- The paper presents a comprehensive 3D asset generation benchmark that standardizes quality with 252k assets, 240k part decompositions, and 125k synthetic samples.
- The paper introduces full-level and part-level data pipelines that ensure watertight meshes, uniform orientation, and detailed structural annotations for robust 3D modeling.
- The paper’s empirical evaluation reveals that models trained on HY3D-Bench achieve competitive fidelity with state-of-the-art methods while using significantly fewer parameters.
HY3D-Bench: A Foundation for Structured, High-Fidelity 3D Asset Generation
Motivation and Context
Advances in generative models and neural representations have dramatically expanded the possibilities for automatic 3D content creation. However, progress towards robust 3D generation, perception, and practical applications has been hindered by significant limitations in available 3D datasets—namely, inconsistent asset quality, incomplete geometric representations, and lack of fine-grained structural annotations. "HY3D-Bench: Generation of 3D Assets" (2602.03907) addresses these challenges by proposing an open-source, standardized benchmark and data ecosystem explicitly designed for 3D asset generation and part-level understanding, targeting performance, diversity, and reproducibility across multiple tasks.
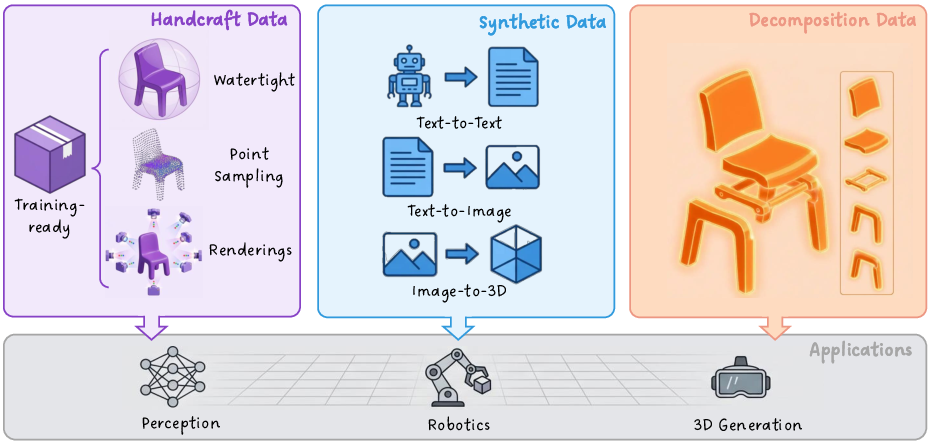
Figure 1: HY3D-Bench provides a unifying ecosystem with 252k high-quality 3D assets, 240k structured part-level decompositions, and 125k AIGC-synthesized long-tail category samples.
Review of 3D Generation Paradigms
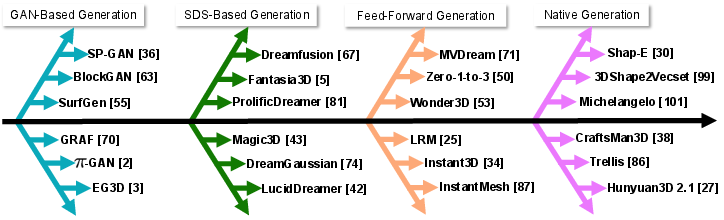
The paper situates HY3D-Bench within the broader trajectory of 3D generative modeling, which has evolved from traditional manual modeling to four major machine learning paradigms (Figure 2):
Benchmark Design and Data Processing
Full-Level Data Pipeline
The full-level data pipeline (Figure 3) addresses deficiencies in existing repositories by establishing a comprehensive and automated workflow for converting diverse, noisy 3D assets into high-fidelity, training-ready meshes with watertight geometry and multi-view renderings. The pipeline includes strict asset filtering, topology repair, and point-cloud sampling guided by both surface uniformity and edge importance. Notably, it achieves a standardized orientation and format conducive to downstream tasks involving learning-based 3D asset generation.

Figure 3: Full-level Data Processing Pipeline emphasizing asset normalization, rigorous filtering, watertight mesh extraction, and training-ready export.
Part-Level Data Pipeline
HY3D-Bench significantly advances structured asset understanding by integrating a part-level data pipeline (Figure 4). This pipeline leverages connected component analysis, automatic merging, and area-based filtering to decompose holistic objects into semantically meaningful and topologically valid components. Assets are further validated for reasonable component number, scale balance, and suppression of trivial or decorative parts. The result is over 240k samples providing robust, hierarchical decompositions—a resource exceptionally useful for controllable part-level generation and robotic manipulation research.

Figure 4: Part-level Data Processing Pipeline enabling consistent decomposition and fine-grained control for 3D representation learning.
Scalable Synthetic Data Generation
Category imbalance in naturally curated datasets is counteracted through a scalable synthetic data pipeline (Figure 5) that exploits LLM- and diffusion-based text-to-image and image-to-3D generative steps. By systematically expanding semantic prompts and customizing text-to-image models via LoRA, the pipeline generates over 125k synthetic assets across 1,252 fine-grained categories—significantly extending long-tail category coverage and diversity, crucial for developing models capable of real-world generalization.
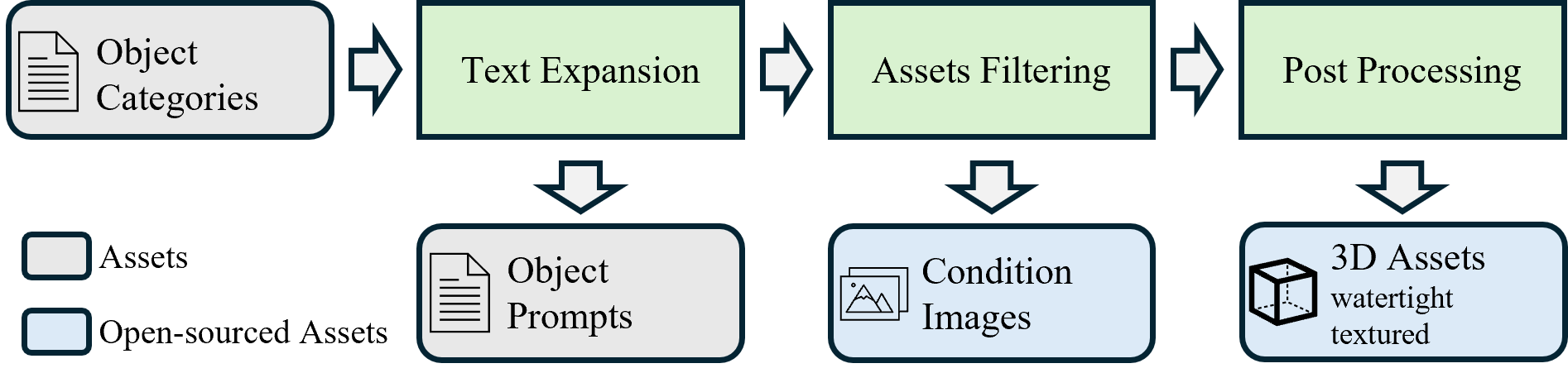
Figure 5: The synthetic data generating pipeline employs semantic expansion, visual synthesis, and robust mesh reconstruction for long-tail category coverage.
Dataset Characteristics and Distribution
The assets in HY3D-Bench span 19 top-level categories and 389 subcategories for full-level data, with a test suite of 400 objects designed for standardized algorithm benchmarking. Detailed visualization reveals the geometric richness and varietal scope, further enhanced by the inclusion of part-level and synthetic assets.
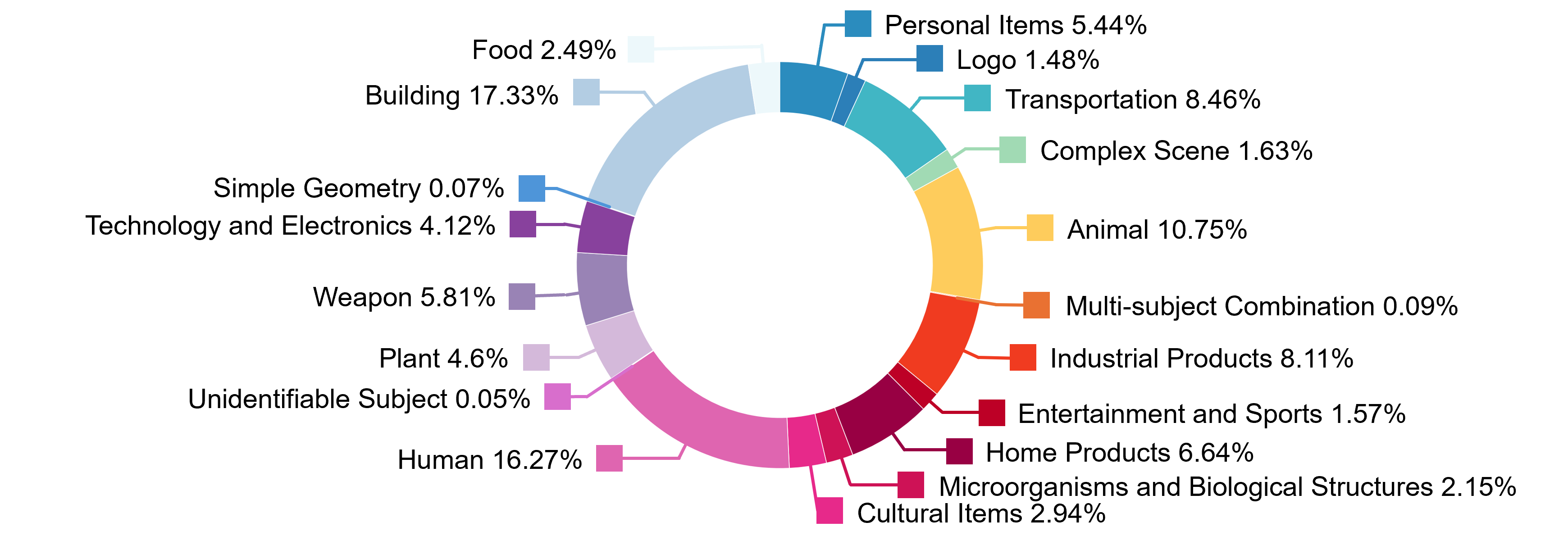
Figure 6: Top-level Category Distribution of Full-level Data shows broad semantic coverage.
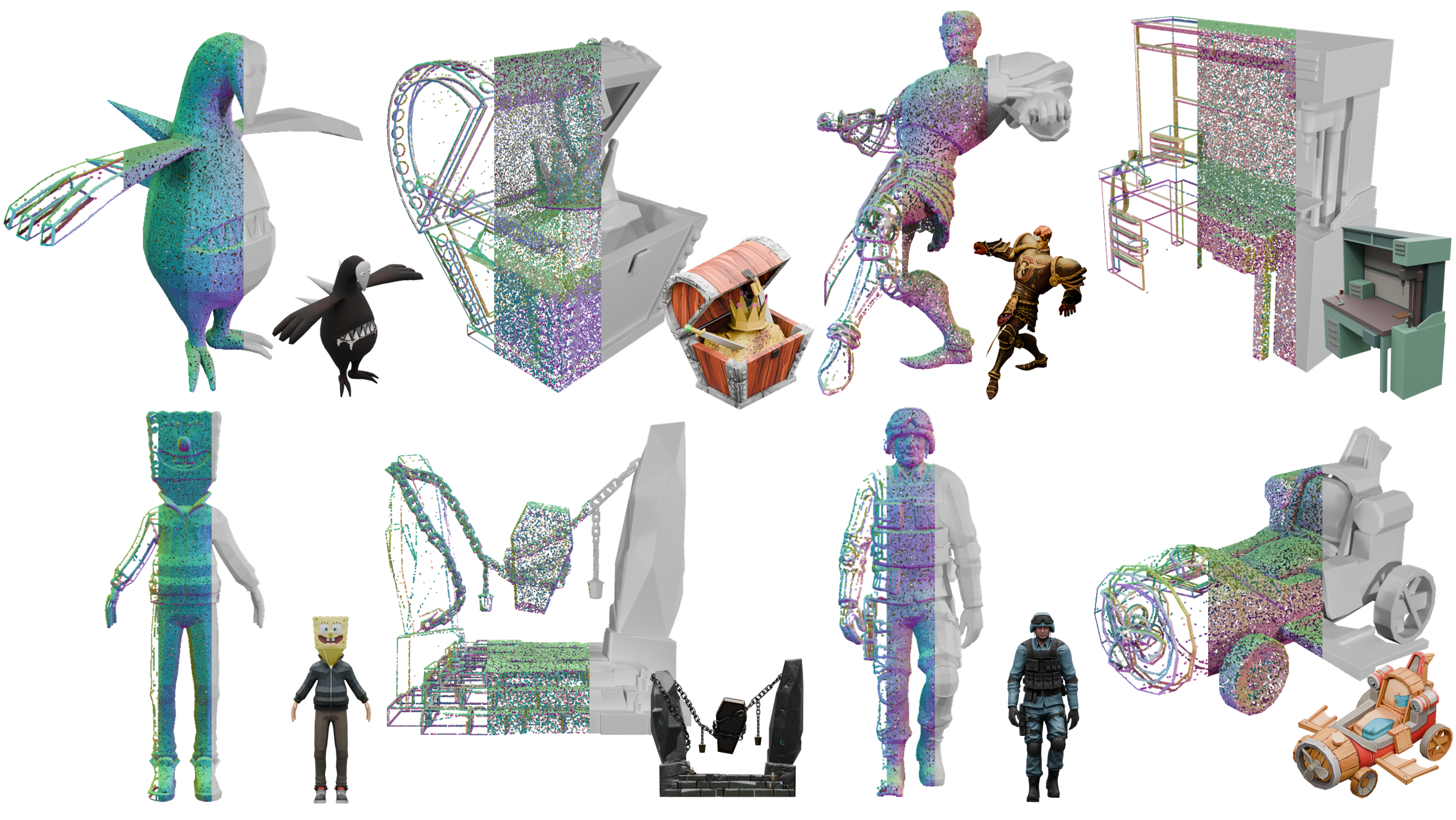
Figure 7: Visualization of representative full-level 3D assets, including mesh details and multi-view renderings.
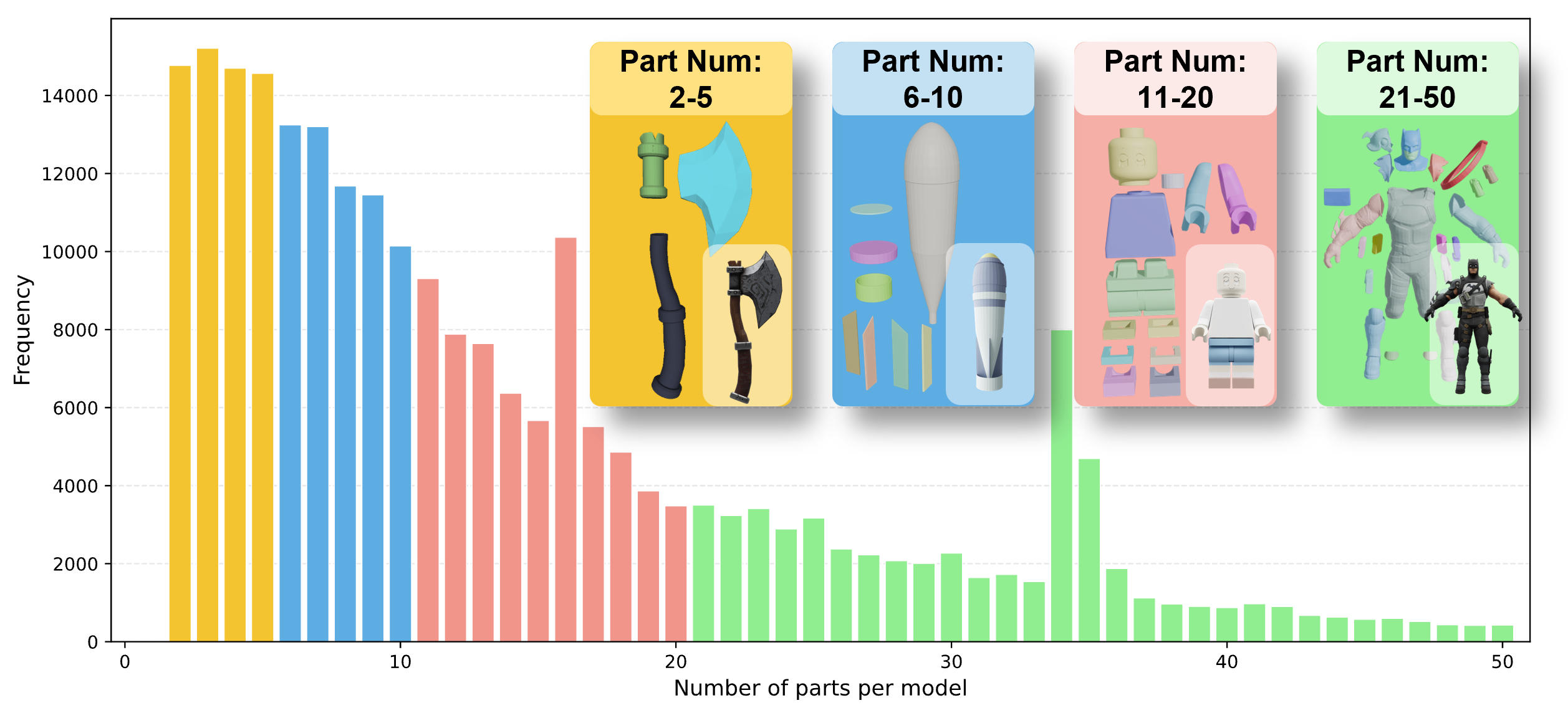
Figure 8: Distribution of component counts in the part-level dataset, indicating structural diversity and the inclusion of texture variants.

Figure 9: Visualization of part-level assets, highlighting component decomposition and color-coded assembly.
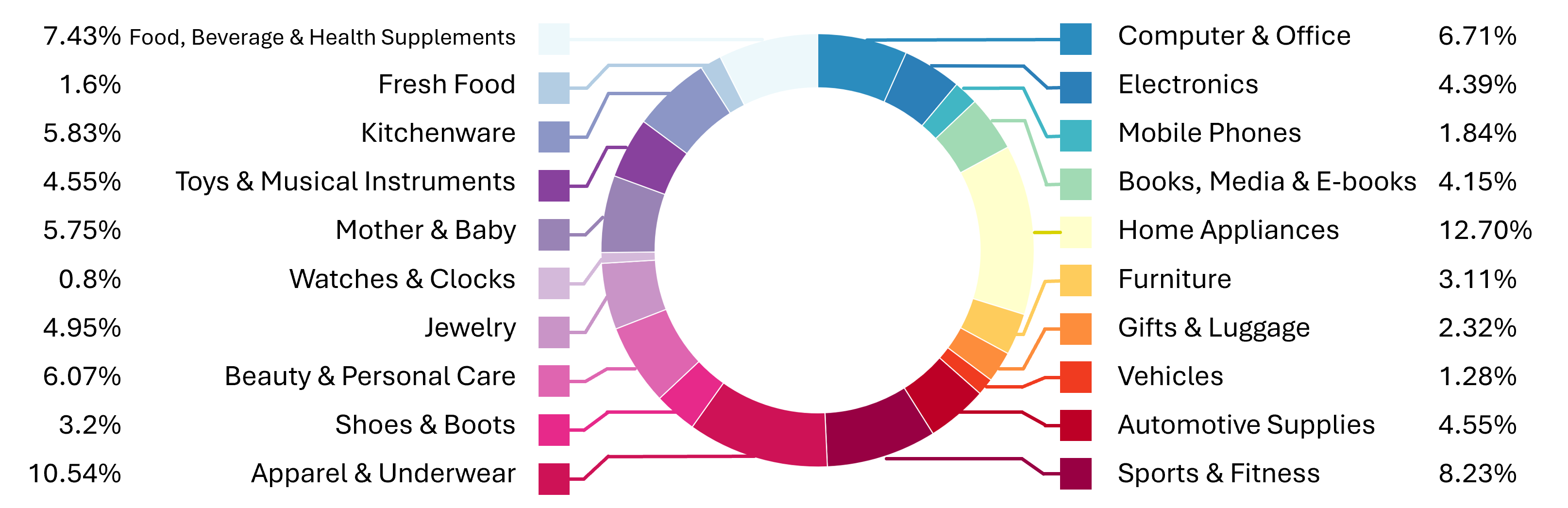
Figure 10: Top-level Category Distribution in the synthetic dataset underscores extended coverage across product-relevant domains.

Figure 11: Examples from the synthetic dataset, illustrating generated variety at the fine-grained category level.
Empirical Evaluation
To empirically validate HY3D-Bench as a data source for generative tasks, a lightweight version of Hunyuan3D-2.1 ("Small", 832M parameters) is evaluated on the image-to-3D generation task. Notably, HY3D-Bench-trained models achieve generation quality on par with state-of-the-art large models such as Trellis and Hunyuan3D 2.1, and superior to comparably scaled alternatives such as CraftsMan, despite having significantly fewer parameters. This supports the claim that data quality and standardization are at least as important as scaling model parameters for effective 3D generation.

Figure 12: Qualitative comparison of image-to-3D generation performance on the test set—the HY3D-Bench model achieves competitive fidelity and detail.
Practical and Theoretical Implications
HY3D-Bench provides a unified resource that resolves the major data curation bottlenecks in 3D generative modeling, lowering entry barriers and allowing the research community to focus on algorithmic innovation rather than pre-processing overhead. The inclusion of structured and synthetic data facilitates advances in part-aware modeling, controllable editing, and synthesis for rare object categories, while also supporting fair benchmarking through a fixed evaluation protocol.
Theoretically, HY3D-Bench's design supports transition towards models that not only generate holistic geometry, but encode and leverage fine-grained structure, enabling more reliable reasoning and interaction in downstream robotics and digital content creation pipelines. The framework also sets the stage for future exploration into dynamic asset generation, richer scene composition, and integration with physical simulation environments.
Conclusion
HY3D-Bench represents a comprehensive and systematic effort to standardize, expand, and structure the data foundations of 3D asset generation and understanding. By offering high-quality, watertight, and hierarchically organized datasets, alongside standardized evaluation protocols, it serves as a critical catalyst for further progress in generative modeling, 3D perception, and downstream application domains (2602.03907). Future directions include support for dynamic assets and expansion to broader 3D tasks.