- The paper introduces EgoActor, a novel framework that directly grounds natural language into low-level egocentric actions for humanoid robots.
- It employs a dual action representation—Structured Language Actions (SLAs) and Natural Language Actions (NLAs)—to effectively manage both navigation and manipulation tasks.
- Extensive benchmarks show that EgoActor achieves superior success rates in obstacle avoidance, mobile manipulation, and human–robot interaction through advanced spatial reasoning.
EgoActor: Grounding Task Planning into Egocentric, Spatially-Aware Actions for Humanoid Robots
Introduction and Motivation
EgoActor addresses the persistent challenge of deploying humanoid robots in dynamic real-world environments, which demand tightly coupled perception, locomotion, manipulation, and interaction capabilities under egocentric, partially observable conditions. Traditional approaches to robot task planning either rely on modular controllers or restrict themselves to pre-defined skill libraries, limiting adaptability and the ability to generalize outside structured tasks. EgoActor confronts this by directly grounding natural language instructions into low-level, egocentric action sequences leveraging vision-LLMs (VLMs) and a newly defined EgoActing task. This formulation emphasizes spatial reasoning and cohesive control for movement, perception, manipulation, and human interaction, laying the groundwork for more robust, autonomous humanoid agency.
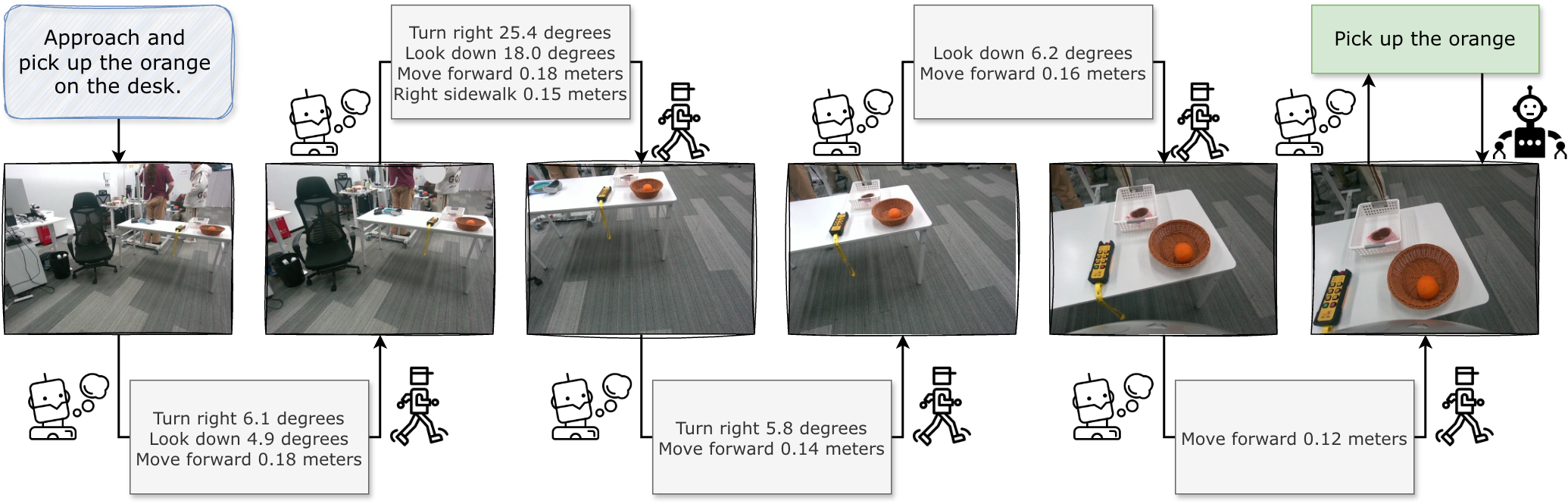
Figure 1: Visualization of EgoActor's working procedure for a given task: ``Approach and pick up the orange on the desk''. The grey blocks represent structured language actions (SLAs) and the green blocks represent natural language actions (NLAs).
The EgoActing task is formalized as predicting the next action at from the set of capabilities A, conditioned on the instruction I, egocentric observation history O1:t, action history a1:t−1, and policy set Π. EgoActor decomposes actions into two classes:
- Structured Language Actions (SLAs): Concise, template-based primitives specifying movement or perception (e.g., "Turn left 30.5 degrees", "Move forward 0.6 meters"). These provide interpretable, spatially-grounded control for navigation and orientation.
- Natural Language Actions (NLAs): Open-ended commands for manipulation and interaction (e.g., "Pick up the cup", "Say hi to the person"), supporting task flexibility and intent expression beyond fixed skill sets.
This dual representation supports robust, generalizable grounding from instruction to action.

Figure 2: Example natural language actions (NLA) in EgoActing. EgoActor is trained to predict the corresponding actions based on obtained RGB observations.
Model Architecture and Training Pipeline
EgoActor is instantiated as a transformer-based VLM (specifically, Qwen3-VL) finetuned via LoRA adaptation. Training is performed over diverse data modalities to enhance embodied spatial intelligence and action grounding:
- Egocentric real-world videos (over 150,000 samples): Capturing authentic perceptual inputs and action transitions under varied layouts.
- Internet-scale datasets (EgoTaskQA): Enriching the training distribution with diverse tasks and complex instructions.
- Virtual environments (VLN-CE, Habitat-Sim): Providing structured spatial navigation trajectories for controlled supervision.
- Spatial reasoning resources (MindCube): Augmenting the model’s understanding of spatial relations.
- Visual-language understanding/planning datasets (GQA, RoboVQA, EgoPlan, ALFRED): Ensuring cross-task transfer and planning synergy.
Actions are predicted using uniform sampling over history and recent observations, allowing context-aware discrimination of next actions and facilitating sub-second inference latency on both 4B and 8B parameter scales.
Benchmarking and Empirical Results
Human-Robot Interaction
EgoActor demonstrates the capacity to resolve attribute-based referential ambiguity and perform seamless approach–interaction pipelines in both single- and multi-person scenarios, outperforming representative navigation-only VLMs (NaVid, Uni-NaVid, NaVILA) in success rates for both navigation and the subsequent interaction. The 8B variant shows significantly enhanced attribute disambiguation and dialogue act generation.
Mobile Manipulation
Under unseen object/layout conditions, EgoActor (especially the 8B model) achieves high success in both approach-and-pick and approach-and-place tasks, for both seen and out-of-distribution objects, confirming robust integration between navigation and fine manipulation cues.

Figure 3: An illustration of our model conducting the mobile manipulation task: ``Approach and grab the pink cup''.
Traversability and Obstacle Avoidance
Traversability experiments in narrow passages (room entry/exit, doorways) highlight EgoActor’s marked superiority in avoiding collisions relative to baseline VLN models. The model generalizes to novel obstacles and layouts, exploiting spatial reasoning learned from first-person data and adjusting behavioral primitives adaptively.

Figure 4: Multi-step illustration of obstacle avoidance generalization of our model, when faced with an unseen string obstacle.
Active Perception and Human-Like Behavior
EgoActor exhibits context-dependent active perception—modulating gaze, posture, and trajectory for task-relevant exploration or to maximize future manipulation success. These behaviors, captured in both real-world and simulation, include nuanced repositioning, joint control sequences, and human-like combined turning/strafe maneuvers.

Figure 5: First-person view of an EgoActor's active perception trace. Color description blocks highlight model's behaviors.

Figure 6: First-person view of an EgoActor's traversability trace, showing the robot walking through a doorway.

Figure 7: First-person view of an EgoActor's height change ability trace in virtual environments. Color description blocks highlight model's behaviors.
Strong Numerical Results and Claims
Across benchmarks, EgoActor (8B, real-world/virtual) achieves:
- Traversability success rates >85% (doorways, unseen layouts), significantly surpassing all baselines (often by >30–40% absolute margin).
- Mobile manipulation (unseen objects/scenes): 100% success in approach-and-pick tasks on some targets, with failures largely attributable to downstream skill execution rather than intent prediction.
- Human–robot interaction: Perfect success in single-person approach + interaction, and robust performance in out-of-distribution multi-person scenarios.
- Virtual environment (<1.0m to goal): >70% success rates; >87% within 3m, substantially higher than baseline VLM navigation models, which plateau below 60% under lenient thresholds.
The results underscore superior transfer of abstract task specifications into actionable, egocentric motor sequences, with sharp improvements in spatial precision, attribute resolution, and qualitative smoothness of behavior.
Discussion: Theoretical and Practical Implications
EgoActor demonstrates a practical pathway for integrating high-level language planning and low-level whole-body control exclusively via egocentric RGB, without reliance on additional sensors or highly engineered skill libraries. The unified action representation enables seamless multi-modal transitions and reduces design/annotation overhead. The architecture’s scalability with data and model size, as well as its generalization across environments and instructions, indicates promise for future generalist humanoid agents.
Notably, existing VLN and classical navigation models—when retrofitted to direct robot control—struggle with spatial miscalibration, over-navigation, and insufficient action intent grounding, underscoring the necessity of architectures like EgoActor.
Limitations and Prospects
EgoActor depends heavily on the integrity and ability of downstream control polices (locomotion, manipulation, speech), and is not end-to-end from perception to physical actuation. Long-horizon compositional tasks and tightly coupled multi-agent scenarios remain challenging. Future extensions could integrate multi-modal sensory inputs, recurrent memory, or direct policy learning for closed-loop, fully unified control.
Ongoing research may enhance the framework by incorporating more diverse skills, real-world feedback (on-policy reinforcement or human-in-the-loop correction), and expanded action ontologies, ultimately facilitating more adaptive, safe, and autonomous humanoid behavior.
Conclusion
EgoActor establishes a new paradigm for grounding task planning into egocentric, spatially-aware whole-body actions in humanoid robots via vision-LLMs. Through a combination of unified action representation, diverse data curation, and rigorous benchmarking, it achieves robust generalization in dynamic, real-world settings. This approach robustly bridges the gap between high-level task abstraction and low-level execution, setting a new technical baseline for scalable, instruction-driven humanoid autonomy.
[The full details and benchmarks are available at (2602.04515).]