- The paper introduces TrajFusion, a framework that fuses correct and incorrect trajectories to enhance LLM mathematical reasoning.
- It employs an adaptive selection mechanism based on error frequency and diversity, achieving notable gains in Pass@1 accuracy.
- TrajFusion improves sample efficiency and interpretability without modifying core training protocols, supporting scalable integration.
Structured Supervision for Mathematical Reasoning: An Analysis of TrajFusion
Motivation and Limitations of Rejection Sampling Fine-Tuning
LLMs have demonstrated significant progress in mathematical reasoning, frequently using chain-of-thought (CoT) prompting and supervised fine-tuning on solution trajectories. A predominant method for constructing supervision is rejection sampling fine-tuning (RFT), which filters trajectories generated by a teacher model and retains only those with correct final answers. While RFT is highly effective and scalable—requiring no human annotation and improving performance across mathematical benchmarks—it systematically discards all incorrect model-generated solution trajectories. This exclusion ignores substantial diagnostic signal available in reasoning failures, such as computational slips, missing assumptions, or faulty argument paths.
The central claim established in this work is that teacher-generated incorrect trajectories should be incorporated as structured supervision for models, rather than treated as mere noise. The discarded trajectory pool, which often encodes diverse failure modes, offers a nuanced view of model uncertainty and reasoning instability, especially in ambiguous or long-form scenarios.
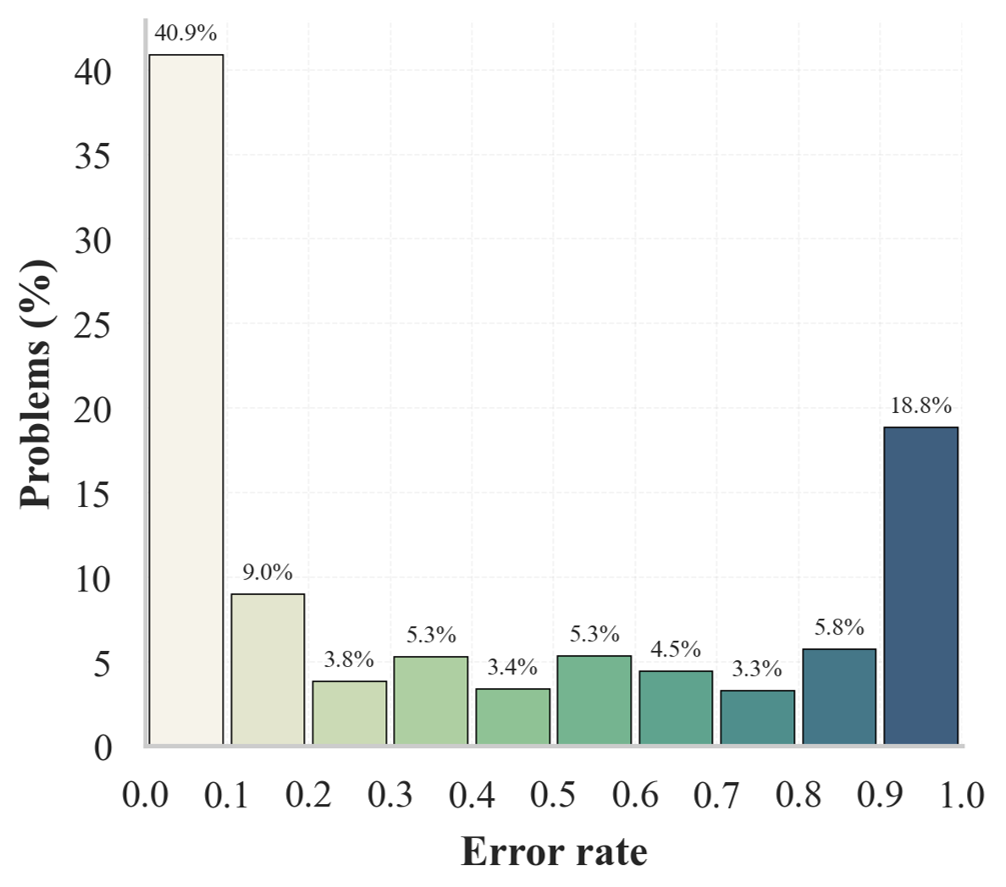
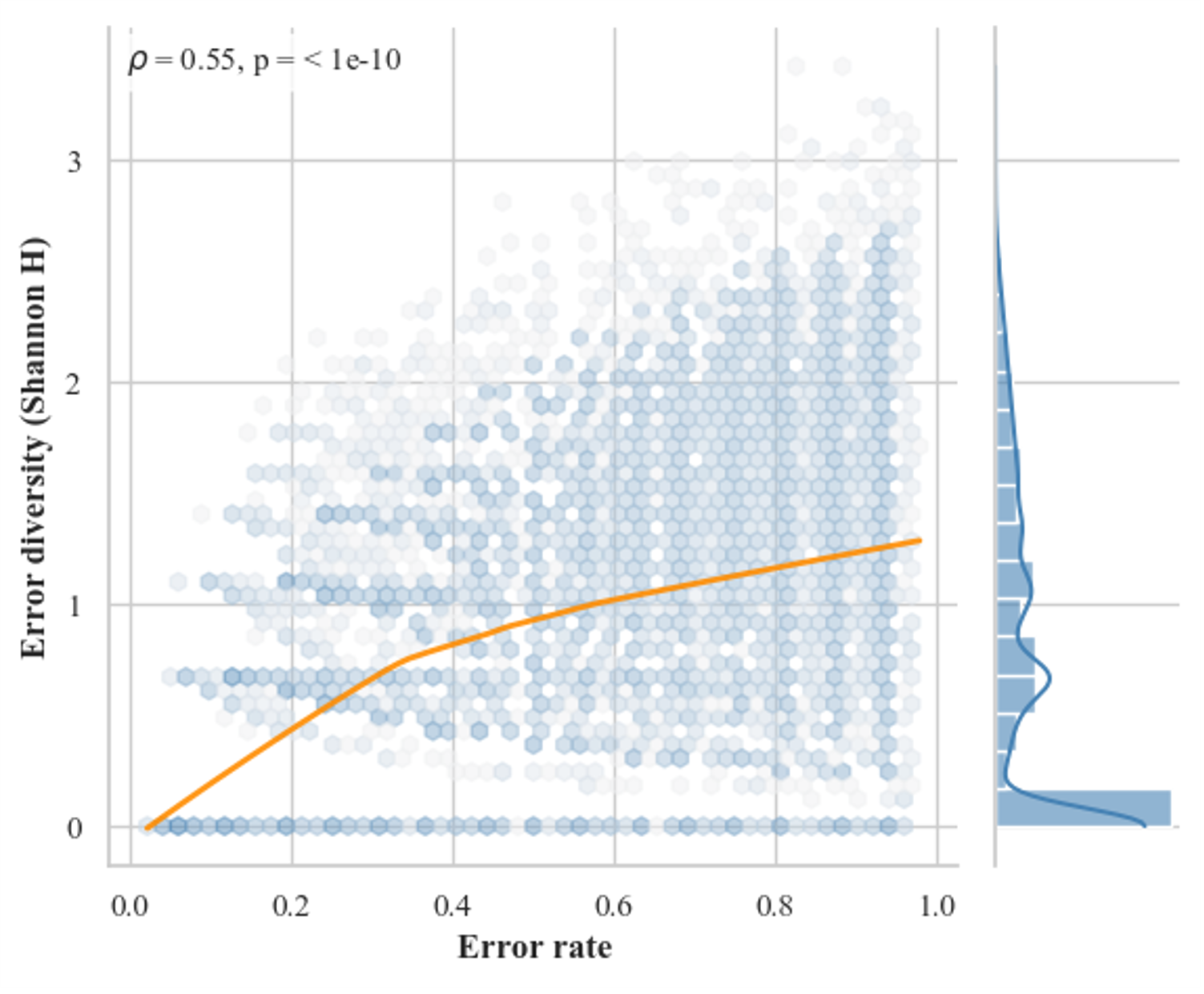
Figure 1: Distribution of error rates (left) and error diversity as Shannon entropy (right) for Qwen2.5-Math-7B-Instruct on DeepMath. Rich structural variation exists in the discarded samples.
The TrajFusion Framework
TrajFusion is presented as a simple, architecture-agnostic extension to vanilla RFT. Its key mechanism is the construction of fused trajectories by interleaving selected incorrect trajectories (with associated reflection prompts) and correct ones. This construction simulates the trial-and-error process, exposing the model to both typical failure modes and correct recoveries.
The selection procedure is adaptive: the amount of fused content is strictly controlled by statistics of error frequency and error diversity (measured via error rate and the distinct final answers, respectively). When the sampled set is dominated by trivial or homogeneous failures (low diversity), fewer or no incorrect trajectories are included; for highly diverse or frequent errors, more are fused into the supervision.
TrajFusion requires no auxiliary preference models, critique generators, architectural modifications, or training loss changes. It operates entirely as a data construction layer, enriching supervision with rich structural error signals.
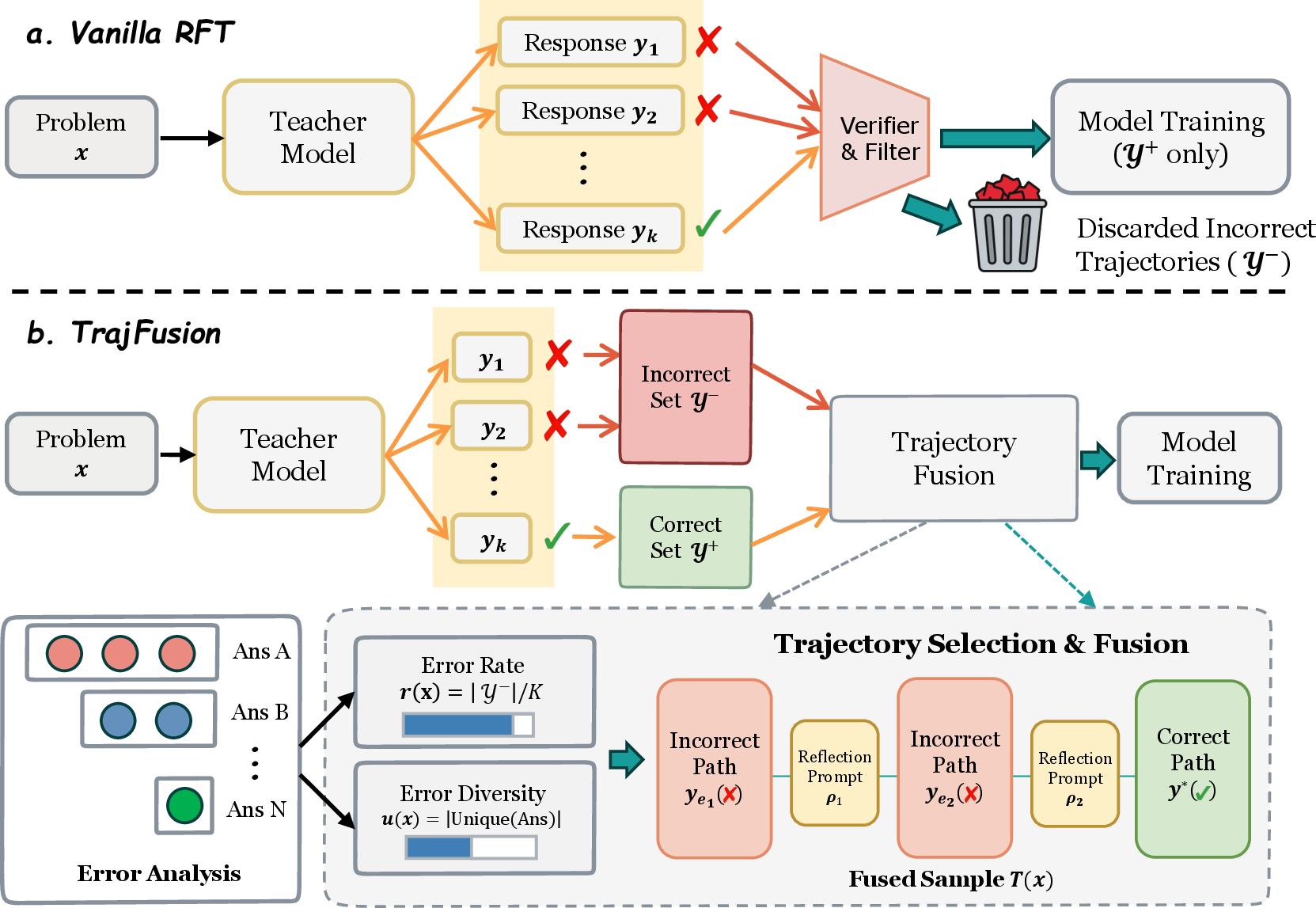
Figure 2: Schematic comparison of vanilla rejection sampling (top) and TrajFusion (bottom): incorrect trajectories are selectively incorporated alongside reflections and correct paths.
Empirical Evidence and Quantitative Gains
TrajFusion is evaluated across two backbone models (LLaMA3-8B, DeepSeekMath-7B) on six established mathematical benchmarks. Experiments are conducted in both low-data (15K) and full-data (100K) regimes. The method is further applied at scale to long-context reasoning via the Qwen2.5-Math-7B model (up to 32K tokens).
Quantitative gains are observed in all settings, with strong improvements in Pass@1 accuracy, particularly on mathematically challenging and long-form datasets:
- On MATH, using DeepSeekMath-7B and 100K examples, TrajFusion achieves 59.1% Pass@1, compared to 56.2% for RFT and lower for other advanced baselines.
- On OlympiadBench and TheoremQA, improvements are especially pronounced, matching or surpassing state-of-the-art using substantially fewer samples.
- On long-context data (AIME24, AIME25, MATH-500), TrajFusion outperforms RFT with both 4K and 32K context lengths.
In all scenarios, TrajFusion is more sample-efficient: given the same training budget, it establishes and maintains a robust gap over vanilla RFT early during training.
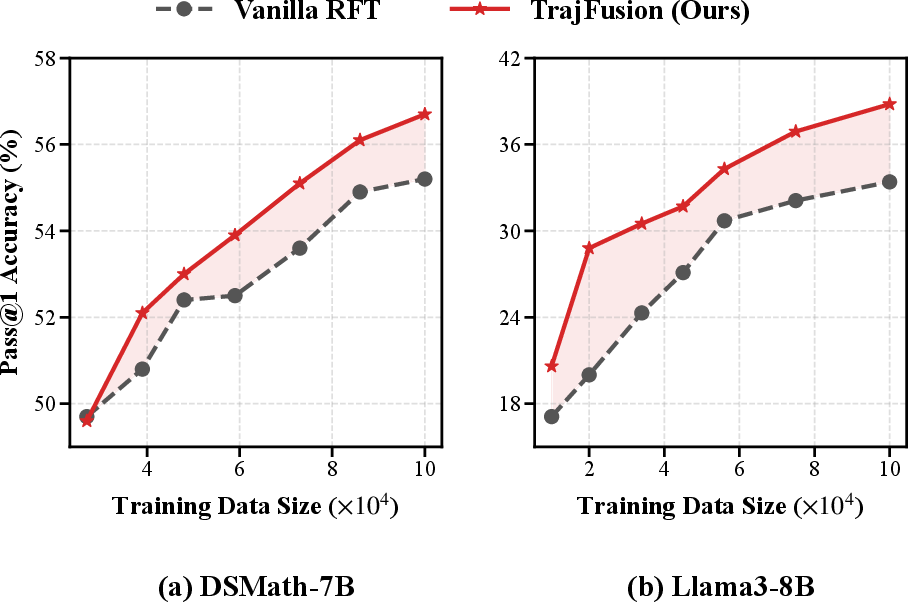
Figure 3: Pass@1 accuracy evolution on MATH (first epoch). TrajFusion consistently outpaces vanilla RFT in both models; margin appears early and persists.
Ablation analyses on the number and diversity of fused error trajectories demonstrate that moderate quantities of structurally distinct incorrect samples are consistently beneficial. However, excessive repetition or redundant inclusion produces diminishing returns.
Behavioral Analysis: Output Compactness and Reflection
TrajFusion-trained models initially produce longer generations (due to the trial-and-error format), but average output length decreases as training progresses, reflecting increased reasoning efficiency. The frequency of reflection tokens—explicit signals for error recognition and correction—shows a consistent upward trend, especially on more complex datasets such as MATH.
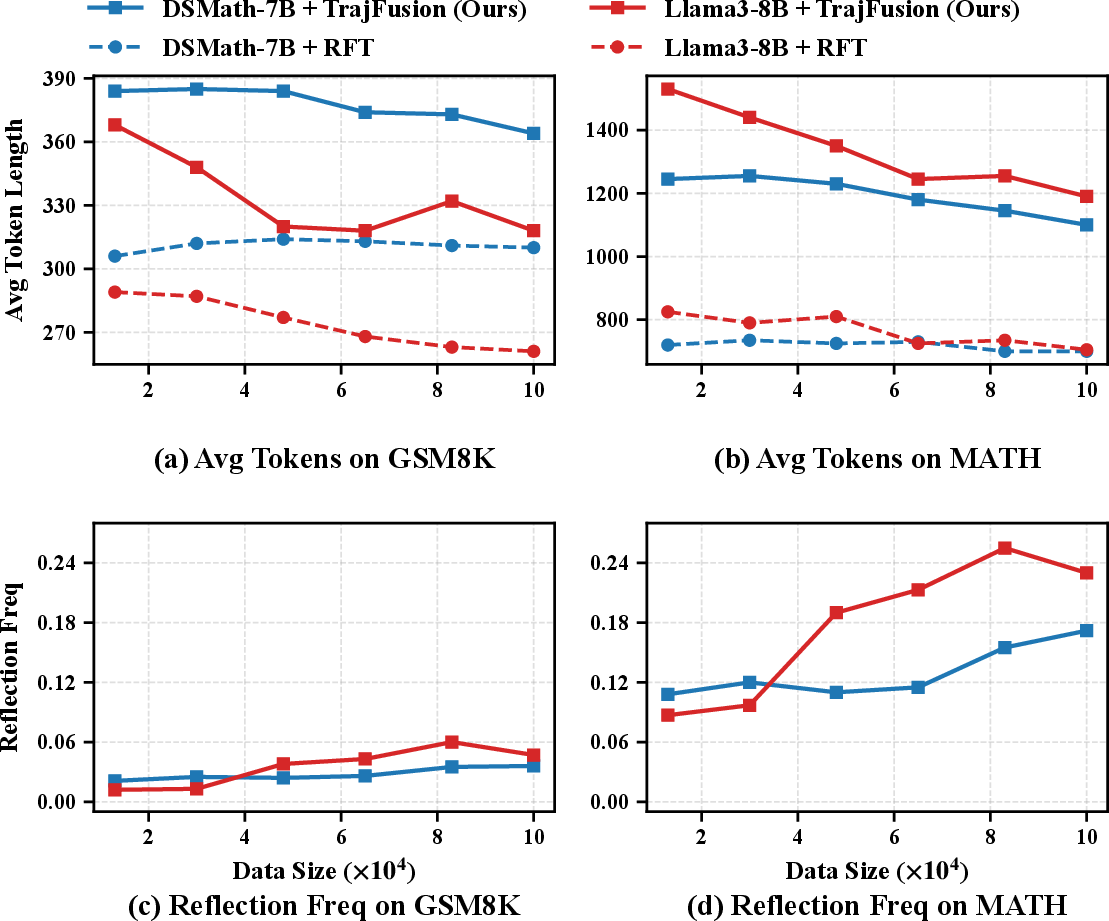
Figure 4: (a, b) Average output length declines with training, while (c, d) the frequency of reflection tokens rises, particularly on more complex mathematical tasks.
Qualitative analysis further shows that the inclusion of structured reflections enhances not only accuracy but also interpretability, as models become more adept at diagnosing and correcting their own computational mistakes in multi-step settings.
Implications and Future Research Directions
TrajFusion operationalizes a central theoretical insight: model-generated reasoning failures encode informative supervision that can systematically improve the robustness and sample efficiency of LLMs for mathematical reasoning. The method is agnostic to model, context length, and dataset, and it requires no changes to core learning protocols.
Practical implications include:
- Scalable and adaptive integration into existing RFT data pipelines in mathematical domains.
- Enhanced resilience and sample efficiency in low-data regimes, supporting model training with reduced annotation requirements.
- Improved interpretability in chain-of-thought outputs, beneficial for downstream educational or critique applications.
Theoretically, this work motivates further investigation into richer utility functions over model-sampled solution sets, especially those integrating trajectory-level structure (not just scalar preferences). There is opportunity to generalize the approach to other domains featuring compositional or hierarchical reasoning tasks.
Future work includes:
- Exploration of more sophisticated fusion/adaptive mechanisms, including dynamic error trajectory selection and contextualized reflection generation.
- Integration with advanced RLHF and preference learning frameworks, seeking to further leverage negative signals in supervised and reinforcement learning contexts.
- Assessment on broader scientific reasoning, theoretical proof generation, or strongly multimodal mathematical domains.
Conclusion
TrajFusion reframes rejection sampling from a binary filtering paradigm to a structured supervision process that leverages both correct and strategically curated incorrect solution trajectories. Empirical evidence across multiple benchmarks and backbone models demonstrates consistent gains in both performance and sample efficiency, with pronounced effects on complex, long-form reasoning. The framework introduces a versatile, model-agnostic mechanism for augmenting mathematical reasoning capabilities in LLMs.
The consistent improvement of TrajFusion over RFT supports the thesis that negative reasoning signals, when integrated systematically, drive substantive advances in the robustness and generality of mathematical LLMs.