- The paper presents VK-LSVD, a dataset with over 40 billion interactions and diverse multi-modal metadata for realistic short-video recommendation studies.
- It employs latent factor analysis to reveal heavy-tailed distributions and demographic structuring that influence user preferences.
- Benchmark experiments using methods like iALS highlight challenges in sparsity and long-tail effects, setting new standards for evaluation.
VK-LSVD: A Large-Scale Industrial Dataset for Advancing Short-Video Recommendation
Motivation and Context
Short-video platforms present inherent challenges for recommender systems: rapid context shifts, a predominant reliance on implicit signals (e.g., watch time), multi-modal content, and evolving user preferences. Academic progress in the field is hampered by the lack of public datasets with sufficient interaction scale, temporal granularity, and realistic, multi-faceted feedback that collectively characterize industrial short-video ecosystems. Compared to established datasets such as Netflix Prize and MovieLens, which are limited in side information and sequential structure, and Kuaishou-derived releases that are user- or temporally restricted, there remains a significant gap for comprehensive datasets facilitating realistic experimentation. VK-LSVD is designed to directly address this vacuum and provide a robust public foundation for recommender systems research.
Dataset Characteristics and Technical Details
VK-LSVD comprises over 40 billion user-item interactions, sourced from 10 million users and nearly 20 million videos over a 6-month window. Crucially, the dataset captures rich, multi-modal content-side embeddings (compressed via SVD), user socio-demographics, a spectrum of implicit (watch time), explicit (like/dislike), viral (shares), and deep engagement (e.g., comment opens, bookmarks) feedback channels, and comprehensive contextual metadata for each interaction (including platform, consumption context, and client agent). Anonymization is enforced across all categorical fields, fully removing PII and complying with privacy regulations.
The dataset’s structure adheres to best engineering practices:
- Chronologically ordered events partitioned by week (train/valid/test) with an enforced global temporal split for real-world sequential evaluation.
- Static user and item metadata files supporting activity- or popularity-based subset sampling for diverse experimental setups.
- Item embeddings in 64-dimensional float16 arrays, supporting scalable and efficient heterogeneous modeling.
Every user-item pair records parameters for the first exposure; watch time aggregates successive replays up to a bounded cap. The dataset’s density is 0.0208%, emphasizing the sparsity characteristic of industrial recommender settings.
Statistical Properties and Latent Factor Analysis
VK-LSVD systematically demonstrates the behavioral and statistical regularities of real-world platforms. User activity and item popularity distributions are shown to be heavy-tailed, indicative of a small fraction of highly active users and viral content drivers, with the majority of users and items exhibiting low to moderate engagement.
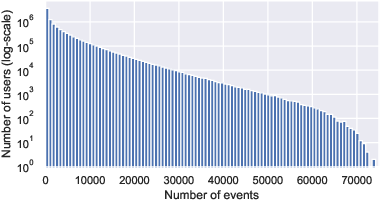
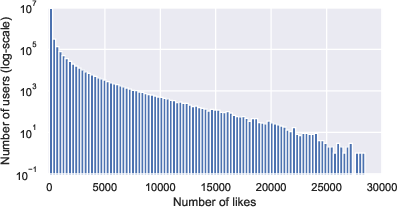
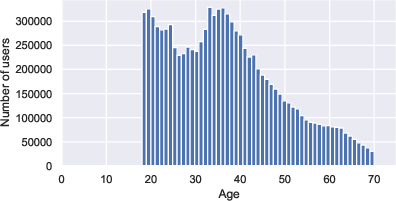
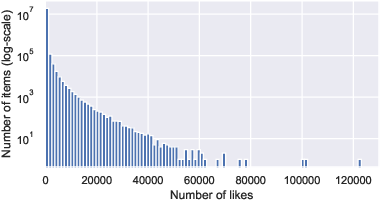
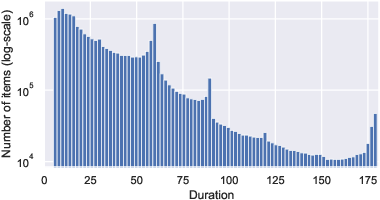
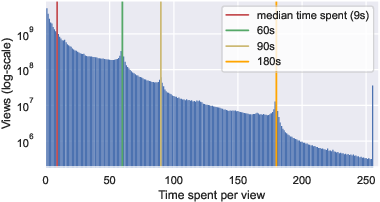
Figure 1: Key user and item statistics reveal characteristic heavy-tailed distributions, with the majority of users and items responsible for a small fraction of interactions but a small subset dominating overall engagement.
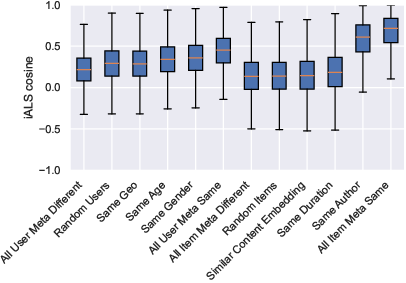
Latent factor analysis via iALS (with positive signals defined as watch time > 10s and positive feedback, negative signals as dislikes) reveals:
These analyses confirm the suitability of VK-LSVD for probing both traditional collaborative filtering paradigms and advanced, context-aware, multi-modal recommendation tasks. The diversity and completeness of attributes facilitate the study of user preference evolution, session dynamics, and content cold-start.
Benchmarking and Evaluation Protocols
VK-LSVD provides subsets (e.g., 1% most active users/items) and utility sampling scripts, allowing researchers to adapt the data to realistic computational constraints while preserving ecosystem characteristics. Baseline experiments (Random, Global Popularity, Conversion, iALS) establish initial performance profiles for the dataset, with iALS achieving an NDCG@20 of 0.06554 on random splits, underscoring the challenge inherent in the data’s extreme sparsity, long-tail structure, and feedback diversity.
The live VK RecSys Challenge 2025 leverages VK-LSVD as its core dataset, with a distinct cold-start user ranking task evaluated via NDCG@100 per video and an enforced limit on recommendations per user, reflecting practical production constraints. With nearly 800 teams participating, anticipated results will provide a direct benchmark for evaluating sequential and content-based models under real-world constraints.
Practical and Theoretical Implications
VK-LSVD sets a new experimental standard for large-scale, multi-modal, and context-rich short-video recommendation research. Its design enables:
- Benchmarking session-based, sequential, context-aware, and hybrid recommender models at scale.
- Systematic analysis of cold-start and long-tail scenarios, including item and user-side cold-start, addressing limitations in earlier datasets.
- Investigations of bias and fairness, given the inclusion of demographic fields and the potential for algorithmic disparate impact.
From a theoretical perspective, VK-LSVD facilitates research on compositional representations (via content embeddings), structural dynamics (demographic and content-driven latent spaces), and robust evaluation protocols leveraging temporally-disjoint splits.
Future Directions
VK-LSVD unlocks substantive opportunities in algorithmic development, fairness analysis, and application to novel tasks such as real-time engagement prediction, trend detection, and fair, privacy-preserving personalization. Anticipated directions include leveraging graph-based and transformer architectures for cross-modal sequence modeling, unbiased evaluation using realistic negative sampling, and domain-adaptive transfer scenarios.
VK-LSVD also motivates comparative studies with domain-specialized datasets (e.g., Yambda-5B for music, T-ECD for synthetic cross-domain tasks), investigating domain transfer and generalization in recommender systems with highly heterogeneous feedback and content encoding.
Conclusion
VK-LSVD provides a foundational infrastructure for short-video recommendation research, supporting scalable, realistic evaluations for next-generation personalized systems. Its combination of scale, feedback diversity, content embeddings, and contextual richness enables the community to address open challenges in sequential modeling, cold-start intervention, and fairness, while bridging the gap between academic research and industrial deployment (2602.04567).