Decomposing Query-Key Feature Interactions Using Contrastive Covariances
Abstract: Despite the central role of attention heads in Transformers, we lack tools to understand why a model attends to a particular token. To address this, we study the query-key (QK) space -- the bilinear joint embedding space between queries and keys. We present a contrastive covariance method to decompose the QK space into low-rank, human-interpretable components. It is when features in keys and queries align in these low-rank subspaces that high attention scores are produced. We first study our method both analytically and empirically in a simplified setting. We then apply our method to LLMs to identify human-interpretable QK subspaces for categorical semantic features and binding features. Finally, we demonstrate how attention scores can be attributed to our identified features.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What This Paper Is About
This paper asks a simple question about Transformer models (like the ones behind chatbots): when an attention head focuses on a word, why did it choose that word? The authors introduce a new way to “peek inside” the attention mechanism by studying how the “query” (what the model is looking for) and the “key” (what each token offers) interact. They propose a method called contrastive covariance to break these interactions into small, understandable pieces. This helps explain which features make the attention score high.
The Main Questions
The paper focuses on these easy-to-understand goals:
- How can we see which features in the query and key are responsible for high attention?
- Can we split the complex interaction between queries and keys into simple parts (like directions) that humans can interpret?
- Does this method work both in toy examples and in real LLMs?
- Can we measure how much each feature contributes to the final attention score?
How The Method Works (In Simple Terms)
Think of attention like matching labels:
- Each token has a “key” vector (its label).
- The current position has a “query” vector (the label the model is looking for).
- If the query and key match in the right way, the attention score is high.
The authors look at the “QK space,” which is just the space of all ways queries and keys can interact. Here’s the idea behind contrastive covariance:
- Covariance is a way to measure how two things change together. Here it’s used to see how query and key features line up.
- They build two situations: 1) Positive case: the query and key share a feature (they “match” on that feature). 2) Negative case: the query and key do not share that feature (they “don’t match” on that feature).
- Then they subtract the negative from the positive. This difference isolates the part of the interaction that’s really about that single feature.
Imagine sorting socks:
- Positive: socks where color matches.
- Negative: socks where color doesn’t match.
- The difference points to “color” as the feature that explains the sorting.
Finally, they use a math tool called SVD (singular value decomposition) to break the difference into:
- A small number of directions (think of them as “feature axes”).
- One set of directions lives in query space; another lives in key space.
- The number of directions needed is the “rank” of the feature (how many dimensions you need to describe it).
What They Did and Found
1) Toy Model Experiments
They built a simple controlled task:
- There are several “payload” tokens (like items with hidden tags).
- There’s a “selector” token (the query) that should attend to the correct payload based on shared hidden features, then output the payload’s label.
- They tested two kinds of hidden features:
- Discrete features: binary sign vectors (like switches set to +1 or −1).
- Continuous features: random Gaussian vectors (like points in a cloud).
What they found:
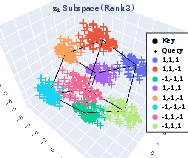
- Their method correctly recovered how many dimensions a feature needed (its rank) and where that feature lived in query and key spaces.
- When the attention head had enough capacity (enough dimensions), features were cleanly separated.
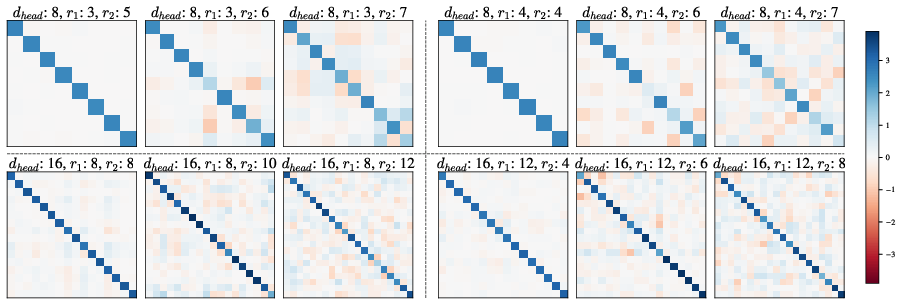
- When there wasn’t enough capacity, features overlapped and got compressed together. This is called superposition: multiple features sharing the same “slots.”
- They could do “causal interventions”: by editing only the part of a key vector corresponding to a feature, they could move the attention from one token to another. This shows the recovered subspaces are actually the ones the model uses.
Two interesting behaviors showed up:
- Feature splits: the model sometimes broke a multi-part feature into independent sub-parts (like splitting “color” into separate axes for red/green/blue).
- Superposition: when space is tight, features blend and interact off-axis, making interpretation harder.
2) Real LLMs
They tried their method on Llama 3.1-8B Instruct and Qwen 3-4B Instruct and focused on two kinds of heads:
A) Filter Heads (Category Detection)
These heads act like filters: given a list of mixed items and a category (like “fruit”), they attend to tokens from that category.
- Using contrastive covariance, they found low-rank (often rank 1 per category) directions that encode categories like fruits, animals, vehicles, drinks, countries, etc.
- When they projected queries and keys onto the “category space” and visualized them (with PCA), tokens clustered neatly by category, and queries aligned with their matching keys.
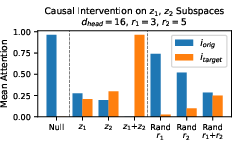
- Causal interventions: by swapping the category component of one token with another (say, “fruit” to “animal”), they could shift attention toward the new category more than random edits—though not always completely, suggesting there are extra features beyond category.
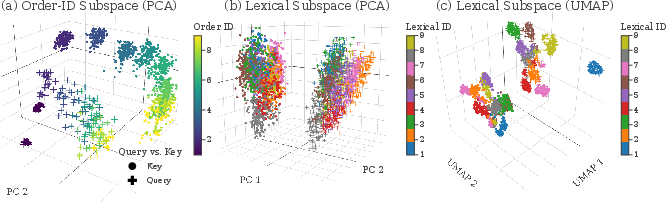
B) Binding Features (Linking an entity to a box)
Example: “The hat is in box O. The jam is in box Z … Which box is the jam in?”
Prior work shows two mechanisms:
- Order-ID: match by the position (the second pair goes with the second query).
- Lexical: match by the actual identity (“jam” goes to the box paired with “jam”).
Using their method:
- They isolated “order-ID” and “lexical” subspaces in QK space.
- Order-ID was usually low rank (like 2–3); lexical was higher rank (around 9–10).
- Visualizations showed clear clusters and alignment between queries and keys in these subspaces.
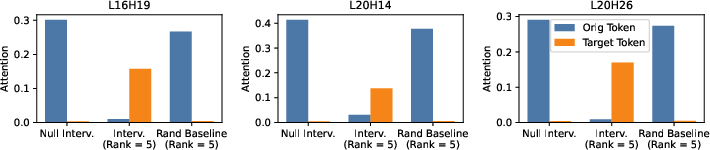
- Causal interventions: editing the order-ID or lexical parts shifted attention toward different boxes, and editing both shifted attention the most. Random edits didn’t do much.
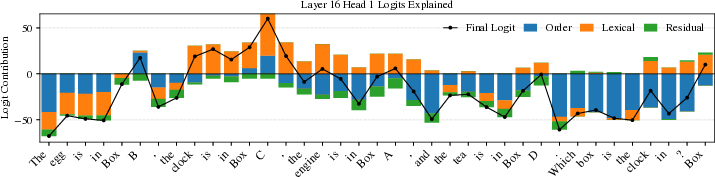
3) Explaining Attention Scores (Logit Attribution)
Attention scores come from logits (numbers before softmax). Because logits depend linearly on the query vector, you can split the query into:
- The part explained by a feature (e.g., order-ID).
- The part explained by another feature (e.g., lexical).
- The leftover part (unexplained residual).
Then you can measure how much each piece contributes to each token’s logit. This gives a clear breakdown of “what feature drove attention here.” They show examples where lexical contributes more than order-ID, and also highlight mistakes the head makes that may be hidden after softmax.
Why This Matters
- It gives a clearer answer to “why did the model attend to this token?” by pinpointing the exact features and their directions in query and key spaces.
- It works without training extra models or relying on pre-learned feature dictionaries. You just define positive/negative matching pairs and compute.
- It helps identify multi-dimensional and overlapping features, and shows where attention is driven by category, order, or lexical identity.
- It provides a way to attribute attention scores to specific features, which can reveal hidden errors or biases and guide debugging.
Big Picture Impact
- Better interpretability: Understanding attention’s inner structure can make models more trustworthy and easier to improve.
- Safer systems: If we can see which features drive attention decisions, we can detect and reduce harmful or biased behavior.
- Research directions: The authors note challenges like superposition and “what counts as a feature,” and suggest exploring unsupervised ways to discover features without predefining them. They also point to multi-dimensional features as a rich area for future work.
In short, this paper offers a simple, powerful toolkit for breaking down attention into human-understandable parts, showing where features live in queries and keys, and how much they matter for the model’s choices.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on them:
- Generalization across models and settings: The method is evaluated on Llama 3.1-8B Instruct and Qwen 3-4B Instruct, on a small set of heads and tasks (filter heads and binding). It is unclear how well the approach generalizes across:
- Model sizes, families, architectures (e.g., different attention implementations, rotary vs. absolute positions, mixture-of-experts).
- Layers and heads (systematic head-level coverage, early vs. late layers, encoder-only vs. decoder-only models).
- Tokenization schemes, languages (multilingual), domains (code, math), and input regimes (long contexts).
- Reliance on human-defined “feature” contrasts: The contrastive covariance requires predefined positive/negative conditions (e.g., categories, order-ID, lexical). The method’s dependence on prior knowledge limits discovery of unknown features; unsupervised or semi-supervised alternatives are not provided or benchmarked.
- Identifiability conditions in real LMs: Beyond the toy model derivation, the paper does not state formal conditions under which the contrastive covariance isolates a feature subspace in real models (e.g., assumptions on independence, confounding, or linear separability in Q/K space). Clear identifiability criteria and failure modes are missing.
- Handling correlated or entangled features: The toy setting holds other latent variables fixed when constructing positive/negative pairs. In natural data, features (e.g., semantics, syntax, frequency, position) often co-vary. There is no method to disentangle correlated features or to control confounding in Delta C estimation.
- Superposition in real LMs: The paper raises but does not resolve how often superposition occurs in practice, how to detect it reliably in large models, and how to interpret and separate superposed components in QK space (e.g., quantifying off-diagonal interactions in G, developing de-superposition procedures).
- Feature splits and the “unit of feature”: The observation that models split features into finer independent components (feature splits) lacks a principled characterization. It remains open how to systematically identify the granularity of “units” the model uses and to reconcile human feature definitions with model-native decompositions.
- Rank estimation robustness: Ranks are estimated via a 99% Frobenius norm threshold on singular values. The paper does not analyze sensitivity to this threshold, provide statistical confidence intervals, or compare alternative criteria (e.g., information criteria, permutation tests, bootstrapping).
- Sample complexity and estimator stability: No analysis of how many samples are required to estimate ΔC reliably (variance, bias), nor guidance on convergence diagnostics, robustness to noise, and performance under limited data.
- Query-only logit attribution limitations: Logit attribution is done by projecting the query vector into feature subspaces; contributions carried primarily on the key side are not separately attributed. A bi-linear attribution that decomposes both
qandkcontributions is not explored, and overlap/ordering sensitivity between subspaces is acknowledged but not resolved. - Softmax and nonlinearity effects: The link between softmax “winner-takes-all” behavior and superposition is hypothesized but not quantified. There is no study of how temperature scaling, logit magnitude, or normalization affects feature decomposition and causal interventions.
- Value/output path interactions: The method focuses on Q/K; it does not investigate how V and O paths (W_V, W_O) interact with identified QK subspaces, nor whether features are redundantly or differently represented in value streams.
- Causal intervention validity: Interventions replace coordinates in recovered subspaces and measure attention shifts, but do not systematically assess whether these interventions preserve distributional realism or induce artifacts. End-to-end task effects (e.g., final token prediction accuracy) are not reported.
- Partial attention shift indicates missing features: Interventions on categorical and binding subspaces often fail to move all attention, indicating additional, unaccounted features. The paper does not attempt to identify these residual components or quantify their nature (e.g., positional, frequency, recency, syntactic cues).
- Negative pair construction risks: For lexical binding, counterfactual prompts may alter the broader distribution (e.g., entity co-occurrence, surface form frequency). The method lacks checks that ΔC isolates only lexical identity signals and not unintended confounds.
- Quantitative alignment metrics: Alignments between keys and queries are shown via PCA/UMAP visualizations but lack quantitative measures (e.g., canonical correlation analysis, subspace alignment angles, cluster quality metrics, separability scores) to support claims of alignment and semantic clustering.
- Head selection bias: Heads are selected by simple attention ratios (filter heads) or minimum accuracy thresholds (binding). A systematic head discovery procedure (e.g., comprehensive scan, reproducible selection criteria, multiple metrics) and analysis of false positives/negatives are missing.
- Layerwise and circuit-level analysis: The method is applied at the single-head level. There is no study of how identified QK subspaces propagate across layers, interact with other heads, or participate in larger circuits (e.g., whether downstream components causally depend on the same subspaces).
- Sensitivity to prompt phrasing, context length, and noise: Robustness to changes in prompt wording, number and diversity of items/entities, and noisy/ambiguous inputs is not assessed. The method may be brittle to distribution shifts.
- Cross-task coverage: The paper focuses on categories and binding. It remains unknown whether the approach reveals interpretable QK subspaces for other phenomena (e.g., coreference, syntax, morphology, arithmetic, long-range dependencies, tool-use/context retrieval).
- Multilingual and cross-domain evaluation: No exploration of whether similar low-rank QK subspaces exist for categories/binding across languages, scripts, or domains (e.g., code, math, biomedical text).
- Multiple-component behaviors: When multiple subspaces produce indistinguishable behaviors (e.g., attending to the same token), the paper notes interpretability challenges but does not propose criteria to distinguish, label, or prioritize components.
- Estimator choices (mean-centering, covariance vs. cross-covariance): ΔC is computed without mean-centering; implications for bias due to non-zero means or heteroscedasticity are not analyzed. Alternative estimators (e.g., centered covariances, partial correlations) are not compared.
- Numerical scalability: Practical costs of computing ΔC and SVD across many heads/layers for very large models are not reported. Guidance on batching, sub-sampling, or randomized SVD methods is absent.
- Identifying multi-dimensional features automatically: Although highlighted in the discussion, the paper does not offer an algorithm to discover multi-dimensional feature subspaces of varying ranks in an unsupervised manner, nor benchmarks to evaluate such discovery.
- Benchmarking against alternative approaches: The claimed advantage over feature-dependent methods (e.g., SAEs, probes) is not empirically demonstrated via comparative studies (precision/recall of feature recovery, causal validity, sample efficiency, robustness).
- Formalizing error decomposition in logit attribution: The residual logit component is shown qualitatively; there is no quantitative decomposition (e.g., proportion explained, confidence bounds, overlap between feature subspaces) or analysis of attribution stability across samples.
- Conditions for feature overlap and projection ordering: The method acknowledges sensitivity to projection order when subspaces overlap. No procedures are offered to measure overlap, orthogonalize subspaces, or ensure order-invariant attributions (e.g., oblique projectors, joint subspace models).
- Public datasets and reproducibility: Details sufficient for exact replication (e.g., prompt templates, item lists, entity sets, sampling seeds) and code for ΔC construction/intervention procedures are not provided, limiting reproducibility and external validation.
Practical Applications
Immediate Applications
Below are practical uses that can be deployed now, leveraging the paper’s contrastive covariance method, low-rank QK subspace recovery, causal interventions, and attention logit attribution.
- Attention-head labeling and diagnostics for LLMs (software/AI)
- Use case: Systematically identify what specific features (e.g., categories, binding mechanisms) individual attention heads encode and how they drive attention.
- Tools/workflows: “QK Decomposer” library to build positive/negative covariance datasets; SVD-based rank estimation; head-level reports; CI checks for regressions.
- Assumptions/dependencies: Access to model internals (queries/keys); ability to generate or curate contrastive datasets; existence of low-rank feature subspaces.
- Explainability overlays via attention logit attribution (finance, healthcare, legal, enterprise software)
- Use case: Provide per-token, feature-level explanations showing how much each recovered feature (e.g., lexical vs. order-ID) contributed to attention logits in decision-critical applications.
- Tools/workflows: Integrate the query-space projection and attribution into inference pipelines; UI dashboards that overlay “reason bars” next to tokens or retrieved items.
- Assumptions/dependencies: Defined feature sets and contrastive conditions; users accept attention-based attributions as informative (not causal for full model behavior).
- Debugging spurious bindings in structured extraction and question answering (education, enterprise data, content moderation)
- Use case: Detect and reduce reliance on brittle mechanisms (e.g., order-ID) when the task requires lexical binding; triage heads that misroute attention.
- Tools/workflows: Counterfactual prompt harnesses (swap entity labels while keeping structure); subspace interventions to quantify attention shifts.
- Assumptions/dependencies: Ability to gather paired prompts; heads actually encode separable binding features; intervention does not degrade downstream utility.
- RAG and retrieval tuning through subspace interventions (enterprise software, knowledge management)
- Use case: Steer attention to the correct items by editing keys in identified category subspaces; diagnose why retrieval fails and correct it without retraining.
- Tools/workflows: Key projection/edit operators (orthogonal projectors on recovered V-bases); automated tests that measure attention shifts to targeted items.
- Assumptions/dependencies: Access to intermediate activations in deployed models; careful handling to avoid distribution shifts; limited by softmax dynamics and superposition.
- Trust & Safety red-teaming with categorical QK subspaces (policy, platform safety)
- Use case: Audit whether specific categories (e.g., protected attributes) are explicitly encoded and drive attention; stress-test prompts to assess risks of discriminatory focus.
- Tools/workflows: Category inventories; contrastive covariance across protected vs. non-protected tokens; attention shift quantification; safety reports.
- Assumptions/dependencies: Clear category definitions; appropriate legal/ethical review; attention-level signals may not capture all downstream harms.
- MLOps monitoring of feature ranks and subspaces (software/AI operations)
- Use case: Track changes in QK feature ranks/subspaces over model versions to catch interpretability regressions (e.g., growing superposition or feature drift).
- Tools/workflows: Automated SVD rank metrics per head; comparison dashboards; alerts on rank inflation or subspace overlap.
- Assumptions/dependencies: Stable prompt suites for measurement; storage of head-level diagnostics; acceptance of rank thresholds (e.g., 99% Frobenius norm).
- Bias and fairness probing at attention level (HR tech, finance, public-sector NLP)
- Use case: Measure whether sensitive categories disproportionately influence attention logits; use subspace attribution to inform fairness analyses and mitigation.
- Tools/workflows: Feature attribution over sensitive-vs-neutral items; aggregate statistics across datasets; documentation for internal audits.
- Assumptions/dependencies: Sensitive attribute labeling; attention is only one component of behavior; requires complementary outcome-level analyses.
- Curriculum/data curation for feature coverage (academia, model training)
- Use case: Design prompts and datasets that expose and strengthen desired feature mechanisms (e.g., lexical binding), reducing reliance on spurious ones.
- Tools/workflows: Contrastive prompt generators; rank targets per mechanism; training evaluation with attention attribution.
- Assumptions/dependencies: Access to training/validation loops; willingness to optimize for interpretability signals alongside accuracy.
Long-Term Applications
The following require further research, scaling, or development to become robust and broadly deployable.
- Training-time regularization to shape QK subspaces (software/AI research)
- Use case: Add losses that penalize superposition or enforce orthogonality between desired features, improving interpretability and robustness.
- Tools/products: “Subspace-regularized attention” modules; constraints on WQ/WK; curriculum that enforces distinct feature ranks.
- Assumptions/dependencies: Empirical validation that regularization improves utility; careful trade-offs with model capacity and performance.
- Unsupervised QK decomposition (academia, AI tooling)
- Use case: Discover multi-dimensional attention features without predefined labels; cluster or factorize QK interactions to reveal latent mechanisms.
- Tools/products: Unsupervised contrastive frameworks; matrix/tensor factorization; sparse methods; evaluation protocols for interpretability.
- Assumptions/dependencies: Advances in unsupervised interpretability; robust identification of overlapping subspaces; meaningful mapping from discovered features to behavior.
- Feature-level guardrails and safety controls (policy, platform safety)
- Use case: Proactively attenuate or block attention flowing through unsafe subspaces (e.g., sensitive categories) at inference time.
- Tools/products: Runtime subspace filters; policy-configurable feature blocks; compliance logs demonstrating guardrail activation.
- Assumptions/dependencies: High confidence in feature maps; minimal utility loss; formal safety standards for feature-level interventions.
- Subspace-aware modular routing in model architectures (software, robotics)
- Use case: Route tokens to specialized modules based on detected QK feature components (e.g., lexical binding vs. spatial reasoning), improving efficiency and reliability.
- Tools/products: Attention routers keyed on U/V bases; hybrid modular-transformer architectures; dynamic computational budgets.
- Assumptions/dependencies: Stable feature detection; low latency overhead; evidence that routing improves performance on real tasks.
- Certification and transparency standards for model internals (policy, compliance)
- Use case: Regulators or customers require feature-level disclosures (e.g., QK feature maps and ranks for critical heads) as part of transparency reports.
- Tools/products: Standardized interpretability audits; third-party verification; model “feature cards.”
- Assumptions/dependencies: Regulatory frameworks evolve to accept and incentivize such disclosures; standardized metrics across vendors.
- Distillation and model transfer that preserve QK features (software/AI)
- Use case: When compressing or fine-tuning models, ensure target models retain the same interpretable QK subspaces for safety-critical circuits.
- Tools/products: Feature-preserving distillation losses; evaluation harnesses comparing subspace alignment across student/teacher.
- Assumptions/dependencies: Reliable measurement of subspace similarity; compatibility across architectures.
- Personalized attention profiles (daily life, enterprise UX)
- Use case: Allow users to prioritize certain attention features (e.g., domain categories) for tailored responses and filtering in assistants and productivity tools.
- Tools/products: User-configurable subspace weighting; profile-based attention steering; explainable personalization.
- Assumptions/dependencies: Safe exposure of controls; non-deceptive explanations; ensuring personalization does not amplify bias.
- Multi-modal extensions (healthcare imaging, autonomous vehicles, AR/VR)
- Use case: Apply QK decomposition to vision/audio transformers to isolate positional, entity, or binding features across modalities for explainability and safety.
- Tools/products: Cross-modal QK analyzers; subspace interventions for sensor fusion; safety-certified feature maps.
- Assumptions/dependencies: Adaptation to larger heads/channels; real-time constraints; domain-specific validation.
- Interpretability benchmarks and consortium-led standards (academia, industry)
- Use case: Establish tasks and datasets that stress-test multi-dimensional features and superposition; compare QK methods to autoencoders/probes.
- Tools/products: Public benchmark suites; metrics for subspace rank/overlap; leaderboards and best practices.
- Assumptions/dependencies: Community coordination; robust ground-truthing of features; sustained funding and adoption.
Glossary
- attention heads: Transformer components that compute attention by producing queries, keys, and values per token. "Despite the central role of attention heads in Transformers, we lack tools to understand why a model attends to a particular token."
- attention logits: The pre-softmax attention scores for each key relative to a query. "Finally, we show how attention logits (attention scores prior to softmax) can be attributed to the QK features that we identify."
- bilinear interactions G: The matrix capturing pairwise interactions between latent query and key features in QK space. "we study how our latent variables interact with each other in QK space by analyzing their bilinear interactions :"
- bilinear joint embedding space: A space defined by bilinear forms of queries and keys capturing their interactions. "we study the query-key (QK) space -- the bilinear joint embedding space between queries and keys."
- binding features: Mechanisms that bind related entities (e.g., an object and its associated label) across positions. "identify human-interpretable QK subspaces for categorical semantic features and binding features."
- causal interventions: Controlled manipulations of representations to test causal effects on model behavior. "To validate the role of the recovered subspaces, we perform causal interventions."
- contrastive covariance: The difference between covariances computed under matched vs. mismatched conditions to isolate a feature. "We present a contrastive covariance method to decompose the QK space into low-rank, human-interpretable components."
- contrastive covariance matrix: The matrix ΔC formed by subtracting negative from positive query-key covariances conditioned on a feature. "Our method constructs a contrastive covariance matrix between queries and keys"
- counterfactual prompts: Paired prompts differing in a targeted variable to isolate lexical effects. "we make counterfactual prompts: for every prompt, we make a copy but replace the entity being queried"
- feature splits: A phenomenon where models further decompose a multi-dimensional feature into independent components. "we observe feature splits, as indicated by the strong diagonals in such settings."
- Filter Heads: Attention heads that act like filters, attending to tokens matching a queried category. "Filter Heads~\citep{sharma2025llms} refer to attention heads that mirror ``filter'' functions"
- Frobenius norm: A matrix norm used here to determine effective rank via cumulative singular value energy. "capture 99\% of the squared Frobenius norm of ."
- latent variables: Hidden factors (discrete or continuous) that generate observed embeddings and drive attention behavior. "Our data generation relies on latent variables."
- lexical mechanism: A binding mechanism that uses the identity of the queried entity to retrieve the associated item. "Another mechanism is the lexical mechanism: the model uses the identity of the queried entity (e.g., jam) to retrieve the associated box."
- low-rank: Having dimensionality much smaller than the ambient space; used to describe compact feature subspaces. "decompose the QK space into low-rank, human-interpretable components."
- one-hot encoding: A sparse vector with a single 1 indicating a categorical class. "where is a one-hot encoding of "
- order-ID: A binding mechanism that tracks the ordinal position of entities to match pairs by order. "One mechanism is dubbed order-ID, in which the model uses the order in which entity groups appear"
- orthogonal projector: A linear operator projecting vectors onto a subspace with orthonormal basis. "Let be an orthogonal projector."
- payload embeddings: Token embeddings containing payload information (e.g., class labels) used in the toy task. "Each payload embedding is generated by first randomly sampling latent keys"
- PCA (Principal Component Analysis): A linear dimensionality reduction method used to visualize subspaces and clusters. "then perform PCA, which recovers the 3D-cube structure of ."
- QK space: The space of all query-key interactions within an attention head. "Understanding the structure of QK spaces reveals how queries and keys interact."
- residual query space: The part of the query vector not explained by identified feature subspaces. "and is the residual query space that is not accounted for by order-ID and lexical-ID."
- selector embedding: The query-side embedding that specifies which payload to retrieve in the toy task. "The selector embedding is generated similarly."
- superposition: Compression of multiple features into fewer dimensions than their combined intrinsic rank. "we see superposition~\citep{elhage2022superposition}, in which the model compresses both variables using less dimensions than available."
- SVD (Singular Value Decomposition): A matrix factorization used to extract ranks and subspaces from ΔC. "Given , we can recover the rank and subspace of latent variable by performing SVD:"
- token-level attributions: Decompositions assigning contributions of feature components to each token’s logit. "This yields token-level attributions in logit space"
- UMAP (Uniform Manifold Approximation and Projection): A nonlinear manifold learning method used to visualize high-dimensional lexical subspaces. "we include both PCA and UMAP: the clusters are easier to see in UMAP"
Collections
Sign up for free to add this paper to one or more collections.