ERNIE 5.0 Technical Report
Abstract: In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces ERNIE 5.0, a very large AI model that can both understand and create text, images, video, and audio—all inside one unified system. Instead of being a text model with add‑ons for pictures or sound, ERNIE 5.0 learns all these skills together from the start, so it can handle rich, mixed-media tasks more naturally and efficiently.
What the paper is trying to do
The paper sets out to:
- Build one model that can understand and generate multiple types of content (text, images, video, audio) using the same method.
- Keep the model powerful but make it flexible enough to run on different computers, from big servers to smaller devices.
- Train it in a way that avoids the usual trade-offs (like getting better at images but worse at text).
- Make reinforcement learning (a way of improving the model by rewarding good answers) stable and efficient for such a huge, multi-skill system.
How the model works (explained simply)
Think of ERNIE 5.0 like a giant, smart “storyteller” that reads and writes using the same rules, no matter the medium.
The core idea: tokens and prediction
- Everything—text, pictures, video frames, sounds—is turned into small pieces called “tokens,” kind of like LEGO bricks.
- The model learns to predict the “next token” or the “next group of tokens,” similar to guessing the next word in a sentence. That same idea gets extended to images (next parts of the image), video (next frame and details), and audio (next chunks of sound).
A team of experts inside the model
- ERNIE 5.0 uses a Mixture-of-Experts (MoE). Imagine a big team of specialist teachers. For each token, a “router” picks a few of the best experts to help, so the model stays fast while being very capable.
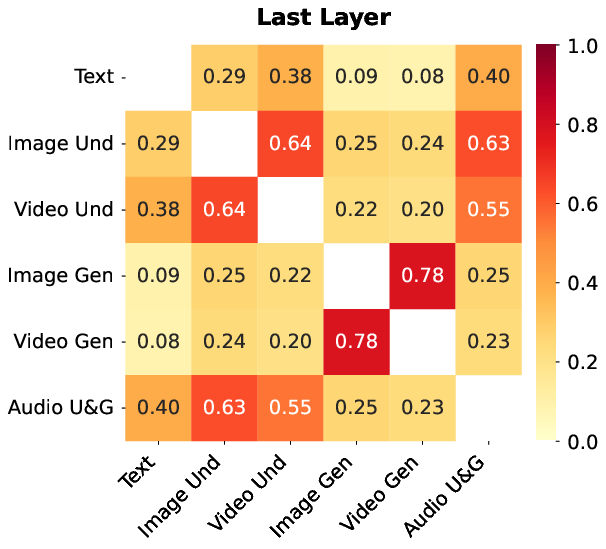
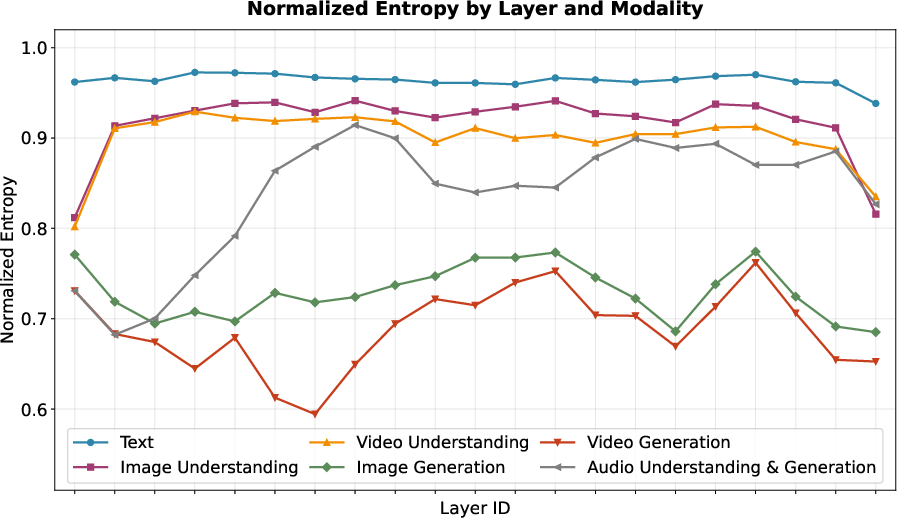
- The routing is “modality-agnostic,” meaning the router doesn’t just pick teachers based on whether it’s image or audio—it picks based on what the token seems to need. This helps experts learn useful skills that can transfer across text, images, and audio.
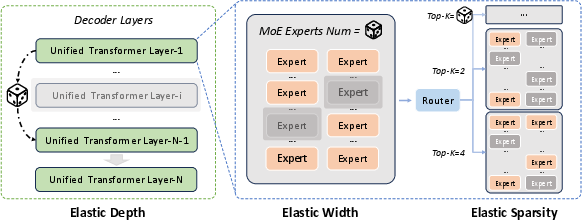
Elastic training: one training run, many model sizes
- Instead of training a huge model and later compressing it, ERNIE 5.0 trains in a way that naturally supports smaller versions inside it.
- It randomly practices being:
- Shallower (fewer layers),
- Narrower (fewer experts available),
- Sparser (activating fewer experts per token).
- This is like training a sports team to play well with different numbers of players. Later, you can easily “spawn” a smaller model for faster use, without retraining from scratch.
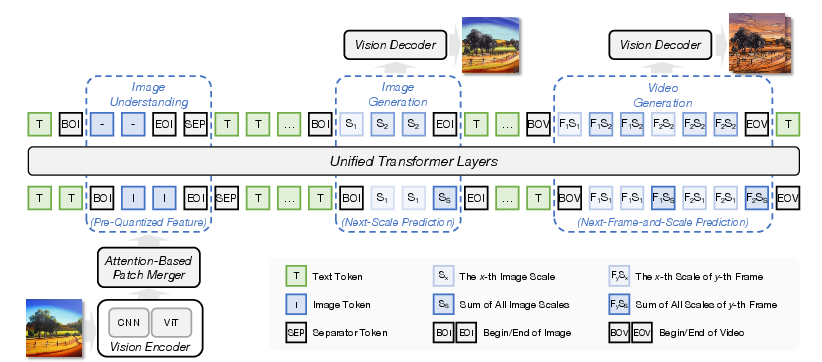
Visual (image/video) modeling
- Images and videos are turned into tokens using a special “tokenizer” that captures both big-picture meaning and fine details.
- For generation, ERNIE uses Next‑Frame‑and‑Scale Prediction (NFSP):
- For images, it predicts from low‑resolution to high‑resolution within the same image (coarse to fine).
- For videos, it predicts frame by frame over time.
- There’s also a separate “refiner” (like a detail-enhancing filter) that sharpens and beautifies the final image/video at high resolution.
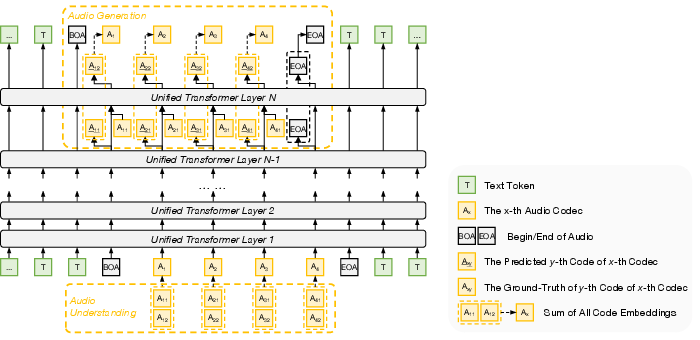
Audio (speech/sound) modeling
- Audio is broken into layered “codec” tokens (coarse meaning first, then finer acoustic details).
- For generation, ERNIE uses Next‑Codec Prediction (NCP):
- It predicts the semantic code first (the general content), then adds finer layers of sound detail step by step.
- This keeps sequences short and efficient while producing high-quality audio.
Post-training: teaching by examples and rewards
- After pre-training, ERNIE gets supervised fine‑tuning (SFT): it learns from lots of example instructions and good answers.
- Then it does unified multimodal reinforcement learning (UMRL): a verifier system scores its responses across text, image, video, and audio tasks, and ERNIE learns from rewards.
- The team added tricks to make this stable and efficient (like an unbiased replay buffer that speeds up training without favoring only short, easy examples).
Main findings and why they matter
- Strong, balanced performance: ERNIE 5.0 does very well in both understanding and generating across text, images, video, and audio—without sacrificing one skill for another.
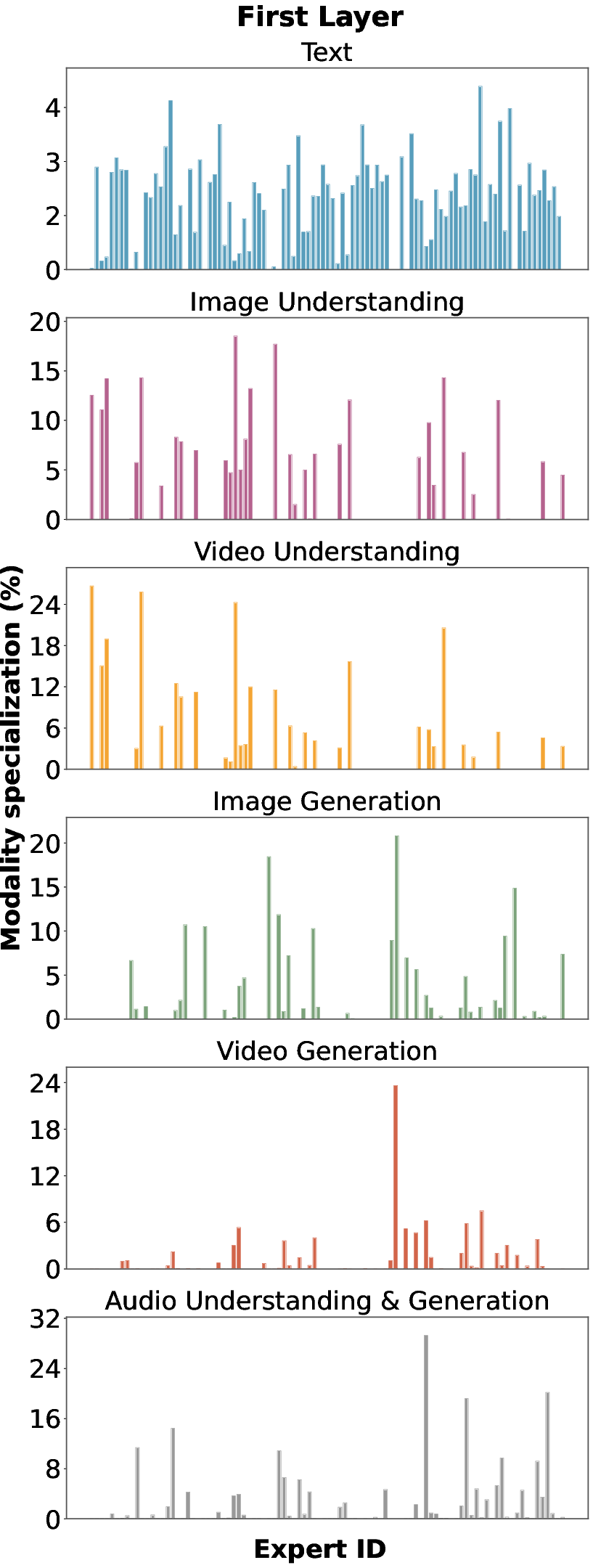
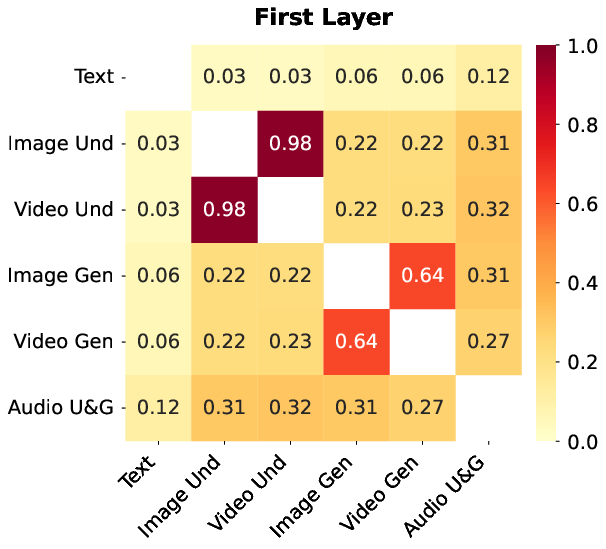
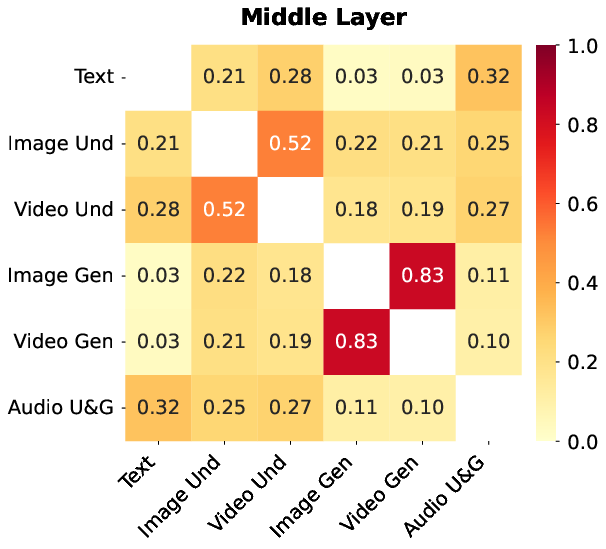
- Smart expert behavior: Even with one shared routing system, the experts naturally specialize based on task needs. This suggests cross-modal training helps experts learn generalizable skills.
- Faster inference with minimal loss: Using fewer experts per token (reducing routing “top‑k” to about 25%) speeds up decoding by over 15%, with only a small drop in accuracy.
- Elastic training works: Smaller sub-models created by selecting fewer parameters retain nearly full performance. One result showed about 53.7% of the usual active parameters and 35.8% of the total parameters still achieved near-full accuracy.
- First of its kind: It’s, to their knowledge, the first publicly disclosed trillion‑parameter, unified autoregressive model that can both understand and generate across multiple media at production scale.
These results matter because they show you can have one big model that truly handles many media types elegantly, runs faster when needed, and scales to different devices and constraints—all without clunky add-ons or separate training runs.
What this could mean going forward
- Easier multimodal apps: Developers can build more natural tools—like assistants that see, listen, speak, and create visuals—without stitching together separate systems.
- Flexible deployment: Organizations can pick the version that fits their hardware and speed needs, from powerful servers to smaller setups.
- Better learning techniques: The reinforcement learning tricks and elastic training insights can help future models train faster, more fairly, and more stably.
- Deeper cross-modal understanding: Because everything is learned together, the model may continue to get better at tasks that combine text, images, video, and audio—like explaining a video, editing a picture by instruction, or generating a video with a matching soundtrack.
In short, ERNIE 5.0 shows a promising path for building one smart, flexible model that understands and creates across many kinds of media, and can be deployed efficiently in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide follow-up research and reproducibility efforts.
- Data transparency and reproducibility: exact per-modality/token counts, language mix, domain mix, interleaved-sequence proportions, and sampling weights are not reported; no dataset manifests, hashes, or licenses are provided to enable replication.
- Decontamination specifics: the paper does not detail decontamination rules, benchmark lists, overlap thresholds, or audit outcomes per modality; leakage risk for multimodal benchmarks remains unquantified.
- Safety filtering: criteria, model-based filter architectures, thresholds, and estimated false-positive/false-negative rates for unsafe content filtering are not disclosed; cross-modal safety coverage is unclear.
- Compute and environmental footprint: total pre-training tokens, steps, throughput, GPU-hours, hardware types, and estimated energy/carbon costs are not reported.
- Architecture disclosure: core MoE hyperparameters (experts per layer, expert hidden size, capacity factor, top-k ranges per stage, routing network design) and backbone dimensions (layers, d_model, heads, FFN size) are missing, limiting reproducibility and analysis.
- Modality-agnostic routing risks: the extent of cross-modal interference (e.g., rare modalities being overshadowed), modality imbalance, and failure cases for modality-agnostic expert routing are not quantified.
- Expert specialization dynamics: stability of emergent expert specialization over training and post-training (SFT/RL), susceptibility to collapse, and drift across modalities and tasks are not analyzed.
- Load balancing robustness: auxiliary-loss-free load balancing settings, sensitivity, and failure modes (e.g., routing hotspots, tail latency) under trillion-parameter scale and during RL are not reported.
- Long-context multimodal scalability: memory/time scaling, stability, and quality for 32K–128K sequences that include video/audio tokens (not just text) are not evaluated; effectiveness of FlashMask with heterogeneous masks at 128K remains unquantified.
- Uni-RoPE ablations: impact of Unified Spatiotemporal RoPE on text-only tasks, multilingual text, and cross-modal attention compared to standard RoPE/ALiBi is not shown; handling of aspect ratios and non-rectangular frames is unclear.
- NFSP correctness and exposure bias: theoretical justification and empirical assessment of bidirectional attention within a spatial scale versus strict autoregression are missing; error-accumulation behavior and mitigation efficacy are not quantified across lengths/resolutions.
- Visual tokenizer switching: the schedule, criteria, and effects of progressive low-bit to high-bit tokenizer switching on stability and final quality are not specified; recon metrics (PSNR/LPIPS/CLIP-FID/FVD) are not reported.
- Bit-corruption training for vision: corruption rates, schedules, and ablations are missing; trade-offs between robustness and fidelity, especially for fine text/faces, are not assessed.
- Cascaded diffusion refiner: conditioning interface, training protocol (degradation model, datasets), latency/memory overhead, and alignment preservation (semantic/identity/layout) are not quantified; failure modes and user control (e.g., strength) are not discussed.
- Visual understanding–generation trade-offs: concrete measurements of any seesaw effects and how the dual-path hybrid representation affects editing accuracy, OCR, and chart/document reasoning at different token budgets are not provided.
- Audio token rate adequacy: with a 12.5 Hz token rate, the temporal precision sufficiency for prosody, coarticulation, and lip-sync is unclear; ablations with higher token rates and impacts on fidelity and alignment are missing.
- NCP exposure bias: robustness of Next-Codec Prediction to inference-time errors (without teacher forcing) is not analyzed; scheduled sampling or noise injection strategies for audio are not explored.
- Whisper distillation details: alignment loss design, weighting, and effects on non-speech audio, multilingual speech, and code-switching are not reported; potential teacher biases and their downstream impact are unquantified.
- Elastic training schedule: sampling distributions for depth/width/sparsity across training, curriculum design, and their sensitivity are insufficiently specified for reproduction.
- Sub-model selection methodology: no procedure is given to select the best sub-model (depth/width/top-k) for a target compute/memory/latency budget; automated search or calibration criteria are absent.
- Sub-model transfer and safety: how SFT/RL applied to the full model transfers to sub-models (performance drift, safety alignment retention, hallucination rates) is not evaluated; guidance on whether sub-models need post-hoc alignment is missing.
- Elastic sparsity at inference: the reported 15% speedup at reduced top-k lacks a Pareto analysis; modality-specific accuracy impacts, latency variance, and dynamic top-k policies for live constraints are not provided.
- RL verifier system: architecture, coverage (text/vision/audio/video), calibration, bias analyses, inter-rater agreement, and robustness to adversarial prompts are not described; reward hacking and spurious correlations remain unaddressed.
- Replay buffer bias: U-RB design is introduced but incompletely specified in the excerpt; unbiasedness proofs, off-policy correction guarantees, and empirical difficulty-distribution stability across iterations are not shown.
- MoE–RL interaction: effects of RL updates on routing distributions (expert drift, collapse), mitigation strategies (e.g., gating regularizers, freeze policies), and downstream stability are not examined.
- Multilingual and low-resource evaluation: detailed performance by language/script (especially non-Latin), code-mixing, and domain transfer for multimodal tasks is not presented.
- Robustness and security: adversarial robustness, jailbreak resistance, prompt injection in multimodal contexts, and data exfiltration risks are not systematically tested.
- Safety and misuse of generative video/audio: watermarking, provenance, deepfake safeguards, consent policies for voice cloning, and safety RL objectives for generative modalities are not specified.
- Hallucination and calibration: multimodal hallucination rates, confidence estimation, abstention mechanisms, and their dependence on routing sparsity or sub-model size are not evaluated.
- Fairness: modality- and language-conditioned fairness metrics (e.g., demographic bias in perception/synthesis) and mitigations are not provided.
- Deployment metrics: end-to-end latency, memory footprint, and throughput across elastic configurations and hardware classes (A100/H100/consumer GPUs) are not reported; networking overhead from disaggregated tokenizers is unquantified.
- Continual learning: procedures to add experts/modalities or update tokenizers without catastrophic forgetting or routing instability are not described.
- Licensing and release: model, tokenizer, and data release plans, licenses, and usage restrictions are unspecified; reproducibility artifacts (code, configs, checkpoints) are not provided.
- Theoretical grounding: guarantees or analyses for next-group-of-tokens prediction (consistency with maximum likelihood, convergence properties) across heterogeneous modalities are not developed.
- Error analysis: qualitative failure cases (e.g., fast motion video, dense text in images, noisy audio, long code) and targeted mitigations are not reported.
Glossary
- Adaptive hint-based RL: A reinforcement learning technique that provides auxiliary guidance signals when rewards are sparse or tasks are hard. "For difficult tasks with sparse rewards, adaptive hint-based RL is introduced to provide auxiliary guidance when needed."
- Adversarial loss: A training objective derived from GAN discriminators to improve realism or distributional fidelity in generated outputs. "we utilize the adversarial loss~\citep{stylegan} from GAN-based discriminators to improve distributional fidelity."
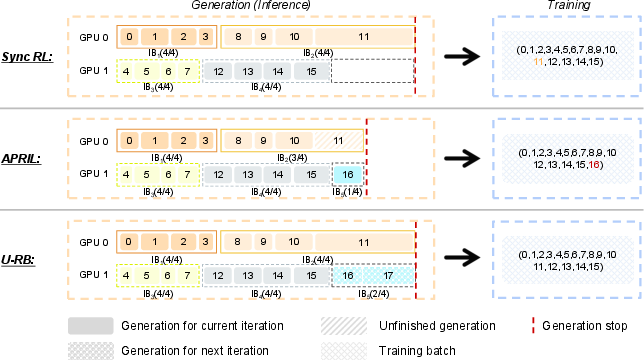
- APRIL: A rollout efficiency method in RL that over-provisions requests and stops generation after collecting a target number of responses. "APRIL stops generation once the target number of responses (16) is reached, which leads to a non-stationary data difficulty distribution."
- Attention-based Patch Merger: A module that fuses CNN and ViT patch features via attention to form compact yet expressive visual tokens for understanding tasks. "This observation motivates the following Attention-based Patch Merger."
- Autoregressive: A modeling paradigm where the model predicts the next token(s) conditioned on previously generated tokens. "a unified autoregressive framework for both multimodal understanding and generation."
- Auxiliary-loss-free load balancing: An MoE routing stabilization method that balances expert utilization without adding explicit auxiliary losses. "The training is further stabalized by an auxiliary-loss-free load balancing~\citep{wang2024auxiliary} , ensuring robust expert utilization at a trillion-parameter scale."
- Bit-wise quantization: A discretization strategy that represents latents as bit-codes, with bit count tied to vocabulary size. "Following the bit-wise quantization strategy, we quantize the unified visual latent representation into a group of bit-codes,"
- BPE dropout: A regularization method for subword tokenization that randomly drops merges to reduce overfitting. "and we use BPE dropout~\citep{provilkov2020bpe} to reduce overfitting to frequent patterns."
- Cascaded diffusion refiner: A post-AR enhancement module trained separately to add high-fidelity details to low-resolution autoregressive outputs. "we adopt a cascaded diffusion refiner on top of the autoregressive backbone."
- Causal attention mask: An attention masking scheme that enforces uni-directional visibility to preserve autoregressive ordering. "a scale-wise causal attention mask is applied,"
- Convolutional Neural Networks (CNNs): Neural networks that extract local perceptual features via convolutional operations, used here for visual representations. "We integrate perceptual features extracted by Convolutional Neural Networks (CNNs) with semantic features encoded by a Vision Transformer (ViT)."
- Cosine learning rate schedule: A training schedule that anneals the learning rate following a cosine curve. "we switch to a cosine learning rate schedule and anneal the learning rate from to ."
- Decontamination: The removal of benchmark or test content from training data to avoid data leakage. "and decontamination safeguards keep benchmarks out of the training data."
- Depth-wise autoregression architecture: An audio modeling approach that predicts hierarchical codec tokens across transformer layers instead of flattening them into one sequence. "we utilize a depth-wise autoregression architecture to model audio tokens for both understanding and generation,"
- Entropy collapse: A failure mode in RL where the policy distribution becomes overly deterministic, harming exploration and stability. "Multi-granularity importance sampling, together with positive sample masking, stabilizes policy optimization and effectively mitigates entropy collapse."
- FlashMask: A method to efficiently handle per-sample heterogeneous attention masks, especially for local bidirectional vision attention. "we employ FlashMask~\citep{flashmask} to efficiently handle per-sample heterogeneous attention masks."
- GAN-based discriminators: Discriminator networks from GANs used to provide adversarial feedback for better distributional quality. "from GAN-based discriminators to improve distributional fidelity."
- Hybrid parallelism: A distributed training strategy combining multiple parallelism forms (e.g., data/model/pipeline) for large-scale models. "we utilize hybrid parallelism with fine-grained memory control to support effective training of a trillion-parameter ultra-sparse MoE model."
- Knowledge distillation: A compression technique where a smaller model learns from a larger teacher model’s outputs or representations. "knowledge distillation~\citep{gu2023minillm, xu2024survey}"
- Late-fusion: A multimodal integration approach where modality-specific components are combined at a later stage rather than jointly trained end-to-end. "late-fusion designs~\citep{qwen3-omni,seedream4}."
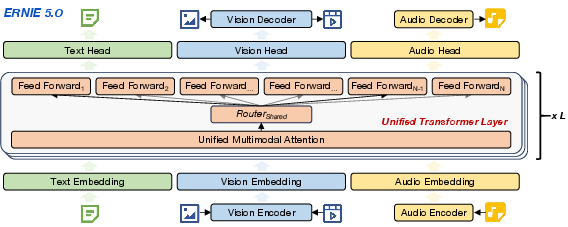
- Mixture-of-Experts (MoE): An architecture with multiple expert subnetworks and a router that selects a sparse subset per token to increase capacity efficiently. "an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing."
- Modality-agnostic expert routing: An MoE routing scheme that conditions on token representations instead of explicit modality labels, allowing cross-modal expert sharing. "At the core of this architecture is modality-agnostic expert routing, where routing decisions are conditioned on unified token representations rather than explicit modality identifiers."
- Modality-specific decoders: Separate generative components tailored to individual modalities, typically attached to a language backbone. "augment pre-trained LLMs with modality-specific decoders or generators, which are connected to the language backbone through late-fusion designs"
- Multi-Token Prediction (MTP): An objective/mechanism that predicts multiple future tokens at once to improve efficiency and output quality. "augmented by the Multi-Token Prediction (MTP) mechanism~\citep{gloeckle2024better, deepseekv3}"
- Multi-granularity importance sampling: An RL stabilization technique that reweights samples across multiple granularities to reduce variance and bias. "Multi-granularity importance sampling, together with positive sample masking, stabilizes policy optimization and effectively mitigates entropy collapse."
- Next-Codec Prediction (NCP): An autoregressive audio generation scheme that predicts hierarchical codec tokens in a coarse-to-fine manner. "and audio generation utilizes Next-Codec Prediction (NCP) to capture temporal and spectral structure."
- Next-Frame-and-Scale Prediction (NFSP): A visual AR paradigm that predicts across spatial scales and temporal frames for image/video generation. "Vision generation employs Next-Frame-and-Scale Prediction (NFSP)~\citep{ji2026videoar},"
- Next-Group-of-Tokens Prediction: A unified objective that predicts groups of tokens across modalities to align their training within a single AR paradigm. "a unified Next-Group-of-Tokens Prediction objective,"
- Next-Token Prediction (NTP): The standard AR objective of predicting the next single token conditioned on previous context. "text generation adheres to the standard Next-Token Prediction (NTP) paradigm,"
- Once-For-All: A training strategy that optimizes a super-network containing many sub-networks (e.g., varying depth/width/sparsity) for flexible deployment. "Once-For-All ~\citep{devvrit2023matformer,cai2024flextron,gu2025elastic}"
- Posterior-based loss weighting: A method to rescale losses across modalities into a comparable range based on estimated posterior statistics. "we introduce a posterior-based loss weighting strategy that rescales the autoregressive losses of different modalities to the same interval,"
- Positive sample masking: An RL training trick that masks certain positive samples to stabilize policy optimization and maintain entropy. "Multi-granularity importance sampling, together with positive sample masking, stabilizes policy optimization"
- Progressive tokenizer switching strategy: A curriculum that starts with low-bit tokenizers and gradually shifts to higher-bit ones to stabilize training. "we adopt a progressive tokenizer switching strategy, starting with a low-bit tokenizer (i.e., small vocabulary) and gradually transitioning to higher-bit variants"
- Residual Vector Quantization (RVQ): A hierarchical quantization method where successive codebooks encode residual errors for finer detail. "The audio quantization module follows a Residual Vector Quantization (RVQ) design,"
- RoPE (Rotary Positional Embedding): A positional encoding technique that rotates query/key vectors to encode relative positions, here scaled for long contexts. "the RoPE base is set to 1{,}000{,}000 starting from the 8K stage."
- Routing top-k: The number of experts selected per token by the MoE router; lowering it reduces compute at potential accuracy cost. "Reducing routing top- to 25\% during inference yields over 15\% decoding speedup with only minor accuracy loss,"
- Semantic regularization loss: A training signal derived from external vision models to preserve high-level semantics in learned tokens. "we incorporate a semantic branch and apply a semantic regularization loss derived from large-scale vision foundation models to preserve high-level semantic consistency."
- Speaker embedding: A vector representing speaker identity/timbre used to control voice characteristics during speech synthesis. "For speech synthesis, a speaker embedding is inserted as part of the conditioning context to enable controllable voice timbre,"
- Supervised fine-tuning (SFT): A post-training stage where the model is trained on curated instruction-response pairs to align with desired behaviors. "which includes two stages, supervised fine-tuning (SFT) and unified multimodal reinforcement learning (UM-RL)."
- Teacher forcing: A training technique where ground-truth outputs are fed back as inputs for the next prediction step. "During training, teacher forcing is applied,"
- Unified multimodal reinforcement learning (UMRL): An RL framework and pipeline that trains reasoning/agent/instruction-following tasks jointly across modalities. "combines supervised fine-tuning (SFT) with unified multimodal reinforcement learning (UMRL)."
- Unified Spatiotemporal Rotary Positional Embedding (Uni-RoPE): A RoPE variant that encodes unified temporal and spatial positions for heterogeneous tokens. "we introduce a Unified Spatiotemporal Rotary Positional Embedding (Uni-RoPE) and apply it to all tokens in ERNIE 5.0."
- Unbiased Replay Buffer (U-RB): A rollout-generation system that preserves query order to avoid bias toward short/easy samples while improving throughput. "Visualization of the Unbiased Replay Buffer (U-RB) in ERNIE 5.0, in comparison with existing methods,"
- UTF-16BE: A text encoding format (big-endian UTF-16) used here for stable byte-level fallback and compact multilingual representation. "Specifically, we encode text in UTF-16BE to provide stable byte-level fallback and a more compact representation for many non-Latin symbols,"
- Vision Transformer (ViT): A transformer-based architecture for vision that processes images as sequences of patches. "encoded by a Vision Transformer (ViT)."
- Warmup-Stable-Decay (WSD) learning rate schedule: A schedule that warms up, holds steady, then decays the learning rate to stabilize early training. "We adopt a Warmup-Stable-Decay (WSD) learning rate schedule~\citep{hu2024minicpm} in this stage."
- Whisper model: A pretrained speech model used as a teacher to distill semantic information into the first audio token. "we distill knowledge from a pretrained Whisper model~\citep{radford2023robust}."
- Windowed temporal attention: An attention scheme that restricts temporal context to a window to improve efficiency and robustness in video generation. "we further introduce windowed temporal attention and random historical frame masking"
Practical Applications
Immediate Applications
Below are actionable, near-term use cases that can be deployed with current infrastructure and standard productization patterns, leveraging the paper’s unified multimodal autoregressive model, ultra-sparse MoE with modality-agnostic routing, elastic training, and post-training RL techniques.
- Bolded items are the core use cases; each includes sectors, suggested tools/products/workflows, and key assumptions/dependencies.
- You can combine multiple items (e.g., elastic MoE and routing top‑k controls) in a single deployment for better cost/performance control.
- Many “Immediate” items assume API or on‑prem access to ERNIE 5.0 or comparable unified multimodal models.
- Bold Cost- and latency-tunable multimodal inference (elastic training + MoE top‑k) (software, cloud, enterprise IT)
- What: Serve one model family with adjustable depth/width/sparsity and per-request routing top‑k to meet SLAs and budgets while minimizing accuracy loss.
- Tools/workflows/products: “Elastic Serving Controller” that auto-selects sub-models based on device/hardware budget; a policy that lowers top‑k under latency pressure; A/B latency–accuracy tuner; autoscaler that turns experts on/off based on load.
- Assumptions/dependencies: Access to the elastic super-network weights and sub-model export; inference runtime supporting MoE parallelism; monitoring for quality regressions when reducing top‑k.
- Bold Unified multimodal assistants for customer support (text+image+audio) (customer service, e‑commerce, telecom)
- What: Agents that handle chats with photos/screenshots and voice notes; respond with text or synthesized speech; request additional images or screen recordings when needed.
- Tools/workflows/products: Contact-center AI integrating image/video intake, audio NCP-based TTS; routing top‑k lowered for peak loads; guardrails via unified verifier for safety.
- Assumptions/dependencies: Clear data governance for user uploads; domain SFT; guardrail tooling; latency budget for speech I/O.
- Bold Document, chart, and UI understanding automation (dual-path visual representation) (finance, insurance, logistics, gov/RegTech)
- What: High-accuracy extraction and reasoning over PDFs, charts, forms, invoices, and app screenshots.
- Tools/workflows/products: “Doc AI Pipeline” using the Attention-Based Patch Merger; OCR+layout+reasoning chain; validation via verifier-based quality checks.
- Assumptions/dependencies: Access to the dual-path understanding module or model variant; private fine-tuning on org-specific templates; regulatory compliance for PII.
- Bold Multimodal RAG: ingest and answer from mixed corpora (text, images, videos, audio) (enterprise knowledge management, education)
- What: Build retrieval over training videos, product images, manuals, and call recordings; answer with text or speech; optionally return annotated frames.
- Tools/workflows/products: Multimodal indexers (frame/audio chunk embeddings), unified token streaming to the backbone; sub-model choice by context length and cost.
- Assumptions/dependencies: Legal rights to index media; scalable embedding store; data de-duplication and safety filters.
- Bold Image/video editing and generation with semantic fidelity (NFSP + diffusion refiner) (media, advertising, design, e‑commerce)
- What: Coherent AR-based generation from prompts/storyboards with a diffusion refiner for high-res detail; supports pixel-level edits and temporal consistency.
- Tools/workflows/products: “Multimodal Content Studio” with AR backbone → diffusion cascade; storyboard-to-video workflows; batch refiner for high-res upscaling.
- Assumptions/dependencies: Refiner training with paired low-/high-res data; licensing on generated content; compute for diffusion stages.
- Bold Voice experiences and dubbing (NCP) (media localization, education, CX)
- What: Speech generation and dubbing that preserves semantics and controllable timbre via speaker embedding; voice chatbots with faster coarse-to-fine synthesis.
- Tools/workflows/products: NCP-based TTS/dubbing SDK; voice cloning controls; latency-aware top‑k routing for real-time interaction.
- Assumptions/dependencies: Consent and legal compliance for voice cloning; speaker embedding capture; robust mic/noise pipeline.
- Bold Accessibility copilots (daily life, public sector, edtech)
- What: Describe images/videos and charts to audio; live captioning and explanations for multimedia; smart reading of complex documents.
- Tools/workflows/products: Mobile/desktop app integrating visual understanding pipeline and NCP-based TTS; adjustable sub-model for on-device versus cloud.
- Assumptions/dependencies: Model availability on-device or via low-latency API; safety re: sensitive content; localization/multilingual support.
- Bold Cross-modal content moderation and review (policy/gov, platforms, enterprise compliance)
- What: Unified detection and triage of unsafe content in text, images, videos, and audio using a single backbone and unified verifier for reward signals.
- Tools/workflows/products: Moderation console; continuous learning with verifier-guided SFT/RL; elastic deployment for bursty loads.
- Assumptions/dependencies: Clear policy taxonomies; human-in-the-loop review; bias and false-positive audits.
- Bold Training pipeline acceleration with U‑RB (RL infrastructure, labs, foundation model teams)
- What: Increase RL rollout throughput without biasing difficulty, reducing cost/instability in large-scale post-training.
- Tools/workflows/products: Integrate Unbiased Replay Buffer (U‑RB) into RL ops stack; multi-granularity importance sampling; positive sample masking.
- Assumptions/dependencies: Access to training code; compatibility with sparse MoE; proper logging/telemetry.
- Bold Academic benchmarking across budgets (ML research, ed)
- What: Use one pre-trained elastic model family to study scaling, routing sparsity, and long-context trade-offs without retraining multiple sizes.
- Tools/workflows/products: “Once‑for‑All” sub-model zoo; scripts to sweep depth/width/sparsity; routing visualizations for modality-agnostic experts.
- Assumptions/dependencies: Research access to weights or API with controllable configs; compute for evaluations.
Long-Term Applications
The following applications are promising but may require further research, domain fine-tuning, safety alignment, data partnerships, scaling, or ecosystem maturation.
- Bolded items identify the core future-facing opportunity; each lists sectors, potential tools/workflows/products, and dependencies.
- Bold Multimodal robotic assistants with unified perception and language (robotics, manufacturing, home/IoT)
- What: End-to-end policies that fuse camera/audio with instruction-following and planning; teach from video demonstrations and language-guided tasks.
- Tools/workflows/products: Policy fine-tuning on robot datasets; video NFsP for long-horizon perception; speech guidance via NCP.
- Assumptions/dependencies: Large, high-quality embodied datasets; safety verification; on-device inference or low-latency edge; sim-to-real transfer.
- Bold Clinical admin and documentation copilots (healthcare)
- What: Multimodal assistants for intake forms, imaging-linked narratives, and dictated notes; summarize consultations and attach annotated frames/audio.
- Tools/workflows/products: HIPAA-compliant pipelines; domain SFT with audit trails; verifier-based safety filters for medical claims.
- Assumptions/dependencies: Regulatory approval; strict PHI handling; domain adaptation; clinicians-in-the-loop; risk management for generative outputs.
- Bold Long-form video generation and editing (media, entertainment, education)
- What: High-fidelity, minutes-long controllable video with scene text fidelity and consistent faces; script-to-video learning objects for courses.
- Tools/workflows/products: Hierarchical NFSP schedules, advanced error-correction, stronger diffusion cascades; asset libraries and rights management.
- Assumptions/dependencies: More robust long-horizon stability and compute; rights/ethical use; scalable storage and rendering.
- Bold Speech-to-speech translation preserving prosody and identity (global platforms, media localization)
- What: Direct speech-in → speech-out with preserved speaker timbre and emotion using NCP hierarchy.
- Tools/workflows/products: Multilingual codec training; privacy-preserving speaker embeddings; latency-optimized pipelines.
- Assumptions/dependencies: Large parallel speech corpora; consent and voice IP rules; accent and language coverage.
- Bold On-device multimodal models for edge and mobile (consumer devices, automotive, AR/VR)
- What: Deploy selected sub-models with reduced width/depth and lower top‑k experts for offline assistants, dashcams, or AR glasses.
- Tools/workflows/products: Model slicing/export tools; MoE-aware compilers and schedulers; mixed-precision kernels; caching strategies for experts.
- Assumptions/dependencies: Efficient MoE runtimes on mobile/edge accelerators; thermal/power constraints; privacy and local storage limits.
- Bold Multimodal educational tutors and simulators (edtech)
- What: Interactive lessons that adaptively generate/assess text, images, videos, and audio; explain charts and lab videos; simulate experiments.
- Tools/workflows/products: Curriculum-aligned generators; feedback with unified verifiers; parent/teacher dashboards.
- Assumptions/dependencies: Content safety; curriculum licensing; bias and fairness evaluation; compute for rich media generation.
- Bold Enterprise digital twins with multimodal I/O (industry 4.0, energy, smart cities)
- What: Unified agents that read schematics, interpret sensor audio/video, and generate visual maintenance instructions and alerts.
- Tools/workflows/products: Multimodal RAG over CAD, logs, and footage; procedural generation of video/manuals; human oversight workflows.
- Assumptions/dependencies: Secure integration with OT systems; domain SFT; reliability requirements for safety-critical contexts.
- Bold Government e‑services assistants across modalities (public sector)
- What: Citizens submit photos, videos, voice notes; assistant provides compliant guidance and forms; accessibility-first experiences.
- Tools/workflows/products: Policy-tuned models; multilingual pipelines; automated auditing and redaction.
- Assumptions/dependencies: Procurement and standards; governance for bias and transparency; data residency.
- Bold Open standards for multimodal tokens and routing (ecosystem/standards)
- What: Interoperable tokenizers and routing interfaces so models/tools can share multimodal token streams and expert pools.
- Tools/workflows/products: Reference token APIs; evaluation suites; router-adapter specs.
- Assumptions/dependencies: Community and vendor buy-in; IP around tokenizers; security considerations.
- Bold Training once for portfolio delivery (cloud/AI vendors)
- What: “Train once, ship many sizes” as a platform capability—elastic super-network pre-training, then slice to SKUs by depth/width/sparsity.
- Tools/workflows/products: Sub-model catalog; SLA-based selection; billing aligned to activation rates.
- Assumptions/dependencies: Robust elastic training pipelines; legal clarity on model derivatives; customer education on trade-offs.
Notes on Assumptions and Dependencies
- Model access and licensing: The paper presents a production-scale system; deploying these applications typically requires API access or licensed weights for ERNIE 5.0 (or a comparable unified multimodal model).
- Hardware/runtime: MoE inference requires expert-parallel runtimes and kernels; FlashMask/FlashAttention-like capabilities improve efficiency; diffusion refiners add compute.
- Data and safety: Regulated sectors require domain SFT, guardrails, and auditability; use de-duplication, decontamination, and safety filters; multilingual performance hinges on tokenizer design and data coverage.
- Quality–latency trade-offs: Reducing routing top‑k and sub-model size yields speedups with minor accuracy loss; each deployment should validate task-specific impacts.
- Tokenizers/refiners: Visual 2D/3D tokenizers, audio codec tokenizers, and diffusion refiners must be available or replicated; training refiners needs paired low/high-res data.
- Privacy/compliance: Voice cloning, document processing, and surveillance-like scenarios require consent, IP checks, and adherence to local regulations.
- Long-horizon stability: While corruption-based training and NFSP/NCP mitigate error accumulation, ultra-long video/audio generation remains a research area; product roadmaps should stage complexity accordingly.
Collections
Sign up for free to add this paper to one or more collections.