability: benchmark object-storage relays (S3/R2) for serving patches to thousands of nodes; analyze caching, rate limits, and backpressure behavior under real workloads.
- Task/domain coverage: extend evaluation beyond MATH/MBPP to NL RLHF, multilingual datasets, multimodal reasoning, and complex code tasks; report domain-specific sparsity and compression variability.
- Context length effects: measure how longer contexts and out-of-distribution prompts alter gradient magnitudes, update absorption, and patch sizes.
- Advanced compression structure: explore block-sparse formats, per-layer segmentation, run-length encoding of contiguous indices, and entropy coding of value streams; provide ablations against general-purpose codecs.
- Memory discipline: quantify double-buffering costs (W_t and W_{t-1}), evaluate streaming diff/patch to reduce memory, and propose designs for memory-constrained nodes.
- Formal losslessness guarantees: state and prove conditions under which patch composition is strictly lossless (ordering, anchoring, integrity), and provide bounds on cumulative storage and recovery latency.
- Delta vs value patching comparison: empirically measure drift and error accumulation in additive-delta schemes (with FP32 masters), contrasting accuracy and robustness with value-based patches.
- Operational metrics in decentralized training: report achieved GPU utilization, wall-clock throughput, iteration speed, and cost reductions with PULSE vs baselines across bandwidth tiers and node heterogeneity.
Practical Applications
Below is an analysis of the paper’s practical, real-world applications, derived from its findings on weight-update sparsity and the proposed PULSE method. Applications are grouped into what can be deployed immediately versus what will likely require further research, scaling, or productization.
Immediate Applications
The following applications are deployable now with existing tooling and standard RL post-training setups. They assume BF16 or mixed precision, Adam-like optimizers, conservative RL learning rates, and a decoupled trainer–inference architecture.
- [Sector: Software/MLOps] Bandwidth-efficient weight synchronization in RL post-training pipelines
- Use case: Replace full checkpoint broadcasts (e.g., 14 GB for 7B models) with PULSE-style sparse patches (~108 MB at ~99% sparsity) when pushing weights from trainers to inference workers.
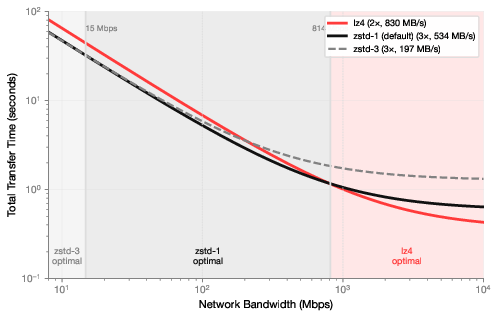
- Tools/workflows: Integrate the PULSE encode/decode path into existing orchestration (e.g., PyTorch-based RLHF/RLAIF/RLVR stacks; object storage relays like S3/R2; compression selection logic: lz4 for >800 Mbit/s, zstd-1 for 14–800 Mbit/s, zstd-3 for <14 Mbit/s).
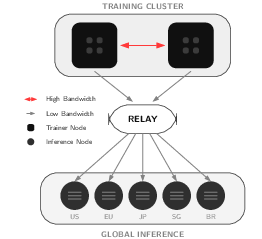
- Assumptions/dependencies: BF16 or mixed precision, Adam (or similar) optimizers, low learning rates typical of RL; dense gradients remain local (high-bandwidth interconnect), sparse weight broadcast uses commodity links; ensure anchor intervals and SHA256 integrity checks for patch chains.
- [Sector: Cloud/Infrastructure] Patch-relay services for geo-distributed inference fleets
- Use case: Offer a managed “patch relay” service that stores and distributes sparse updates to many inference nodes across regions, enabling >100× reduction in upstream link requirements and sustaining high GPU utilization over commodity networks.
- Tools/workflows: CDN-backed object storage, integrity verification (hashes), periodic anchors to minimize late join recovery; bandwidth-aware compressor selection; autoscaling of relay nodes.
- Assumptions/dependencies: Patch format stability, reliable object storage, monitoring for staleness and recovery latency; inference workers can apply patches bit-identically.
- [Sector: Academia/Research] Democratized RL post-training on commodity networks
- Use case: Small labs and classrooms can run GRPO/PPO-style RL post-training across distributed machines (e.g., dorms or campus WANs) using sparse patches, avoiding datacenter-grade links.
- Tools/workflows: Adoption of open-source “grail” integration; reproducible patch-chain logs; standard anchor intervals (e.g., every k steps) to limit worst-case recovery.
- Assumptions/dependencies: Consistent BF16/mixed precision training; modest off-policy delays (k ≤ 8 recommended, robust up to 32); basic DevOps for patch storage and validation.
- [Sector: Enterprise/On-Prem AI] Frequent, verifiable on-prem model updates
- Use case: Vendors ship regular RL post-training updates to customers’ on-prem LLM appliances via sparse patches, ensuring bit-identical reconstruction while minimizing bandwidth and change windows.
- Tools/workflows: Signed patch chains, audit logs, anchor-based recovery, bandwidth-aware compression; integration into CI/CD for model updates.
- Assumptions/dependencies: Consistent model layout across customer deployments; strict integrity checks; policy compliance for software updates.
- [Sector: Healthcare] Privacy-preserving cross-site RL updates
- Use case: Hospital networks keep inference close to PHI data, while central trainers push policy improvements via sparse patches, reducing cross-site data movement and update windows.
- Tools/workflows: Patch-based synchronization with signed hashes, anchor frequency tuned to clinical uptime constraints; local verification workflows.
- Assumptions/dependencies: Compliance (HIPAA/GDPR), isolated inference environments, BF16/mixed precision; conservative learning rates preserve sparsity.
- [Sector: Finance] Secure, auditable model updates over restricted networks
- Use case: Banks deploy patch-based RLHF updates to trading surveillance or compliance assistants on segmented networks, with minimal bandwidth and robust tamper-evidence (hash chain).
- Tools/workflows: Policy-gated patch application, anchor schedules during maintenance windows, immutable logs; compression tuned to WAN constraints.
- Assumptions/dependencies: Strict change-control processes; cryptographic verification; mixed precision and low LR; risk-aware rollback via anchors.
- [Sector: Robotics/Edge AI] Over-the-air (OTA) policy updates for fleets
- Use case: Central trainer broadcasts sparse patches to robots/drones operating in bandwidth-constrained environments; off-policy tolerance enables asynchronous application without halting operations.
- Tools/workflows: Patch receive/apply pipelines with fail-safe anchors; bandwidth-aware compressor; latency-aware anchor intervals to minimize recovery at reconnect.
- Assumptions/dependencies: Reliable OTA channels; BF16/mixed precision on deployable hardware; task-specific validation tests before patch activation.
- [Sector: Education] Practicum-friendly RL post-training modules
- Use case: Course modules that let students coordinate decentralized RL over campus Wi-Fi using PULSE-style patch sync, exposing concepts of off-policy delay, staleness, and compression trade-offs.
- Tools/workflows: Teaching kits using “grail,” dashboards showing utilization vs bandwidth, compressor selection labs, anchor interval experiments.
- Assumptions/dependencies: Controlled environments, pre-configured datasets (MATH/MBPP), reproducible seeds.
- [Sector: Energy/Climate Policy] Immediate bandwidth and energy savings in AI operations
- Use case: Adopt sparse synchronization to reduce data transfer and power usage in AI training operations; include patch-based sync as a best practice in sustainability guidelines.
- Tools/workflows: Reporting of data transfer reduction and carbon savings; internal policy checklists; auditors validate patch-chain integrity and compression use.
- Assumptions/dependencies: Availability of operational telemetry; standardized sustainability metrics; consistent sparsity under adopted hyperparameters.
- [Sector: Developer/Daily Life] Home-lab distributed RL experiments
- Use case: Individual practitioners running small clusters across home ISP links can pursue RLVR experiments by broadcasting sparse patches, avoiding full model transfers.
- Tools/workflows: Simple CLI for patch encode/decode and anchor management; compressor presets; integrity verification; bandwidth diagnostics.
- Assumptions/dependencies: Mixed precision training, low learning rates, patience with off-policy delays; modest hardware.
Long-Term Applications
These applications likely require further research, standardization, hardware co-design, or broader ecosystem adoption. They may also depend on extending the sparsity analysis beyond GRPO and Adam, to other algorithms and optimizers.
- [Sector: Software/Networking] Policy-update CDNs and open patch standards
- Use case: A standardized, interoperable “Model Patch Format” with versioning, signatures, and anchor semantics; CDNs optimized for patch distribution with locality-aware caching.
- Tools/products: Open spec, reference libraries, multi-cloud relays, client-side integrity and rollback tooling.
- Assumptions/dependencies: Community consensus on patch structure; compatibility across frameworks; end-to-end security standards.
- [Sector: Hardware] NIC/DPU offload for sparse patch encode/decode
- Use case: Hardware acceleration for index sorting, delta encoding, compression, and in-place patching to reduce CPU/GPU overhead and improve end-to-end throughput.
- Tools/products: Firmware/driver support; kernel bypass APIs; GPUDirect-style in-memory patch application.
- Assumptions/dependencies: Vendor support; stable patch semantics; measurable gains over software baselines.
- [Sector: Federated/Decentralized AI] Volunteer training networks with patch-ledgers
- Use case: Global federations where trainers publish signed patch chains to a tamper-evident ledger; inference nodes join/leave freely, syncing via anchors; micro-incentives for relay/caching.
- Tools/products: Patch-chain registries, reputation systems, incentive mechanisms, robust recovery protocols.
- Assumptions/dependencies: Governance and security; reliable verification; resilient to churn and byzantine behavior.
- [Sector: Space/Remote Operations] Sparse updates for satellites and remote sensors
- Use case: Push policy improvements to spaceborne or remote edge devices over extremely limited links; patch chains applied during contact windows; anchors reduce recovery latency.
- Tools/products: Radiation-hardened patch application, scheduled compression tiers, predictive anchor planning.
- Assumptions/dependencies: Extreme link constraints; reliable storage; additional fault tolerance; compatible on-device precision.
- [Sector: Robotics/Autonomy] Swarm-wide adaptive policy updates
- Use case: Real-time adaptation across swarms via patch multicast; bandwidth-aware scheduling that prioritizes critical agents; on-device validation against safety invariants.
- Tools/products: Policy-update scheduler, safety validators, graded rollout with canary agents; QoS-aware patch streaming.
- Assumptions/dependencies: Robustness under diverse tasks; hierarchical anchors; safety certification.
- [Sector: Security/Compliance] Cryptographically verifiable patch histories
- Use case: Chain-of-custody for model evolution (e.g., in healthcare/finance), enabling audits, rollbacks, and provenance tracking across regulated environments.
- Tools/products: Signed patches, Merkle-tree anchors, audit dashboards, compliance APIs.
- Assumptions/dependencies: Regulatory acceptance of model provenance artifacts; aligned legal frameworks.
- [Sector: MLOps/Autonomous Systems] Adaptive orchestration based on network telemetry
- Use case: Controllers that adjust compressor level, anchor interval, and synchronization cadence based on live bandwidth/utilization, keeping GPU utilization near targets across heterogeneous links.
- Tools/products: Observability agents, policy engines, auto-tuners integrated with Kubernetes/Ray; SLO-driven orchestration.
- Assumptions/dependencies: Reliable telemetry; stable relationships between LR/sparsity and patch sizes under diverse workloads.
- [Sector: Multimodal AI] Extending sparse synchronization beyond text LLMs
- Use case: Apply lossless sparse patches to RL in vision/speech/code agents if similar BF16 absorption occurs; combine with FP8 to potentially amplify sparsity.
- Tools/products: Cross-modal patch tooling; dataset/task-specific validators; mixed-precision profiles.
- Assumptions/dependencies: Empirical validation of sparsity in other modalities/algorithms (PPO/DPO/actor-critic); optimizer/precision dependencies.
- [Sector: Standards/Policy] Sustainability benchmarks and procurement guidelines
- Use case: Institutional policies requiring patch-based sync for RL training to cap bandwidth and energy consumption; procurement specs favor solutions with demonstrated >50× reduction.
- Tools/products: Certification programs, reporting templates, energy audits aligned to patch usage.
- Assumptions/dependencies: Broad acceptance; robust measurement frameworks; alignment with organizational goals.
- [Sector: Enterprise AI Platforms] Model-as-a-service with incremental RL updates
- Use case: Subscription offerings that stream incremental improvements as patch chains; customers choose anchor cadence and compression profiles to match network realities.
- Tools/products: Customer-managed anchors; SLA for recovery latencies; secure relay integrations.
- Assumptions/dependencies: Product-market fit; platform integration; support across diverse deployment environments.
Cross-cutting assumptions and dependencies to consider
- Precision and optimizer: The observed sparsity hinges on BF16 (or mixed precision) and Adam-style optimizers with conservative RL learning rates; pure FP32 training can remove sparsity entirely, and higher LRs reduce it materially.
- Algorithm generality: Findings are shown for GRPO with RLVR tasks; prior observations suggest similar behavior in PPO-based RLHF, but broader validation (PPO/DPO/actor-critic) is prudent.
- System topology: Sparse patching addresses weight broadcast to inference nodes; gradient communication remains dense and typically needs high-bandwidth interconnects near trainers.
- Off-policy delay: Sparsity and training efficacy remain robust up to k ≈ 8 (recommended) and tested up to 32; anchor intervals should balance recovery latency vs storage.
- Integrity and reliability: Use actual values (not additive deltas) to avoid floating-point drift; enforce SHA256 verification; maintain signed patch chains in regulated settings.
- Compression selection: Throughput vs ratio trade-offs depend on link capacity; lz4 for high-bandwidth datacenters, zstd-1 for typical clouds, zstd-3 for constrained links.
- Model scale and layout: Index encoding depends on consistent parameter ordering across builds; major architecture changes require fresh anchors/full checkpoints.
Glossary
- Advantages: In RL, the advantage function estimates how much better an action is compared to a baseline. "GRPO estimates advantages from group-relative rewards without requiring a learned value function."
- Adam optimization: A popular adaptive gradient-based optimizer used for training neural networks. "This consistency suggests the phenomenon is fundamental to Adam optimization with RL fine-tuning rather than model-specific."
- Allreduce collectives: Distributed communication primitives that aggregate data (e.g., gradients) across multiple nodes efficiently. "Unlike gradient aggregation which uses bandwidth-efficient allreduce collectives."
- Anchor interval: The fixed number of steps between full checkpoints that anchor a chain of sparse patches. "Training nodes publish a full checkpoint every steps (the anchor interval)."
- Asynchronous RL: Reinforcement learning where different components operate without strict synchronization, allowing delayed policy updates. "Within the recommended range for asynchronous RL~\citep{scalerl}, sparsity remains above 98\% for all models."
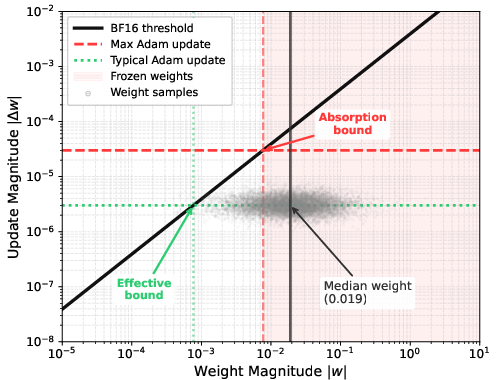
- BF16 precision: Bfloat16, a 16-bit floating-point format with reduced mantissa used to speed training and reduce memory. "Modern LLM training uses BF16 precision, which has limited resolution, so updates smaller than roughly of a weight's magnitude cannot be represented and are rounded away."
- Bit-identical: Exactly the same at the binary level, ensuring no numerical drift across transfers or reconstructions. "Maintaining bit-identical training dynamics and performance compared to full weight synchronization."
- Clipped surrogate objective: An RL objective that limits policy update magnitude to stabilize training, used in PPO-like methods. "The policy is updated using a clipped surrogate objective similar to PPO~\citep{schulman2017proximal}."
- COO representation: Coordinate list format for sparse data that stores indices and values of non-zero entries. "The default configuration uses 2D COO representation with delta encoding, type downscaling, and zstd-1 compression."
- Delta encoding: A compression technique storing differences between consecutive values instead of absolute values. "Delta encoding sorts indices and stores differences between consecutive indices rather than absolute positions."
- Entropy coding: Lossless compression methods that encode symbols based on their probability distribution (e.g., Huffman, arithmetic coding). "Lossless techniques such as entropy coding~\citep{han2016deep} have historically yielded only modest gains with compute overhead."
- Error feedback: A technique that compensates for lossy compression by feeding back the compression error in subsequent updates. "Require mitigation through techniques such as error feedback~\citep{sparseloco} or extensive hyperparameter tuning."
- Fan-out pattern: A broadcast communication pattern where one sender transmits to many receivers, stressing bandwidth. "This fan-out pattern makes weight transfer particularly sensitive to bandwidth constraints, as the same payload must reach every inference worker."
- Floating-point drift: Accumulated numerical error over successive floating-point operations or reconstructions. "PULSE is robust to transmission errors and avoids floating-point drift inherent in additive delta schemes."
- FP32: 32-bit floating-point format providing higher precision than BF16. "Training with pure FP32 eliminates sparsity entirely while achieving identical model performance."
- FP8: 8-bit floating-point format with even lower precision than BF16, often for extreme efficiency. "Lower-precision formats (e.g., FP8) will exhibit even higher sparsity, compounding computational savings with reduced communication costs."
- GRPO: Group Relative Policy Optimization, an RL algorithm that uses group-based advantage estimation without a value function. "We use Group Relative Policy Optimization (GRPO)~\citep{shao2024deepseekmath}, the dominant algorithm for training reasoning models."
- Gradient compression: Methods that compress gradients to reduce communication in distributed training. "The communication bottleneck in distributed training has traditionally motivated extensive research into gradient compression~\citep{alistarh2017qsgd,lin2018deep,vogels2019powersgd}."
- Integrity verification: Ensuring data authenticity and correctness, often via cryptographic hashes. "Each patch includes a SHA256 hash of the resulting weights for integrity verification."
- KL divergence penalty: A regularization term penalizing deviation between updated and reference policies. "Following recent work~\citep{yu2025dapo,liu2025drgrpo}, we omit the KL divergence penalty."
- LZ4: A fast, low-latency lossless compression algorithm. "At high bandwidth, encoding time dominates, so fast algorithms (lz4) minimize total transfer time."
- Mantissa: The significand part of a floating-point number that determines precision. "BF16's limited mantissa means updates must exceed a weight-dependent threshold to take effect."
- Mixed-precision training: Training that uses lower-precision arithmetic for most operations while keeping some values (e.g., master weights) in higher precision. "Mixed-precision training, where BF16 is used for computation while optimizer master weights remain in FP32~\citep{micikevicius2018mixed,sheng2025hybridflow}, preserves the same level of sparsity."
- Object storage: Scalable storage systems for blobs (e.g., checkpoints), typically cloud-hosted. "Training nodes publish sparse patches to centralized object storage (e.g., Cloudflare R2, AWS S3), while inference nodes pull updates independently."
- Off-policy delay: The number of steps by which policy weights used for rollouts lag behind the current training step. "A rollout generated using parameters is said to have an off-policy delay of steps."
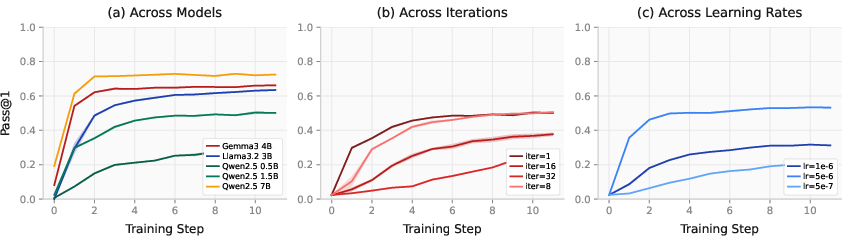
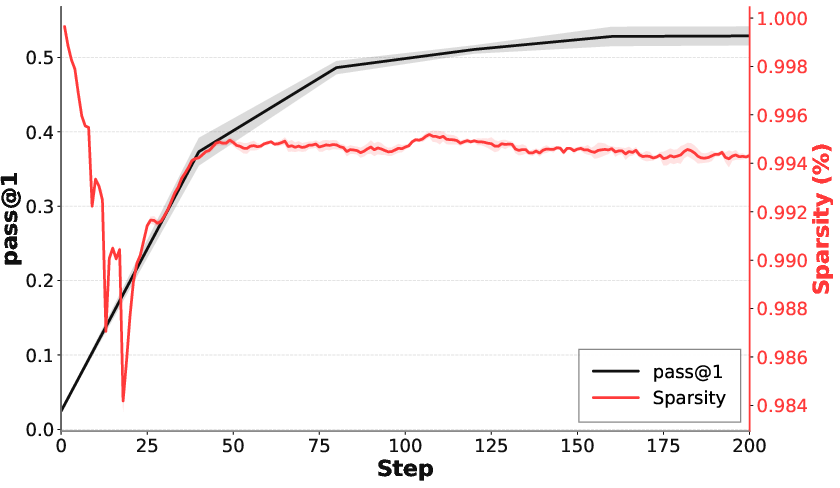
- Pass@1: Evaluation metric indicating the proportion of problems solved correctly on the first attempt. "Pass@1 accuracy curves on validation sets across all models (\Cref{app:training_curves}); performance plateaus by step 400 in most cases."
- Policy staleness: Using outdated policy weights to generate rollouts due to asynchronous updates. "This policy staleness is common in asynchronous training."
- PPO: Proximal Policy Optimization, an RL algorithm employing clipped objectives to stabilize updates. "The policy is updated using a clipped surrogate objective similar to PPO~\citep{schulman2017proximal}."
- PULSE: Patch Updates via Lossless Sparse Encoding, a method that transmits only changed weights for synchronization. "We propose PULSE (Patch Updates via Lossless Sparse Encoding), a simple yet highly efficient lossless weight synchronization method that transmits only the indices and values of modified parameters."
- Replay buffer: Storage of past trajectories or rollouts used for training in RL, often enabling off-policy updates. "The trainer runs continuously, sampling from a replay buffer while background processes handle checkpoint uploads and rollout downloads at window boundaries."
- RLAIF: Reinforcement Learning from AI Feedback, which replaces human annotations with AI-generated feedback. "Reinforcement Learning from AI Feedback (RLAIF)~\citep{bai2022constitutional,lee2024rlaif} scales this approach by substituting human annotators with AI models."
- RLHF: Reinforcement Learning from Human Feedback, using human preferences to guide policy training. "Reinforcement Learning from Human Feedback (RLHF)~\citep{ouyang2022training,christiano2017deep,stiennon2020learning} uses human preference data to encourage instruction-following behavior."
- RLVR: Reinforcement Learning with Verifiable Rewards, where rewards are computed by programmatic verifiers. "Reinforcement Learning with Verifiable Rewards (RLVR) uses tasks with programmatically verifiable outcomes, such as mathematics and code, to provide objective reward signals."
- SHA-256: A cryptographic hash function used to verify data integrity. "All weight transfers pass SHA-256 verification, confirming bitwise-identical reconstruction at inference nodes."
- Top-p: Nucleus sampling method that truncates to the smallest set of tokens whose cumulative probability exceeds p. "We sample rollouts with temperature $1.0$ and top- to encourage exploration."
- Type downscaling: Reducing integer width to compress small deltas or indices. "Type downscaling represents these small deltas using narrower integer types (e.g., uint16 instead of int32)."
- Update absorption: The phenomenon where small updates are rounded away due to limited floating-point precision. "Our measurements reveal the opposite: gradients are nearly fully dense ... through a phenomenon we call update absorption: modern LLM training uses BF16 precision..."
- Verifier: A programmatic checker that determines whether a generated response satisfies task constraints. "A verifier defines a reward function indicating whether satisfies the task constraints (e.g., correct final answer)."
- Zstd: Zstandard, a general-purpose compression algorithm offering strong ratios at high speed. "Our default configuration using zstd-1 achieves on average, with some architectures reaching ."
Collections
Sign up for free to add this paper to one or more collections.